제목: Universal Language Model Fine-tuning for Text Classification (2018)
링크: https://arxiv.org/abs/1801.06146
0. Abstract:
- 기존의 NLP 방식은 task-specific한 설정과 training from scratch 완전 백지 상태에서 부터 시작을 한다.
- 즉, 경제 기사와 정치 기사를 분류하는 모델을 만들려면, 훈련용으로 많은 양의 경제 기사와 정치 기사를 모아야 하고, 모델은 초기 백지 상태에서 시작을 해야 한다.
- 이런 방식을 대체하기 위해, 이 논문에서 Universal Language Model Fine-tuning (ULMFiT)이라는 효과적인 Transfer Learning (전이 학습) 방법을 구현했다.
- 위의 비유에 대입을 하자면, 경제/정치 기사와 별개로 다른 기사들로 미리 학습된 (pre-trained) 언어 모델을 구성한 후에, 경제/정치의 소스를 덮어서 (Fine-tuning) 모델을 만드는 방식.
- 이 방식으로 적은 양의 학습 데이터로도 훨씬 좋은 성능을 낼 수 있었다고 한다.
1. Introduction
- Transfer Learning은 이미 Computer Vision (CV) 분야에서 이미 큰 영향을 끼쳤다. 이를 바탕으로 응용해보자
- 우선 NLP에서 딥러닝 모델들이 좋은 성능을 보여주고 있지만, 이 모델들은 백지 상태에서 시작하고 많은 양의 데이터를 요구한다.
- NLP는 주로 Transductive transfer 에 초점이 맞춰져 있었다.
- Inductive transfer 에서는 pre-trained된 word embedding은 성능이 좋아서 많이 쓰임
- Pre-trained된 모델을 이용하는 것은 많은 장점을 가져오지만, NLP에서는 몇 가지 이유로 성공적으로 쓰이지 못하고 있다.
- NLP모델은 CV 분야에 비해 모델 깊이가 얕고, 대부분은 Language Model들은 작은 데이터셋에 학습이 되어 overfit된 경향 때문에 fine-tuning을 해도 catastrophic forgetting이 자주 일어난다고 한다.
- Universal Language Model Fine-tuning (ULMFiT)로 아무 NLP 문제에 안정적인 inductive transfer learning을 제공
(* Transductive transfer vs. Inductive transfer)
- 두 학습 방식의 차이
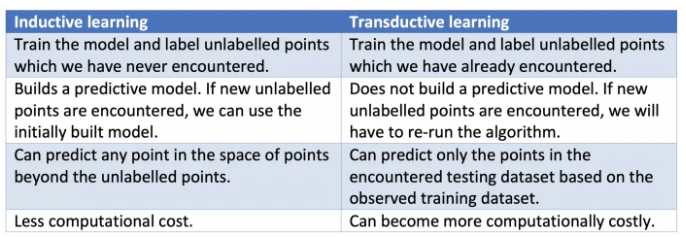
- (참고 링크: https://towardsdatascience.com/inductive-vs-transductive-learning-e608e786f7d)
2. Related Work
-
Transfer Learning in CV
- CV 분야에서의 학습은 “general to task-specific” 하게, 첫 layer에서 general한 pre-trained 모델을 transfer하고, 뒤쪽 layer에 갈수록 task에 specific해지는 방식이다.
- 주어진 목적에 맞는 학습 모델이 필요하면, 좀 더 general한 모델을 우선 사용해서, 학습을 시작한다는 느낌
- 비유가 될지는 모르겠지만, 미슐랭 급 맛집을 찾아주는 모델을 만들고자하면, 식당들의 정보에 “망고 플레이트"에 등록된 식당들의 임베딩 정보를 먼저 덮어서 모델 학습을 진행한다는 느낌.
- 하지만 요즘에는 앞단의 layer들이 아닌, 앞의 layer들은 frozen 상태로 두고, 뒤의 마지막 layer에 pretrained model을 사용하는 추세이다.
-
Hypercolumns
- Hypercolumn이라는 개념은, 다른 task에서 pre-trained된 embedding을 가져와 좀 더 추가적인 context를 넣기 위해 layer 사이사이에 껴놓는 방식이다.
- 하지만 CV 분야에서는 end-to-end fine-tuning 방식에 의해 거의 대체된 상태
-
Multi-task learning (MTL)
- 기존 모델에 또 다른 Language Model을 추가해서 결합 학습이 되는 방식.
- Pre-trained된 모델을 쓰는게 아니라 처음부터 학습이 되어 비효율적
-
Fine-tuning
- Pre-trained된 모델을 사용한다고 해도, 목적에 맞게 정교하게 tuning을해야하는 것이 fine-tuning이다.
- 그럼에도 NLP 분야에서는 좋은 성능으로 fine-tuning을 하려고 해도 10k이상의 데이터를 사용해야 가능…
- 하지만! ULMFiT는 100개의 데이터로도 SOTA 달성했다~라고 자랑
3. Universal Language Model Fine-tuning
- ULMFiT는 large general-domain corpus에 pretrain 되어 있고, target task에 fine-tune되는 방법론이다.
- “Universal”한 이유는 다음과 같다:
- Works across tasks varying in document size, number and label type = Domain, Task와 환경과 상관 없음
- Uses a single architecture and training process = 한 가지의 아키텍처 및 학습 절차
- Requires no custom feature engineering or preprocessing = 부가적인 Feature Engineering X
- Does not require additional in-domain documents or labels = 추가적인 문서 및 레이블 X
- 실험에서 사용한 Language Model은 그 당시 SOTA였던 AWD-LSTM
-
ULMFiT는 다음과 같은 단계로 구성이 된다:
- General-domain LM pretraining
- 문서 약 30000개와 단어 1억개로 구성된 Wikitext-103로 pretrain 진행
- 가장 자원과 시간이 많이 소요되지만, 한 번만 실행을 하면 되고 좋은 성능을 가져올 것이기 때문에 괜춘
- Target task LM fine-tuning
-
Pre-trained 된 general-domain 데이터가 아무리 다양한 집군으로 이루어져 있어도, target task의 데이터는 다른 분포를 이룰 것이기 때문에 fine-tuning을 해야한다.
-
Fine-tuning은 두 가지 방법으로 진행을 한다: Discriminative fine-tuning and slanted triangular learning rates:
-- Discriminative fine-tuning: 각 layer는 “different types of information”을 가지고 있다. (Yosinski et al., 2014) 그래서 각 layer마다 different learning rate를 사용한다.
실험적으로 확인을 해보니 마지막 layer를 fine-tuning을 하고, 앞 layer들의 learning rate을 2.6으로 나눈 값으로 설정하는게 성능이 잘 나왔다고 한다.-- Slanted triangular learning rates: Task-specific하게 parameter들이 잘 학습이 되기 위해서는 초반에 빨리 적합한 parameter space에 converge한 후에, 그 후에 parameter를 정밀하게 자리 잡길 학습한다.위의 설명과 같은 학습법을 위해 slanted triangular learning rate (STLR)를 사용. 처음에는 linear하게 learning rate를 높인 후에 linear하게 decay하는 방식이다.
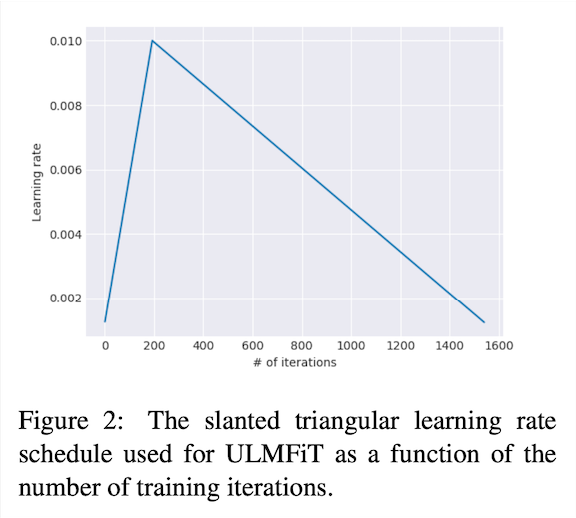
- Target task classifier fine-tuning
- 마지막으로 classifier를 fine-tuning하기 위해 pre-trained LM을 linear block 두개 (Batch normalization + dropout + ReLU activation, 그리고 확률을 내뱉기 위한 softmax)
- 추가적인 요소들)
(Concat pooling) layer의 hidden state만을 고려하면 information을 많이 잃어버릴 수도 있기 때문에, 마지막 hidden state를 모든 time step의 hidden state들의 max-pool값과 mean-pool 값을 concatenation해준다.
(Gradual unfreezing) 모든 layer들을 Fine-tuning을 한 번에 하는 것보다 (이러면 catastrophic forgetting 유발할 위험이 존재) 마지막 layer부터 하나하나씩 서서히 unfreeze 하는 방식
(BPTT for Text Classification - BPT3C) Language Model은 back propagation through time (BPTT)로 학습이 된다.
4. Experiments & Results
- 6개의 잘 알려진 NLP 데이터셋을 사용. (Sentiment Analysis, Question Classification, Topic classification와 같은 주제)
- 어느 논문에서 주장하듯이 성능이 잘 나왔다고 함
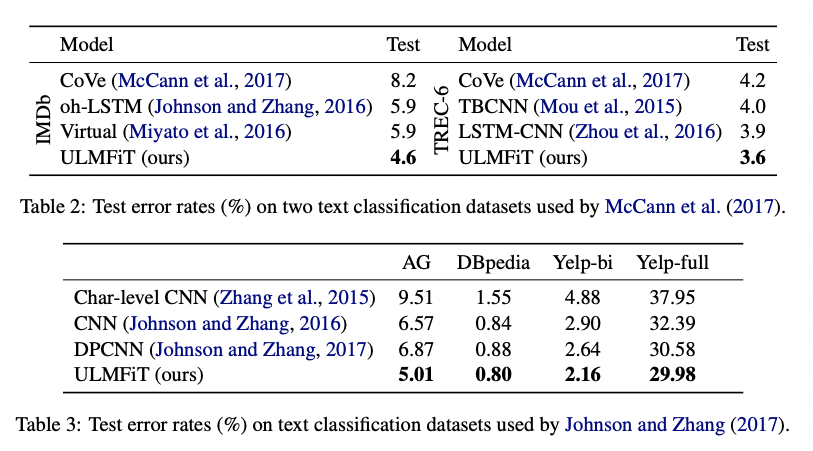
5. Analysis
- 그래서 위에서 설명한 ULMFiT의 구성요소들이 어떻게 성능에 기여를 했는지 여러 조건으로 실험을 했다고 함
(i) Low-shot learning
- Transfer Learning의 큰 장점 중 하나는 작은 데이터셋으로도 좋은 성능을 낼 수 있다는 점이다. 아래의 Figure 3. 에서 보이듯이 scratch에서 쌩 모델을 만드는것보다 성능이 훨씬 좋다는 것을 확인
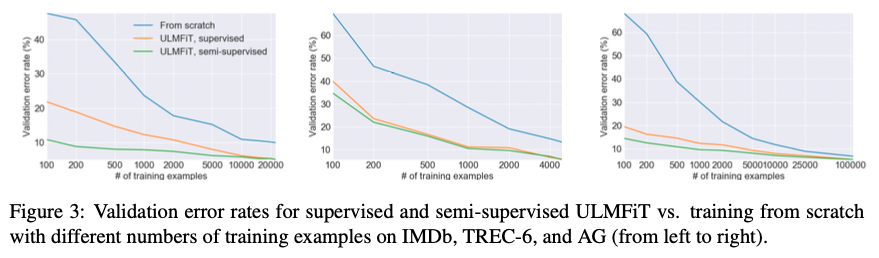
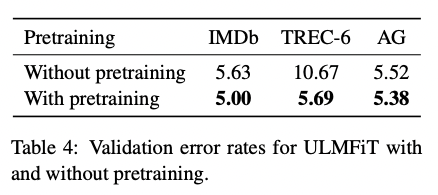
(ii) Impact of pretraining
- Pre-training을 한게 그래서 성능에 도움이 됐나? -> YES
- 작은 데이터셋, 큰 데이터셋에서도 도움이 됐음 (데이터셋 크기 무관하게)
(iii) Impact of LM quality, Impact of LM fine-tuning, Impact of classifier fine-tuning
- Language Model 자체를 성능이 좋은걸로 사용하면 성능이 좋아짐
- LM fine-tuning은 언급된 discriminative fine-tuning 이랑 slanted-triangular learning rates 다 쓰니깐 좋았다
- Classifier fine-tuning도 다양한 기법 사용해서 성능이 좋아짐
6. Discussion & Conclusion
- ULMFiT와 같은 Transfer Learning 기반 Language Model은 도움이 많이 될 것이다:
- 영어가 아닌 언어들은 데이터셋이 부족한데, 이 방법으로 도움이 많이 될 것
- state-of-the-art 아키텍처가 없는 NLP task에서 응용 가능할 예정
- 한정된 label data의 task도 처리 가능
- ULMFiT로 catastrophic forgetting도 방지하고, 다양한 도메인에서도 학습이 가능하게 했고, 이를 바탕으로 NLP에서도 transfer learning이 잘 사용될 수 있는 계기가 되길 바람
