[DE인듯DE아닌DE가되고싶은]
1.오랜만에 들고온 일상

우선, 그간 취활에 집중했다.무작정 어찌저찌 욱여넣은 이력서를 들고 하루에 3~4개, 일주일에 20개씩은 넣었던 것 같다. 혼자 공부하는 것에 한계를 느껴서 도대체 어떤 걸 공부하면 좋을지 면접장에 가서 물어봤다. 첫 주에 운이 좋게도 4군데 중 3군데를 2차 면접까지
2.그래서 첫 출근부터 무얼했냐

별 거 안 했다.회사는 아직 어플 개발 단계이고, 데이터팀으로써 할 수 있는 일은 데이터 아키텍처를 그리거나 파이프라인을 짜는 거라고 들었지만 우리 회사는 특수하게 본사의 다른 팀이 거의 주도하고 나머지 팀이 대기하는 그런 흐름이라 할 게 없었다. 그래서 나는 개인공부
3.[책리뷰]데이터 분석가의 숫자유감(권정민 저)

책 구매 링크<예스24 미리보기 캡처>만화라 읽었다. 솔직히.데이터 분석가로 취업한 동기의 추천을 받아 책을 한 권 읽었다. 전혀 부담스럽지 않은 만화라 한 시간에 다 읽은 것 같다. 책 속의 화자는 '숫자에 민감한' 데이터 분석가로 일하고 있는 회사원이고, 주로
4.[Flask]SQLAlchemy 도전

임무라고 할까. 회사에서 처음으로 데이터팀다운 일(?)을 했다. 바로 FLASK로 DB 서버 구축하기.이유는 모르겠지만(아마 MSA...?), 회사에서는 백엔드 서버, DB 서버, AI팀 서버를 따로 구축한다고 한다. 그래서 데이터팀에서 그나마 DB랑 웹을 만져본 내가
5.[대학합격예측]EDA 및 간단한 모델 생성
회사에서는 여전히 데이터팀보다는 기획이나 설계 파트에 관한 업무를 진행하고 있다. 따라서 나의 커리어를 위해 개인적으로 프로젝트에도 참가하고 있었다. 그러던 중, 지인으로부터 대학 합격 모델을 만들 수 있냐는 제안을 받았다. 그래서 3년치의 성적 데이터를 받아 코랩에서
6.[Pytrends]구글 트렌드 API
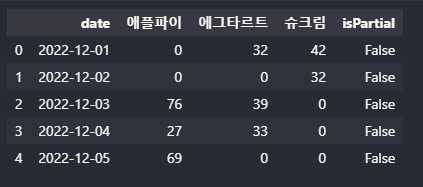
개인 프로젝트 중에 구글, 네이버와 같은 사이트들을 크롤링 해야하는 일이 생겼다. 네이버야 api로 제공하던 많은 부분들을 제한해와서 결국 bs4로 크롤링하기로 했지만, 구글은 그래도 뭔가 더 주지 않을까...! 해서 찾아본 결과, 한 오픈소스 라이브러리를 발견했다.
7.[Scrapy]네이버 View 크롤링
보안상의 이슈로 결국 DB 서버를 Django를 통해 만들기로 결정되었다. 그런데 특이하게 서브미션으로 주어진 게 있었는데, 바로 Scrapy를 Django에 접목시키는 것이다.Django에서 키워드를 입력하면 Scrapy가 작동되어 url에서 크롤링해서 DB에 적재하
8.[Pynecone]파이썬으로 React & Next.js가....?
python을 배우면서 python의 영역이 점점 넓어진다는 이야기를 들은 적이 있다. 하지만 실제 채용 공고들을 뒤적여봤을 때 결국 메인 언어는 JAVA, C++, C그러던 중 주말에 팽팽 놀다가 자려고 누운 일요일 밤, 노마드코더의 유튜브를 보고 "이거시 모다냐..
9.[회고]2022년 그리고 2023년
커리어 전환을 하고 원하던 데이터 직무로 취업을 했다. 하지만 생각보다 원하던 업무내용과는 거리가 있기에 평소에 공부하고 싶었던 것들을 공부하는 시간들을 가졌다.12월부터 지금까지리눅스Django보안 및 네트워크중급 Python크롤링 툴데이터 모델링등을 공부했다. 그리
10.[스토리]User Story Mapping
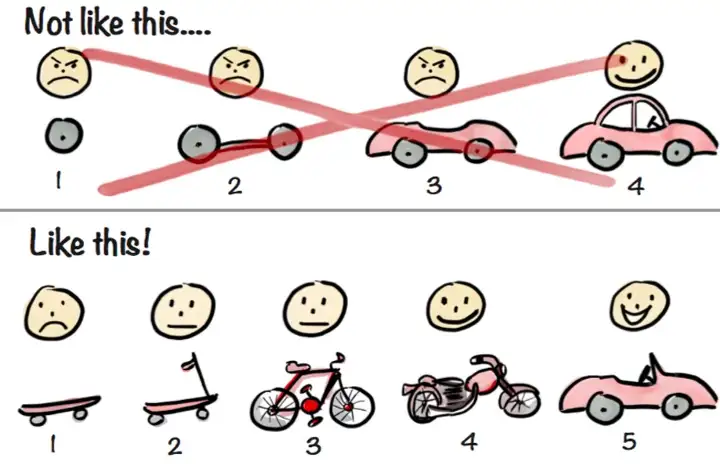
🤨 갑자기 스토리? 왜? 갑작스레 소프트웨어 설계팀에 들어가게 되었다. 사실 소프트웨어 설계라고는 해도 설계는 거의 끝난 상태였고 유지/보수를 위해 PM과 함께 일할 각 팀 사람들을 뽑아 만든 팀이다. 비전공자에 아직 코드도 버벅대면서 치지만 설계 파트에 들어가게
11.[Python]파이썬 자세히 공부하기 1️⃣
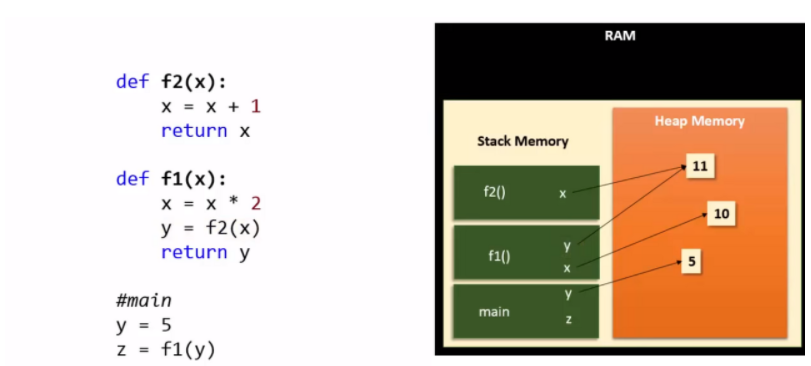
1. 파이썬이란 무엇인가, 장점은 무엇인가 파이썬은 현재 가장 많이 사용되고 있는 인터프리터 언어이며, 실행 전에 컴파일 할 필요가 없다. 변수를 선언할 때 데이터 유형을 언급할 필요가 없는 동적 언어이다. 파이썬은 객체지향언어로, 컴포지션(다른 클래스의 일부 메서드
12.[Python]파이썬 자세히 공부하기 2️⃣
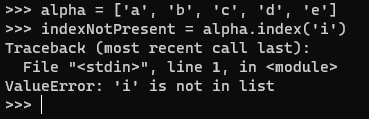
8. 모듈 "re"를 이용하여 이메일 id를 확인하는 표현식을 작성하라. > #### 9. 아래 코드의 아웃풋 값은 무엇인가? 답은 []이다. 만약, print(list[10])이라고 단순히 인덱싱을 하면 IndexError: list index out of ran
13.[Python]파이썬 자세히 공부하기 3️⃣
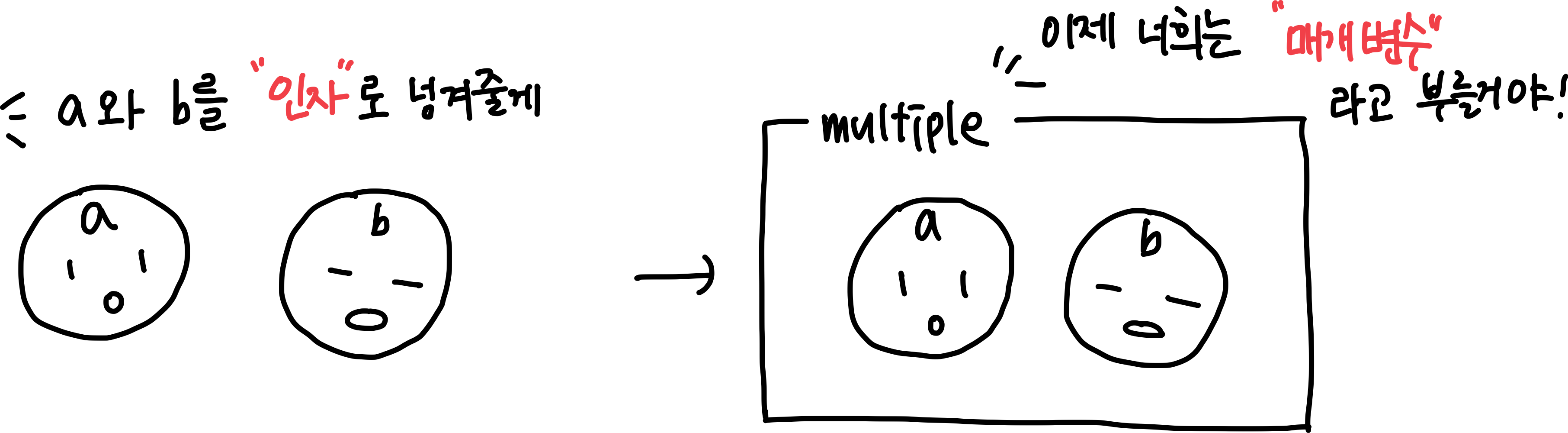
Q-21: 파이썬에서 Docstring이란 무엇인가? A docstring is a unique text that happens to be the first statement in the following Python constructs: Module, Functi
14.[Python]파이썬 자세히 공부하기 4️⃣
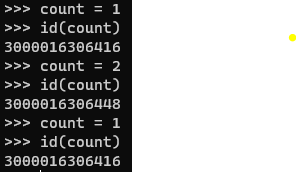
파이썬에서 continue는 점프문으로, 블록의 나머지 명령어들을 모두 실행하지 않은 채 루프의 다음 반복을 실행하기 위해 컨트롤을 이동시킨다. while문과 for문 모두에서 사용가능하다.자주 헷갈리는 개념으로, pass와 break가 있다.pass : 실행할 코드가
15.[DMS]설계
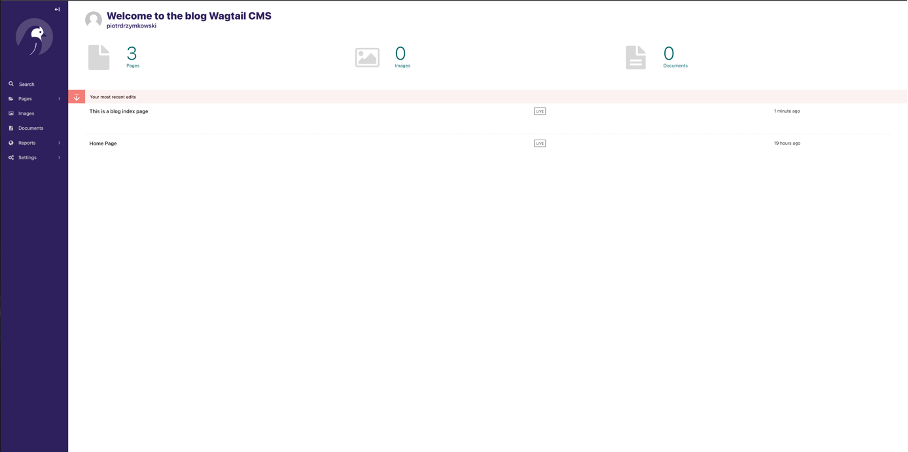
현재 회사에서는 DMS 즉, Django로 웹을 구축하여 서버내의 데이터들을 관리하는 시스템을 개발하고 있다. 오늘은 그를 위한 간단한 컨셉과 설계에 대해 설명하고, 그간 겪은 문제점과 해결책에 대해 정리해보려 한다. 우리 회사는 다양한 데이터셋을 활용해 AI 모델을
16.[DMS]admin 페이지 커스터마이징 + 업로드 기능
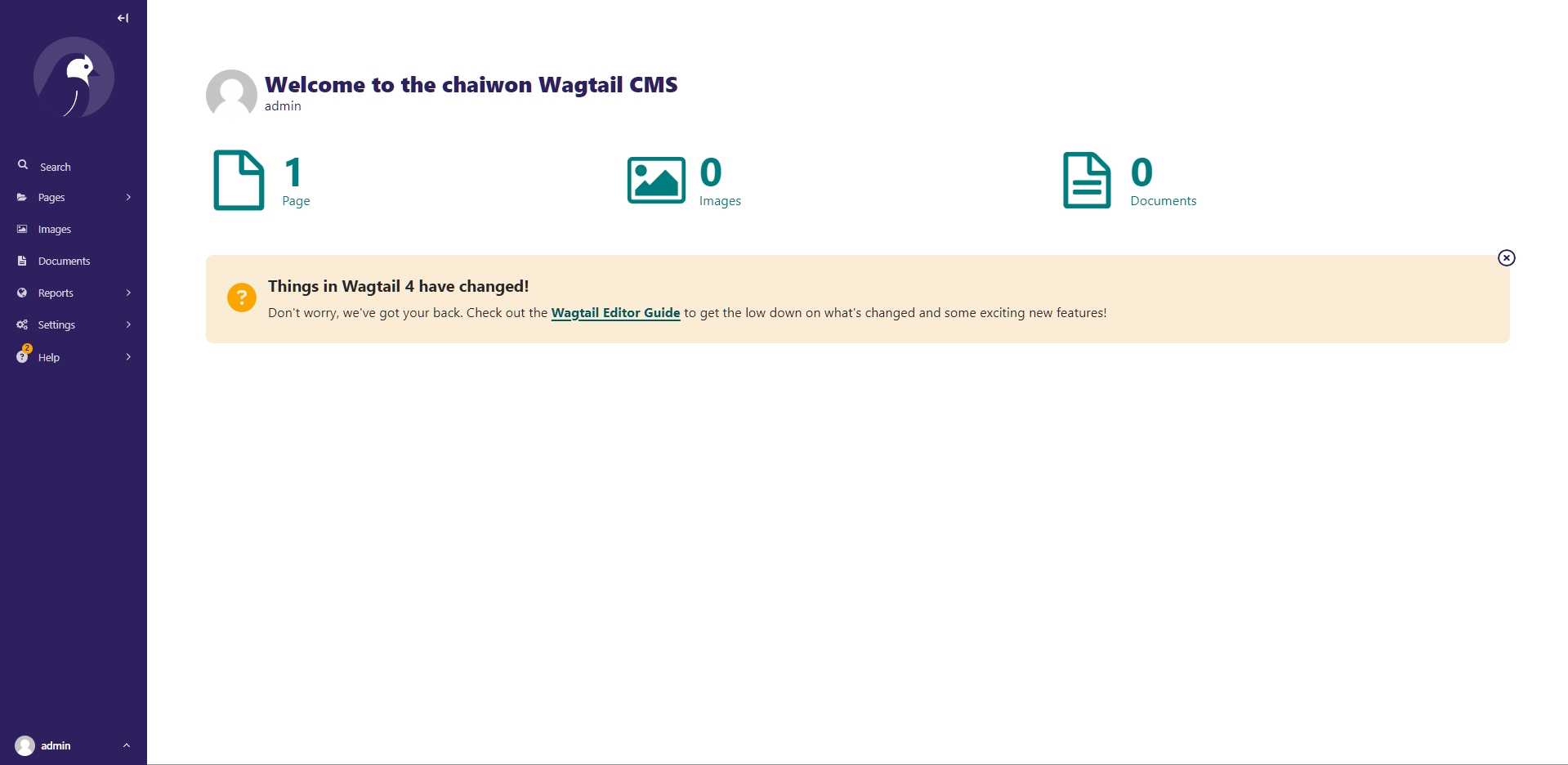
우선, 서버를 켜주고 admin 페이지에 접속해본다.로그인 후 위와 같은 화면이 나온다면 성공이다.왼쪽의 사이드바를 보면 기본적으로 wagtail이 제공해주는 기능들이 들어가있다. 오늘은 첫 화면과 사이드바를 커스터마이징 해보겠다. 기본적으로는 django의 상속 매커
17.Spark로 S3의 객체 접근하기
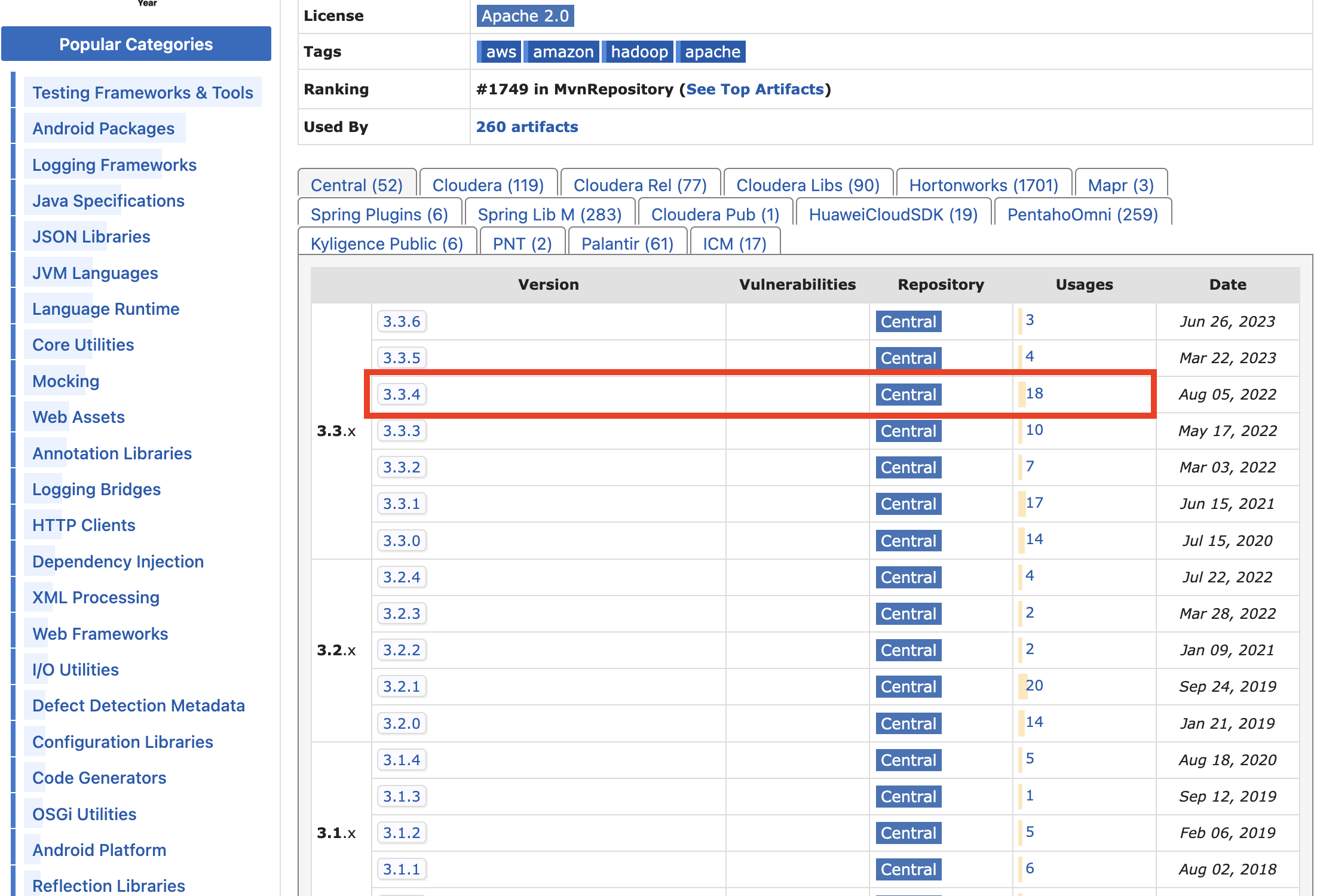
Spark로 S3에 업로드 해둔 파일을 가져와 작업하는 경우가 있다. 이 경우, 방법이 두 가지이다.boto3로 s3에 접근한다. S3getFile 라이브러리를 통해 s3에 접근한다. 1번의 경우, 파일에 따라 전부 불러오지 못 하는 문제가 생겨, 나는 2번 방법으로
18.[AWS EMR]vCPU 오버 에러 해결하기
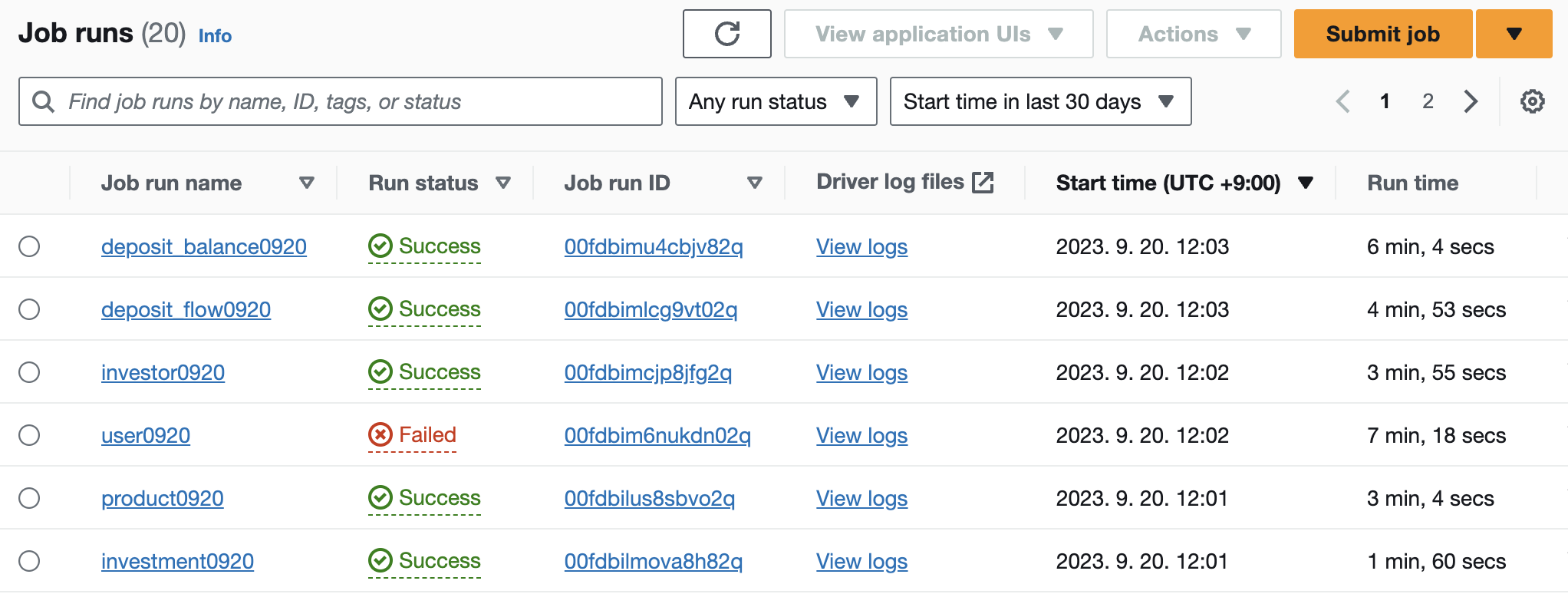
Job failed as account has reached the service limit on the maximum vCPU it can use concurrently.
19.[AWS Glue]CDC
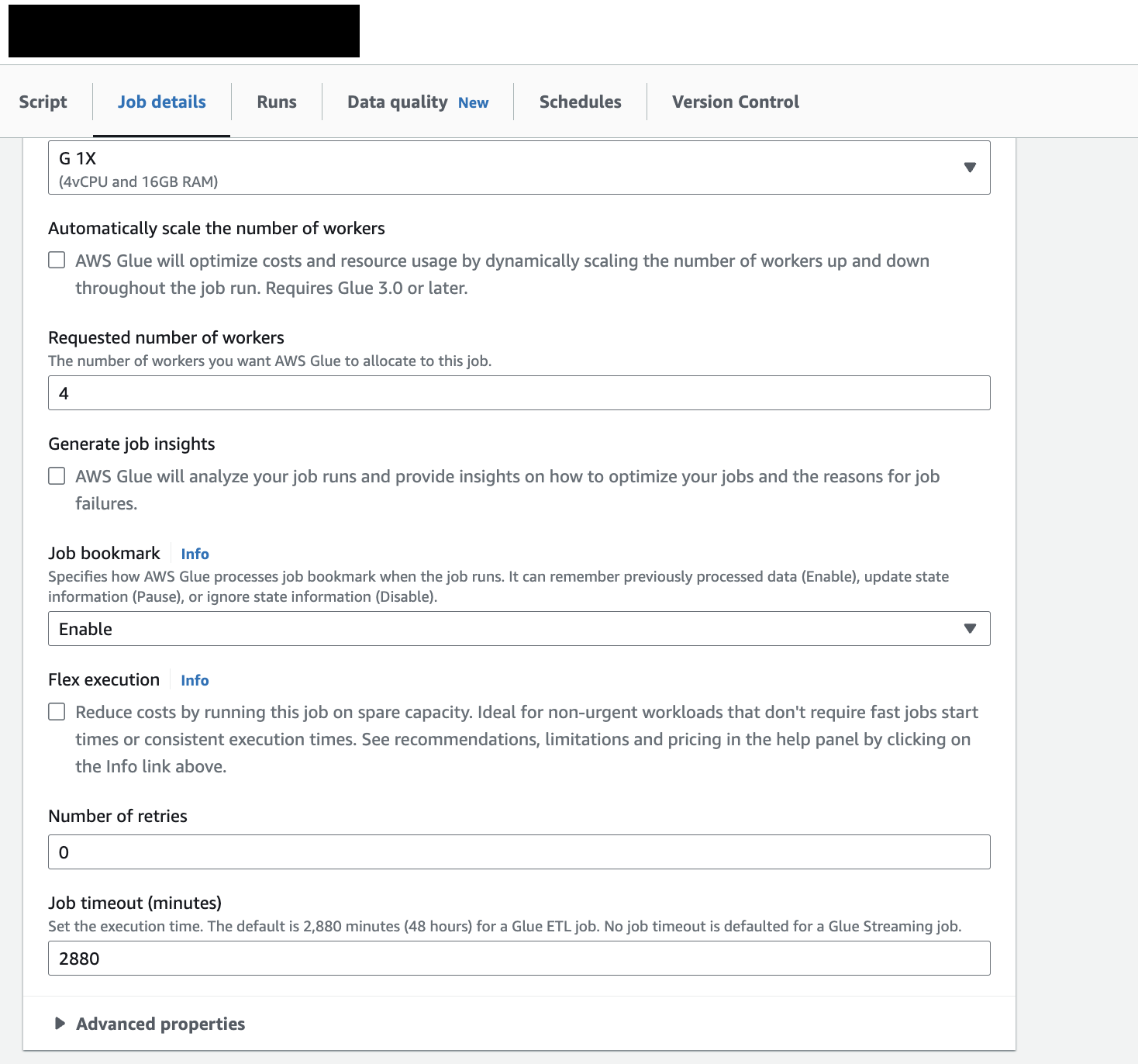
문제 상황S3의 데이터를 우리의 Data Mart인 Postgresql로 옮기는 ETL job을 run하면 중복 데이터가 계속 쌓인다. 예를 들어, 어제 100줄짜리 user테이블이 담긴 parquet 파일이 S3에 담겨있었고, 이걸 postgresql로 옮기는 ETL
20.[MLflow]MLflow 사용법 1️⃣ (feat.LGBM)
공식 튜토리얼에 나오는 내용을 기반으로 하되, 직접 MLflow를 사용해보면서 유의할 점들에 더 집중해서 작성한다. 머신러닝의 생애주기를 위한 오픈 소스 플랫폼간단하게 말해서, ML 모델의 CI/CD/CT를 위한 툴이라고 생각하면 된다. ML 모델을 배포하기 위한 툴(
21.[MLflow]MLflow 사용법 2️⃣(feat.LGBM)
지난 포스팅아까 만들어둔 3개의 파일 중 나머지 2개를 작성한다. 이렇게 하는 것이 MLflow Projects를 패키징하는 과정이라고 생각하면 된다. train.py : 모델 학습 시킬 파일MLmodel : 전체적인 프로젝트 관리를 위한 파일python_env.yam
22.[Airflow]Postgres Operator
Postgres to S3 새로운 파이프라인을 짜면서 기존 RDB인 Postgres에서 raw 데이터가 쌓이는 S3로 보내는 DAG를 작성하다보니, aiflow에서는 특별히 postgres만을 위한