[Programmers]실리콘밸리에서 날아온 DE 스타터 키트4️⃣주차
🈯 숙제 해설
3주차 복습
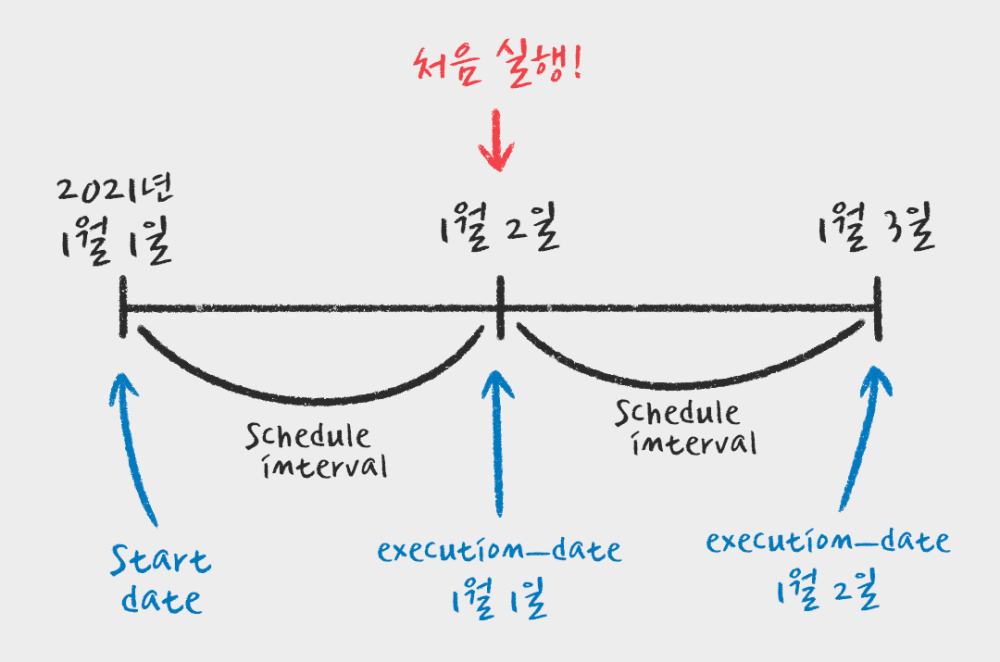
start_date- 처음 DAG가 실행되는 날짜
- 실제로 실행되는 것은 start_date + 실행주기
- backfill을 쉽게 하기 위한 용도
execution_date- 실제로 데이터를 읽는 행위를 하는 날짜
- 나중에 DAG를 실행할 때 쓰는 고유의 ID 같은 날짜
- 출처 : 오늘의 집 기술블로그
- 멱등성
- 데이터 파이프라인이 연속 실행되었을 때 소스에 있는 데이터가 그대로 DW로 저장되어야하는 성질
- 멱등성을 지키기 위한 방법
Full Refresh의 경우INSERT전에 항상DELETE로 기존 테이블의 내용을 지워주고INSERT실행Incremental Update의 경우 타임스탬프와 같은 필드 생성 후execution_date활용
- Transaction
- Atomic하게 실행되어야 하는 SQL들을 묶어서 하나의 작업처럼 처리하는 방법.
BEGIN;(queries);END;와 같은 방법으로 구현.- 만약, 중간에 하나라도 실패하면
ROLLBACK이라는 sql 실행하면 임시상태의 모든 쿼리 삭제. - 임시 상태이기 때문에 쿼리를 너무 많이 Transaction으로 묶으면 안 됨. 최소로 하는 게 좋음.
AUTOCOMMIT을 True, False로 할 지는 팀 내에서 정해야함.- SQL에서
BEGIN;END;를 쓸지, Python에서try/except를 쓸지는 선호 차이.
🧐 4주차
Airflow DAG
-
default_args 예시
default_args = {
'owner': 'ownerid',
'retries': 0,
'retry_delay': timedelta(seconds=20),
'depends_on_past': False
}- DAG 예시
dag = DAG(
"dag_v1", # DAG name
'start_date': datetime(2020,8,7,hour=0,minute=00),
# schedule (same as cronjob)
schedule_interval="0 * * * *",
# common settings
default_args=default_args
)- Task 예시
task_start = DummyOperator(
task_id='start',
dag=dag_runAirflow_v1
)
t1 = BashOperator(
task_id='print_date',
bash_command='date',
)- 중요한 DAG parameters
max_active_runs: 동시 실행 가능한 DAG 수(default=16)max_active_tasks: 동시 실행 가능한 Task 수(default=16)catchup: 밀린 거 자동으로 채울건지- 위와 같은 DAG parameters는 DAG레벨로 적용되는 것이고,
default_args로 지정되는 건 Task parameters로 Task레벨로 적용되는 것!
🧐 4주차
Airflow DAG 개선
- params를 통해 변수 넘기기
from airflow import DAG
from airflow.operators.python import PythonOperator
def func(**context) :
link = context["params"]["url"]
...
dag_name = DAG(...)
task = PythonOperator(
task_id = 'func',
python_callable = func,
params = {
"url" : "https://..."
},
dag = dag_name
)- Xcom객체를 이용해 task의 결과값 받기 + Variable 사용하기
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.models import Variable
def func1(**context):
link = context["params"]["url"]
task_instance = context['task_instance']
execution_date = context['execution_date']
...
return something
def func2(**context):
text = context["task_instance"].xcom_pull(key="return_value", task_ids="func1")
...
dag_name = DAG(...)
task1 = PythonOperator(
task_id = 'func1',
python_callable = func1,
params = {
'url': Variable.get("csv_url")
},
dag = dag_name
)
task2 = PythonOperator(
task_id = 'func2',
python_callable = func2,
params = {
},
dag = dag_name
)- Connection 사용하기
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.models import Variable
from airflow.hooks.postgres_hook import PostgresHook
def connection(autocommit=False):
hook = PostgresHook(postgres_conn_id='redshift_dev_db')
conn = hook.get_conn()
conn.autocommit = autocommit
return conn.cursor()
def func1(**context):
link = context["params"]["url"]
task_instance = context['task_instance']
execution_date = context['execution_date']
...
return something
def func2(**context):
text = context["task_instance"].xcom_pull(key="return_value", task_ids="func1")
...
dag_name = DAG(...)
task1 = PythonOperator(
task_id = 'func1',
python_callable = func1,
params = {
'url': Variable.get("csv_url")
},
dag = dag_name
)
task2 = PythonOperator(
task_id = 'func2',
python_callable = func2,
params = {
},
dag = dag_name
)Variables와ConnectionsVariables: 자주 사용되는 configuration info들을 미리 저장해 두는 것.- [‘password’, ‘secret’, ‘passwd’, ‘authorization’, ‘api_key’, ‘apikey’, ‘access_token’]와 같은 단어가 들어가면 별표(*)로 WEB UI에 표시된다.
Connections: 외부 서비스와 연결하기 위한 계정 정보들을 미리 저장해 두는 것.
- DAG 실행시 Primary Key 유지하기
- 임시 테이블을 활용하는 방법
- DAG가 실행될 때마다 임시 테이블 만들기
- 새로 읽어들인 레코드를 임시 테이블에 복사
ROW_NUMBER()를 이용해서 primary key로 partition 나누고 ts로 order by 해서 하나의 레코드만 남기기
- 기존의 원본 테이블을 DROP 하고 임시 테이블을 원본 테이블로 복사
- 임시 테이블을 활용하는 방법

완료주의