
저번에는 여러 가지 DB 엔진의 복제 형태에 대해서 알아봤습니다.
그러면 오늘은 MySQL의 복제 방식에 대해서 조금 더 알아보겠습니다.
복제 기준
레플리카는 원본을 어떻게 복사해올까요??
원본 서버의 테이블을 그대로 복사해 와서 레플리카에 덮어 씌우는 걸까요??
아닙니다!!
레플리카DB는 원본 DB의 바이너리 로그을 기반으로 복제를 실시합니다!!
바이너리 로그 : DB의 모든 변경사항이 로그 파일에 순서대로 기록되어 있는 파일
그럼 하나 하나 알아봅시다!!
복제의 타입
우선 복제를 하려면 어디서 부터 복제를 해야할지 알아야겠죠!! 즉, offset을 알아야합니다!!
그리고 이 offset을 관리하는 방법은 2가지 입니다.
바이너리 로그 파일 위치 기반
소스 서버의 바이너리 로그의 로그 파일명과 offset 을 이용한 복제 방식입니다.
단 이 방식은 소스 서버 내에서만 파일의 위치를 알 수 있다는 단점이 존재합니다.
만약 현재의 메인 서버가 죽고 다른 레플리카가 메인 서버로 승격된다고 해도, 이전의 offset을 가지고는 전에 있던 메인 서버가 어디까지 읽었는지 알 수 있는 방법이 없습니다.
그 offset은 그저 이전의 메인 서버에서만 유효한 offset 이니까요.
동일한 이벤트를 처리한다고 해서 레플리카에서도 동일한 파일, 동일한 위치에 저장된다는 보장이 없기 때문입니다!
GTID 기반 복제
위의 단점을 상쇄하기 위해서 나온 방식이 글로벌 트랜잭션 기반 복제 방식입니다.
MySQL 5.6 버전 이상부터 채택된 방식으로, 소스 서버 및 소스 서버를 복제하고 있는 모든 레플리카 서버들이 동일한 식별값을 가지고 있습니다.
그렇기 때문에 레플리카가 승격되더라도 식별자는 그대로 가져다가 쓸 수 있기 때문에 복구 되는데 걸리는 시간이 짧아지는 장점이 존재하죠!!

- 원본 DB 에서 데이터의 변경이 일어난다
바이너리 로그 덤프 스레드가 해당 이벤트를 읽은 뒤 이를 레플리카 DB로 전송한다- 레플리카 서버의
레플리케이션 I/O 스레드는 해당 이벤트를 수신한 뒤 이를 레플리카 서버에서 로컬에 존재하는릴레이 로그에 기록한다 레플리케이션 SQL 스레드는릴레이 로그를 읽은 뒤 이를 레플리카 서버의 데이터에 반영을 한다
위의 과정을 거쳐서 이루어 집니다!!
복제 포맷(Replication Foramt)
Statement-based binary logging(SBR)
Statement 기반 복제 방식으로 복제를 진행하면 소스 DB는 바이너리 로그에 SQL을 그대로 기록합니다.
그러면 레플리카 DB는 해당 바이너리 로그(SQL)을 그대로 읽어오고 가져온 SQL문을 실행시켜서, 복제를 진행합니다.
장점
- 검증된 기술이다.
- 로그 파일에 적히는 내용이 상대적으로 적다.
- 모든 변경 SQL 실행문이 기록되어 있으므로 DB 감사에 사용할 수 있음.
만약 하나의 SQL문이 많은 row를 수정한다고 하더라도 SQL 문 하나만 기록되기 때문에 이 방식으로 복제를 진행하면 바이너리 로그 파일의 크기가 뒤에 나올 Row-Based Logging 방식보다 작다는 장점이 존재합니다.
단점
- SBR에 안전하지 않은 statement 들이 존재한다.
- 특히 비확정적 statement는 SBR 방식에서 복제를 어렵게 한다. 예를 들면...
- 로드 가능한 함수 또는 저장된 프로그램에 의존하는 statement
-LIMIT을 사용하지만,ORDER BY를 사용하지 않는DELETE, UPDATE문
-NOWAIT, SKIP LOCKED옵션을 사용해서 읽기 statement에 락을 거는 경우
- 그리고 레플리카에서 다음함수들을 사용할 경우
-LOAD_FILE()
-UUID(), UUID_SHORT()
-FOUND_ROWS()
-SYSDATE()
-GET_LOCK()
-IS_FREE_LOCK()
-IS_USED_LOCK()
-MASTER_POS_WAIT()
-RAND()
-RELEASE_LOCK()
-SOURCE_POS_WAIT()
-SLEEP()
-VERSION()
만약 안전하지 않은 statement를 실행하면 다음과 같은 경고를 로그에 기록합니다
[Warning] Statement is not safe to log in statement format.
Row-based logging(RBR)
위의 Statement-based logging 방식과는 다르게 원본 DB는 SQL로 인해 변경된 각 테이블의 row들을 바이너리 로그 파일에 기록합니다.
MySQL 8.0에서는 RBR이 기본 복제 방법입니다.
장점
- 모든 변경사항에 대해서 복제가 가능하고 가장 안전한 형태의 복제이다.
- 다음과 같은 statement들에 대해서 원본 DB에 대해 더 적은 row에 락이 걸리므로 높은 동시성을 보장한다
-INSERT ... SELECT
-AUTO_INCREMENT가 포함된INSERT
- 키를 사용하지 않거나 대부분의 평가된 row들을 변경하지 않는WHERE절이 포함된UPDATE나DELETE INSERT, UPDATE, DELETEstatement들이 레플리카 DB에서 더 적은 락을 차지한다.
단점
- 하나의 statement 가 많은 행을 수정할 경우, 바이너리 로그 파일의 크기가 커진다
- 레플리카 입장에서는 무슨 statement 를 수행됐는지 알 수 있는 방법이 없다
---base64-output=DECODE-ROWS랑--verbose옵션을 사용해서 mysqlbinlog를 변경하면 볼 수 있다. - 스토리지 엔진으로
MyISAM을 사용하는 테이블의 경우, SBR 방식을 사용할 때 보다 레플리카 서버에 더 강력한 수준의 락을 사용해야 함.
Mixed
Mixed 방법은 위의 두 가지 방법을 적절히 섞어서 사용하는 방법이라고 할 수 있습니다.
mixed 방법은 NDB 클러스터에서 기본적으로 채택하는 방식입니다!
NDB Cluster is the distributed database system underlying MySQL Cluster. It can be used independently of a MySQL Server with users accessing the Cluster via the NDB API (C++). "NDB" stands for Network Database.
해당 방식은 기본적으로 SBR 방식으로 복제를 진행하다가 다음과 같은 상황에서는 RBR 방식으로 진행됩니다.
- 함수에
UUID()함수가 포함되어 있을 때 AUTO_INCREMENT열이 있는 하나 이상의 테이블이 업데이트되고 트리거 또는 저장된 기능이 호출되는 경우- 뷰의 본문에서 행 기반 복제가 필요한 경우 또는 뷰를 작성하는 경우.
- 실행가능한 함수가 포함되어 있을 때
FOUND_ROWS(),ROW_COUNT()이 사용된 경우USER(),CURRENT_USER()가 사용된 경우- 연관된 테이블 중 하나가 mysql DB 의 로그 테이블인 경우
LOAD_FILE()함수가 사용된 경우- statement 가 하나 이상의 시스템 변수를 사용한 경우. 단, 다음 명령어들이 세션 범위에서 사용된 경우 로그 기록 방식을 변경하지 않음
-auto_increment_increment,auto_increment_offset
-charset_set_client,charset_set_connection,charset_set_database,charset_set_server
-collation_connection,collation_database,collation_server
-foreign_key_checks
-identity
-last_insert_id
-lc_time_names
-pseudo_thread_id
-sql_auto_is_null
-time_zone
-timestamp
-unique_checks
각 스토리지 엔진 별 차이
마지막으로 스토리지 엔진 별로 지원하는 복제 방식에 대한 정리입니다.
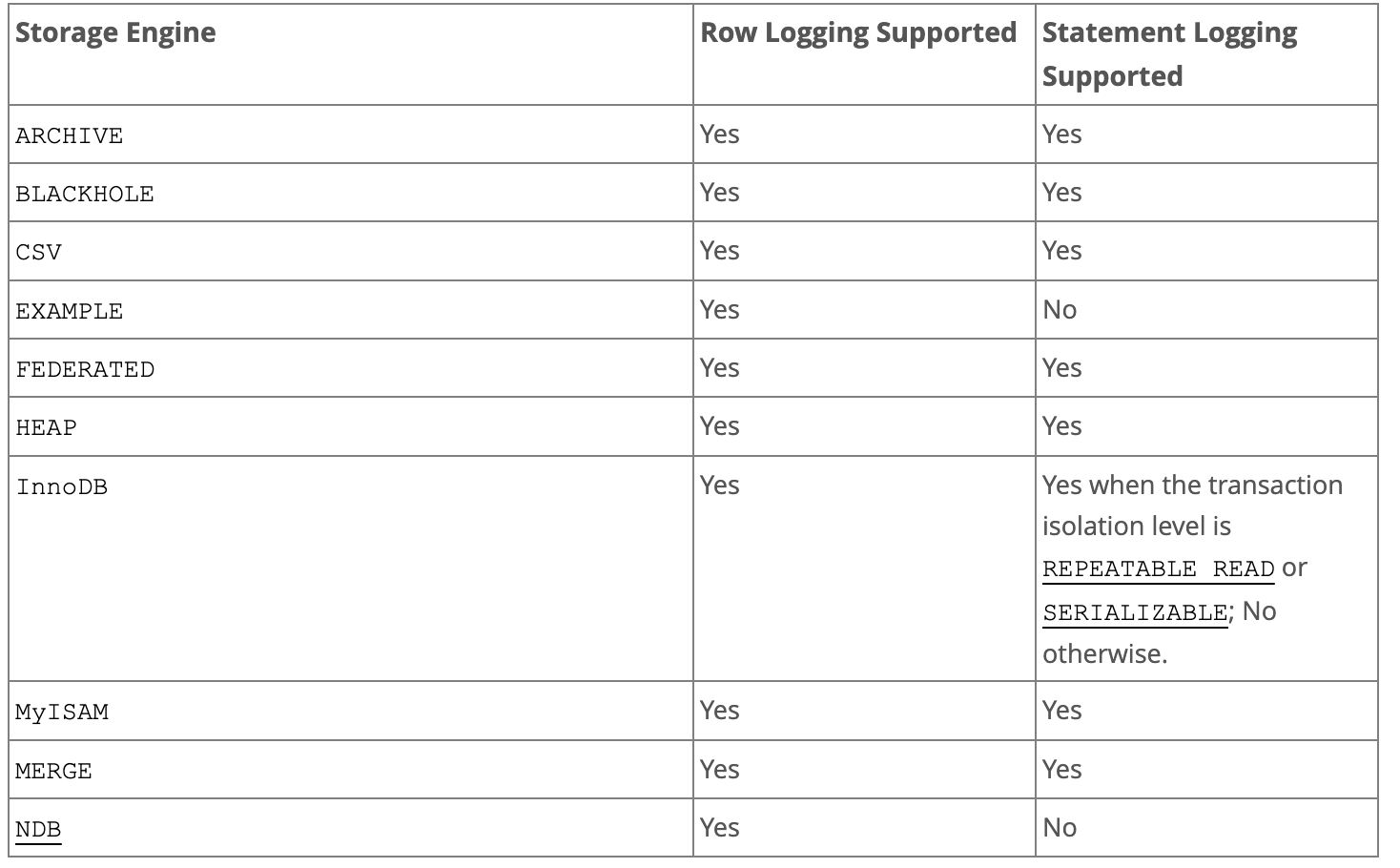
복제 방식
Async Replication
MySQL이 기본적으로 사용하는 방식으로 비동기적으로 소스와 레플리카 사이에서 복제를 진행하는 방식입니다.
소스 서버의 덤프 스레드와 연결되어 있는 레플리카 서버의 I/O 스레드는 소스서버로 요청을 보냅니다.
그러면 덤프 스레드가 바이너리 로그를 레플리카 서버로 전달해주죠
그리고 레플리카 서버는 해당 바이너리 로그를 로컬 스토리지 내부에 저장하고 있다가
복제를 진행하게 됩니다.

단 비동기적으로 진행되기 때문에 메인 서버는 레플리카 서버의 복제 성공 여부를 확인하지 않고 트랜잭션을 종료(commit)하게 됩니다.
그렇기 때문에 쓰기 성능에 영향은 미치지 않습니다.
하지만 복제를 비동기적으로 진행하기 때문에 레플리카 서버와 메인 서버 사이에서의 데이터 정합성 문제도 생길 수 있으며, 네트워크 속도 등의 여러가지 이유로 복제가 늦어질 수도 있습니다.
Semi-Sync Replication
Semi-sync 방식은 위와 는 다르게 메인 서버가 레플리카 서버로 부터 ack를 기다리게 됩니다.
ack를 수신해야 commit을 하게 되죠!
레플리카 서버는 수신받은 바이너리 로그를 로컬 스토리지의 릴레이 로그에 기록하고 나면 ack 를 전송하게 됩니다.
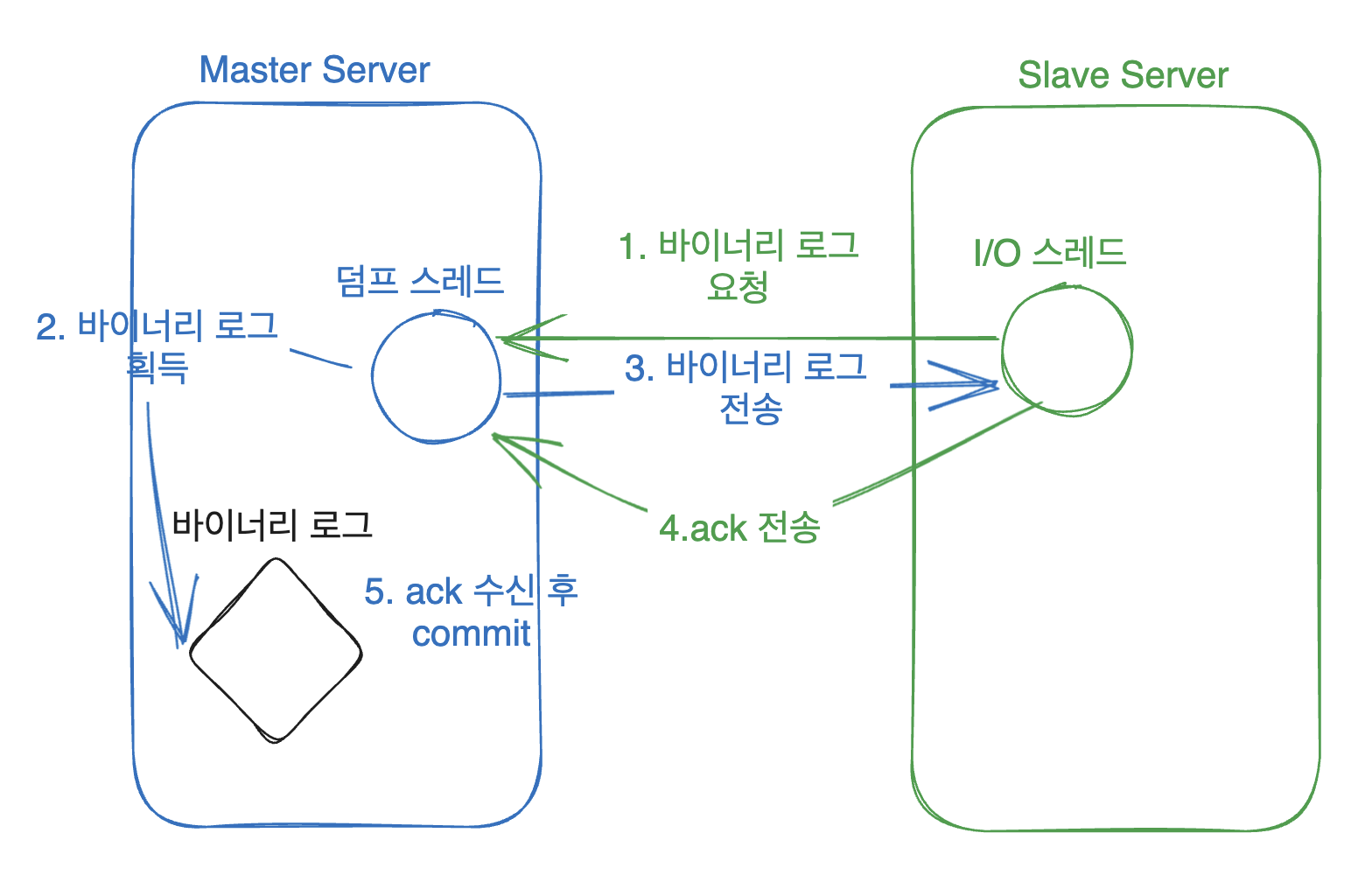
비동기 방식에 비해 한 단계가 더 추가된 모습입니다!!
이와 같이 한 단계가 추가 되었기 때문에 소스 서버의 쓰기 성능에 약간 영향은 미치지만, 완전 동기화 방식보다는 성능 저하가 덜하는 장점이 존재합니다.
또한 비동기 방식에 비해서 소스 서버와 레플리카 서버 간의 데이터 정합성도 어느 정도 보장된다고 할 수 있죠.
참고

잘 봤습니다. 좋은 글 감사합니다.