- 왜 분석하는가?
- Crop Image를 JPEG로 인코딩 하면서 성능 이슈가 발생하였음
- Image의 Row Data 복사 속도에 따라 좌우됨을 확인
- 해당 이슈 확인 및 개발 방향성을 결정하기 위해 OpenCV, Torch, C++ STL, SSE/AVX 구현 방식의 성능 비교분석 진행
- 성능 분석 내용을 확인하기 앞서….
-
Intel 계열 CPU는 SIMD(Single Instrument Multiple Data)를 위한 명령어 셋을 별도로 제공
-
MMX, SSE, AVX가 대표적이며, 이에 따라 지원되는 형태나 명령어도 다름 -
가장 최신 명령어 셋은 AVX이며, 코어, 캐시, 레지스터 등의 차이에 따라 지원되는 명령어 셋이 세부적으로 나누어짐
-
52번 서버의 Xeon Gold 6326 지원 명령어 셋
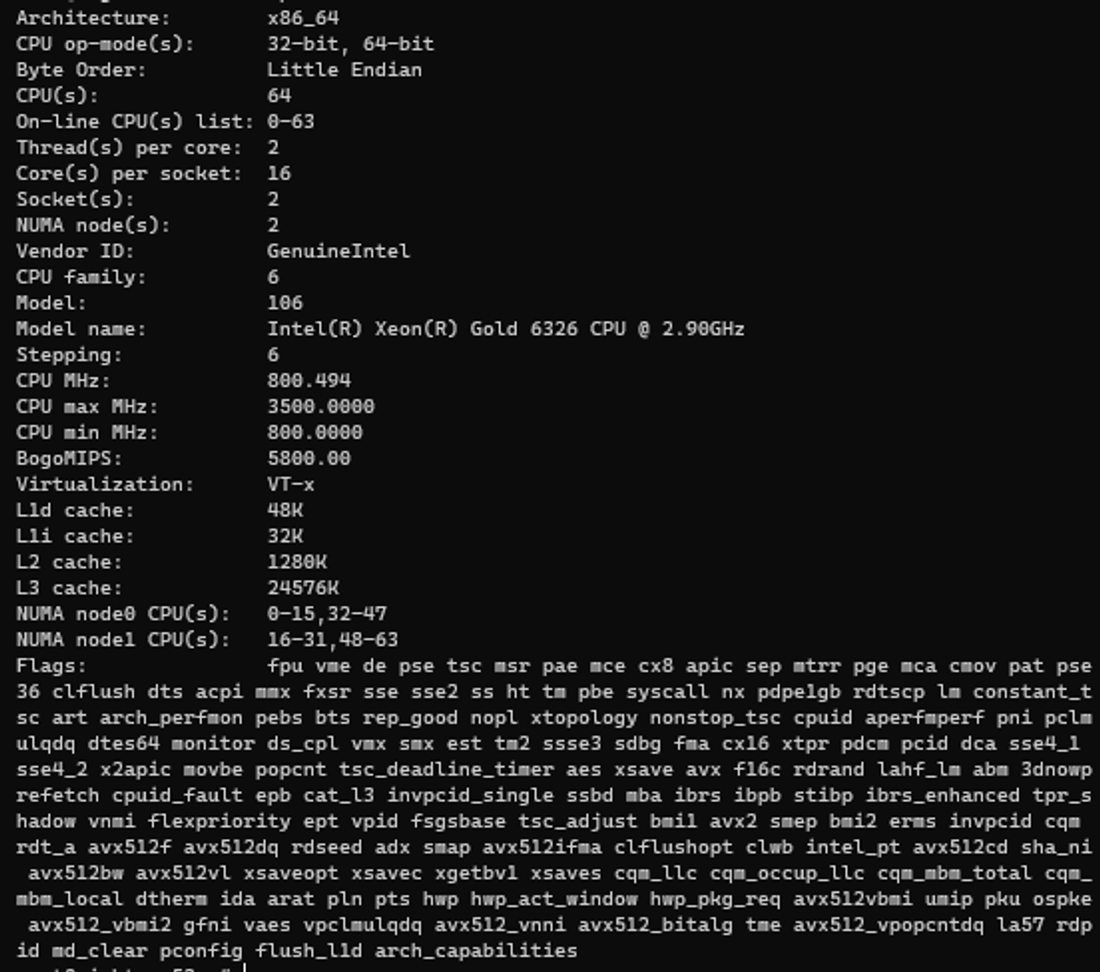
- avx512 계열 명령어까지 지원되는 것으로 보이며, 이는 256bit를 2사이클 간격으로 동시 처리 가능
-
NHN Cloud의 CPU(뭔지 모름)지원 명령어 셋
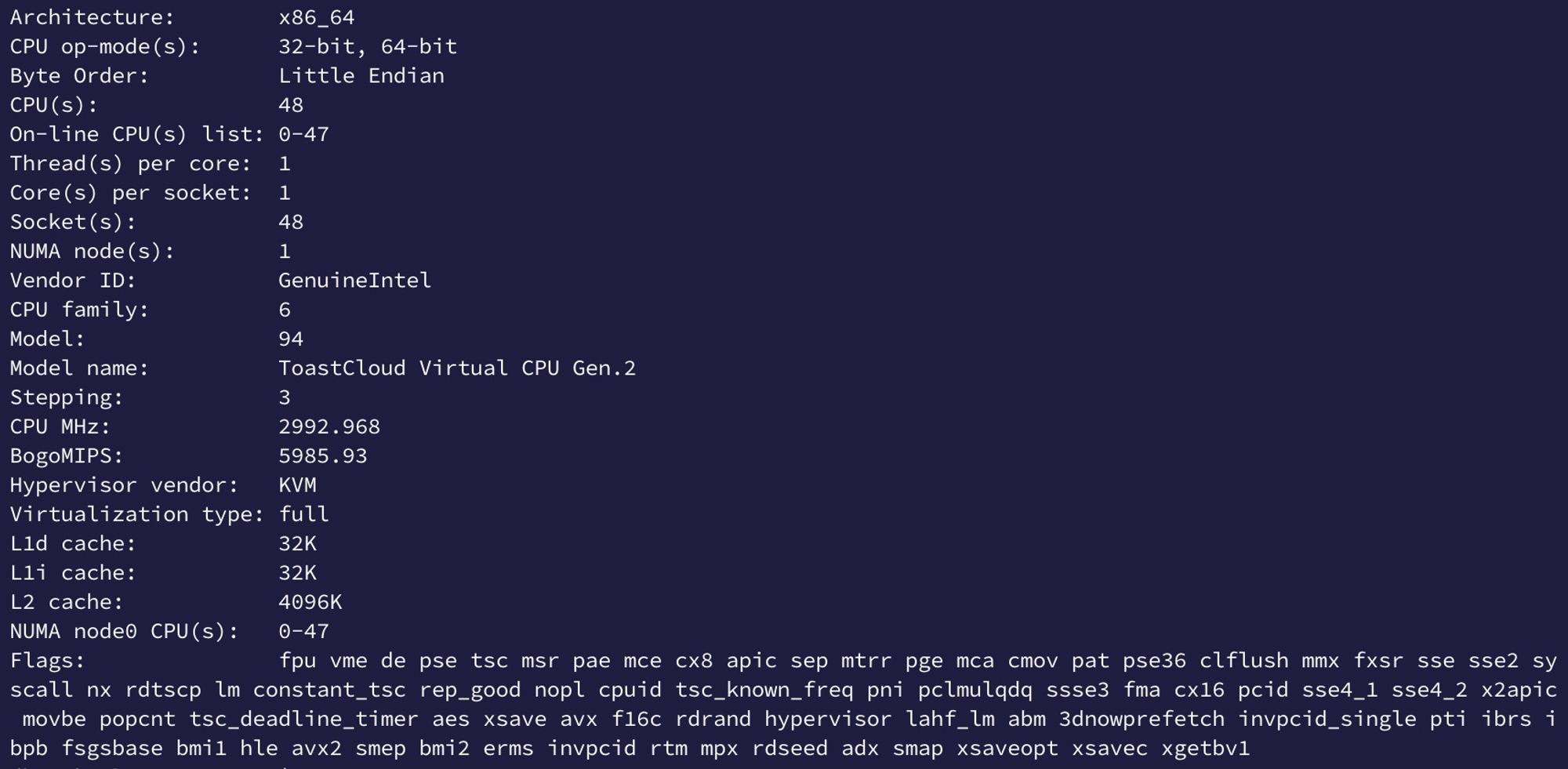
- avx2까지 지원되는 것으로 보이며, 이는 128bit를 2사이클 간격으로 동시 처리 가능
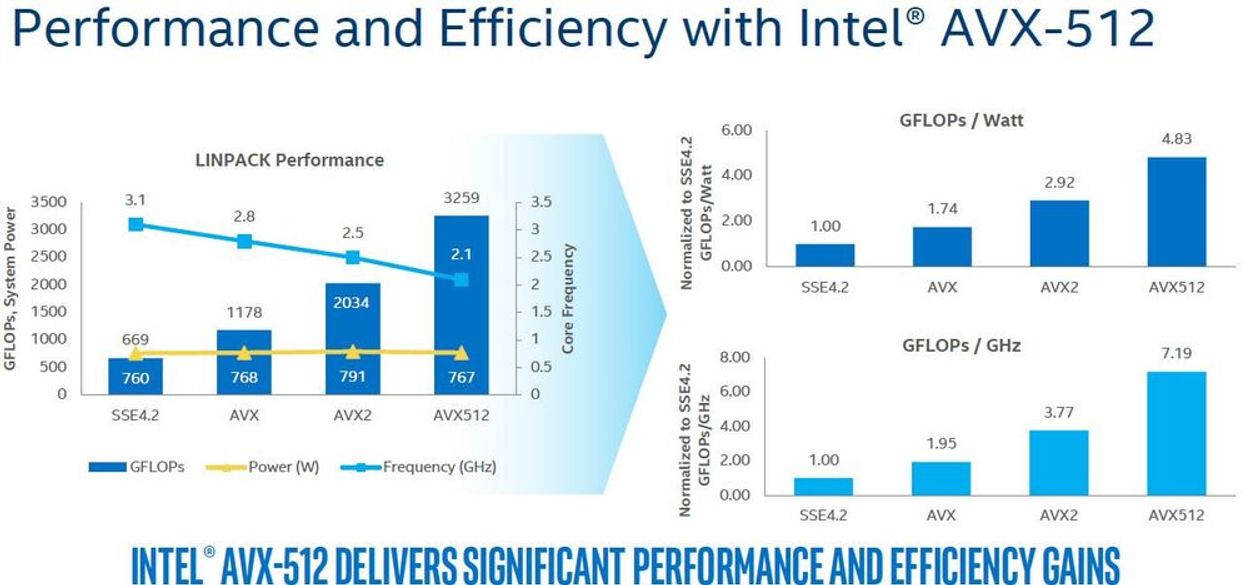
- (참고) AVX2와 AVX-512의 퍼포먼스 차이는 아래와 같음
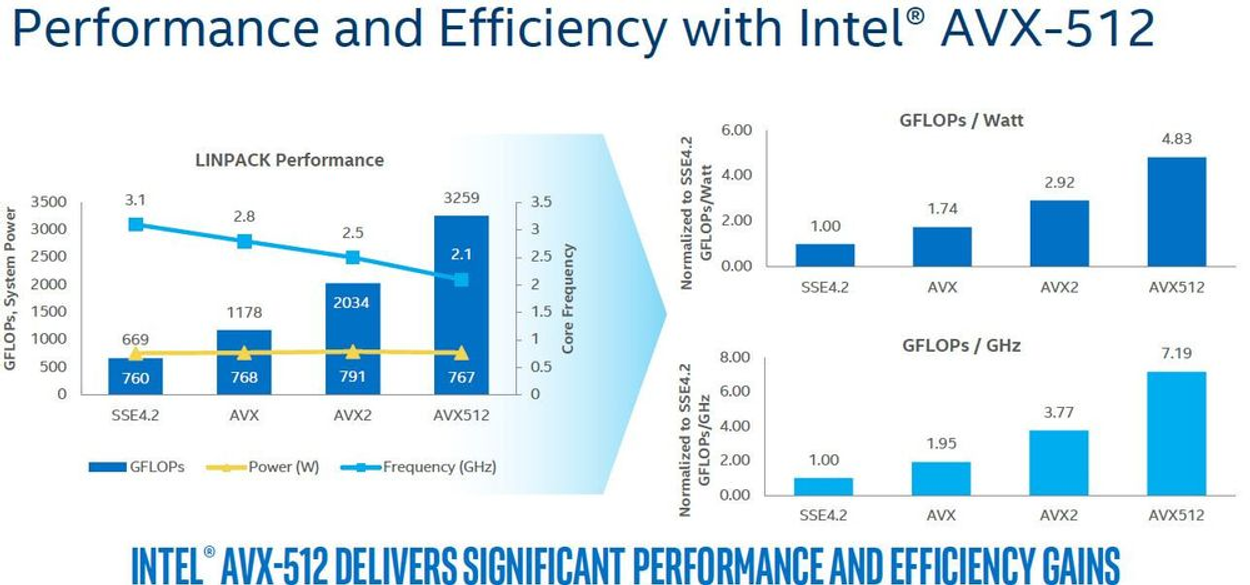
-
-
-
1차 테스트
- OpenCV의 cv::Mat, Torch의 Tensor, C++ std::vector allocation, C++ new/std::memcpy의 4가지 속도를 비교
- Xeon Gold 6326에서 테스트
- 5000장을 분석하여 최대, 최소, 평균 처리속도를 측정
- HD, FHD 각 크기의 RGB Row Data를 복사하는 성능 비교
- CPU가 Burst하게 동작하는 경우(점유율 90~100%)와, 그렇지 않은 경우(점유율 50% 이하)의 두 가지의 성능 비교
- std::copy와 std::memcpy는 성능이 미묘하게 다르나 거의 비슷하다고 알려져 굳이 포함하지 않음
- 결과 (ns)
-
CPU 점유율 100%
HD(12807203) Max Min Average(5000장) cv::Mat 11056661 209229 387329 Tensor 20843264 49609 2496921 vector allocation 7971551 182167 399710 new+memcpy 12764150 161856 728102 FHD(192010803) Max Min Average(5000장) cv::Mat 6954824 561085 998685 Tensor 24104147 98669 2385730 vector allocation 8342649 561324 953321 new+memcpy 9077117 450518 833688 -
CPU 점유율 50% 이하
HD(12807203) Max Min Average(5000장) cv::Mat 1763586 217789 535159 Tensor 11984141 40941 207984 vector copy 2340399 202311 595907 array memcpy 16736949 195602 1241271 FHD(192010803) Max Min Average(5000장) cv::Mat 6858374 624993 1469517 Tensor 23701377 101762 538321 vector allocation 7817482 662939 1406273 new+memcpy 5999779 596376 1105992
-
- 분석
- Tensor : Min을 보면 압도적 빠른 속도로 처리되도록 설계되어 있으나……
- Torch 역시 SIMD의 명령어 셋을 이용하여 최적화하여 개발되었다고 알려져 있음
- 최소 처리 성능만을 보면 OpenCV나 C++ 표준 함수들의 성능을 압도하며 4배 이상의 처리속도를 보여 줌
- 하지만, 리소스 상태에 따라 편차가 매우 큼
- CPU 100%의 경우 평균 처리 속도가 7~8배 까지 하락하는 경향을 보임
- parallel, concurrency를 최대한 활용하도록 설계되어 있다면, OS의 스케쥴링 작업으로 인해 성능의 편차가 심할 것으로 추정됨 (Source가 공개되지 않아 추측만 할 뿐…)
- CPU가 Burst한 경우 위 과정에서 심한 오버헤드가 발생하게 되면서 발생하는 문제로 추측
- CPU 100%의 경우 평균 처리 속도가 7~8배 까지 하락하는 경향을 보임
- OpenCV cv::Mat (std::vector)
- STL의 Vector과 거의 흡사한 성능을 보임
- STL을 기반으로 개발된 것으로 보이며, 이에 따라 이 둘을 비교하는 것은 큰 의미가 없는 것으로 판단 됨
- 최소 처리 속도와 평균 속도가 2배 정도의 편차는 있지만, 50배 까지도 차이가 발생하는 Tensor보다는 훨씬 일관적인 성능을 보임
- new alloc/std::memcpy보다 HD에서는 2배 가량 빠른 속도를, FHD의 경우 약 30%정도 저하된 처리속도를 보임
- STL의 Vector과 거의 흡사한 성능을 보임
- new alloc + std::memcpy
- 가장 하드웨어에 가까운 접근 방법이라 테스트 직전 까지만 해도 가장 좋은 성능을 보여줄 것이라고 예상했으나…..
- HD급에서는 vector보다 2배이상 낮은 처리속도를, FHD급에서는 vector과 비슷하거나 약간 나은 처리속도를 보여줌
- STL에 구현된 memcpy의 성능에 의문을 가지는 사람들도 많으며, SIMD이 적용되지 않은 것은 아닐지 의문이 들어 memcpy를 별도로 구현하여 테스트를 진행
- 가장 하드웨어에 가까운 접근 방법이라 테스트 직전 까지만 해도 가장 좋은 성능을 보여줄 것이라고 예상했으나…..
- Tensor : Min을 보면 압도적 빠른 속도로 처리되도록 설계되어 있으나……
- OpenCV의 cv::Mat, Torch의 Tensor, C++ std::vector allocation, C++ new/std::memcpy의 4가지 속도를 비교
-
번외 테스트
-
Intel SIMD Intrinsics로 다음과 같이 memcpy를 구현 (128bit )
inline void simdMemcpy(void* pDest, void* pSrc, size_t nCount) { nCount /= 0x10; for (size_t i = 0; i < nCount; i++) { __m128i mTemp = _mm_loadu_si128((__m128i*)nSrc + i); _mm_storeu_si128(reinterpret_cast<__m128i*>(pDest) + i, mTemp); } } -
new alloc/std::memcpy와 new alloc/simdMemcpy를 비교
-
CPU 점유율 100%
HD(12807203) Max Min Average(5000장) vector allocation 7971551 182167 399710 new+memcpy 12764150 161856 728102 new+simdMemcpy 2982921 161197 256864 FHD(192010803) Max Min Average(5000장) vector allocation 8342649 561324 953321 new+memcpy 9077117 450518 833688 new+simdMemcpy 3861825 471668 625451 -
CPU 점유율 50% 이하
HD(12807203) Max Min Average(5000장) vector allocation 2340399 202311 535159 array memcpy 16736949 195602 1241271 new+simdMemcpy 1968463 185140 433673 FHD(192010803) Max Min Average(5000장) vector allocation 7817482 662939 1406273 new+memcpy 5999779 596376 1105992 new+simdMemcpy 6898006 566243 873873
-
-
분석
- SIMD로 대충 구현한 memcpy가 C++표준 memcpy / vector allocation 보다 높은 성능을 보임
- HD, FHD 모두 std::memcpy보다 훨씬 높은 속도을 보이며, vector allocation보다도 미묘하게 높은 성능을 보임
- Min과 Average를 비교하여 봤을때도 vector allocation보다 성능 편차가 적음
- (추가 및 의문점) glibc에 구현된 표준 memcpy등의 메모리 핸들링 함수들은 이미 SIMD 최적화가 되어있는 것으로 알려져있음
- 개발자들이 각자 공들여 만든 SIMD memcpy 함수들이 glibc에 구현되어있는 memcpy보다 느리다는 리포팅을 다수 발견할 수 있음
- 하지만 큰 고민없이 날먹으로 구현한 SIMD memcpy가 왜 glibc에 구현된 memcpy보다 더 빠른지에 대해 추 후 고민해 볼 필요가 있음.
- 의심가는 부분은 AVX가 CPU에 많은 부하를 주면서 성능이 저하된다는(쓰로틀링?) 리포팅
- 새로 작성한 SIMD memcpy는 날먹으로 만들어져서 CPU에 부하를 적게 주어 쓰로틀링이 걸리지 않아서 성능저하를 피했을 가능성이 있음
- https://news.ycombinator.com/item?id=20909123
- SIMD로 대충 구현한 memcpy가 C++표준 memcpy / vector allocation 보다 높은 성능을 보임
-
참고
- SSE, AVX로 구현해놓은 FastMemcpy라는 오픈소스가 존재.
- https://github.com/skywind3000/FastMemcpy
- 구현해놓은 날먹 코드랑 구조는 비슷한 것으로 보이며 비슷한 성능을 보임. 시간날 때, glibc의 표준 memcpy와 비교해보는 것도 나쁘지 않아보임
- SSE, AVX로 구현해놓은 FastMemcpy라는 오픈소스가 존재.
-
-
2차 테스트
- OpenCV의 cv::Mat, Torch의 Tensor, C++ std::vector allocation, C++ new+std::memcpy의 4가지 속도를 비교
- NHN Cloud에서 테스트
- 이외 1차 테스트와 동일
- 변수 발생
- CPU 점유율 100%로 동작하지 않음….
- Full load해도 CPU 점유율 50%정도로 동작하는 문제로 이에 대한 테스트만 진행
- 결과
- CPU 점유율이 50% 정도로 동작하는 상황이지만….
- Xeon Gold 6326 에서 CPU Burst (100%)해서 나온 결과와 비슷하게 나옴
- CPU 점유율이 50% 정도로 동작하는 상황이지만….
- OpenCV의 cv::Mat, Torch의 Tensor, C++ std::vector allocation, C++ new+std::memcpy의 4가지 속도를 비교
-
현재까지의 최종 결론
- 이미지 해상도, 리소스 측면, 하드웨어에 따라 성능이 다르게 측정될 가능성이 높으며, 일관적이지 않은 성능을 보여 결정하기가 힘듦
- Decoding, Encoding, ML 등의 무겁고 복잡한 작업으로 리소스를 사용하는 경우이므로, 다음 두 가지를 고려하여 선택
- 최대한 일관성 있고 안정적인 성능을 보이는 방식을 우선순위로 선정
- 위를 만족하면서 빠른 성능을 보이는 방식
- 위 조건에 맞는 케이스는 cv::Mat, vector allocation, SIMD memcpy 세 가지
- 안정성이 떨어지는 Torch Tensor는 배제….
- 그러나 추 후, 고성능 하드웨어에서 높은 해상도 처리를 할 때 고려해 볼 필요는 있음…
- Tensor 제외 가장 빠른 성능을 보이는 것은 SIMD memcpy
- 아직 안정성에 대해 보장 안된 날먹 코드.
- CPU Archicture에 따라 성능이 들쭉날쭉할 가능성이 높음
- 타겟 CPU가 있다면 해당 성능을 확인해보고 적용 가능성을 판단해봐도 됨
- cv::Mat의 경우 vector allocation과 동일한 동작을 한다고 추측 됨
- OpenCV 배제. 굳이 무겁게 라이브러리를 추가 빌드 할 필요 없음
- vector allocation으로 대체
- 안정성이 떨어지는 Torch Tensor는 배제….
∴ 안정적이고 표준화 되어 있는 STL의 vector allocation과 SIMD로 구현한 memcpy, 두 가지로 구현을 진행
내용 추가
- Xeon Gold 6326 서버에서 위와 같이 동일한 테스트를 진행하였으나, 결과가 다시 다르게 나옴
-
테스트 방법 : 상동
-
결과 (ns)
-
CPU 점유율 HD 100% / FHD 70~80% (FHD의 경우 이전 테스트와 다르게 CPU의 풀로드가 되지 않음)
HD(12807203) Max Min Average(5000장) cv::Mat 5222129 217459 292543 Tensor 14316549 41761 443983 vector allocation 6153631 158712 279438 new+memcpy 2889589 157118 255620 FHD(192010803) Max Min Average(5000장) cv::Mat 6954824 1173329 1593093 Tensor 19377702 127920 288277 vector allocation 6574643 1111482 1634486 new+memcpy 16660172 883518 1166557 -
CPU 점유율 50% 이하
HD(12807203) Max Min Average(5000장) cv::Mat 1728149 205262 547690 Tensor 11722993 36609 173569 vector copy 1641290 188057 547901 array memcpy 3791863 158441 468745 FHD(192010803) Max Min Average(5000장) cv::Mat 5068249 459039 1389562 Tensor 11888141 77804 276695 vector allocation 3674948 591678 1434871 new+memcpy 7580591 515391 1209153
-
-
이전 테스트와 비교
- Xeon Gold 6326G 서버의 리소스 상태가 이전 테스트 상태 보다 안정적인 것으로 추정 됨
- 이전 테스트 상태와 마찬가지로 cv::Mat와 vector allocation간의 차이가 없음
- cv::Mat는 개발 내용에서 배제
- 이전 테스트 상태와 다르게 새로 구현한 simd memcpy와 기존 std::memcpy간 차이가 거의 없음
- glibc의 memcpy 역시 simd로 구현된 것이 맞는 것으로 보여짐
- 이전 테스트에서는 std::memcpy가 CPU 100% 상태에서는 vector allocation보다 성능이 2배 가량 떨어졌으나, 이번 경우는 성능이 약간 더 좋음(vector allocation보다 안정성이 떨어짐)
- 이러한 이유로 새로 구현한 simd memcpy와 std::memcpy는 배제
- 이전 테스트 상태와 비교 시, Tensor의 성능 변화 내용이 가장 큼
- CPU 점유율 50%이하의 경우, vector allocation보다 약 3~5배 가량 성능이 좋음…..
- HD영상 CPU 100% 시, 이전 테스트와 비교해서 5~6배 가량의 성능 차이 발생
- FHD영상의 경우 풀로드(CPU 100%)가 재현되지 않음…. 굳이 이전 테스트와 비교하자면 10배 가량의 성능 차이 발생
- 성능은 좋으나, 안정성의 문제로 Tensor 역시 배제….
∴ 안정성이 가장 높고 적당한 성능이 나오는 vector allocation으로 구현 진행
-

개발자