Spark로 S3에 업로드 해둔 파일을 가져와 작업하는 경우가 있다. 이 경우, 방법이 두 가지이다.
- boto3로 s3에 접근한다.
- S3getFile 라이브러리를 통해 s3에 접근한다.
1번의 경우, 파일에 따라 전부 불러오지 못 하는 문제가 생겨, 나는 2번 방법으로 s3에 접근하여 파일을 불러오는 방법을 선택했다.
📕 Spark 설치부터 S3getFile 라이브러리 설치까지의 순서
- Python 설치
- JAVA 설치
- SPARK 설치
- S3getFile 설치
- 환경변수 확인
- 버젼 확인
Python 및 JAVA 설치
spark는 3.x 대 버젼을 설치할 것이기 때문에 Python은 3.4+, JAVA는 8혹은 11을 사용한다. 본인의 Python, JAVA 버젼을 확인한 후 업그레이드/다운그레이드 해주면 된다. 만약 없다면 버젼을 잘 보고 설치한다. 참고블로그
$ python3 --version
Python 3.9.6
$ java --version
openjdk version "1.8.0_382"
OpenJDK Runtime Environment (Zulu 8.72.0.17-CA-macos-aarch64) (build 1.8.0_382-b05)
OpenJDK 64-Bit Server VM (Zulu 8.72.0.17-CA-macos-aarch64) (build 25.382-b05, mixed mode)위와 같은 커맨드를 쉘에서 실행했을 때 command를 못 찾겠다는 에러가 나오면 환경변수 설정이 안 된 것이다. 아래와 같이 환경변수가 잘 설정되었는지 확인해준다.
$ vim ~/.zshrc # bash가 기본쉘이면 ~/.bashrc
### .zshrc에 아래 코드를 추가
# 파이썬 환경변수 잡아주기
export PATH=/usr/local/bin:$PATH
# 자바 환경변수 잡아주기
export JAVA_HOME=/Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home # 본인의 java 폴더 경로를 넣어야한다.
export PATH=$PATH:$JAVA_HOME/bin
$ source ~/.zshrc # 저장한 .zshrc 파일 업데이트 Spark 설치
https://spark.apache.org/downloads.html 에서 원하는 버젼의 spark를 다운로드 받는다. 그런 뒤 환경 변수로 SPARK_HOME을 잡아주고 잘 깔렸는지 확인한다. 참고블로그
$ pyspark --version
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.3.3
/_/
Using Scala version 2.12.15, OpenJDK 64-Bit Server VM, 1.8.0_382
Branch HEAD
Compiled by user yumwang on 2023-08-04T15:08:53Z
Revision 8c2b3319c6734250ff9d72f3d7e5cab56b142195
Url https://github.com/apache/spark
Type --help for more information.
# 아래와 같은 커맨드로도 스파크가 잘 깔렸는지 확인 가능
$ spark-shell
$ pyspark마찬가지로, 위의 커맨드 중 하나라도 실행이 안 되면, 높은 확률로 환경변수를 못 잡고 있는 것이다. 아래와 같이 환경변수가 잘 설정되었는지 확인해준다.
$ vim ~/.zshrc # bash가 기본쉘이면 ~/.bashrc
### .zshrc에 아래 코드를 추가
# 스파크 환경변수 잡아주기
export SPARK_HOME=/usr/local/bin/spark-3.3.3-bin-hadoop3 # 본인이 spark 다운로드 받은 경로로 대체
export PATH=$PATH:$SPARK_HOME/bin
export PYSPARK_PYTHON=python3 # python3의 경우는 명시해주야 pyspark를 에러없이 사용할 수 있다.
$ source ~/.zshrc # 저장한 .zshrc 파일 업데이트 참고로, 나는 pyspark --version 커맨드에서는 버젼이 잘 나왔는데 spark-shell이나 pyspark 커맨드를 입력하면
Service 'sparkDriver' could not bind on a random free port. You may check whether configuring an appropriate binding address.
이런 에러가 자꾸 나왔다. 이건, Spark가 드라이버를 실행할 때 바인딩할 주소를 못 찾는건데, 아래와 같은 방법으로 해결 가능하다.
$ cd $SPARK_HOME/conf
$ ls
fairscheduler.xml.template metrics.properties.template spark-defaults.conf.template workers.template
log4j2.properties.template spark-env.sh.template
$ cp spark-defaults.conf.template spark-defaults.conf
$ vim spark-defaults.conf
### spark-defaults.conf 파일에 아래의 코드를 추가
spark.driver.bindAddress 127.0.0.1S3getFile 설치
https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-aws 에 가서 두 가지를 다운 받을 것이다.
- Apache Hadoop Amazon Web Services Support
- AWS SDK For Java Bundle
우선 링크를 클릭하고 Apache Hadoop Amazon Web Services Support를 먼저 다운로드 할 것이다. 많은 버젼 중 Usages가 많은 것 중 선택한다. 나는 최신 버전 중 3.3.4를 선택했다.
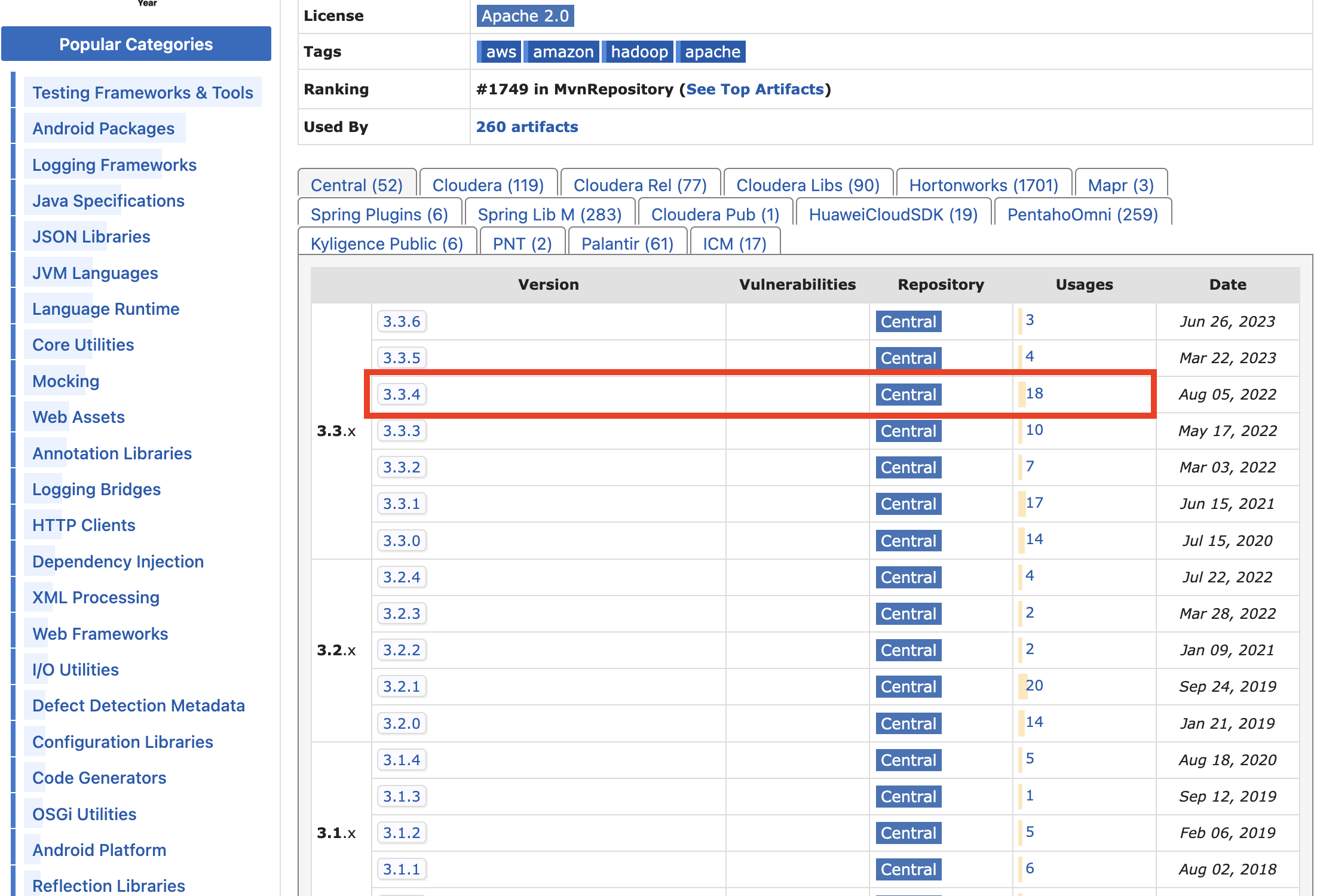
버젼을 클릭하면 다음 페이지가 나오는데 jar 파일을 다운 받는다.
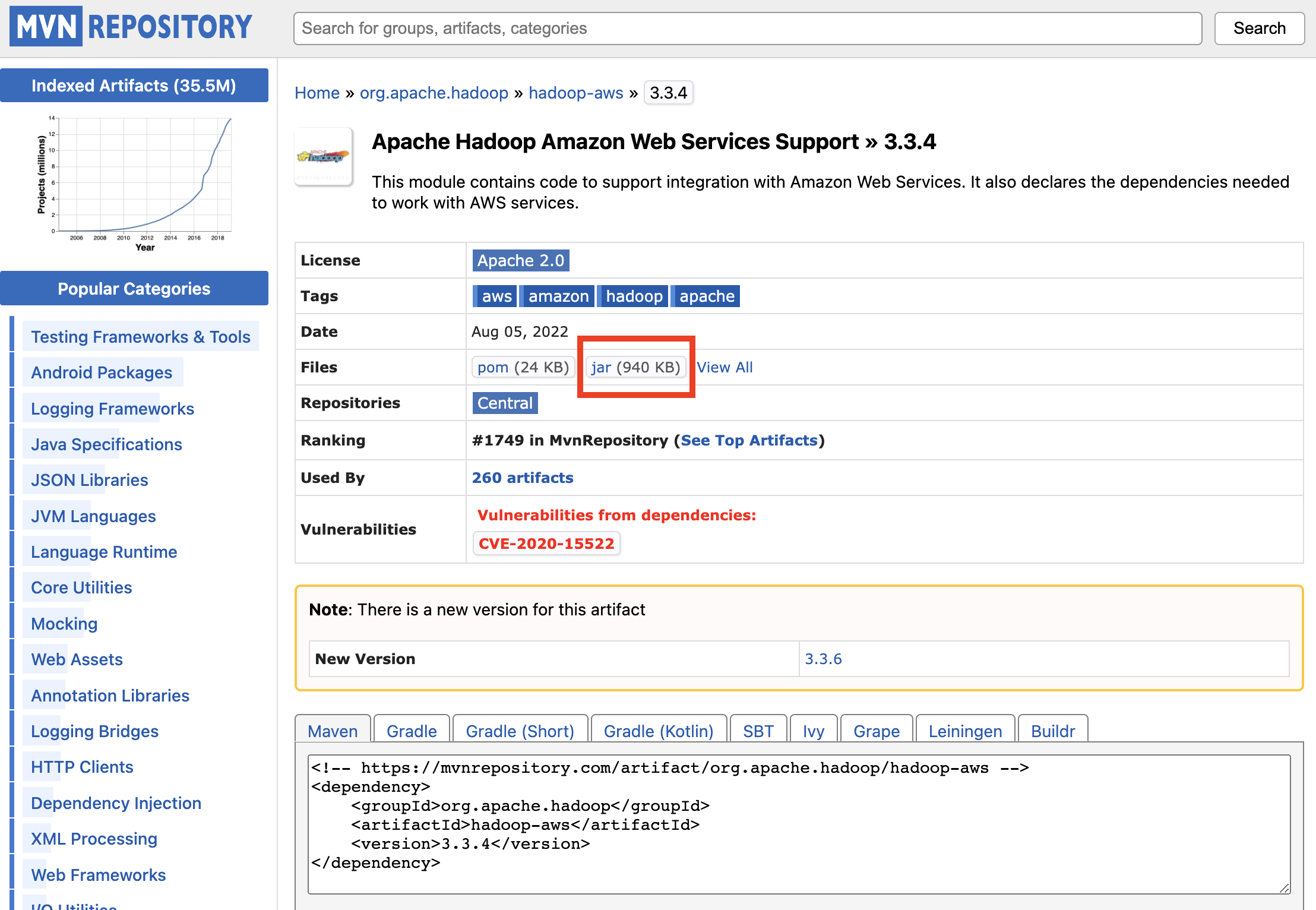
그리고 아래쪽으로 스크롤 하면 아래와 같이 나오는데, 이 때 AWS SDK For Java Bundle를 다운받아야 한다.
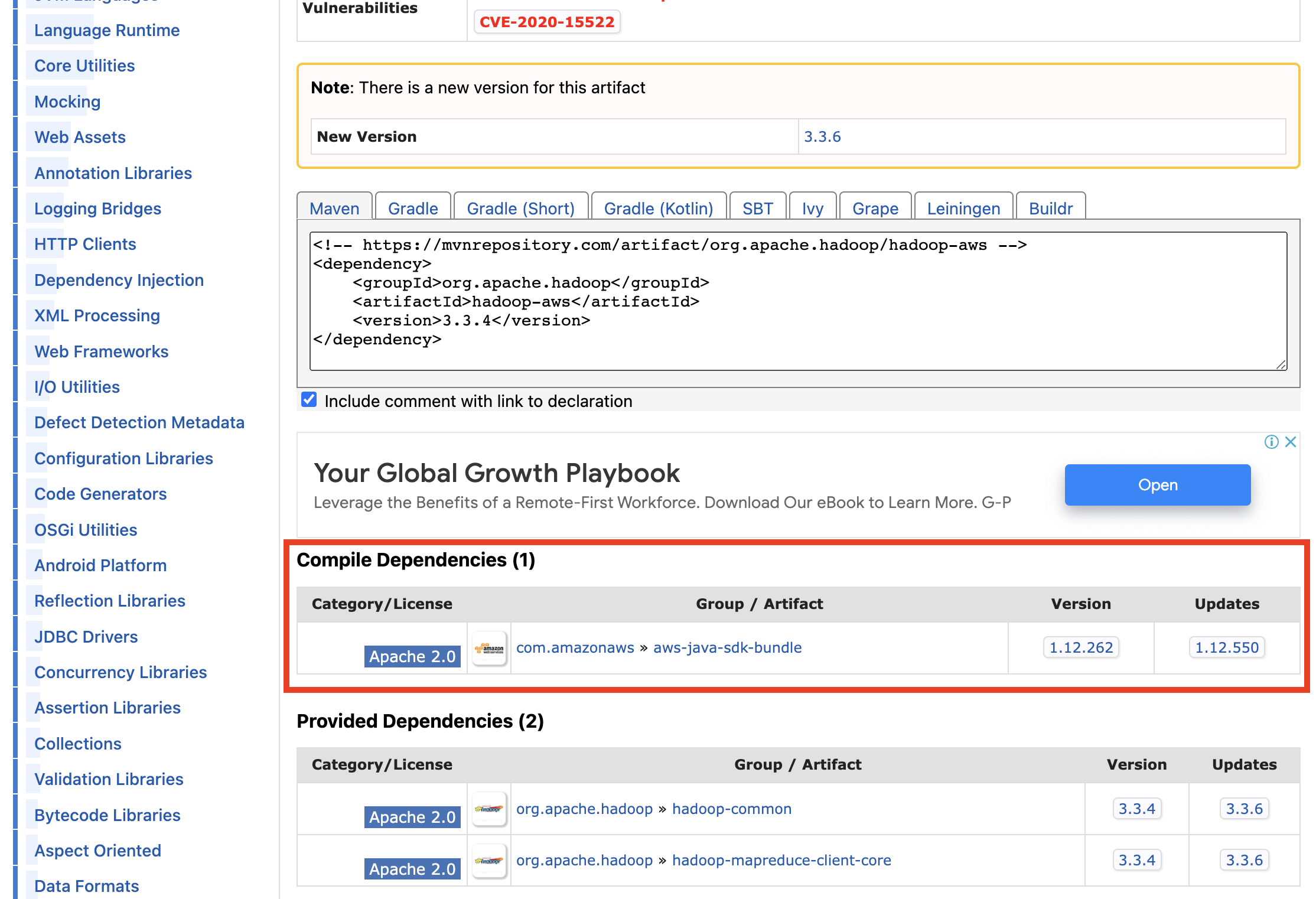
마찬가지로, 버젼을 클릭 하면 아래와 같이 나오는데, 똑같이 jar 파일을 다운 받는다.
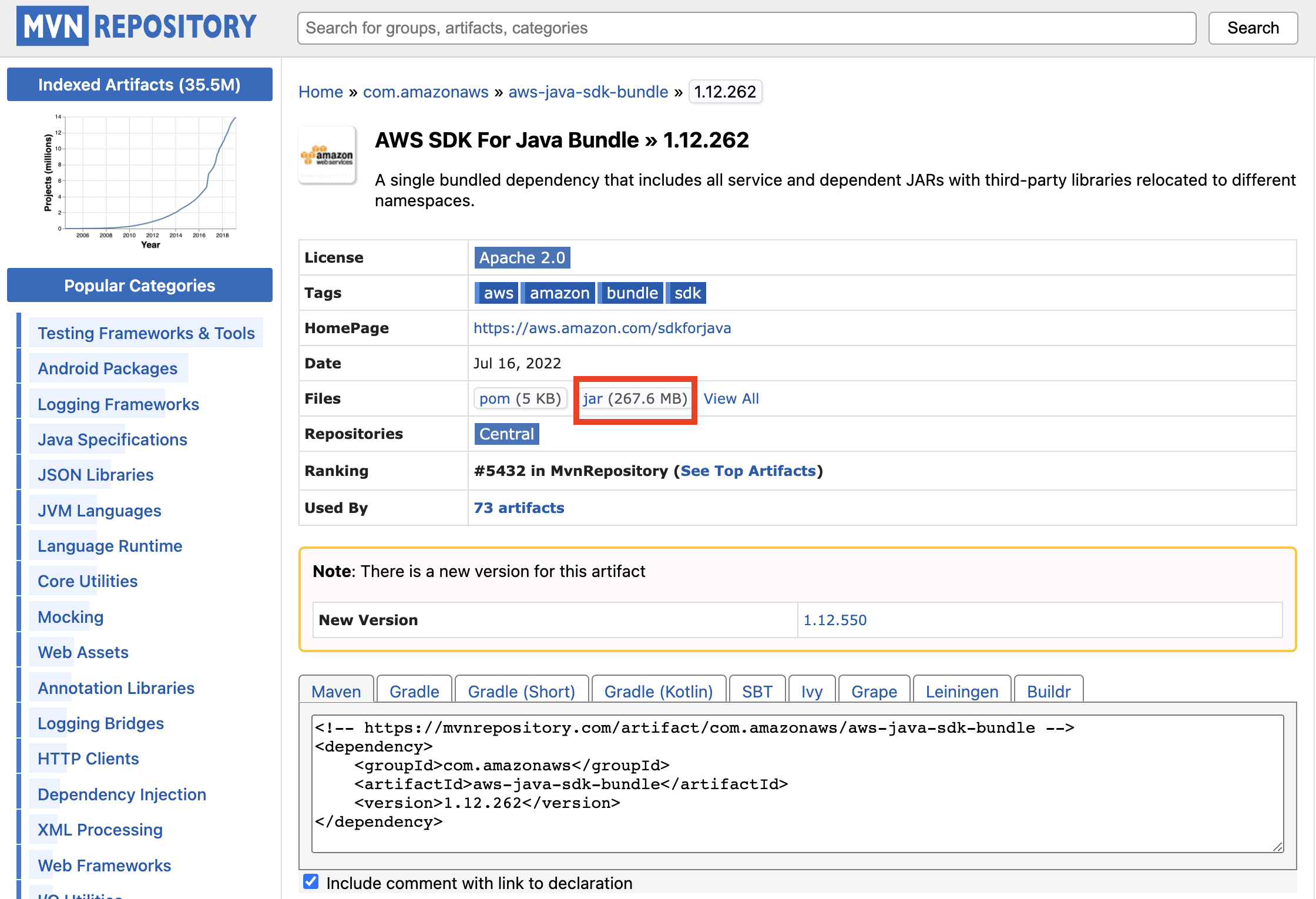
이제 다운받은 파일들을
- spark가 잡을 수 있는 폴더로 이동시키고
- aws 접속용 access key와 access secret key만 conf 파일에 작성해주면 된다.
# 다운로드 받은 두 개의 파일 모두 $SPARK_HOME 안의 jars 폴더 안으로 옮겨준다.
$ mv <다운받은 파일 경로> $SPARK_HOME/jars/
# spark conf 파일에 aws 계정 정보를 넘긴다.
$ cd $SPARK_HOME/conf
$ cp spark-defaults.conf.template spark-defaults.conf
$ vim spark-defaults.conf
# 아래 내용 추가
spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem
spark.hadoop.fs.s3a.access.key <본인의 access key ID>
spark.hadoop.fs.s3a.secret.key <본인의 access key 패스워드>여기까지 하면 모든 준비는 완료되었다.
환경변수 및 버젼 확인
마지막으로, 환경변수와 버젼이 모두 잘 나오는지 확인한다.
# /.zshrc에서 환경변수 확인
export PATH=/usr/local/bin:$PATH
export JAVA_HOME=/Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home
export PATH=$PATH:$JAVA_HOME/bin
export SPARK_HOME=/usr/local/bin/spark-3.3.3-bin-hadoop3
export PATH=$PATH:$SPARK_HOME/bin
export PYSPARK_PYTHON=python3
# JAVA_HOME이나 SPARK_HOME은 본인의 폴더 경로를 넣어야한다. # 파이썬 버젼 확인
$ python3 --version
# 자바 버젼 확인
$ java -version
# 스파크 버젼 확인
$ pyspark # 혹은
$ spark-shell # 혹은
$ pyspark --version # 혹은
$ spark-submit --version그 다음, 아래와 같은 코드가 잘 작동하는지 확인한다.
from pyspark.sql import SparkSession
def getSparkSession() -> SparkSession :
spark = SparkSession.builder \
.appName("GetS3FiletoLocal") \
.getOrCreate()
return spark
def getFileFromS3(spark : SparkSession, s3_bucket : str, s3_prefix : str) :
df = spark.read.parquet(f"s3a://{s3_bucket}/{s3_prefix}")
return df
spark = getSparkSession()
s3_bucket = <버킷명>
s3_prefix = <버킷 안의 원하는 객체까지의 경로>
df = getFileFromS3(spark, s3_bucket, s3_prefix)
print(df.show())print문이 잘 나오면 성공이다.
📌 주의사항 📌
-
뭐가 연결이 안 되면 높은 확률로 환경변수가 안 잡힌 것이다. 환경변수가 잘 잡혔는지 꼭 확인하자. 특히, 블로그만 보고 대충 따라할 경우 블로그 주인의 경로를 그대로 복붙하는 경우가 많은데, 자신의 로컬에서의 경로를 꼭 체크해야 한다.
-
한 개 다운로드 하고 쉘에서 잘 작동하는지 확인하고 다음 껄 다운 받자. 한꺼번에 다 다운 받고 나중에 한 번에 확인하면, 어디서 꼬였는지 알기 어렵다.
-
환경세팅이 개발의 반 이상이라고 생각하고 중간에 스트레스를 받아도 끝까지 버텨내자. 그리고 정 안 되면 관련된 파일을 꼭 싹 다 지워서 깔끔하게 만들고 다시 하나씩 다운로드 해나가자.
