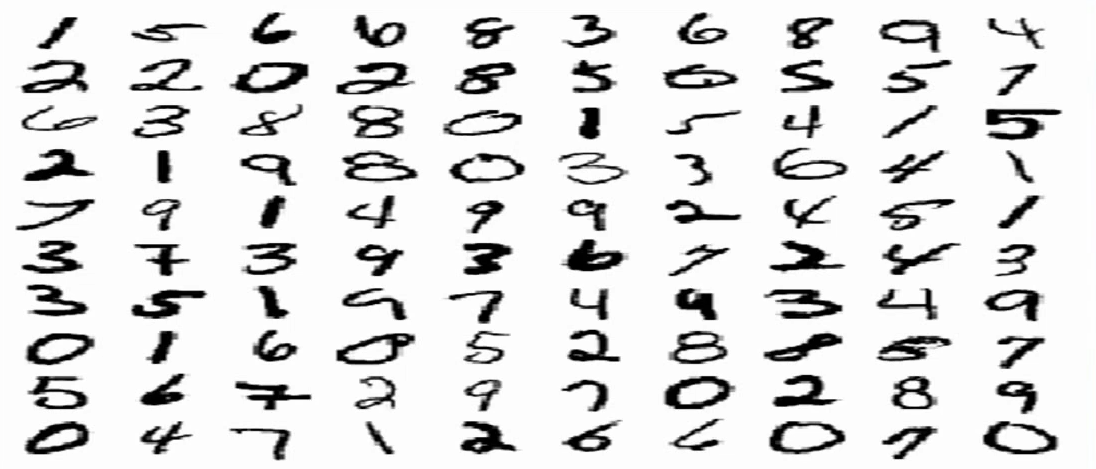
MNIST (Modified National Institute of Standards and Technology database)
MNIST(Modified National Institute of Standards and Technology database)는 손으로 직접 쓴 숫자들로 이루어진 데이터 셋으로, 프로그래밍 언어를 처음 배울 때 "Hello, World"를 출력하는 것처럼 딥러닝에서 반드시 거치는 단계입니다.
MNIST는 0부터 9까지의 숫자 이미지로 구성되며, 60,000개의 트레이닝 데이터와 10,000개의 테스트 데이터로 이루어져있습니다.
다운로드 경로
- mnist_train.csv, mnist_test.csv

training data의 첫번째 열에는 정답을 나타내는 1개의 필기체 숫자를 나타내고 있으며 나머지 784개의 열에는 그 숫자를 나타내는 정보들로 구성으로 training data는 총 60,000개의 데이터(행)으로 구성되어 있습니다.
test data는 training data와 같은 형식으로 총 10,000개의 데이터로 이루어져 딥러닝 아키텍처가 얼마나 잘 작동하는지 테스트 하기 위해 사용됩니다.


trainging data와 test data를 입력받은 후 trainging data의 첫번째 데이터를 이미지로 나타내어 보았습니다.
784 = 28 x 28로 784의 데이터들은 아래의 이미지를 나타내기 위한 화소값들을 나타내는 값이었으며 이와 같이 MNIST는 숫자를 나타내는 이미지의 화소값들을 나열하여 학습시키는 방법임을 알 수 있었습니다.

- One-Hot Encoding

1. 입력층 노드를 입력 데이터 개수와 일치하도록 784개 설정합니다
training data 행렬에서 정답을 나타내는 1열을 제외하면 2열부터 785열까지 총 784개의 데이터가 숫자 이미지를 나타내므로 노드 개수도 784개로 설정합니다.
2. 은닉층 노드는 임의로 설정합니다.
은닉층은 정해진 규칙이 없으므로 100개 설정 (물론 적절한 은닉층의 수를 정하는 알고리즘이 존재하거나 갯수를 변화시키며 trade-off 값을 찾는 등이 필요할거라 생각됩니다.)
3. 출력층 노드는 10개로 설정합니다.
정답은 0 ~ 9 중 하나의 숫자이므로 출력 노드를 10개로 설정합니다. 이 중 가장 큰 값을 가지는 index를 정답을 판단하는 방법을 one-hot encoding이라고 합니다.
One-Hot Encoding

10개의 출력 노드가 위 그림과 같은 경우, index 5번째 노드의 출력 값이 0.99로 가장 크기 때문에 정답을 5라고 판단하는 방법입니다.
- Back-Propagation을 이용한 MNIST 구현
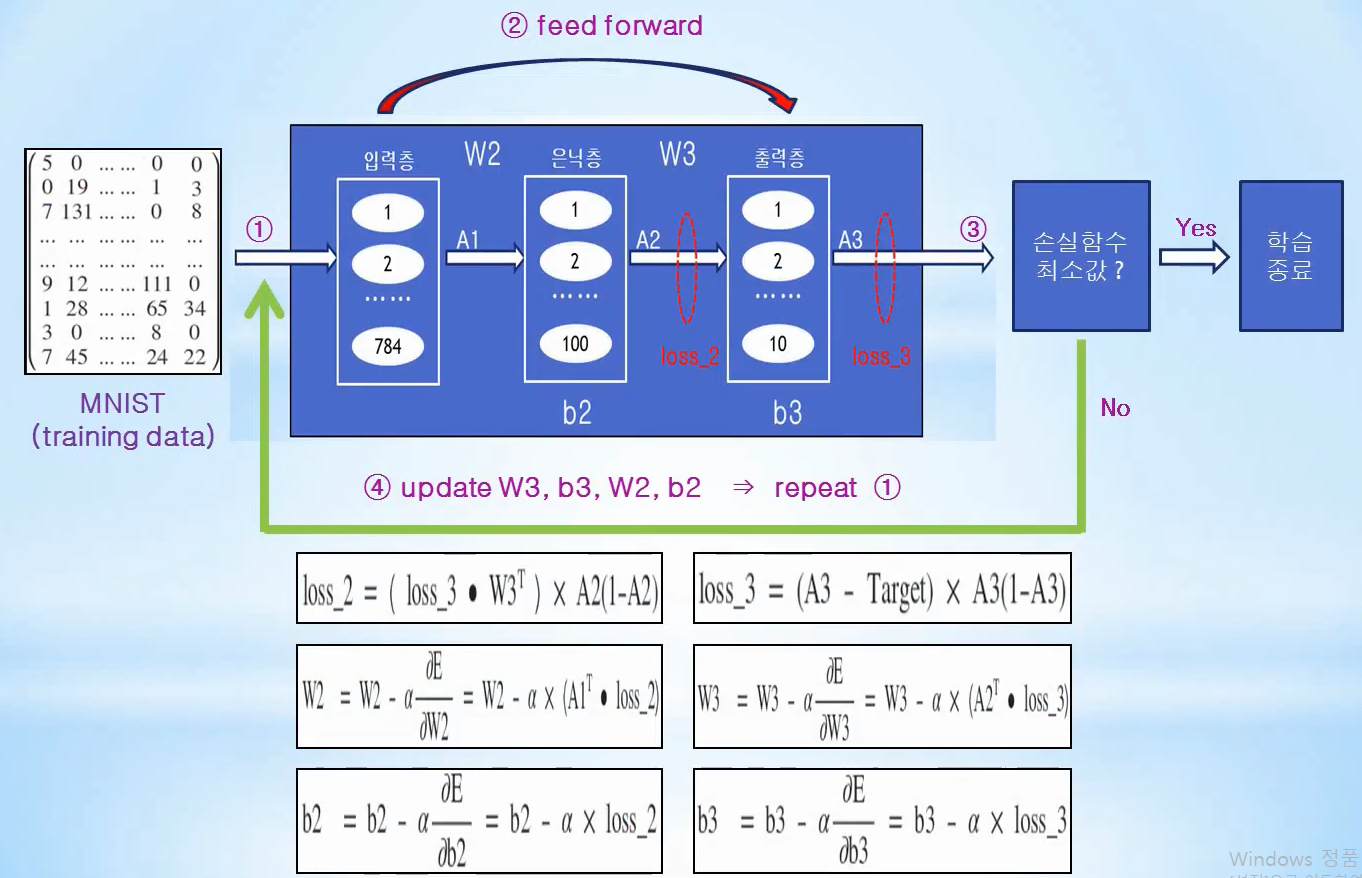
MNIST 인식을 은닉층 1개를 가진 신경망에 오차역전파 공식을 활용하여 구현해보겠습니다.
구현 과정의 설명에는 앞서 자주 사용한 함수들의 설명은 생략하고, 새롭게 구현되는 함수들에 초점을 두고 살펴보겠습니다.
- 구현 코드 Neural Network (init)

입력받은 input, hidden, output nodes, learning rate 변수들의 초기화와 사용되는 가중치 W, 바이어스 b, 선형회귀 값 Z, 출력값 A를 정의 및 초기화하는 과정입니다.
- 구현 코드 Neural Network (feed_forward, loss_val)

feed_forward 함수는 업데이트된 가중치와 바이어스 값을 통해 각 층의 출력값을 구하고 cross-entropy를 이용하여 최종오차 값을 구하는 함수입니다.
loss_val 함수는 feed_forward 함수와 같은 형태로 현재 층의 오차를 출력하기 위해 사용됩니다.
- 구현 코드 Neural Network (feed_forward, loss_val)

train 함수는 앞선 강의에서 유도한 각 층의 가중치, 바이어스의 back-propagation 수식을 활용하여 업데이트 하는 과정이며, predict 함수는 training된 가중치와 바이어스를 이용하여 미래값을 예측하는 함수로 앞서 사용한 형태와 거의 일치하지만 one-hot encoding을 사용하기 때문에 argmax 함수를 이용함을 알 수 있습니다.
- 구현 코드 Neural Network (accruacy)

accuracy 함수는 정확도를 측정하기 위한 함수로 test_data의 1열에 위치한 정답값을 label로 저장해두고 2열부터 785열까지 위치한 0~255값의 입력 값들을 그대로 사용하면 overflow가 발생할 수 있기 때문에 정규화시켜 저장합니다.
이후 예측 후의 값이 label 값과 같다면 matched_list에, 다르다면 not_matched_list에 추가한 후 이를 통해 일치율을 계산합니다.
- 구현 코드 Back-Propagation을 이용한 MNIST

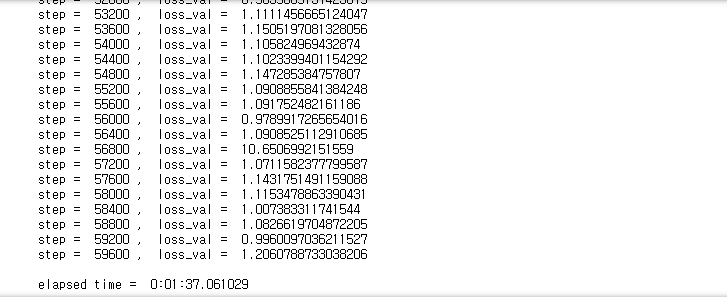

784개의 입력노드, 100개의 은닉노드, 10개의 출력노드, 0.3의 learning rate로 Neural Network Class nn을 생성합니다. 이렇게 생성된 nn class에 대하여 60000번의 training이 진행되는데 우선 입력 데이터와 정답 데이터에 대해 정규화가 진행됩니다. 이후 정규화된 데이터를 이용하여 트레이닝이 진행되며, epochs는 이러한 과정을 수행하는 횟수를 나타냅니다.
epoch를 1로 설정하고 training을 진행을 datatime 메서드를 통해 소요 시간을 측정해보니 약 1분 37초로 수치미분으로 MNIST를 수행했을 때의 비해 기하급수적으로 시간이 감소하였음을 확인하였습니다.
또한 마지막으로 accuracy 함수를 통해 정확도를 측정해보니 94.08%로 epochs를 증가시킨다면 더 높은 정확도를 나타낼 것이라 예상할 수 있었습니다. (다른 트레이닝에서도 절대적일 것이진 않을 것이라고 생각됩니다.)
여기까지 딥러닝 공부을 하면서 Linear Regression을 사용하였지만 이 가중치, 바이어스 등을 어떻게 설정할 것인지, Learning rate나 은닉층의 수, 노드의 개수는 어떻게 설정해야 높은 정확도가 나올 것인지, 어떤 활성함수를 사용할 것인지.... 등등의 많은 궁금증이 들고, 이러한 알고리즘에 대해서 알아가고 싶다는 생각이 많이 드는 것 같습니다.
이 부분들은 앞으로 공부해야가야할 방향이고, 정말 얕은 수준이라고 할 수 있겠지만 딥러닝의 기본적인 틀을 공부하는 기간은 제게 매우 유익한 시간이었습니다..
출처 : 유튜브 NeoWizard 채널 머신러닝/딥러닝 강의
