맥북에서 이미 여러 잡일을 돌리고 있던 터라 최대한 리소스가 적게 드는 놈으로 찾던 중
deepseek-r1:1.5b
라는 놈을 발견했다.
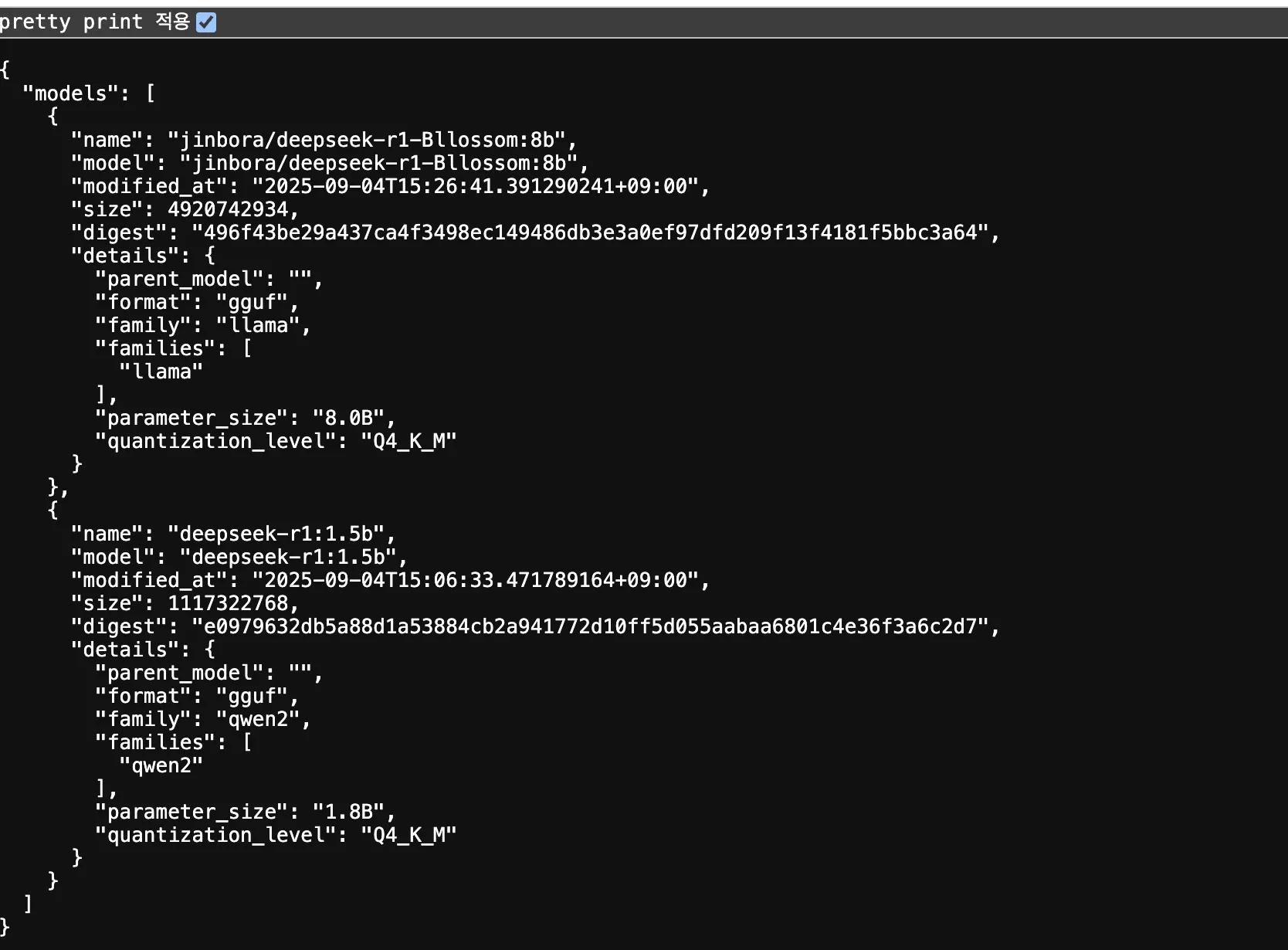
본인은 왜 deepseek-r1:1.5b를 설치하고 jinbora/deepseek-r1-Bllossom:8b 를 또 설치하였는가
아니,, 이놈이 글쎄 영어로도 답변을 잘 안해주고 한국어는 뭐 물건너 가버렸고 그냥 중국어로만 답변을 주길래 제가 못알아먹지 뭐에요
그래서 좀 찾아보니
https://ollama.com/jinbora/deepseek-r1-Bllossom:8b
이런게 있었는데

아 한국어용이다! 내가 원하던 이거잖아

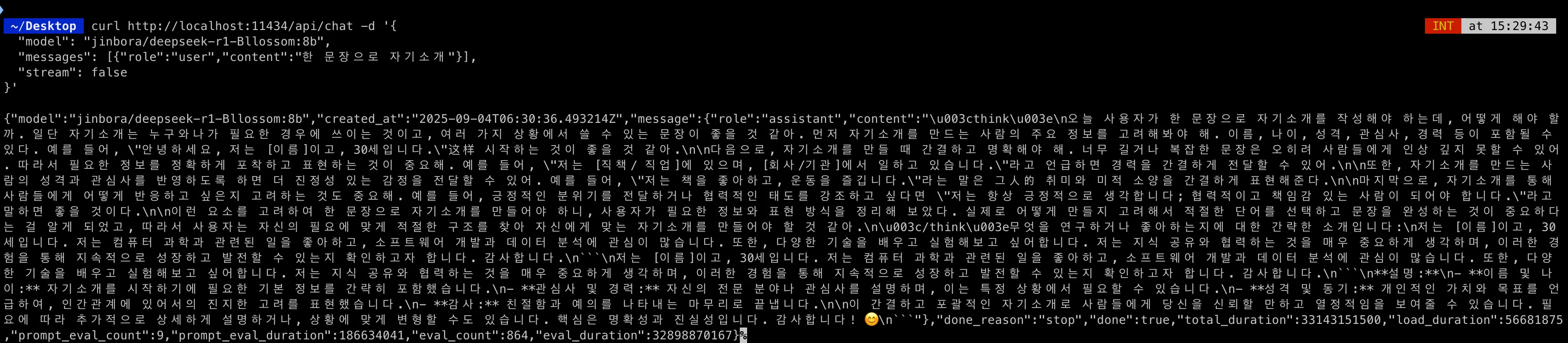
그래서 코드로도 돌려봤다.
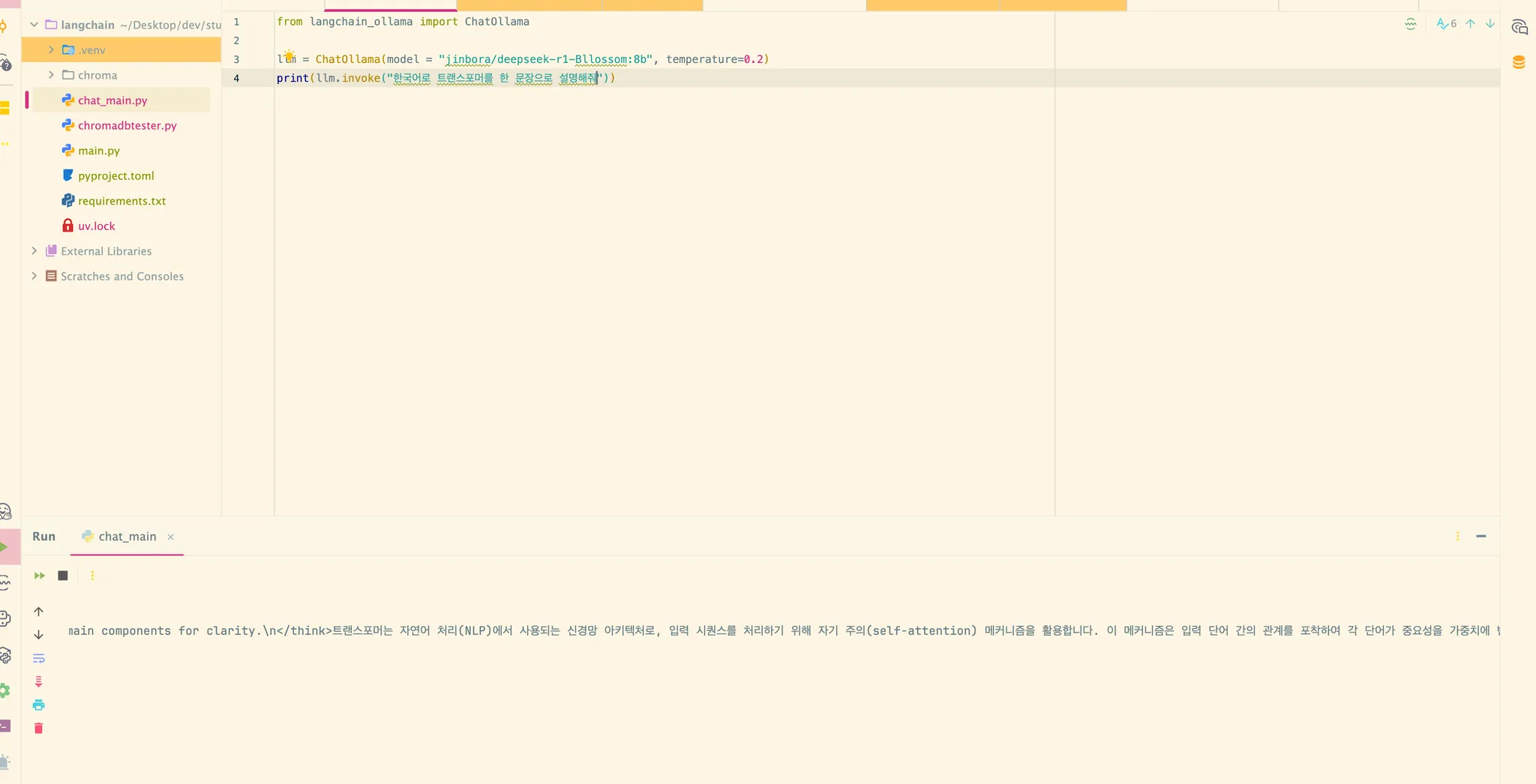
from langchain_ollama import ChatOllama
llm = ChatOllama(model = "jinbora/deepseek-r1-Bllossom:8b", temperature=0.2)
print(llm.invoke("한국어로 트랜스포머를 한 문장으로 설명해줘"))content="\nOkay, I need to explain Transformers in one sentence. Let me start by recalling what I know about them. They're a type of neural network used in NLP, right? They use something called self-attention. Oh yeah, attention mechanisms allow the model to focus on different parts of the input. So maybe I should mention that they process sequences and weigh words based on their relevance.\n\nWait, how do they work exactly? They have these layers where each word is transformed into vectors, and then there's a series of linear transformations. The self-attention layer helps capture relationships between words. Then there's a feed-forward neural network that combines the information. The final output is generated by predicting the next token.\n\nI should make sure to include key components: self-attention, multi-head attention, feed-forward layers, and their purpose in language modeling. Also, mention how they handle sequences by breaking them into tokens and predicting one at a time. Maybe add something about their effectiveness in tasks like translation or summarization.\n\nLet me structure this sentence to flow logically from input processing through attention to output generation. Avoid jargon where possible but still be precise. Check if I'm missing any important parts, like the training process or the architecture details. Hmm, maybe stick to the main components for clarity.\n트랜스포머는 자연어 처리(NLP)에서 사용되는 신경망 아키텍처로, 입력 시퀀스를 처리하기 위해 자기 주의(self-attention) 메커니즘을 활용합니다. 이 메커니즘은 입력 단어 간의 관계를 포착하여 각 단어가 중요성을 가중치에 반영하도록 합니다. 그런 다음, 다단계 선형 변환과 피드포워드 신경망이 결합되어 최종 출력을 생성하며, 이는 언어 모델링 및 번역과 같은 작업에서 뛰어난 성능을 보입니다." additional_kwargs={} response_metadata={'model': 'jinbora/deepseek-r1-Bllossom:8b', 'created_at': '2025-09-04T06:36:08.515241Z', 'done': True, 'done_reason': 'stop', 'total_duration': 15032511417, 'load_duration': 81918417, 'prompt_eval_count': 21, 'prompt_eval_duration': 216840750, 'eval_count': 393, 'eval_duration': 14725917708, 'model_name': 'jinbora/deepseek-r1-Bllossom:8b'} id='run--6cca7988-2b5b-46b9-beaf-8c0b15b56fc3-0' usage_metadata={'input_tokens': 21, 'output_tokens': 393, 'total_tokens': 414}
대충 생각은 영어로 하고 output은 한국어로 준다. 아 진짜 한국어가 나와서 나는 좋다.
