
📙ES6 문법공부
📌문자열
''(작은 따옴표), ""(큰 따옴표), ``(백틱)으로 문자열을 만든다.
✨상황에 맞게 따옴표 쓰기
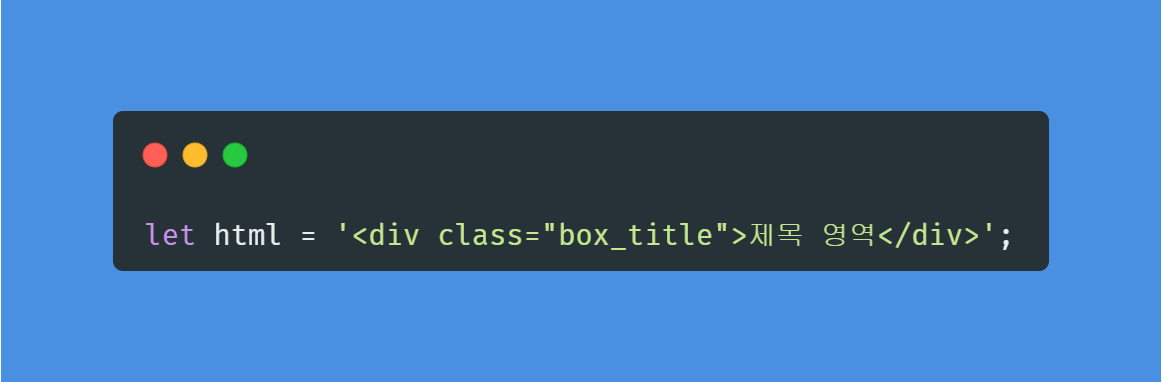
💡html 코드를 쓸 때
hmtl 코드는 작은 따옴표로 감싸는게 편하다. 클래스 명과 같이 큰 따옴표로 된 내용이 있기 때문이다.
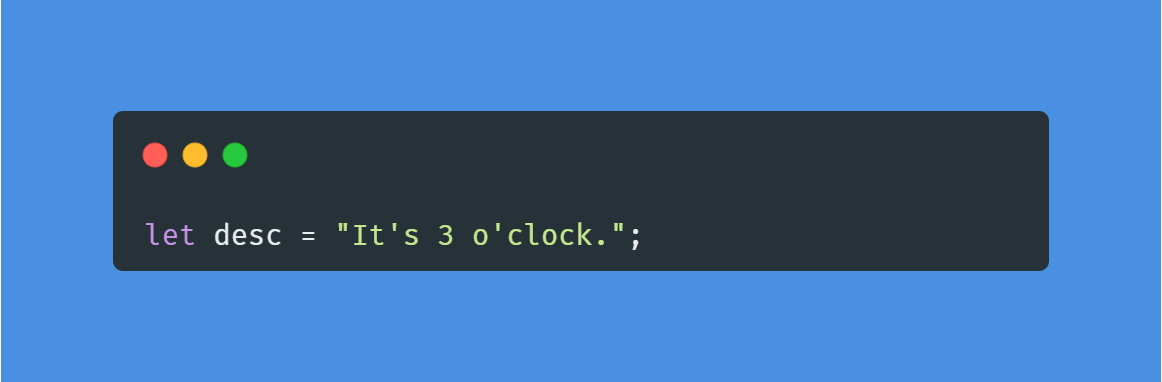
💡영어 문장을 쓸 때
영어 문장은 큰 따옴표를 사용하는 것이 편하다. 영어 문장에 아포스트로피(')가 들어가기 때문이다.
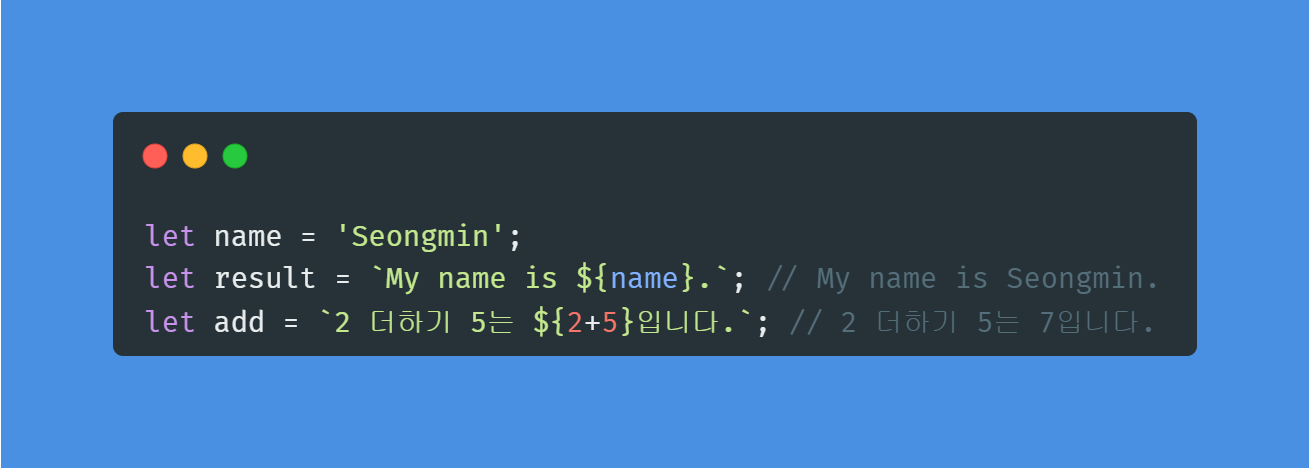
💡백틱의 특징
백틱은 달러와 중괄호를 이용해 변수을 표현하거나 표현식을 쓸 수 있다.
백틱은 '\n'을 쓰지 않고 문자열 여러줄을 포함할 수 있다. 따옴표를 사용해서 문자열을 만들 경우에는 줄바꿈을 하지 않고 한 줄로 써야한다. 줄 바꿈을 표현하기 위해선 '\n'을 사용해야 한다.
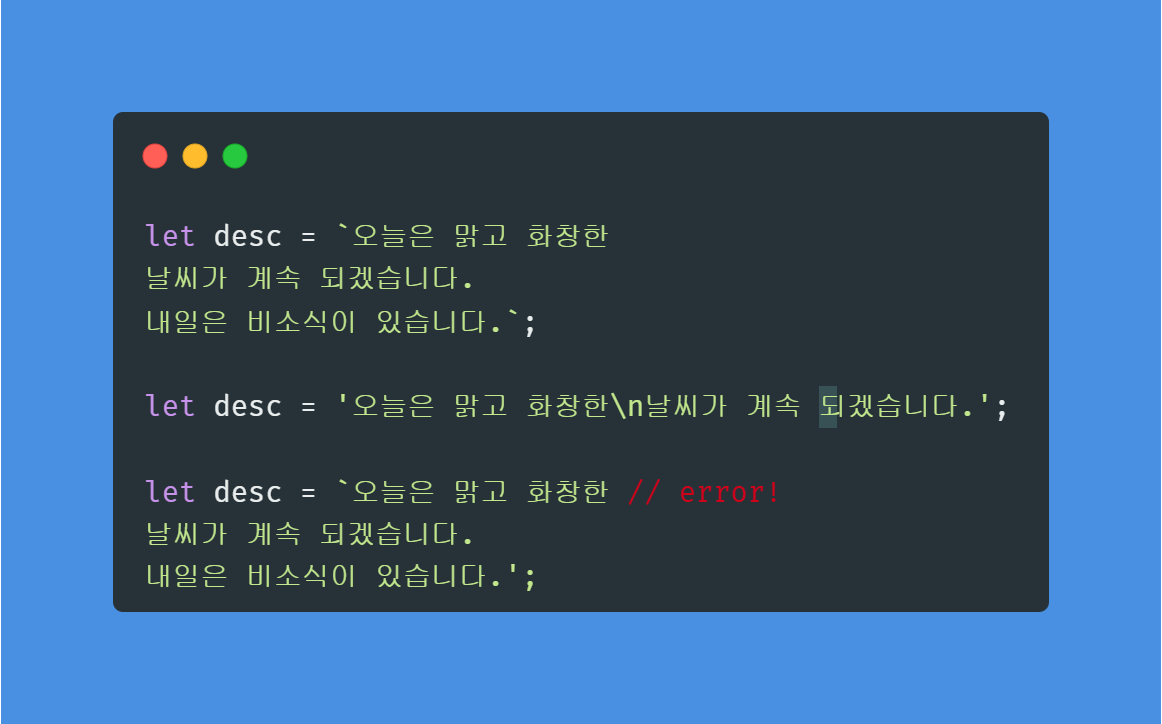
✨문자열 특징
💡length : 문자열 길이
문자열.length를 통해서 문자열의 길이를 구할 수 있다. 회원가입할 때 아이디나 비밀번호를 몇 자 이상, 몇 자 이하로 제한할 때 사용한다.

💡특정 위치에 접근
배열과 동일하게 문자열도 대괄호로와 숫자로 특정 위치의 문자에 접근할 수 있다.

💡일부 수정 불가
문자열은 원시값이기 때문에 불변성을 갖는다. 따라서, 배열과 다르게 한 글자만 바꾸는 것은 허용이 안된다. 문자열에서 일부를 바꾸려면 전체 문자열을 새로 만들어야 한다.

✨문자열의 메서드
💡str.toUpperCase() / str.toLowerCase()
toUpperCase(), toLowerCase() 메서드 각각은 모든 영문을 대문자로, 모든 영문을 소문자로 바꿔준다.

💡str.indexOf(text)
- 문자를 인수로 받아 몇 번째에 위치하는지 알려준다.
ㅤ- 포함된 문자가 여러개라도 첫 번째 위치만 알려준다. 찾는 문자가 없으면 -1을 반환한다.
ㅤ- ⚠️ indexOf() 메서드를 if문의 조건으로 쓸 때 주의할 점: 찾고자 하는 문자의 인덱스가 0이면 조건문 안에서 false를 반환하게 된다. 따라서, 의도치 않은 방향으로 실행되는 것을 방지하기 위해 항상 -1보다 큰지를 비교한다.

💡str.includes(text)
찾고자 하는 문자가 있으면 true를, 없으면 false를 반환한다. 굳이 문자의 인덱스를 확인 안 하고, 문자가 있는지 없는지 정도만 확인할 때 사용하면 좋다.

💡str.slice(n,m) : 특정 범위의 문자열 뽑기
- m이 양수라면, n번째 인덱스부터 m번째 인덱스 직전까지의 문자를 반환한다.
ㅤ- m이 음수라면, 끝에서부터 센다. 끝에서부터 셀 때는 -1 인덱스부터 시작한다. 아래 코드의 역방향 인덱스는
-7 -6 -5 -4 -3 -2 -1이다. 예를 들어, desc.slice(2,-2)는 2번째 인덱스부터 끝에서 인덱스가 -3인 문자까지 출력한다.
ㅤ- m이 없으면 문자열 끝까지를 포함한다.
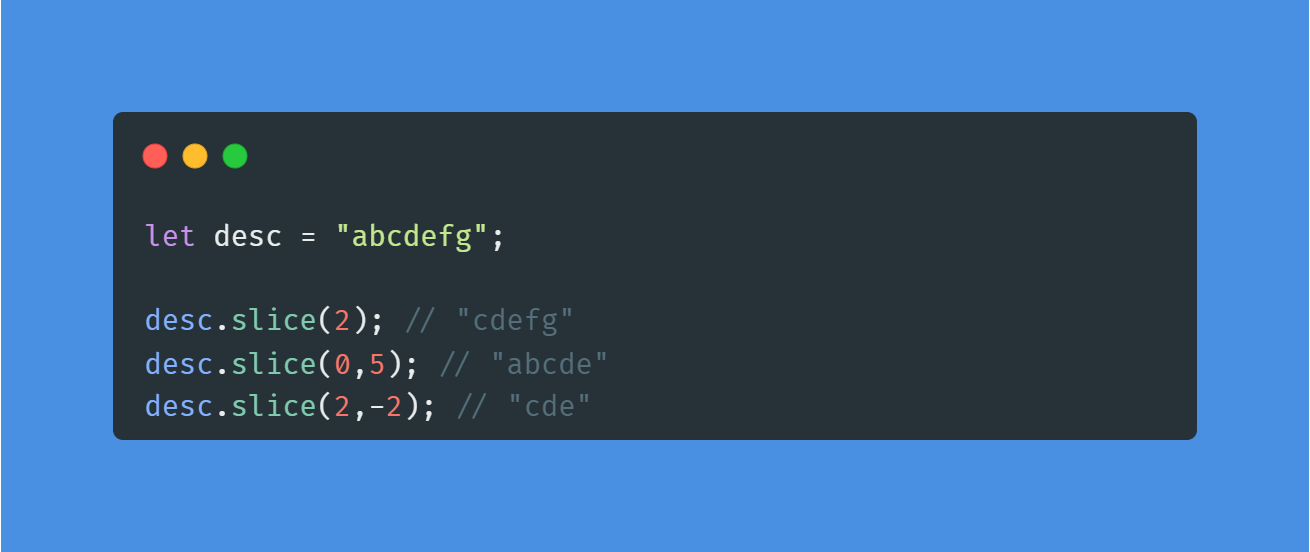
💡str.substring(n,m) : 특정 범위의 문자열 뽑기
인덱스 n과 m사이의 문자열을 반환한다.
slice() 메서드와 유사하지만, substring() 메서드는 n과 m을 바꿔도 동작한다. 음수는 허용하지 않기에 0으로 인식한다.
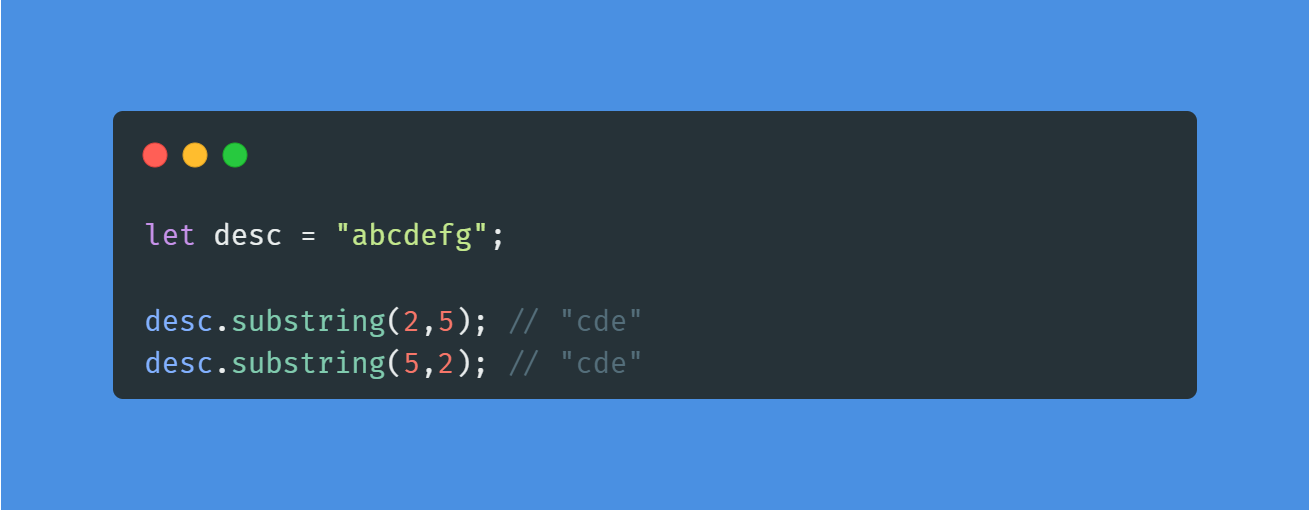
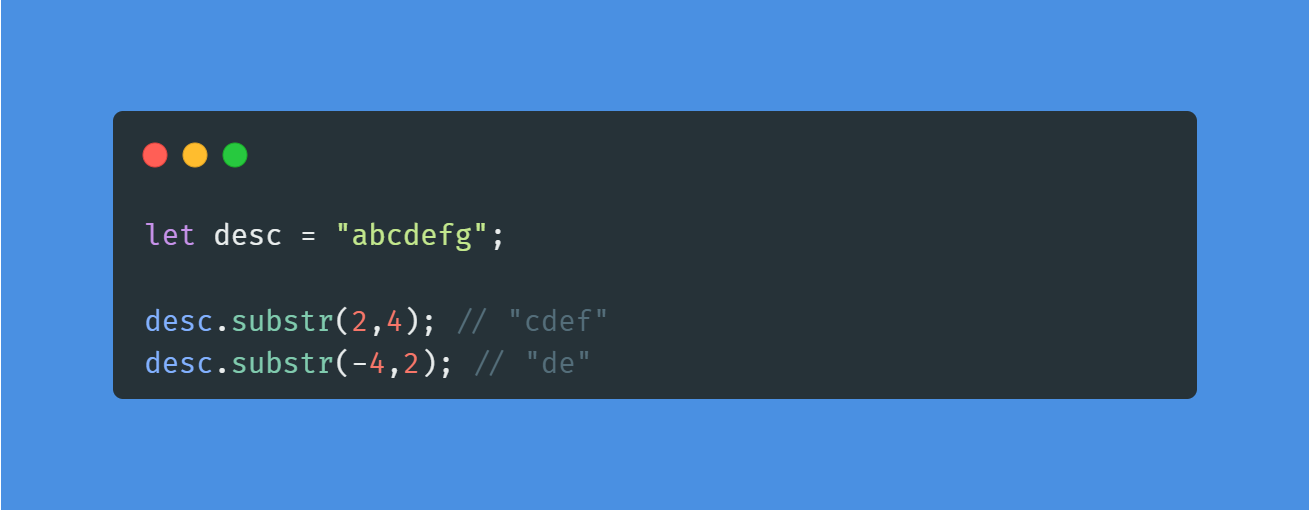
💡str.substr(n,m) : 특정 범위의 문자열 뽑기
인덱스 n부터 시작해서 문자 m개를 가져온다. m은 범위가 아니라 개수이다.
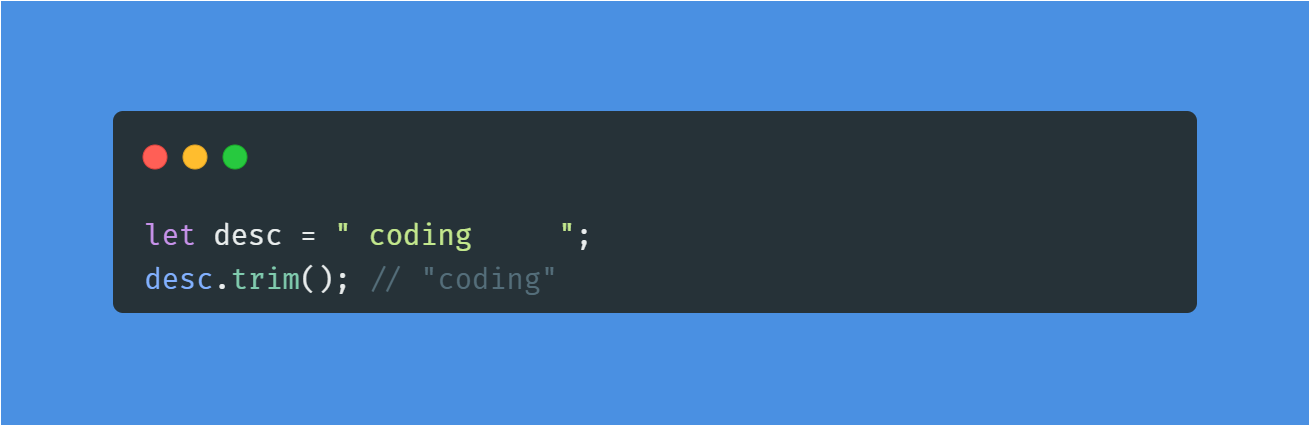
💡str.trim() : 앞 뒤 공백 제거
문자열의 앞, 뒤 공백 문자를 제거해준다. 따라서, 사용자로부터 무언가를 입력받을 때 trim() 메서드를 사용한다.
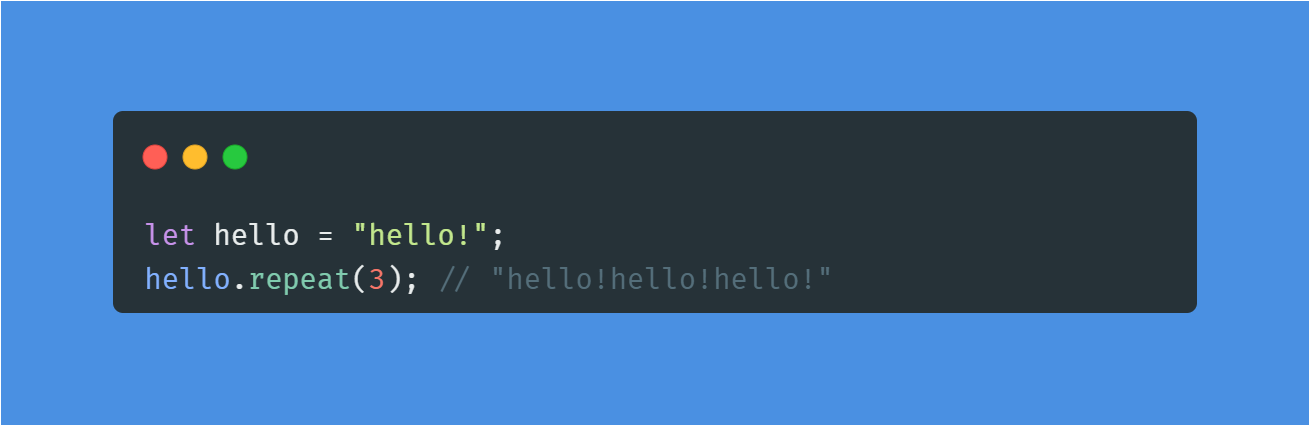
💡str.repeat(n) : 문자열 n번 반복
문자열을 n번 반복한다.
✨문자열 비교
문자에 대응되는 숫자(유니코드 값, 10진수 값)를 비교해서 문자 비교 결과를 출력한다.
💡codePointAt(index)와 String.fromCodePoint(n) 메서드
codePointAt(index)이라는 메서드를 사용해서 해당 인덱스의 문자와 대응되는 유니 코드값을 얻을 수 있다.
그리고, String.fromCodePoint(n)를 사용해서 유니 코드값이 n인 문자를 얻을 수 있다.

✏️아스키 코드 vs 유니 코드
아스키 코드는 0~127 범위의 문자만 포함한다. (영문자, 숫자, 특수문자)
유니코드는 다국어, 이모지 등을 비롯해 더 많은 문자를 포함한다.
아스키 코드는 유니 코드의 하위 집합이기 때문에, 영어 알파벳(A-Z, a-z)에 대응되는 값이 동일하다.
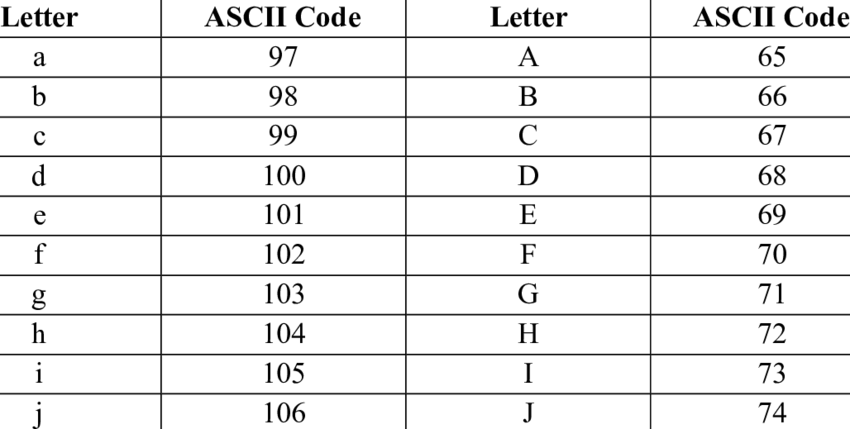
✏️알파벳의 10진수 값
알파벳은 대문자보다 소문자의 10진수 값 (아스키코드 값, 유니코드 값)이 더 크다.
a, b, ... , z로 갈수록 10진수 값이 커진다.
