1. 파이썬이란 무엇인가, 장점은 무엇인가
- 파이썬은 현재 가장 많이 사용되고 있는 인터프리터 언어이며, 실행 전에 컴파일 할 필요가 없다.
- 변수를 선언할 때 데이터 유형을 언급할 필요가 없는 동적 언어이다.
- 파이썬은 객체지향언어로, 컴포지션(다른 클래스의 일부 메서드를 사용하고 싶지만, 상속은 하고 싶지 않을 경우 사용) 및 상속과 함께 클래스를 정의할 수 있다. 다른 언어처럼 private, public과 같은 것이 없다.
- 또한, 파이썬의 함수는 1급 객체(first-class objects)로 변수에 할당하고 다른 메서드에서 return 가능하며 arguments로 전달할 수 있다.
- 파이썬은 컴파일 언어보다 느리지만, 스크립트 최적화를 위해 C언어 확장을 추가하여 최적화 할 수 있다. What's New In Python
- 파이썬은 웹 기반 응용 프로그램, 테스트 자동화, 데이터 모델링, 빅 데이터 분석 등과 같은 여러 가지 용도로 사용된다.
2. 아래의 코드 실행 결과를 예상하시오
def extendList(val, list=[]): list.append(val) return list list1 = extendList(10) list2 = extendList(123,[]) list3 = extendList('a') print "list1 = %s" % list1 print "list2 = %s" % list2 print "list3 = %s" % list3
list1 = [10, 'a']
list2 = [123]
list3 = [10, 'a']이 정답이다. 언뜻보면 list1 = [10], list3 = ['a']처럼 될 것 같지만, 실제로는 함수가 선언될 때 리스트는 처음 한 번만 생성이 된다. 따라서 다시 한 번 함수를 선언해도 기존에 있던 함수의 리스트는 계속 존재하기 때문에 그 리스트에 값이 더해지는 것이다. 이는 id값을 확인해보면 더욱 명확하다.
def extendList(val, list=[]):
list.append(val)
return list
list1 = extendList(10)
print("list1's id is ", id(list1))
list2 = extendList(123,[])
print("list2's id is ", id(list2))
list3 = extendList('a')
print("list3's id is ", id(list3))
list4 = extendList(45, list2)
print("list4's id is ", id(list4))
print("--------------------------")
print("list1 = %s" % list1)
print("list2 = %s" % list2)
print("list3 = %s" % list3)
print("list4 = %s" % list4)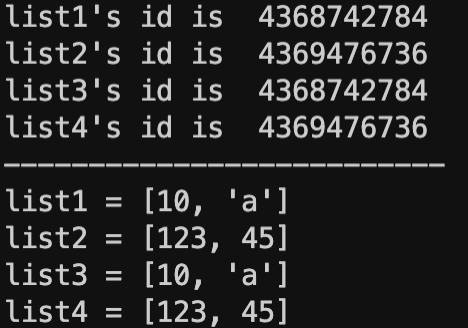
list1과 list3는 함수 호출 시 따로 리스트를 전달하지 않았더니 기존에 함수 생성시 만들어진 리스트에 값이 추가되며 같은 id를 공유하는 것을 알 수 있다. 이에 반해, list2와 list4는 list2 생성 시 빈 리스트를 따로 전달해주니 전달받은 그 리스트에서 값을 추가해가고 같은 id를 공유하는 것을 알 수 있다.
3. 파이썬 애플리케이션에서 버그를 찾거나 정적 분석을 수행하는 방법은?
- 정적 분석기인 PyChecker를 사용할 수 있습니다. 파이썬 프로젝트의 버그를 식별하고 스타일과 복잡성 관련 버그도 보여준다.
pychecker [options] file1.py file2.py ...와 같이 사용할 수 있다. - 또 다른 도구는 파이썬 모듈이 코딩 표준을 충족하는지 확인하는 Pylint이다. C의 lint와 비슷하다.
4. 파이썬의 데코레이터란 무엇인가?
5. 리스트와 튜플의 차이점은 무엇인가?
가장 큰 차이점은 리스트는 mutable 하지만, 튜플은 immutable 하다는 점이다. 따라서 리스트에서 자주 사용되는 append나 insert, remove, sort와 같은 함수를 사용할 수 없다. 대신 튜플은 더 적은 메모리를 필요로 하기 때문에 속도가 빠르다.
둘의 공통점은 인덱싱이 가능하고 슬라이싱도 가능하다는 것이다.
6. 파이썬은 메모리 관리를 어떻게 처리하나?
파이썬은 메모리를 유지하기 위해 비공개 힙(private heap)을 사용한다. 따라서 힙은 모든 파이썬 객체와 데이터 구조를 보유한다. 이 영역은 파이썬 인터프리터만 접근할 수 있으며 프로그래머는 사용할 수 없다.
그리고 비공개 힙을 처리하는 것은 Python 메모리 관리자이며, 파이썬 객체에 필요한 메모리 할당을 수행합니다.
파이썬은 내장된 가비지 컬렉터를 사용하여 사용되지 않는 모든 메모리를 회수하고 힙 공간으로 오프로드한다.
아래의 그림으로 설명한다.
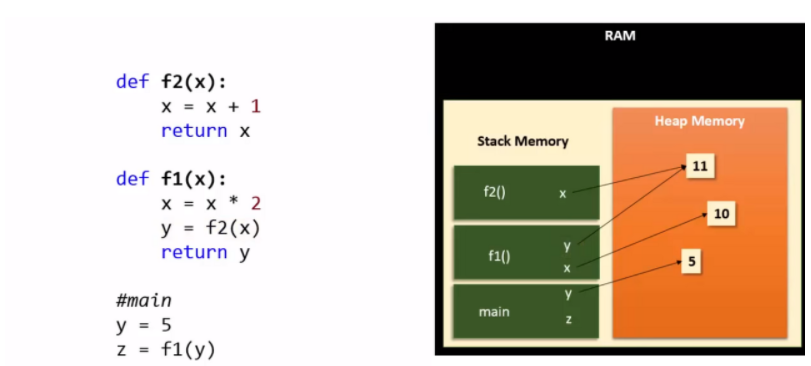
- main 함수에서
y=5라고 선언할 시 heap 영역에는5가 생성이 되고, 이를y가 가리키게 된다. 동시에z=f1(y)를 통해 stack 영역에f1()을 쌓는다. f1(y)내부에서 전달받은 인자인 x(main에서는 y, 즉 5)의 값이10이 되어 heap 영역에 생성 되고,f1()내에서x가 이를 가리키게 된다. 그 다음f1()내의 남은 함수인y=f2(x)를 처리하기 위해 stack 영역에f2()를 쌓는다.f2(x)에서 x=10이며 전달받은 x는 새롭게11이 heap 영역에 생성되고 이를 x가 가리키게 된다.- 메소드와 변수는 stack 영역에, 값들은 heap 영역에 생성되고 이를 변수가 가리키는 형태로 저장된다.
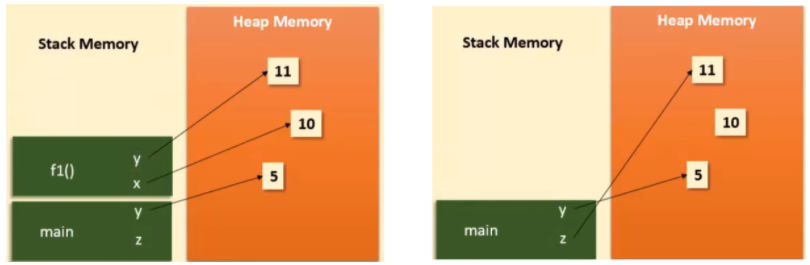
- 가장 먼저 stack의 윗부분인
f2()가 해제된다. 동시에f2()안의x가11을 가리키던 포인터(?)가 사라진다. - 그 다음, stack의
f1()이 해제되는데, 이 때y=11이며 f1()안의 x는 사라지기 때문에 10 int object도 사라진다. 10을 가라키는 변수가 삭제하는 것이reference counting이 0이 됨에 따라 object를 없애는 가비지 컬렉터의 역할이라고 본다. - 마지막으로 처음 선언한 y=5, 모든 stack 영역을 끝내고 나온 결과값인 z=11만 남게된다.
7. def와 lambda의 차이점은 무엇인가?
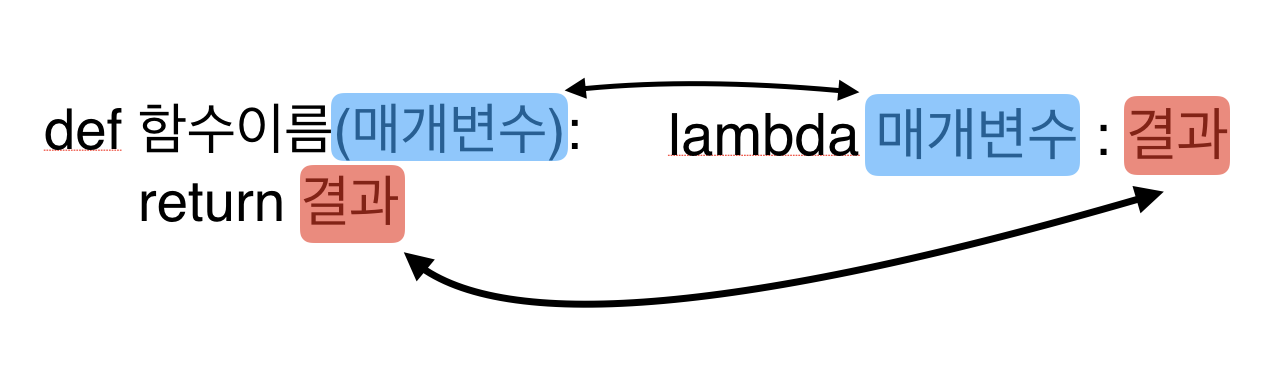
- lambda는 단일 표현식 함수이며, def는 다중 표현식 함수이다.
- lambda는 함수 객체를 생성하고 반환하며, def는 함수를 생성한 뒤 나중에 호출할 이름을 지정한다.
- lambda는 리스트와 딕셔너리에서 사용할 수 있도록 지원한다.
lambda는 익명함수이며 코드가 간결하고 메모리를 절약할 수 있다. 이에 반해 def는 클래스를 통해 생성된 객체 인스턴스로, 그 객체를 함수이름과 동일한 변수에 담게 되는데, 이 시점에 함수객체는 메모리에 올라가 호출되기를 기다린다. 만약, 한 번만 사용될 함수라면 메모리 낭비가 된다.
