
만만하게 봤는데 생각보다 오래 걸린 문제.
우선 나의 생각 전개 과정을 적어본다.
keywords는 다음과 같이 떠올렸다.
upper, lower cases. min length substring. duplicate characters.
즉, 공백이나 숫자는 포함되지 않은 문자에 한하여, 연속된 string의 중복을 허용한 조건을 만족해야함.
-
string t에 대한 중복 문자 처리
unordered_map을 사용하여 각 문자에 대한 횟수를 저장 -
string s에 대한 문자 개수 count
고민을 했던 부분.처음에는 1번에서 만든 value를 감소시키려고 하였으나, 그렇게 되면, 중복으로 나타난 값에 대한 대응이 되지 않았고, 이후 조건을 만족하였는가에 대한 판단을 할 수가 없었음.
예를 들어, t = "ABC"인 상황에서 s = "ABDCDB"가 나온다고 가정하면, 최초 C를 만나기 전까지는 문제없이 줄여나갈 수 있으나, 그 이후 B를 만난 경우, 애초에 t에 존재하지 않았던 문자인지, 이미 다 채워서 0이 된 문자인지 판단하기 어려웠다.
-
위 조건을 만족시키는 상태인지에 대한 확인.
따라서,2번과 3번에 대한 문제를 동시에 해결하고자, count와 새로운 unordered_map을 도입하였고, unorderd_map의 value로는 queue를 넣어, 각 char의 index를 저장하면서, 해당 queue의 size로 조건을 충족하였는가를 판단.
구현:
- low와 high 2가지 index를 가지고 sliding window를 구성. (중복을 허용하지 않는 최대의 문자열과 유사한 방식 착안)
- 최초 조건을 만족할 때까지는 queue에 값을 넣으면서, 각 문자에 대한 queue는 마지막 n개 (t에 존재하는 개수)의 index를 가지고 있도록 update.
- 조건을 만족했냐 / 하지 않았냐에 대한 판단을 하는 변수를 두어, 최초 조건 만족 전 / 후로 나눔 -> because, 최초 조건을 만족하기 전에는 "조건 만족"에 대한 판단을 했어야 했기 때문.
- 조건을 만족한 이후로는,
3-1. 해당 문자열의 queue에 저장된 index가 지금 lo 값이라면, 길이는 update될 수 있으므로 그 다음 최소값을 찾아서 lo로 지정 후 hi - lo의 길이로 비교.
3-2. 해당 문자열읭 queue에 저장된 index가 지금 lo 값이 아니라면, 다른 문자가 lo index를 차지하고 있다는 의미이므로, 더 커진 hi값이 더 작은 substring을 만들 수 없으므로, 단순히 queue값만 업데이트.
class Solution {
public:
string minWindow(string s, string t) {
// keywords: upper, lower cases. min length substring. duplicate characters.
// 시작과 끝은 t에 속한 char로 구성될 것.
//
if(s.size() < t.size()) return "";
unordered_map<char, int> tnums;
for(char c : t) tnums[c]++;
unordered_map<char, queue<int>> snums;
int ans_lo = 0, ans_hi = s.size()-1;
int lo = 0;
bool isContaining = false;
int count = 0;
for(int hi = 0; hi < s.size(); hi++){
char c = s[hi];
if(tnums.find(c) == tnums.end()){
continue;
}
if(isContaining){
bool isMin = true;
for(auto a : snums){
if(a.second.front() < snums[c].front()) {
isMin = false;
break;
}
}
snums[c].pop();
snums[c].push(hi);
if(isMin){
int secondMin = 987654321;
for(auto a : snums){
secondMin = min(secondMin, a.second.front());
}
if(ans_hi-ans_lo > hi - secondMin){
ans_hi = hi;
ans_lo = secondMin;
}
}
} else {
if(snums[c].size() < tnums[c]){
snums[c].push(hi);
count++;
} else {
snums[c].pop();
snums[c].push(hi);
}
if(count == t.size()){
if(t.size() == 1) return t;
isContaining = true;
int m = 987654321;
for(auto a : snums){
m = min(m, a.second.front());
}
if(ans_hi-ans_lo > hi - m){
ans_hi = hi;
ans_lo = m;
}
}
}
}
return isContaining ? s.substr(ans_lo, ans_hi-ans_lo+1) : "";
}
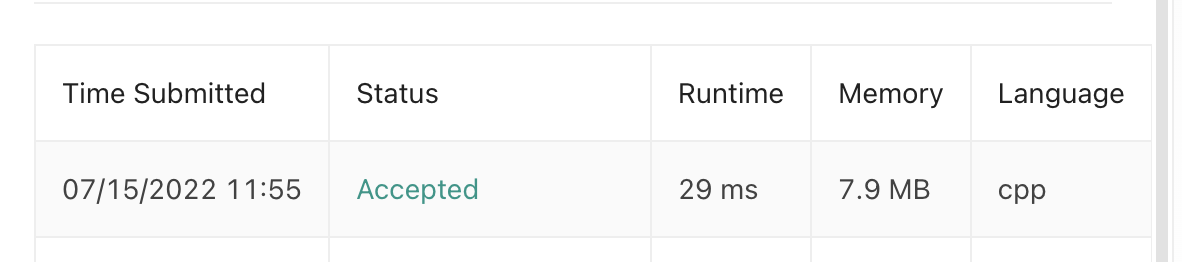
};결과: TLE (265/266)
문제는 무엇인가?
- index를 tracking하기 위한 queue를 managing하는 과정이 불필요했다.
- 조건 만족, 불만족에 대한 case를 divide한 것 또한 불필요했다.
- min값을 찾거나, secondMin값을 찾기위해 모든 snums를 iterate하는 과정이 불필요했다.
어떻게 개선할 수 있었는가?
-
조건 만족에 대한 판단을 새로운 변수 없이 확인할 수 있다.
-> tnums에 비해 snums의 값이 적은 경우에만 count를 증가시키게 되면, 한번 만족한 이후로는 쭉 조건을 만족. -
index를 저장하는 목적이, 다음 lo를 찾기 위한 과정이므로, 다른 방식으로 해결 할 수 있다.
-> 해당 lo 위치에서 lo값을 증가시키면서, 적어도 여기서 부터는 포함해야한다! 는 조건을 확인할 수 있음. (either that character is irrelevant or I have more characters than I need, increase the lo value)
개선된 구현
class Solution {
public:
string minWindow(string s, string t) {
// keywords: upper, lower cases. min length substring. duplicate characters.
if(s.size() < t.size()) return "";
unordered_map<char, int> tnums;
for(char c : t) tnums[c]++;
unordered_map<char, int> snums;
int ans_lo = 0, ans_hi = s.size()-1;
int lo = 0;
int count = 0;
for(int hi = 0; hi < s.size(); hi++){
char c = s[hi];
if(tnums.find(c) == tnums.end()){
continue;
}
snums[c]++;
if(snums[c] <= tnums[c]) count++;
if(count >= t.size()){
while(tnums.find(s[lo]) == tnums.end() || tnums[s[lo]] < snums[s[lo]]){
snums[s[lo]]--;
lo++;
}
if(ans_hi - ans_lo >= hi - lo){
ans_hi = hi;
ans_lo = lo;
}
}
}
return count == t.size() ? s.substr(ans_lo, ans_hi-ans_lo+1) : "";
}
};
사소한 팁.
unordered_map<char, int> map;
cout << map.size() << endl; // 0
if(!map['a']){
// do something
}
cout << map.size() << endl; // 1즉, unorderd_map에서 key의 존재 여부를 판단하기 위하여, 위와 같은 방식으로 체크를 하게 되면, 어느새 key-value pair가 생긴것을 알 수 있음.
key의 존재 여부 체크를 위해서는
if(map.find('a') == map.end()){
// do something
}위와 같이 find를 사용하자.
