목표
- Spring Security 안의 PasswordEncoder와 엔드 유저 인증 과정에서 PasswordEncoder의 역할
- PasswordEncoder와 더불어 비밀번호를 다루거나 데이터베이스와 같은 저장소에 비밀번호를 저장할 때 준수해야 하는 표준
들어가기전에 앞서..
일단 현재 저는 비밀번호를 일반 텍스트 형식으로 취급하는 기본 PasswordEncoder를 사용하고 있습니다
@Bean
public PasswordEncoder passwordEncoder() {
return NoOpPasswordEncoder.getInstance();
}
-
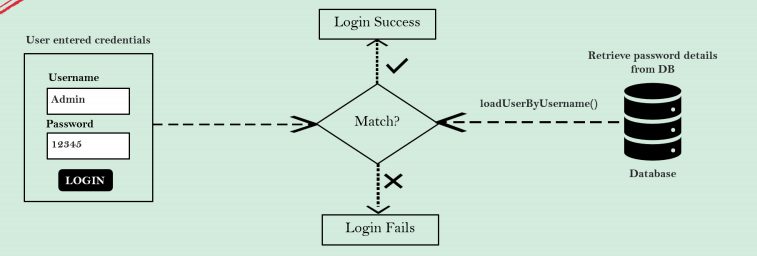
그림을 보면 가장 첫 단계에서 엔드 유저는 본인의 자격 증명인 유저 네임과 비밀번호를 입력합니다.
-
유저가 로그인 버튼을 클릭하자마자 Spring Security 프레임워크는 AuthenticationProvider 내부의 모든 로직을 실행하고 UserDetailsManager의 구현 클래스 내부에 있는
loadUserByUsername메소드의 도움으로 저장소에서 모든 정보를 불러오려고 할 겁니다 -
유저 정보를 불러온 다음 Spring Security는 엔드 유저가 제공한 비밀번호와 데이터베이스에서의 비밀번호를 비교합니다. 이 비교는 Java에서 두 문자열을 비교할 때 처럼 일반 텍스트 비교로 equals 메소드의 도움을 받습니다.
-
비밀번호가 일치한다면 로그인에 성공하고, 그 반대는 로그인에 실패할 겁니다
하지만 이 접근법에는 문제가 있습니다
우리의 모든 비밀번호는 일반 텍스트 형식으로 저장되어 있습니다
그게 왜 문제인데? 왜 데이터베이스에 비밀번호를 일반 텍스트로 저장할 수 없는데?
이 접근법의 문제점은 모든 운영 웹 애플리케이션에서 사용하는 데이터베이스의 경우 DBA와 같은 데이터베이스 관리자나 특권 유저가 당연히 운영 데이터베이스에 접근권을 가지며 고객 테이블이나 유저 테이블에 단순히 쿼리를 실행해 웹 애플리케이션에 등록된 모든 고객 또는 엔드 유저의 유저 네임과 비밀번호를 특정할 수 있다는 겁니다
그렇다면 어떤 DBA라도 단순히 비밀번호를 데이터베이스에서 불러와 고객의 자격 증명으로 로그인을 시도하고 이를 악용할 수 있습니다.
이런 모든 상황을 방지하기 위해 비밀번호를 데이터베이스에 일반 텍스트로 저장하는 것은 절대 추천하지 않습니다.
심각한 무결성과 기밀성 문제가 있기 때문입니다.
Spring Security 내부의 비밀번호 검증 로직
DaoAuthenticationProvider 안에서 실질적인 검증이 일어날 겁니다
우리가 사용한 기본 PasswordEncoder로 저의 비밀번호가 어떻게 검증되는지 살펴보겠습니다
서버를 디버깅 모드로 실행하고 비밀번호는 '54321'로 로그인을 클릭하면
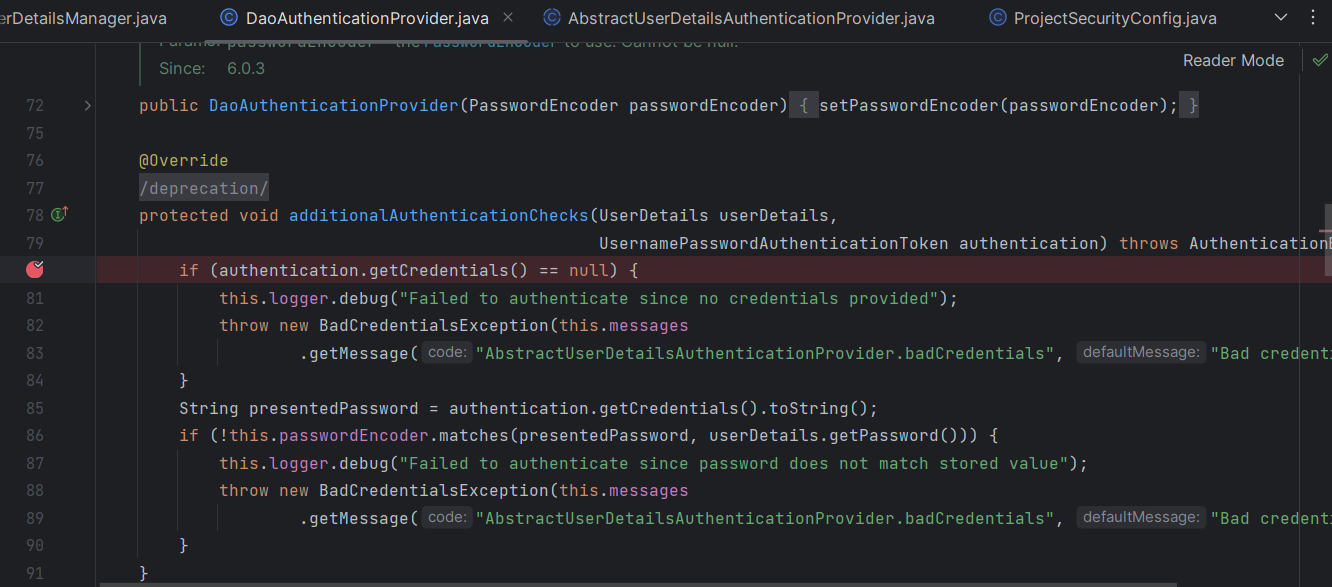
DaoAuthenticationProvider의 additionalAuthenticationChecks라는 이 메소드 안에서 실행이 멈춘 걸 볼 수 있습니다.
먼저 저의 인증 객체 내부에 자격 증명이 존재하는지 확인합니다
자격 증명이 존재한다면 presentedPassword로 여러분의 문자열에 할당됩니다
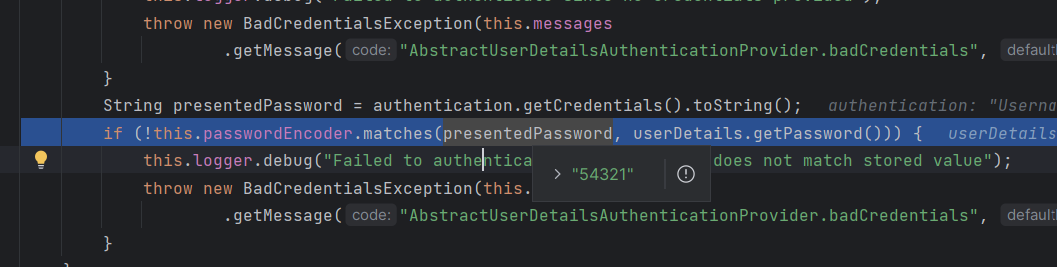
그러니 인증 객체로부터 받는 비밀번호가 바로 엔드 유저가 입력한 비밀번호입니다
Spring Security 필터는 유저 네임과 비밀번호를 인증 객체로 변환합니다
그래서 인증 객체로부터 그 비밀번호 정보를 읽어내려고 하는 것입니다
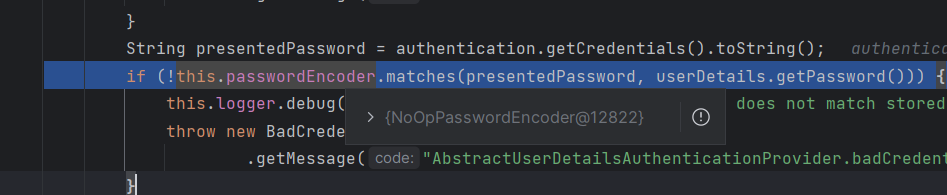
그 다음 여기에서는 PasswordEncoder 내부의 matches라는 메소드를 호출합니다 이 PasswordEncoder를 하이라이트 해보면 지금 제가 사용하는 PasswordEncoder는 NoOpPasswordEncoder입니다
이 matches 메소드 안에 들어가보면, NoOpPasswordEncoder이고 현재 이 PasswordEncoder의 matches 안에 있습니다
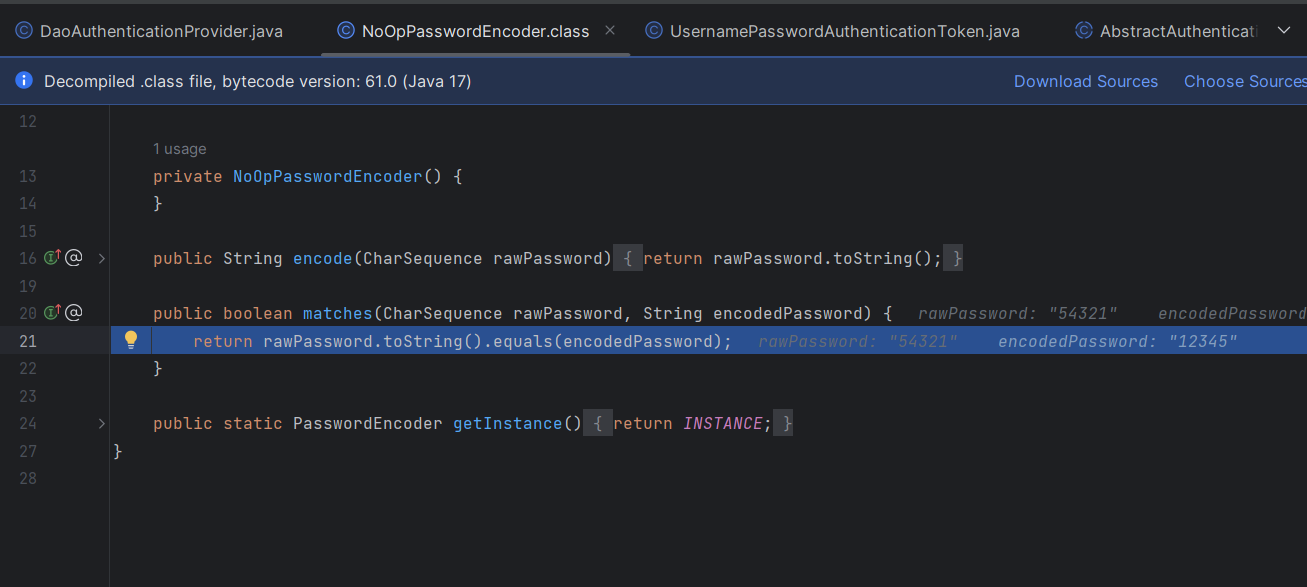
이 Java 주석을 읽어보시면 이 PasswordEncoder는 보호되지 않으며 다른 PasswordEncoder를 사용하라고 합니다.
/**
* This {@link PasswordEncoder} is provided for legacy and testing purposes only and is
* not considered secure.
*
* A password encoder that does nothing. Useful for testing where working with plain text
* passwords may be preferred.
*
* @author Keith Donald
* @deprecated This PasswordEncoder is not secure. Instead use an adaptive one way
* function like BCryptPasswordEncoder, Pbkdf2PasswordEncoder, or SCryptPasswordEncoder.
* Even better use {@link DelegatingPasswordEncoder} which supports password upgrades.
* There are no plans to remove this support. It is deprecated to indicate that this is a
* legacy implementation and using it is considered insecure.
*/
두 번째 매개변수는 데이터베이스에서 불러온 userDetails 객체로부터 받고 있습니다. 이 두 문자열이 일치한다면 참이라는 불리언을 반환할 것이고
어떤 이유든 자격 증명이 불일치한다면 잘못된 자격 증명이라는 예외를 반환할 것입니다.
일단은 이것이 우리의 Spring Boot 웹 애플리케이션에서 일어나는 일입니다. 보호되지 않은 NoOpPasswordEncoder에 의존하고 있습니다.
인코딩 vs 암호화 vs 해싱
아주 오래 전 거의 웹 애플리케이션 초기 시절에 모두가 자격 증명을
일반 텍스트 형식으로 저장했지만 이후에 보안 침해, 기술 발전에 의해
업계가 발전했습니다.
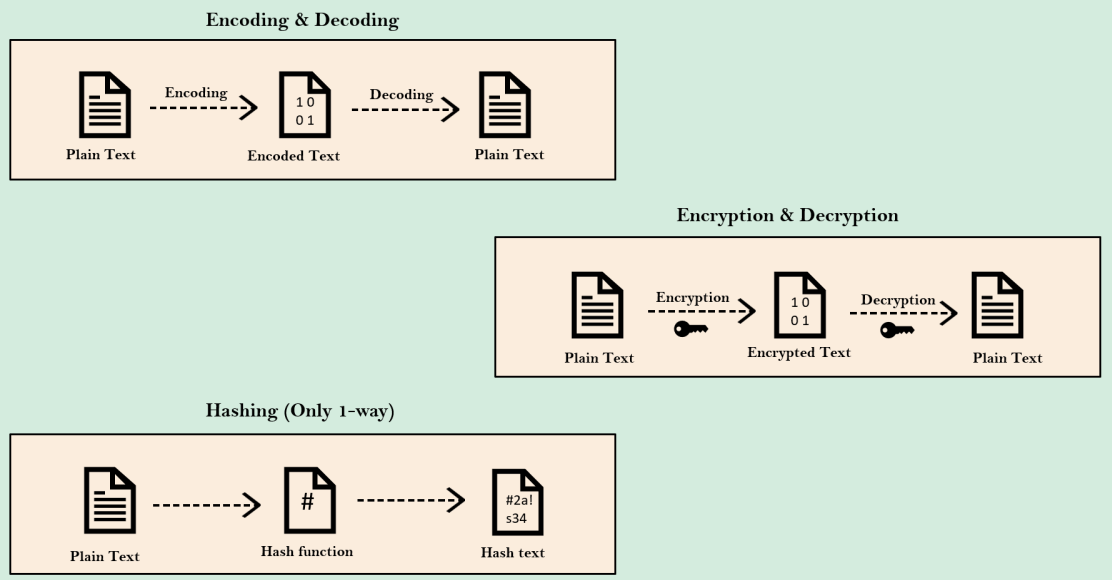
인코딩입니다
인코딩은 여러분의 데이터를 한 형식에서 다른 형식으로 변환하는 과정이며
어떠한 기밀성도 포함하지 않는다. 무슨 뜻이냐면 제가 일반 텍스트 비밀번호를 인코딩을 따라 인코딩 값으로 변환한다면 누구든 이 인코딩 값을 가져다가 디코딩 과정을 따라할 수 있다는 겁니다
아무런 기밀도 포함하지 않고 완전히 가역적이기 때문에 비밀번호 관리에는 적합하지 않습니다 물론 일반 텍스트 비밀번호를 저장하는 것보다는 낫지만
여전히 우리가 고려할 옵션은 아니고 인코딩은 주로 MP3 파일이나
영상 파일을 인코딩하는 상황에서 사용됩니다
base64decode.org라는 웹사이트로 왔습니다
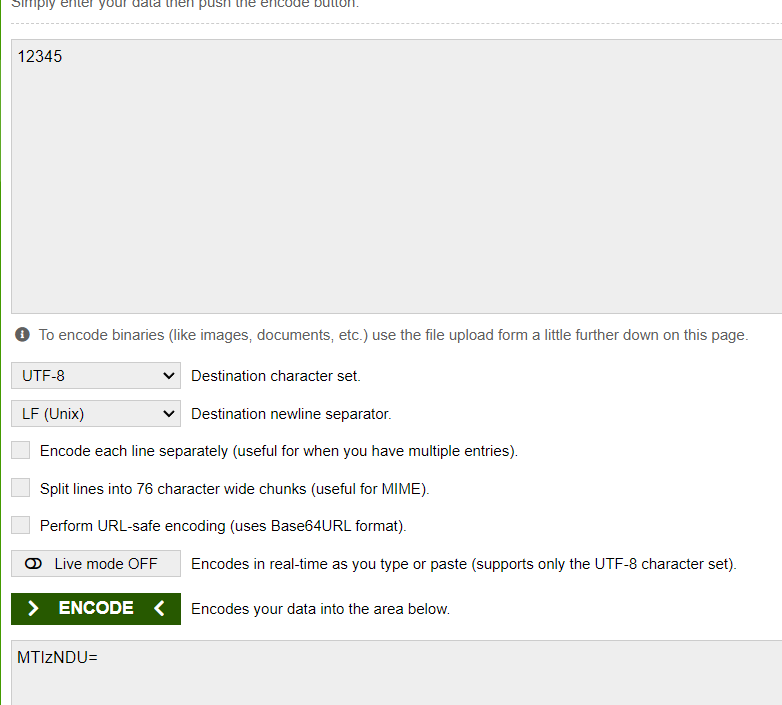
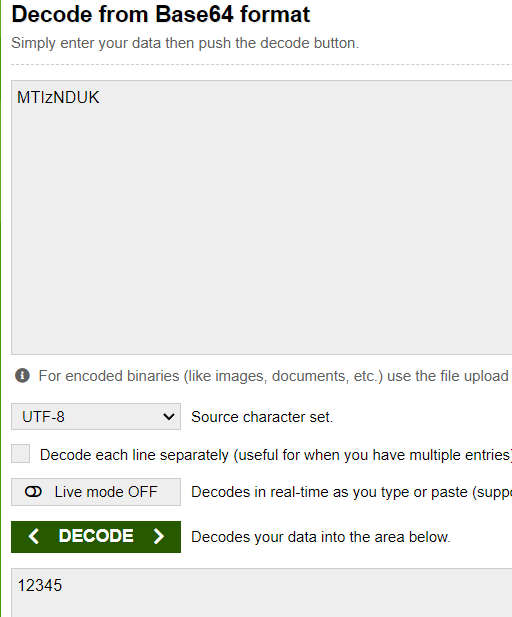
12345를 Encode 한 값을 그대로 Decode 하면 원래의 값을 알 수 있습니다. 그러니 여기서는 비밀이나 기밀성이 없습니다. 아무런 노력 없이 완벽히 되돌릴 수 있기 때문입니다.
암호화
암호화 또한 기밀성을 보장하는 방법으로 여러분의 일반 데이터를 변환하는 과정입니다.
이 기밀성을 충족할 방법은 우리가 데이터를 암호화하려고 할 때마다 특정 알고리즘을 따르고 이 암호화 알고리즘에 비밀 키(secret)를 제공하는 것입니다.
이 비밀 키 값을 고려하여 암호화 알고리즘은 저의 일반 텍스트 비밀번호를
아무도 이해하지 못하는 형식으로 암호화합니다. 일반 텍스트 비밀번호를 암호화한 다음에 일반 텍스트 비밀번호가 무엇인지 알고 싶다면 복호화를 해야 합니다
복호화는 암호화의 반대 과정입니다. 복호화하고 싶은 경우에는 무조건
암호화 과정에서 사용된 동일한 알고리즘과 동일한 비밀 키(secret) 또는 키를 사용해야 합니다.
하지만 여기에도 문제가 있습니다. 여러분의 서버 관리자가 비밀 키와 알고리즘과 같은 변수에 접근할 수 있는 개발자 또는 테스터라는 것입니다.
즉 암호화된 값을 일반 텍스트 비밀번호로 되돌릴 가능성이 있다는 것입니다. 그렇기 때문에 이것 또한 비밀번호 관리에 고려하는 것을 추천하지 않습니다.
해싱
해싱에서 여러분의 데이터는 수학적 해싱 기능을 사용해 해시값으로 변환됩니다 그러므로 일반 텍스트 비밀번호에 해싱을 적용하면 이것은 비가역적입니다
아무도 해시값을 아는 것만으로 일반 텍스트 비밀번호를 볼 수 없기에 해싱은 데이터베이스와 같은 저장소에 비밀번호를 저장하기 위한 업계 표준이 되었습니다
여기서 의문이 드실 수 있습니다
일반 텍스트 비밀번호로 되돌릴 수 없다면 로그인 작업에서 엔드 유저가 입력한 비밀번호를 어떻게 검증할까요?
유저가 입력한 일반 텍스트 비밀번호와 데이터베이스 안에 저장된 이미 해싱된 값을 비교하려고 할 때마다 엔드 유저가 입력한 비밀번호에 해싱 기능을 적용해야 합니다
그러면 여러분에게 두 개의 해시값이 있습니다.
1. 로그인 작업에서 유저가 입력한 비밀번호에 기반해 새로 생성된 해시값
2. 여러분이 데이터베이스에 저장해둔 엔드 유저의 등록 과정에서 생성되었을 값
이 두 개의 해시값이 있다면 이들을 비교할 수 있습니다.
해싱은 해시값을 일반 텍스트 비밀번호로 되돌릴 수 없다는 이점이 있습니다
따라서 최초의 일반 텍스트 비밀번호를 아는 사람만이 저의 시스템에 접속할 수 있습니다.
저장된 해시값을 볼 수 있더라도 저의 시스템에 접속할 수 없는데 일반 텍스트 비밀번호를 알지 못하기 때문입니다.
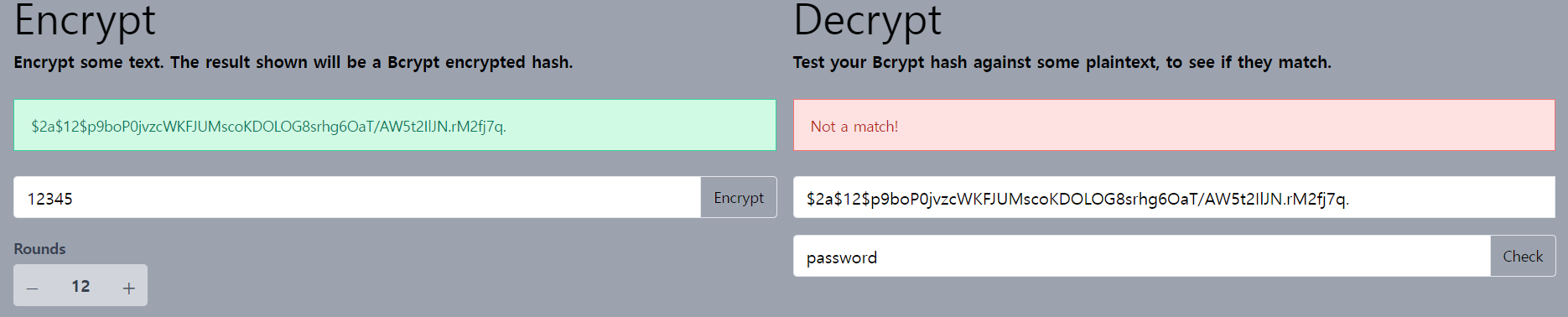

이 해시값을 보기만 해서는 초기 텍스트 비밀번호가 뭔지 누구도 맞출 수 없습니다.
해싱의 또 다른 이점은 동일한 일반 텍스트 비밀번호를 한 번 더 해싱하면 제 해시값의 다른 문자열 표현을 반환한다는 겁니다.
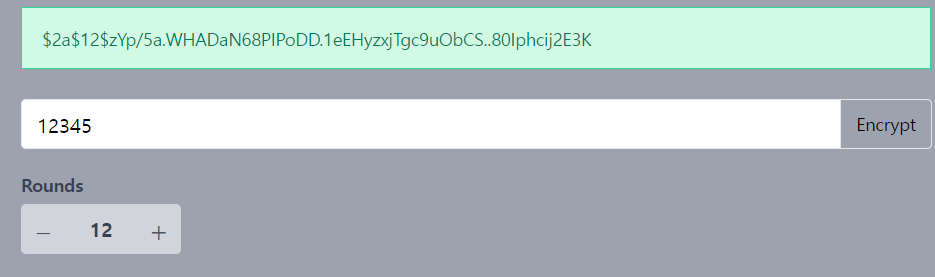
같은 12345를 입력했지만 다른 해시를 얻었습니다. 해싱을 시도할 때마다
같은 해시값을 반환하지 않습니다 하지만 내부적으로 이 문자열은 해시값을 가지기에 이 해시값은 항상 같습니다
12345와 같이 같은 비밀번호를 가진 사람들은 데이터베이스에 같은 해시 문자열을 저장할 것이고 이것은 또 보안 문제입니다
그래서 이런 시나리오를 방지하기 위해 해싱 알고리즘은 해싱을 반복해서
매번 다른 해시 문자열을 반환합니다.
하지만 내부적으로 이 해싱 알고리즘들은 이 해시 문자열들이 내부적으로는 반드시 같은 해시값을 가지게 합니다.
해시값을 어떻게 생성하는지 어떻게 비교하는지 걱정하지 않아도됩니다,
이 모든 작업을 위해서 Spring Security 안에 비밀번호 인코더들이 있습니다.
PasswordEncoder
PasswordEncoder는 인터페이스이며 두 개의 추상 메소드와 한 개의 기본 메소드가 있습니다.
public interface PasswordEncoder {
String encode(CharSequence rawPassword);
boolean matches(CharSequence rawPassword, String encodedPassword);
default boolean upgradeEncoding(String encodedPassword) {
return false;
}
}encode
첫 번째 추상 메소드는 encode입니다.
엔드 유저의 등록 절차에서 활용할 수 있습니다. 이 encode 메소드는 엔드 유저가 등록 절차에서 입력한 일반 텍스트 비밀번호를 내가 사용하는 PasswordEncoder에 기반해 해시 문자열 또는 암호화된 값으로 변환합니다.
matches
matches는 로그인 작업에서 유저가 입력한 비밀번호와 데이터베이스에 이미 저장된 비밀번호를 비교하기 위해 사용해야 하는 메소드입니다.
이 matches 메소드는 엔드 유저가 로그인 작업에서 입력한 rawPassword를 받습니다
두 번째 매개변수는 encodedPassword 또는 loadUserByUsername의
도움으로 데이터베이스에서 불러온 해시 비밀번호입니다.
matches 메소드는 먼저 동일한 해싱 알고리즘을 사용해 rawPassword를 해싱하는 로직을 가집니다. 그 다음 두 개의 해시 문자열을 비교하고 이들의 해시값을 유도합니다.
해시값이 동일하다면 이 matches 메소드는 true로 반환하고 반대로 해시값이 일치하지 않는다면 matches 메소드는 false로 반환합니다.
upgradeEncoding
이것은 기본 메소드이며 언제나 false로 반환하는 기본 로직을 갖고 있습니다. 이 메소드의 목적은 해커가 여러분의 비밀번호를 해킹하고 복호화하여
해시값의 일반 텍스트 비밀번호를 알아내는 것을 여러분이 아주 아주 어렵게 하고자 한다면
여러분의 비밀번호를 두 번 인코딩할 수 있습니다. 해싱을 두 번 하는 것입니다. 즉, upgradeEncoding은 true값을 반환한다면 여러분의 비밀번호에 더 많은 보호를 제공합니다.
기본적으로 이는 false인데 일반 텍스트 비밀번호를 기본 1회 해싱하는 것으로 충분해야 하기 때문입니다
PasswordEncoder 구현 클래스

PasswordEncoder 6개를 강조해두었습니다. 우리 웹 애플리케이션에서 이 중 무엇이든 사용할 수 있습니다. 하지만 장,단점을 이해해야 적합한걸 선택할 수 있습니다.
NoOpPasswordEncoder
해싱, 인코딩, 암호화의 개념이 없고 여러분의 비밀번호를 일반 텍스트로 취급할 겁니다.
그렇기에 운영 애플리케이션에 추천하는 PasswordEncoder가 아닙니다
데모 애플리케이션이나 우선순위가 낮은 비운영 환경 애플리케이션에만 사용하는게 좋습니다.
PasswordEncoder
이 StandardPasswordEncoder 또한 운영 앱에 추천하지 않습니다.

여기를 보시면 이건 사용이 중단됐습니다.
이 PasswordEncoder를 추천하지 않는 이유는 그저 일반 텍스트 비밀번호를 암호화하기 위해 이 PasswordEncoder를 구현한 것이기 때문입니다.
Pbkdf2PasswordEncoder
5~6년 전 쯤에 개발된 애플리케이션에서는 이 PasswordEncoder를 사용할 수도 있는데 그 때는 안전하게 여겨졌기에 이것을 사용하는 것일 수 있습니다
하지만 최근에는 CPU, GPU의 발전과 더불어 이것은 더 이상 안전하지 않습니다. 해커가 고성능 GPU 기계를 갖고 있다면 손쉽게 여러분의 해시값에 무차별 대입 공격을 가하고 일반 텍스트 비밀번호를 추측할 수 있습니다.
무차별 대입 공격 (brute-force attack)
엔드 유저들의 비밀번호와 유저 네임 정보를 전부 다운로드했습니다
해커가 가장 먼저 할 것은 특정 해시 값의 최초 텍스트를 추측 시도하는 일일 것입니다.
여러 자주 사용되는 비밀번호 또는 사전의 여러 단어를 시도해볼겁니다
만약 누군가가 취약한 비밀번호를 사용하고 있다면 해커는 해당 해시 값의 일반 텍스트를 쉽게 알아낼 수 있습니다.
이런 식으로 해커는 다양한 입력값을 시도해보고 주어진 해시 값의 최초 텍스트 비밀번호를 추측하려고 합니다
이런 종류의 공격을 무차별 대입 공격이라고 부릅니다.
따라서 개발자로서 제가 할 수 있는 것은
해싱 로직을 지연시켜 이 해커가 쉽게 값을 찾지 못하도록 하는 것입니다.해커의 삶을 어렵게 하려면 몇 가지 선택지가 있습니다
- 단순한 비밀번호를 사용하지 않기
- 강력한 해싱 알고리즘을 사용
BCryptPasswordEncoder
이름이 보여주듯이 이것은 1999년에 발명된 BCrypt 해싱 알고리즘을 사용합니다.
지난 20년 동안 이 BCrypt 해싱 알고리즘은 광범위하게 사용되며 컴퓨터 내부에서 일어나는 최신 발전에 따라 주기적으로 업데이트됩니다
그러니 BCryptPasswordEncoder의 도움으로 일반 텍스트값을 해싱하거나
matches 메소드를 실행하려고 하면 이것은 CPU 연산을 요청합니다
즉 밀리초 안에 실행할 수 있는 쉬운 Java 코드가 아니라는 뜻입니다. 여러분이 BCryptPasswordEncoder에 설정한 작업량 또는 라운드 수에 따라
이 해싱 알고리즘이 사용하는 CPU 연산은 더 많아집니다.
어떤 해커가 무차별 대입 공격을 하려고 하면 연산 능력을 필요로 할 겁니다.
SCryptPasswordEncoder
이 SCryptPasswordEncoder는 BCryptPasswordEncoder의 고급 버전입니다. SCryptPasswordEncoder는 누군가 이 알고리즘의 해싱 기능 또는 matches 기능을 사용하고자 할 때 두 개의 인자를 요구하기 때문입니다.
첫 번째 인자는 BCryptPasswordEncoder에서 다루었던 연산 능력입니다.
두 번째 인자는 메모리입니다 .
이 알고리즘은 우리가 적용한 설정에 따라 고의적으로 일부 메모리 할당을 요구합니다. 따라서 우리의 해커는 연산 능력과 본인 RAM 내부의 메모리를 제공해야 합니다.
Argon2PasswordEncoder
이것은 심지어 더 최신인 해싱 알고리즘인데 세 가지 측면이 있습니다
첫 번째는 BCrypt와 SCrypt에서 사용되는 연산 능력입니다.
두 번째 자원 또는 두 번째 측면은 메모리인데 우리는 이것도 ScryptPasswordEncoder에서 봤습니다.
해커에게 요구하는 세 번째 인자 또는 세 번째 자원은 다중 스레드입니다
누군가 이 Argon2PasswordEncoder 또는 Argon2 해싱 알고리즘을 이용하려고 한다면 우리의 해커든 어떤 코드든 이 세 가지 자원을 할당해야 합니다
- 연산
- 메모리
- 다수의 스레드 또는 다중 CPU 코어입니다
이 모든 걸로 인해 우리가 Argon2 해싱 알고리즘을 사용할 때 무차별 대입 공격이 사실상 불가능한 것입니다.
Argon2PasswordEncoder는 최신의 해싱 알고리즘이며, 화려해 보이고 보안이 강해보여 여러분의 운영 웹 애플리케이션을 위한 좋은 선택지 같기도 합니다.
하지만 이 생각에 너무 몰입하지는 마시기 바랍니다. 왜냐하면 해커로부터 시간을 더 빼앗는다는 것은 여러분의 웹 애플리케이션에서도 꽤 많은 시간을 빼앗는다는 뜻이기 때문입니다.
여러분의 코드와 작동 중인 서버로부터 많은 자원을 요구하기에 로그인 작업이나 등록 절차 도중 성능 문제가 분명히 있을 겁니다.
이러한 성능 문제로 인해 가장 일반적으로 보게 될 PassowrdEncoder는 BCryptPasswordEncoder입니다.
알파-숫자값 특수문자를 조합했으며 8개 이상의 철자로 된 강력한 비밀번호를 독려하는 어떤 유효성 검사를 갖추고 있다면 여러분은 괜찮을 것이고 어떠한 해커도 무차별 대입 공격을 가하지 못할 것입니다.
예제 코드
@Configuration
public class ProjectSecurityConfig {
@Bean
SecurityFilterChain defaultSecurityFilterChain(HttpSecurity http) throws Exception {
http.csrf((csrf) -> csrf.disable())
.authorizeHttpRequests((requests) -> requests
.requestMatchers("/myAccount", "/myBalance", "/myLoans", "/myCards").authenticated()
.requestMatchers("/notices", "/contact", "/register").permitAll())
.formLogin(Customizer.withDefaults())
.httpBasic(Customizer.withDefaults());
return http.build();
}
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
}스프링 시큐리티 설정 config 클래스에서 passwordEncoder를 내가 사용하고자 하는 클래스를 지정해준다.
@RestController
public class LoginController {
private final CustomerRepository customerRepository;
public LoginController(CustomerRepository customerRepository, PasswordEncoder passwordEncoder) {
this.customerRepository = customerRepository;
this.passwordEncoder = passwordEncoder;
}
private final PasswordEncoder passwordEncoder;
@PostMapping("/register")
public ResponseEntity<String> registerUser(@RequestBody Customer customer) {
Customer savedCustomer = null;
ResponseEntity response = null;
try {
String hashPwd = passwordEncoder.encode(customer.getPwd());
customer.setPwd(hashPwd);
savedCustomer = customerRepository.save(customer);
if (savedCustomer.getId() > 0) {
response = ResponseEntity
.status(HttpStatus.CREATED)
.body("Given user details are successfully registered");
}
} catch (Exception ex) {
response = ResponseEntity
.status(HttpStatus.INTERNAL_SERVER_ERROR)
.body("An exception occured due to " + ex.getMessage());
}
return response;
}
}내가 적용하고자 하는 (여기서는 회원가입) 로직에서 비밀번호를 지정할때 PasswordEncoder로 encode한뒤 그 값을 데이터베이스에 저장하는 것이다.
