
오늘은 스프링에서 Bulk Insert를 구현하려면 어떻게 해야 하는지 한 번 알아보도록 하겠습니다
우선 저장할 엔티티를 하나 만들어 보겠습니다.
Post.java
@Entity @Setter @Getter
@Table(name = "posts")
@NoArgsConstructor
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private String name;
private String content;
@Builder
public Post(Long id, String name, String content) {
this.id = id;
this.name = name;
this.content = content;
}
}여기서 비즈니스의 요구에 의해서 여러 개의 Post를 저장해야 한다고 해 봅시다!
그러면 보통 JPA Repository의 saveAll() 메소드를 떠올리겠죠!!
SaveAll()
SimpleJpaRepository.java
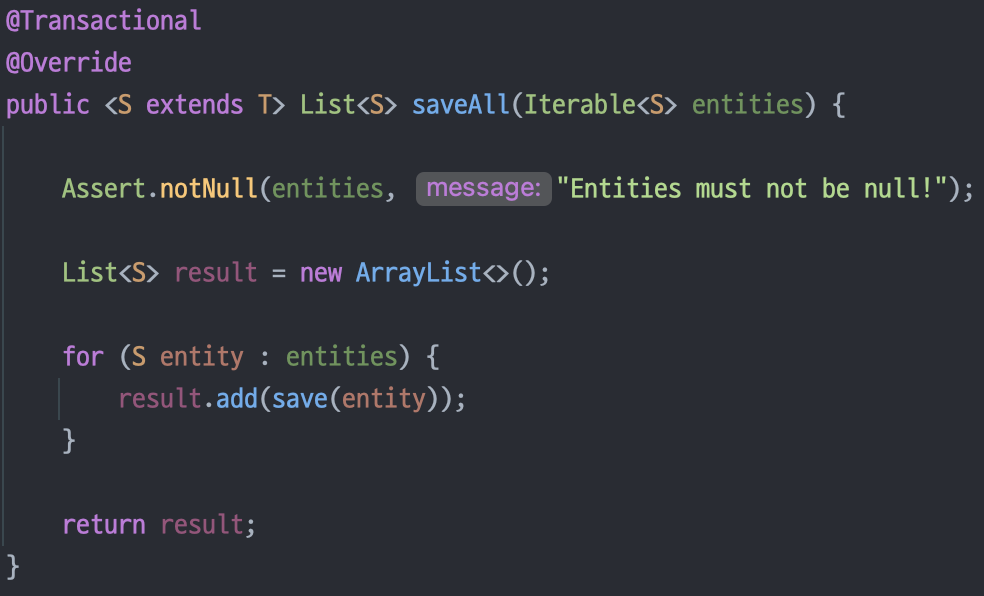
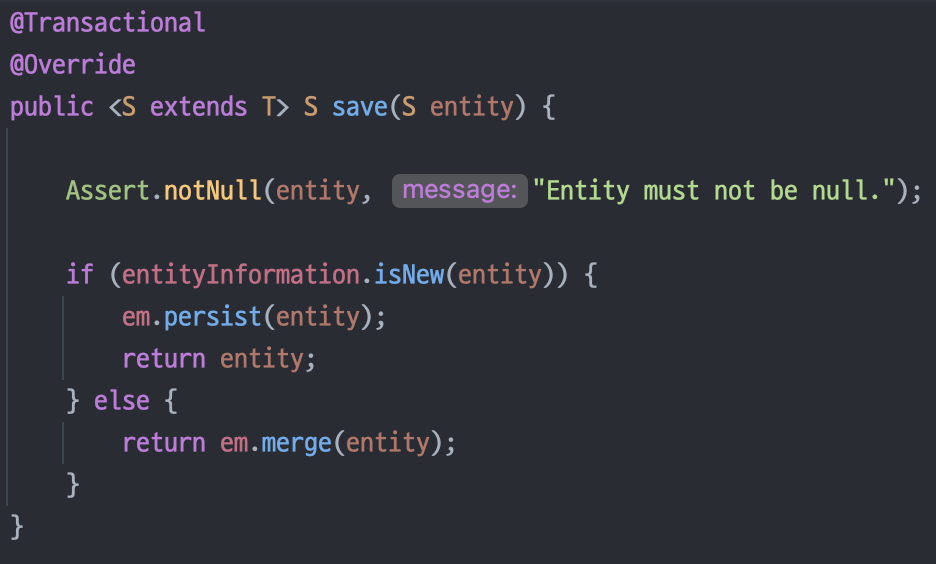
하지만 보시다 시피 saveAll() 메소드는 그저 인자로 들어온 Iterable<>을 순회하면서 save() 메소드를 여러 번 호출해주는 역할만 해 줄 뿐입니다.
이러면 쿼리 문 자체가 여러 번 나가게 되어서 매우 나쁜 성능을 자랑(??)하죠!!
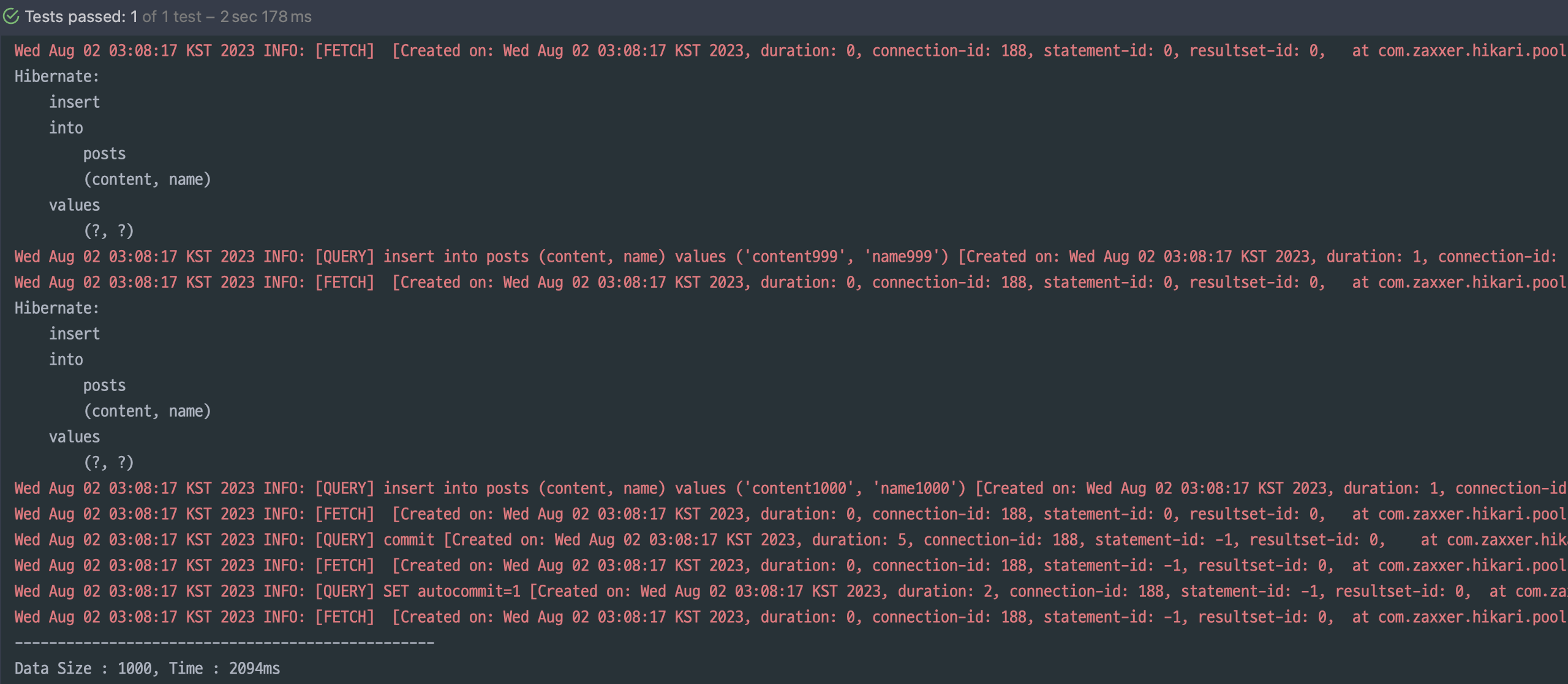
단순한 쿼리가 여러 번 날아간다
그리고 1000개의 데이터를 넣는데 2초나 걸린다.
쿼리를 한 번에 처리하면 문제가 해결됩니다!!
기존의 단일 쿼리
INSERT INTO POSTS (content, name) VALUES (content1, name1);
INSERT INTO POSTS (content, name) VALUES (content2, name2);
INSERT INTO POSTS (content, name) VALUES (content3, name3);Bulk Insert
INSERT INTO POSTS (content, name) VALUES (content1, name1), (content2, name2), (content3, name3);아주 쉬운 해결방법입니다!
그러면 JPA에서 어떻게 하면 해당 쿼리가 나갈 수 있게 할 수 있을까요??
JPA Bulk Insert
아쉽게도 현재의 코드로는 Bulk Insert를 수행할 수 없습니다.

Hibernate 는 ID 생성 전략이 Identity 일 경우에는 Bulk Insert를 JDBC 수준에서 불가능 하게 한다는군요...
그렇다면 해결 방법은 크게 두 가지로 생각됩니다!!
1. ID 생성 전략을 변경한다
2. JPA가 아닌 다른 방식으로 쿼리는 날린다.
우선 1번 방법으로 진행해보겠습니다!!
ID 전략 변경
JPA 에서 ID 생성 전략은 크게 3가지 입니다.

그리고 MySQL 은 Sequence 가 존재하지 않으므로 채택할 수 있는 전략은 Table 하나만 남게 되죠
Auto 가 남았다고요?? MySQL 을 사용하면서 ID 생성 전략을 Auto 로 할 경우 자동으로 Table 로 결정되게 됩니다

그렇다면 간단한게 생성전략만 바꿔서 saveAll() 을 진행하면 어떻게 될까요??
@Entity @Setter @Getter
@Table(name = "posts")
@NoArgsConstructor
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.TABLE) // 바뀐 부분!!
private String name;
private String content;
@Builder
public Post(Long id, String name, String content) {
this.id = id;
this.name = name;
this.content = content;
}
}getPosts();
List<Post> getPosts(){
List<Post> posts = new ArrayList<>();
for (int i = 1; i < SIZE + 1; i++) {
posts.add(Post.builder()
// .id((long)i) // JDBC를 사용할 때는 주석을 풀어줄 부분
.name("name" + i)
.content("content" + i)
.build());
}
return posts;
}saveAll():
@Test
void saveAll() {
Long start = System.currentTimeMillis();
postRepository.saveAll(getPosts());
Long end = System.currentTimeMillis();
System.out.println("-------------------------------------------------");
System.out.println("Data Size : " + SIZE + ", Time : " + (end - start) + "ms");
}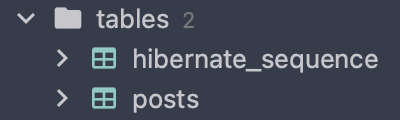
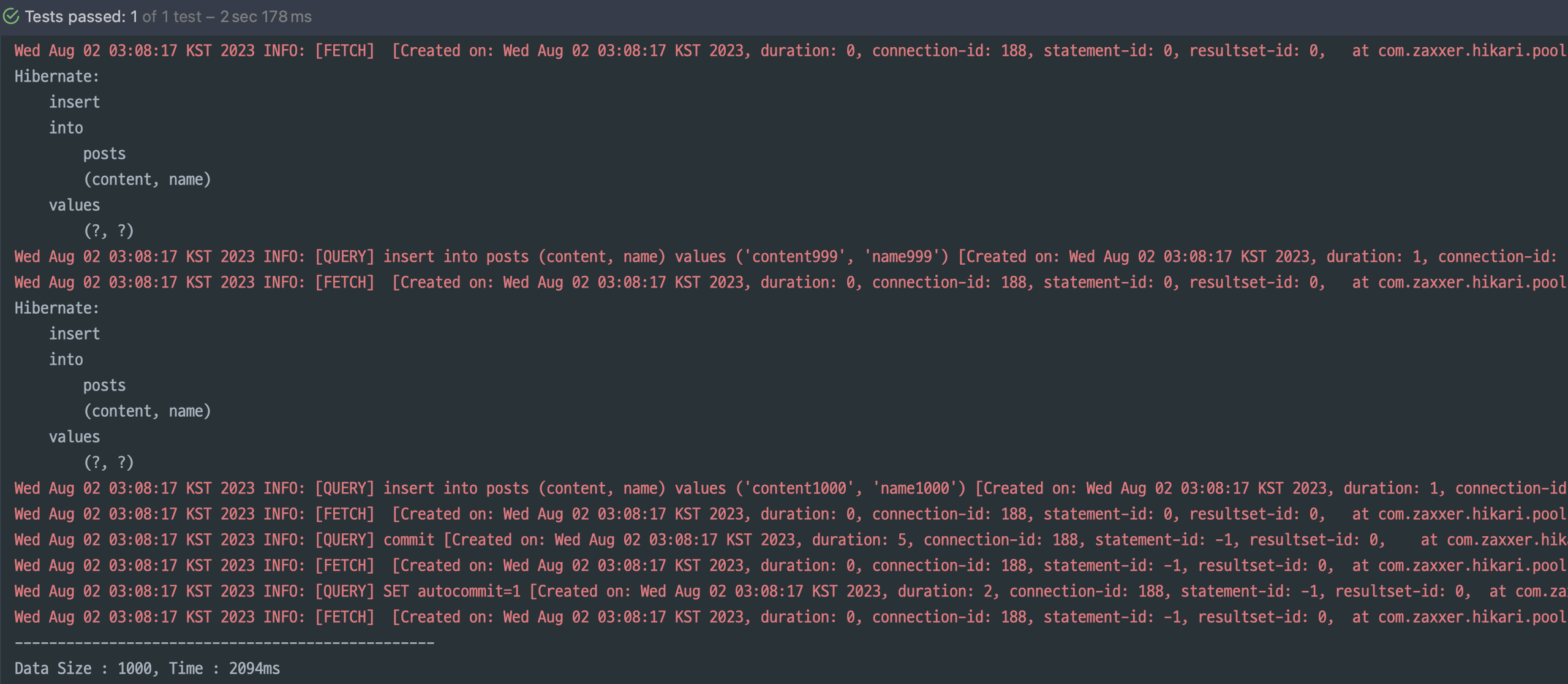
신기하게도 hibernate_sequence 라는 이름의 테이블이 생성되었고
매번 쿼리가 나갈때 마다 해당 테이블을 참조하면서 INSERT 쿼리가 나가는 모습을 볼 수 있습니다!!
아마도 해당 테이블을 참조하면서 다음 값을 가져오고 그 값을 ID로 지정하는 것 같습니다.
날아간 쿼리는 확인하니 배치성으로 쿼리가 날아간 것 같지만....
시간상으로는 전혀 이득을 보지 못하고 있군요..
아무래도
1. hibernate_sequence 테이블에서 다음으로 사용할 ID next_val을 조회
2. 다음 엔티티의 ID값을 설정하고, sequence_table의 next_val의 값을 +1한 값으로 수정
이런식으로 DB를 계속 찌르다 보니 성능 저하가 심한 것 같습니다.
애초에 TABLE 전략이 다른 테이블을 참조하는 것이다 보니... 근본적으로 해결이 불가능 할 것 같습니다.
아쉽지만 다른 방법을 찾아봐야 겠군요.
JPA가 아닌 다른 방법을 사용한다
그럼 JPA가 아닌 다른 방법을 생각해보죠
JDBC를 사용해 보는 거죠!!
저는 그럼 NamedParameterJdbcTemplate 에서 지원하는 batchUpdate 메소드를 사용해 보도록 하겠습니다

PostJdbcRepository.java
@Repository
@RequiredArgsConstructor
public class PostJdbcRepository {
private final NamedParameterJdbcTemplate jdbcTemplate;
private static final String TABLE = "posts";
public void bulkInsert(List<Post> posts) {
String sql = String.format("""
INSERT INTO `%s` (id, name, content)
VALUES (:id, :name, :content)
""", TABLE);
SqlParameterSource[] params = posts
.stream()
.map(BeanPropertySqlParameterSource::new)
.toArray(SqlParameterSource[]::new);
jdbcTemplate.batchUpdate(sql, params);
}
}batchUpdate에 들어갈 2가지 파라미터를 준비해 줍니다
BeanPropertySqlParemeterSource 를 사용해 주면 쿼리문 뒤에 파라미터들을 매핑시켜줘서 리스트 안에 있는 데이터들을 쿼리문의 파라미터로 매핑시킨 후, 쿼리 문을 확장시켜 줍니다.
batchUpdate()
@Test
void batchUpdate() {
Long start = System.currentTimeMillis();
postJdbcRepository.bulkInsert(getPosts());
Long end = System.currentTimeMillis();
System.out.println("-------------------------------------------------");
System.out.println("Data Size : " + SIZE + ", Time : " + (end - start) + "ms");
}실행 결과는 다음과 같습니다.

와우~
이전에 진행했던 테스트는 10초 걸릴때도 있고 짧아도 2초가 걸리는데
이번에는 100ms 도 걸리지 않았군요!!
매우 인상적입니다!!
앞으로 ID 생성 전략이 IDENTITY를 유지하면서 많은 양의 데이터를 넣어야 할 경우에는 JDBC를 사용해서 데이터를 삽입해 주면 좋을 것 같군요!
번외 / MySQL에서 Id generation strategy 가 GenerationType.SEQUENCE 경우에는 어떨까?
MySQL 은 Sequence 가 존재하지 않기 때문에 해당 전략을 사용할 수는 없겠지만...
시도는 해 볼수 있잖아요??
@Entity
@Setter @Getter
@Table(name = "posts")
@NoArgsConstructor
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Long id;
private String name;
private String content;
@Builder
public Post(Long id, String name, String content) {
this.id = id;
this.name = name;
this.content = content;
}
}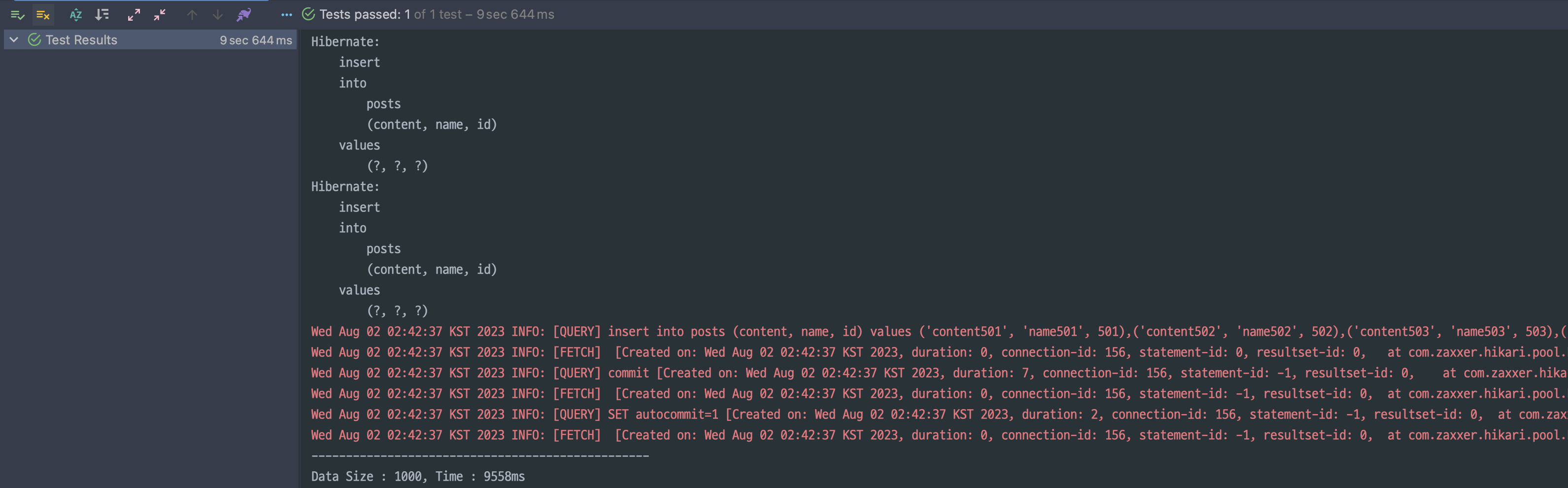
Table 전략과 동일하게 hibernate_sequence 테이블이 생성되었습니다.1000개의 데이터를 넣는데 걸린 시간은 총 9558ms 가 걸렸고요
그런데 여기서 다른 DB 처럼 살짝 손을 봐주면...
@Entity
@Setter @Getter
@Table(name = "posts")
@SequenceGenerator(
name = "USER_SEQ_GENERATOR"
, initialValue = 1
, allocationSize = 1000
)
@NoArgsConstructor
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "USER_SEQ_GENERATOR")
private Long id;
private String name;
private String content;
@Builder
public Post(Long id, String name, String content) {
this.id = id;
this.name = name;
this.content = content;
}
}무려 320ms 가 나오는 군요!!
위에서 수정한 부분에서 중요한 부분은 allocationSize입니다.
sequence를 한 번 호출할 때 마다 증가하는 수입니다.
기본값은 50이고 쉽게 말해 한 번에 처리할 작업의 양이라고 저는 받아들이는 값입니다.
저는 이 값을 1000으로 설정해서 성능최적화를 꾀한것이죠!!
DB를 여러번 찌르지 않기 때문에 이런 성능이 나오는 것 같습니다.
결국 DB를 적게 찔러야 하는군요
만약 다른 TABLE 전략을 사용해야 한다면 이런식으로 allocationSize를 적절히 조절해가면서 부하를 줄일
수 있을 것 같습니다!!
그런데 어떤 데이터를 넣어야 하지...
대용량의 데이터를 넣는 스킬을 얻었는데.... 무슨 데이터를 넣어야 할까요???
현업이라면 데이터가 많겠지만 학생이나 취준생의 입장에서는 다량의 데이터를 만들어서 넣어야 할텐데 말이죠
그 문제는 제 다른 포스팅 데이터가 필요해 를 참고해 주시면 좋을 것 같아요!!
참고

감사합니다. 이런 정보를 나눠주셔서 좋아요.