🏨 사실은 이것은 빌드업이다
보안상의 이슈로 결국 DB 서버를 Django를 통해 만들기로 결정되었다. 그런데 특이하게 서브미션으로 주어진 게 있었는데, 바로 Scrapy를 Django에 접목시키는 것이다.
Django에서 키워드를 입력하면 Scrapy가 작동되어 url에서 크롤링해서 DB에 적재하는 것이다.
다 좋은데, 우선 Scrapy 써 본 적이 거의 없기 때문에 바로 복습에 들어갔다.
Scrapy를 검색하면 많은 튜토리얼이 나오기 때문에 적당한 걸 찾아서 따라해보면 되지만, 나는 우선 최근에 크롤링했던 네이버를 크롤링 하기로 했다. 키워드를 입력받아서 그 페이지를 크롤링 하는 건 아직 못 구현 못 했지만 우선 키워드가 "가게"인 것을 구현해보기로 했다.
또한, 내 블로그의 목적이기도 한데, 정확하고 올바른 정보를 전달하는 게 아니라, 초보가 진행하면서 만나게 될 에러들을 정리하는 데 중점을 둘 것이다.
Install
간단하다.
가상환경 만들어 주고 -> pip로 인스톨 해주고 -> 프로젝트 생성하고 -> 프로젝트 디렉토리로 들어가기
$ python -m venv <가상환경이름> # 나는 venv로 했다.
$ pip install scrapy
$ scrapy startproject <프로젝트 이름> # 나는 testscraper로 했다.
$ cd <프로젝트 이름> 그러면 아래와 같은 폴더 구조가 보일 것이다. 색은 신경쓰지 말자.
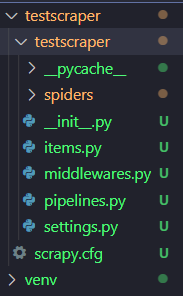
실제 일은 저 spiders라는 폴더에 있는 스파이더 파일(후에 작성)이 해 줄 것이고, 우리는 items.py랑 pipelines.py로 DB랑 연결하고, settings.py로 몇 개 설정을 해주면 된다. 실질적으로 우리가 만질 파일은 4개 정도이다.
Setting
이제 크롤링을 하기 전에 준비할 것이 있다.
바로, "어떤 사이트를 크롤링 할 것인가" 이다. 기업들이 바보가 아닌 이상 열심히 만들어놓은 사이트를 다 크롤링하게 두진 않는다. 보안 관련 이슈도 있고 해서 막아두는 경우가 있는데, 아무 사이트나 집어넣고 크롤링 할래! 하면 아래와 같은 에러를 마주하게 된다. 참고로 네이버를 크롤링하려고 시도했다.

이렇게 처음엔 200으로 뜨지만, 아래줄과 같이 Forbidden 당한다. 따라서 우리가 크롤링 하고자 하는 사이트를 선정하는 데에는 2️⃣가지 방법이 있다.
-
헐. 그럼 크롤링 되는 사이트를 찾자...!😟
-
어쩌라고. 학습용이니까 봐줘😩
본인이 어떤 타입인지 잘 생각해서 선택하면 된다. 둘 다 해결방법은 간단하다.
- 1번 ➡ 브라우저에
<본인이 크롤링 하고 싶은 사이트 url>/robots.txt입력- 그러면 각 사이트마다 크롤링 가능한 범위와 안 되는 범위를 알려준다.
- 예를 들어, 내가 검색한 네이버는 모든 걸 Disallow한다. 치사빤쓰다.
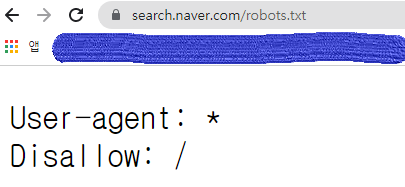
- 쿠팡은 해주는 것도 있고, 아닌 것도 있다.
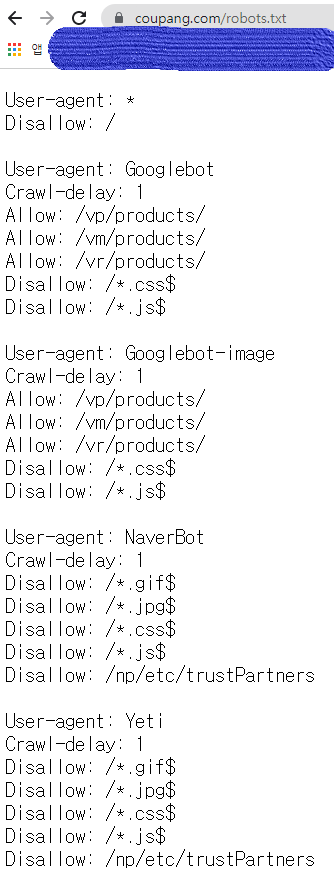
이렇게 크롤링 가능한 사이트를 찾는 방법이 있다. 하지만 생각해보자. 세상살이 그렇게 맞춰주고 살아가면 날 보자기로 보는 사람들이 있다. 따라서 나는 2번 방법을 선택하는 것도 나쁘지 않다고 본다(물론 법적으로는 책임 못 진다).
- 2번 ➡
settings.py에 들어가서ROBOTSTXT_OBEY = True로 되어있는 걸False로 바꿔준다. 학습용에 한해서 robotstxt를 무시한다.
그 다음, 또 설정해줄게 있다. settings.py에 들어가서 맨 아래에 FEED_EXPORT_ENCODING = 'utf-8'를 추가해준다.
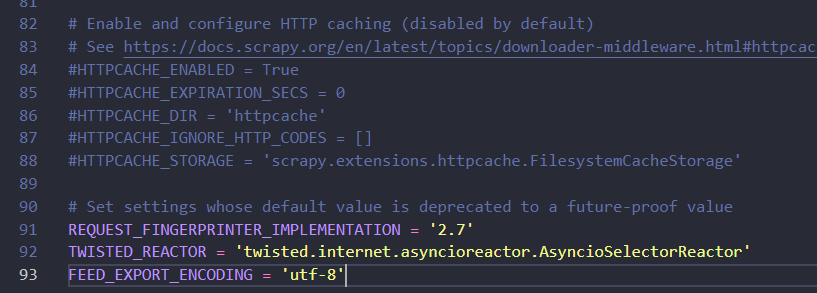
안 해주면 한국어로 된 사이트 크롤링 하면 인코딩 방식이 달라 숫자로만 나온다.
마지막으로, 크롤링을 많이 하면 블락 당한다. 사전에 방지하자. 같은 settings.py에서 아래를 고쳐주자.
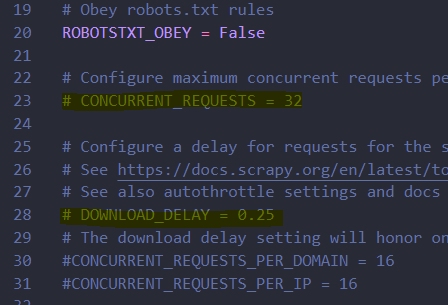
우선 주석처리 제거해주고,
- 동시에 request 보내는 파라미터인
CONCURRENT_REQUESTS=에 원하는 숫자를 넣는다. default는 16. - 페이지 다운로드 할 때 기다리는 시간 파라미터인
DOWNLOAD_DELAY=에 원하는 숫자를 넣는다. default는 0.
이제 설정은 끝났다. 다음은 진짜 spider를 만들 차례다.
사실 거짓말이다. 페이지 파싱부터 확인해야한다.
공식문서나 유튜브 강의들을 보다보면 scrapy shell을 켜서 이것저것 css 태그들을 확인하던데 성격 급한 한국인으로써 "그런거 왜 해야됨. selenium으로 다져진 xpath 신공을 보여주지" 하고 무시하고 시작했다가 삽질 오지게 하고 어른들이 하라는 덴 다 이유가 있구나 싶었다. 건너뛰지 말고 얌전하게 쉘 창을 열자.
$ scrapy shell그러면 주르륵 로그들이 나오고 뭐든 치고 싶게 생긴 >>> 표시가 뜰 것이다. 거기에 이렇게 입력하자.
>>> fetch('크롤링 할 사이트')
>>> responsefetch 명령어 입력 후 멈춘 것 같다면 살포시 엔터를 눌러주면 된다.
그리고 response 입력 후 <200>이 뜨면 잘 연결된 것이다.
이제, 파싱을 하면 되는데, 파싱은 나도 잘 못 해서 여러분들을 응원만 하겠다. 화이팅(다른 블로그를 참고하자).
다만, 파싱하면서 주의해야 할 점이 있다.
response.css('')나response.xpath('')를 쓸 텐데, 개인적으로 셀레니움으로 할 때는 xpath가 편했지만, 요소를 특정시켜버리기 때문에 웬만하면 css를 쓰자.- 그리고 text만 가져오고 싶을 때, css랑 xpath랑 방식이 다르다.
response.css('~~~::text')response.xpath('~~~/text()')
- 그리고 또 하나, 예를 들어 css_selector를 긁어왔는데
div > ul > li:nth-child(1)와 같은 형태면:nth-child(1)요 부분을 지워줘야한다. 그래야 list 전체가 긁어와진다. get()은 하나만 반환.getall()이나 뒤에 아무것도 안 붙히면 리스트로 전체 반환한다. ex)response.css('a.content')-> 똑같은 태그로 묶인 거 리스트로 전부 반환한다.- 속성을 가져오고 싶을 때는
.attrib['<속성값>'] - 👀꼭 잘 파싱 되는지 하나하나 쳐 보면서 확인하자👀
다음은 내가 파싱한 페이지와 코드이다. 네이버에 가게라고 입력했을 때 페이지이다.
>> views = response.css('#main_pack > section.sc_new.sp_nreview._prs_rvw._au_view_collection > div > div._svp_list > panel-list')
>>> len(views) # 전체 리스트 다 들어갔는지 확인
8
>>> views.css('div.total_area > a::text').get() # 타이틀
'탁월했던 부산 반찬'
>>> views.css('div > div.total_info > div.total_sub > span > span > span.elss.etc_dsc_inner > a::text').get() # 블로그 이름
'새벽감성캘리그라피'
>>> views.css('div.total_area > a').attrib['href'] # 포스팅 url
'https://blog.naver.com/dudghk4170/222958584728'
>>> import re
>>> re.sub('<.+?>', '', str(views.css('div.total_wrap.api_ani_send > div > div.total_group > div > a > div').get()), 0).strip() # 내용
'지난 금요일 매번 시키는 배달음식도 질리고 외식은 부담되어 자주 찾는 부산 반찬가게에서 일주일 식량을... 내부로 들어서면 여느 가게랑 비슷한 크기로 아늑한 공간을 마
주할 수 있었고요. 갓 만들어진 국들을 작은...'약 한 시간 반을 쉘에다 쳐보면서 얻어냈다. 나 같은 삽질을 부디 적게 하길 바라며 이제 진짜 스파이더를 만들어보자.
🕷 Spider
프로젝트 폴더에 spiders폴더에 대충 아무거나 이름 붙여서 파이썬 파일을 만들어준다.
그리고 파일을 열어 아래와 같이 구조를 짜준다.
import scrapy
import re
class TestSpider(scrapy.Spider): # 클래스명은 대충 짓는다. 언 헷갈리게만.
name = 'naver' # 얘를 잘 지어줘야 한다. 이 name을 가지고 스파이더를 작동시킬 것이다.
start_urls = ['https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=1&ie=utf8&query=%EA%B0%80%EA%B2%8C'] # 크롤링 할 url을 넣어준다.
def parse(self, response) :
posts = response.css('#main_pack > section.sc_new.sp_nreview._prs_rvw._au_view_collection > div > div._svp_list > panel-list > div > ul > li') # 여기에 파싱할 요소들을 전부 리스트로 담아서 변수에 저장해준다.
for post in posts : # for문을 돌면서 한 줄씩 요소들을 뽑아낸다.
try :
yield {
'title' : post.css('div.total_area > a::text').get(),
'author' : post.css('div > div.total_info > div.total_sub > span > span > span.elss.etc_dsc_inner > a::text').get(),
'link' : post.css('div.total_area > a').attrib['href'],
'contents' : re.sub('<.+?>', '', str(post.css('div.total_wrap.api_ani_send > div > div.total_group > div > a > div').get()), 0).strip()
}
except :
print("Error happened")이렇게 짜면 끝이다!
물론, 여기에 페이지를 옮겨서 뭐 끝까지 다 크롤링을 하거나, 더 다양한 내용을 크롤링 할 수 있겠지만, 내 목적은 크롤링을 잘 하는 것보다 Django에 넣기전에 간단하게 개념을 알아보자는 것이기 때문에 거기까진 하지 않겠다. 여기를 참고바란다. 아니면 여기.
Crawl
이제 스파이더를 작동시켜보자. 쉘 스크립트로 가서 아래와 같이 명령어를 친다.
# 간단하게 크롤링만 돌릴거면
scrapy crawl <스파이더 이름> # 나의 경우는 naver
# json 형식으로 저장하고 싶으면
scrapy crawl <스파이더 이름> -O <저장한 파일명>.jsonjson파일로 저장할 때 -O(대문자)를 쓰면 덮어쓰기, -o(소문자)를 쓰면 기존 파일에 추가하기이다.
그러면 아래와 같이 json파일이 생긴 것을 확인 할 수 있다.
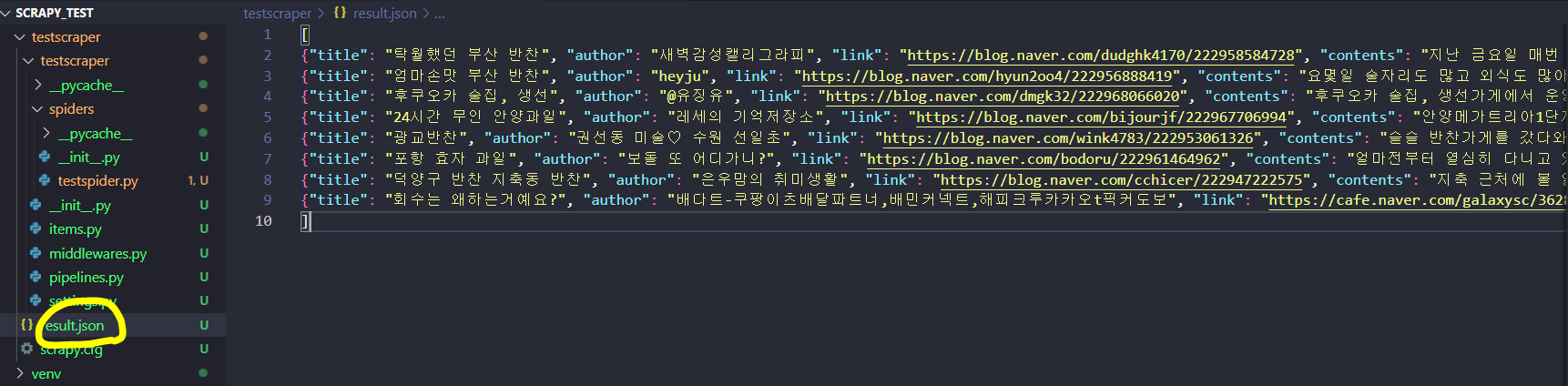
끝!
다음엔 items랑 pipelines 파일로 db에 적재하는 것을 다뤄볼까 한다.
그리고 요새 회사에 들어오고 개인 프로젝트도 하면서 느끼는 건데, 무언가를 완벽히 안다는 것은 정말 어렵구나. 하나하나 쌓아가다보면 언젠간 완벽에 가까워지는 날이 올까싶은 생각이 든다.
면접을 보면서 많은 면접관들이 내게 "완료주의가 무엇이라고 생각하시나요?" 라는 질문을 해왔고, 나는 그에 대해 "완벽보단 완료를 중요하게 생각하고, 완벽해지기까지 기다리는 것이 아니라 하루하루 하나하나씩 완료해나가는 것을 지향하고 있습니다"라고 패기롭게 대답해왔는데, 요새 들어 새로 익혀야하는 스킬들이 많다보니까 어디까지가 완료이고 어디까지가 완벽인지 헷갈리기 시작했다.
그러던 중 오늘 보게 된 워킹맘들의 인터뷰에서 아주 살짝의 위안을 받았다.
"70점도 충분해요 대신 계속하세요"
"대충이라는 벌레를 키우자. 그 벌레도 모이면 태산이 돼요."
그래. 내가 하고있는 일들이, 쓰고있는 글들이 70점짜리일지는 몰라도 70점씩 100개 하면 7천점이다. 그렇게 쌓아가자라는 생각으로 오늘도 70점에서 75점, 80점까지는 해보자고 다짐을 하며, 퇴근을 기다려야겠다.
