1. SQL data definition
데이터베이스에서 릴레이션의 집합은 데이터 정의 언어(DDL)를 이용하여 시스템에 명시되어야 한다. SQL DDL은 릴레이션의 집합뿐만 아니라 다음을 포함하는 각 릴레이션들에 관한 정보도 명시할 수 있게 한다.
- 각 릴레이션의 스키마
- 각 속성들과 관련된 값들의 타입
- 무결정 제약조건(integrity constraint)
- 각 릴레이션에서 유지해야 할 인덱스들의 집합
- 각 릴레이션의 보안과 권한 정보
- 각 릴레이션의 디스크에서의 물리적인 저장 구조
1.1 기본 타입
- char(n) : 사용자가 지정하는 길이 n을 갖는 고정 길이 문자열
- varchar(n) : 사용자가 지정하는 최대 길이 n을 갖는 가변 길이 문자열
- int : 정수
- smallint : 작은 정수
- numeric(p,d) : 사용자가 지정하는 정확도(precision)을 갖는 고정 소수점 수(fixed-point number). 수는 p개의 숫자(부호 포함)로 구성되어 있고, p개의 숫자에서 d개는 소수점의 오른쪽에 있다. 따라서 numeric(3,1)은 44.5는 정확히 저장하지만, 444.5 혹은 0.32는 이 타입으로는 정확히 저장할 수 없다.
- float(n) : 적어도 n개의 숫자의 정확도를 가지는 이동 소수점 수
char 타입과 varchar 타입을 비교할 때, 비교하기 전에 길이를 같게 하기 위해 varchar 타입에 여분의 공백이 더해질 것으로 기대할 것이다. 하지만 이러한 일은 데이터베이스 시스템에 따라 일어날 수도 있고 일어나지 않을 수도 있다. 결과적으로 char 타입 속성 A, varchar 타입 속성 B에 "AVI"라는 값이 저장되었다고 하더라도 A=B 비교가 거짓이라는 결과로 나타날 수도 있다. 이러한 문제를 피하기 위해 char 타입 대신 varchar 타입을 사용하는 것이 낫다.
1.2 기본 스키마 정의
create table 명령을 사용하여 SQL 릴레이션을 정의할 수 있다. 다음의 명령은 department 릴레이션을 데이터베이스에 만든다.
create table department
(dept_name varchar(20),
building varchar(15),
budget numeric(12,2),
primary key(dept_name));create table 명령의 기본적인 형태는 다음과 같다.
create table r
(A1 D1,
A2 D2,
...,
An Dn,
<integrity-contraint1>,
...,
<integrity-constraintN>);여기에서 r은 릴레이션의 이름이고, 각각의 Ai는 릴레이션 r의 스키마의 속성의 이름이며, Di는 속성 Ai의 도메인이다. 즉 Di는 Ai에 가능한 값을 제한하는 추가적인 제약조건에 덧붙여 속성 Ai의 타입을 구체화한다.
SQL은 다른 여러 무결성 제약을 지원한다. 이 절에서는 그 중 몇 가지만을 다룬다.
- primary key(A1, ... , An) : primary key 속성들은 null 값을 갖지 않고 유일하다. 즉 어떤 튜플도 primary key 속성에 대해 null 값을 가질 수 없고, 어떠한 두 개의 튜플도 모든 primary key 속성에 대해 같은 값을 가질 수 없음을 요구한다.
- foreign key(A1, ... , An) references s : foreign key 명세는 릴레이션에서의 어떤 튜플에 대한 속성의 값(A1, ... , An)이 반드시 릴레이션 s의 몇 튜플의 primary key 속성의 값으로 상응되어야 한다.
예를 들어, courses 테이블의 "foreign key(dept_name) references department"라는 선언은, 각각의 수업 튜플에 대해 그 튜플에 명시된 학과 이름은 반드시 department 릴레이션의 primary key 속성이 dept_name에 존재해야 한다고 설명한다. - not null : 속성에서의 not null 제약조건은 그 속성에 대해 null 값이 허용되지 않음을 명시한다. 달리 말하면, 제약조건은 그 속석의 도메인에서 null 값을 제외시킨다.
SQL은 무결성 제약을 위반하는 모든 데이터베이스 업데이트를 막는다. 예를 들어, department 릴레이션에 나타나지 않은 dept_nmae 값을 가지는 course 튜플의 삽인은 course에 대한 foreign key 제약을 위반하고, SQL은 그러한 삽입이 일어나는 것을 막는다.
1.3 명령문 종류
- insert문
insert into instructor values(10211, 'Smith', 'biology', 66000);- delete문
student 릴레이션의 모든 튜플들을 삭제함
delete from student;- drop문
릴레이션을 제거하기 위해 drop table 명령 사용. drop table 명령은 데이터베이스에서 제거될 릴레이션과 관련된 모든 정보들을 삭제함. delete문은 릴레이션 r을 남겨두지만, r의 모든 튜플들을 제거하는 것이고, drop문은 r의 모든 튜플뿐만 아니라 r의 스키마까지도 삭제한다.
drop table r;- alter문
alter table 명령어로 이미 존재하는 릴레이션에 속성을 추가할 수 있다. 릴레이션의 모든 튜플들에 대해 새로운 속성을 위한 값으로 null이 할당된다. 여기에서 A는 추가될 속성의 이름, D는 그 속성의 도메인이다. 또한 릴레이션에서 속성을 제거하기 위해 다음과 같은 명령문을 사용할 수 있다.
alter table r add A D;
alter table r drop A;2. SQL query의 기본 구조
SQL 표현의 기본 구조는 select, from, where의 세 개의 절로 이루어진다. 질의는 from 절에 나열된 릴레이션들을 입력으로 받고, where과 select 절에 명시된 동작을 수행해 결과로 릴레이션을 만들어낸다.
2.1 하나의 릴레이션에서의 질의
관계형 모델의 수학적 정의에서 릴레이션은 집합이다. 따라서 중복된 튜플은 릴레이션에서 나타날 수 없다. 실제로 중복을 제거하는 일은 시간이 걸리는 작업이기 때문에 SQL 표현의 결과에서 뿐만 아니라 릴레이션에서도 중복을 허용한다.
중복을 제거하기 위해서는 select 뒤에 distinct라는 키워드를 삽입한다.
2.2 다수의 릴레이션에서의 질의
- select절은 질의의 결과 속성들을 나열하는 데 사용된다.
- from절은 질의를 수행하기 위해 접근해야 하는 릴레이션들을 나열한다.
- where절은 from절에 있는 릴레이션의 속성들을 포함하는 조건이다.
from절은 그 절에 나열된 릴레이션들의 카티션 곱을 정의한다. 결과 릴레이션은 from절의 모든 릴레이션으로부터의 모든 속성을 다 가지고 있다. 예를 들어, instructor와 teaches 릴레이션의 카티션 곱의 릴레이션 스키마는 다음과 같다.
(instructor.ID, instructor.name, instructor.dept_name, instructor.salary, teaches.ID, teaches_course_id, teaches.sec_id, teaches.semester, teaches.year)카티션 곱은 서로 관계가 없는 instructor와 teaches의 튜플들을 결합한다. instructor의 각 튜플은 teaches의 다른 교수를 지칭하는 튜플들을 포함한 모든 튜플과 결합된다. 결과는 매우 큰 릴레이션이 될 수 있고, 그러한 카티션 곱을 만드는 것은 대부분 적합하지 않다.
대신에, where절의 술어조건은 카티션 곱에 의해 생성되는 조합들을 필요에 따라 걸러내기 위해 사용된다. 우리는 instructor와 teaches를 포함하는 질의가 instructor의 특정 튜플 t와, t가 참조하는 같은 교수를 가리키는 teaches의 튜플들을 결합할 것을 기대한다. 즉, 같은 ID값을 가진 teaches 튜플과 instructor 튜플을 연결시키길 원한다.
select name, course_id
from instructor, teaches
where instructor.ID = teaches.ID;보통 SQL 질의의 의미는 다음과 같이 이해할 수 있다.
1. from절에 나열된 릴레이션들의 카티션 곱을 생성한다.
2. 1번 과정의 결과에 대해 where절에 명시된 조건을 적용한다.
3. 2번 과정의 결과의 모든 튜플에 대해 select절에 명시된 속성을 출력한다.
2.3 자연 조인
instructor와 teaches 테이블로부터 정보를 결합하는 예시 질의에서, 일치 조건은 instructor.ID와 teaches.ID가 같아야 한다는 것이다. 이것들은 두 릴레이션에서 같은 이름을 가지는 유일한 속성이다.
이러한 경우에 SQL은 자연 조인이라는 기능을 제공한다. 자연 조인 명령은 두 개의 릴레이션에서 동작하고 하나의 릴레이션을 결과로 생산한다. 두 릴레이션에서 첫 번째 릴레이션의 각 튜플과 두 번째 릴레이션의 모든 튜플을 연결시키는 카티션 곱과는 다르게, 자연 조인은 두 릴레이션의 스키마에서 나타나는 속성의 값이 같은 튜플의 짝만을 고려한다. 즉, instructor와 teaches 릴레이션에서 instructor natural join teaches 는 instructor와 teaches의 튜플 둘 다 공통된 속성인 ID에 대해 같은 값을 가지는 짝만을 고려한다.
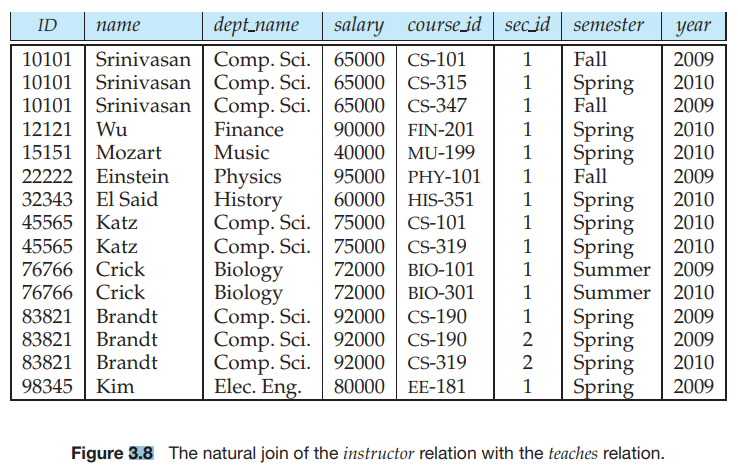
그림 3.8의 두 릴레이션의 스키마에 나타나는 속성들이 반복하지 않고 한 번만 표현됨을 유의해야 한다. 또한, 나열된 속성들의 순서에 주의해야 한다. 처음에는 두 릴레이션의 공통인 속성이 나타나고 두 번째에는 처음 릴레이션의 스키마에만 유일한 속성이 나타나고 마지막으로 두 번째 릴레이션의 스키마에 유일한 속성이 나타난다.
"모든 교수의 이름과 그들이 가르치는 수업의 제목을 나열하라"라는 질의에 답을 하길 원한다고 가정해보자. 이 질의는 다음과 같이 작성될 수 있다.
select name, title
from instructor natural join teaches, course
where teaches.course_id = course.course_id;instructor와 teaches의 자연 조인이 먼저 계산되고, 조인 결과의 course_id가 course 릴레이션의 course_id와 일치하는 튜플만을 추출하는 where절로부터 자연 조인의 결과와 course의 카티션 곱이 계산된다. 자연 조인 결과의 course_id는 teaches 릴레이션으로부터 나오는 것이기 때문에 where절의 teaches.course_id는 자연 조인 결과의 course_id를 참조한다.
반면, 다음 SQL 질의는 같은 결과를 계산해내지 않는다.
select name, title
from instructor natural join teaches natural join course;instructor와 teaches의 자연 조인은 (ID, name, dept_name, salary, course_id, sec_id) 속성을 갖고 있는 반면, course 릴레이션은 (course_id, title, dept_name, credits) 속성을 갖고 있다. 결과적으로, 이 둘의 자연 조인은 dept_name 속성 뿐만 아니라 course_id 값도 같아질 것을 요구한다. 그러면 이 질의는 교수가 소속된 학과가 아닌 다른 학과에서 가르치는 수업을 포함하는 모든 (교수 이름, 수업 제목) 짝을 제거할 것이다.
참고
Database System Concepts 6th edition 3장
