알고리즘 기본 성능 확인
생각해보니 머신러닝 모델만 소개하고 딥러닝 모델은 포스팅을 못 했는데 순전히 내 능력을 뛰어넘는 일이라서 그렇다.
무지성 복붙을 해도 되지만 그래도 개인 프로젝트이기 때문에 진짜 내 것으로 만든 것들로 채우고 싶기 때문에 내가 할 수 있는 범위에서만 도전해 보려 한다. (딥러닝 어려워잉)
우선 이번 프로젝트에서 시행해 본 알고리즘은 다음과 같다
- IsolationForest
- K-Means
- MeanShift(KDE)
- GMM
- DBSCAN
- One Class SVM
- EllipticEnvelope
- LOF
기본 성능만 확인하는 코드이기 떄문에 별다른 HP 조정은 안 했다. 모든 과정은 local에서 했지만 GPU 문제로 Colab에서 추가 진행되었다.
IsolationForest(Base Code참조)
def get_pred_label(model_pred):
model_pred = np.where(model_pred == 1, 0, model_pred)
model_pred = np.where(model_pred == -1, 1, model_pred)
return model_pred
IF = IsolationForest(contamination=val_contamination, random_state=42)
IF.fit(X_train)
IF_val_pred = IF.predict(X_val)
IF_val_pred = get_pred_label(IF_val_pred)
# 모델 결과 확인
unique, counts = np.unique(IF_val_pred, return_counts=True)
IF_contamination = counts[1] / counts[0]
print(f'클래스 : {unique}, 클래스별 개수 : {counts}')
print(f'정상 데이터 : {counts[0]}, 사기 데이터 : {counts[1]}')
print(f'검증 데이터의 사기 비율 : [{IF_contamination}]')
print(classification_report(y_val, IF_val_pred))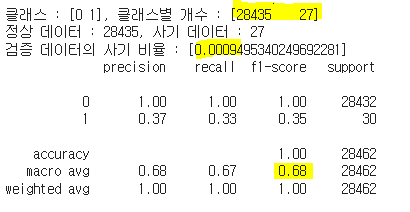
K-Means
# 모델 학습
kmeans = KMeans(n_clusters=2, init='k-means++', max_iter=300, random_state=42)
kmeans.fit(X_train)
kmeans_val_pred = kmeans.predict(X_val)
# 모델 결과 확인
unique, counts = np.unique(kmeans_val_pred, return_counts=True)
kmeans_contamination = counts[1] / counts[0]
print(f'클래스 : {unique}, 클래스별 개수 : {counts}')
print(f'정상 데이터 : {counts[0]}, 사기 데이터 : {counts[1]}')
print(f'검증 데이터의 사기 비율 : [{kmeans_contamination}]')
# 모델 성능 확인
print(classification_report(y_val, kmeans_val_pred))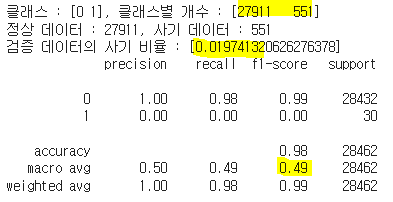
MeanShift
# 모델 학습
MS = MeanShift(bandwidth=2)
MS.fit(X_train)
MS_val_pred = MS.predict(X_val)
# 모델 결과 확인
unique, counts = np.unique(MS_val_pred, return_counts=True)
MS_contamination = counts[1] / counts[0]
print(f'클래스 : {unique}, 클래스별 개수 : {counts}')
print(f'정상 데이터 : {counts[0]}, 사기 데이터 : {counts[1]}')
print(f'검증 데이터의 사기 비율 : [{MS_contamination}]')
# 모델 성능 확인
print(classification_report(y_val, MS_val_pred))GMM
# 모델 학습
gmm = GaussianMixture(n_components=2, random_state=42)
gmm.fit(X_train)
gmm_val_pred = gmm.predict(X_val)
# 모델 결과 확인
unique, counts = np.unique(gmm_val_pred, return_counts=True)
gmm_contamination = counts[1] / counts[0]
print(f'클래스 : {unique}, 클래스별 개수 : {counts}')
print(f'정상 데이터 : {counts[0]}, 사기 데이터 : {counts[1]}')
print(f'검증 데이터의 사기 비율 : [{gmm_contamination}]')
# 모델 성능 확인
print(classification_report(y_val, gmm_val_pred))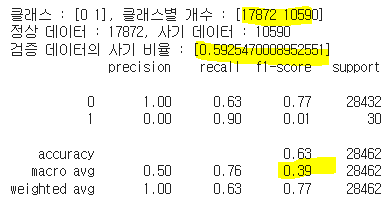
DBSCAN
def get_pred_label_db(model_pred):
model_pred = np.where(model_pred == -1, 0, model_pred)
model_pred = np.where(model_pred != 0, 1, model_pred)
return model_pred
# 모델 학습
dbscan = DBSCAN(metric='euclidean')
dbscan_val_pred = dbscan.fit_predict(X_val)
dbscan_val_pred = get_pred_label_db(dbscan_val_pred)
# 모델 결과 확인
unique, counts = np.unique(dbscan_val_pred, return_counts=True)
dbscan_contamination = counts[1] / counts[0]
print(f'클래스 : {unique}, 클래스별 개수 : {counts}')
print(f'정상 데이터 : {counts[0]}, 사기 데이터 : {counts[1]}')
print(f'검증 데이터의 사기 비율 : [{dbscan_contamination}]')
# 모델 성능 확인
print(classification_report(y_val, dbscan_val_pred))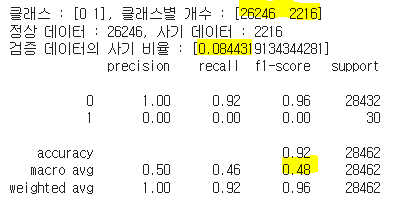
One Class SVM
# 모델 학습
ocsvm=OneClassSVM()
ocsvm.fit(X_train)
ocsvm_val_pred = ocsvm.predict(X_val)
ocsvm_val_pred = get_pred_label(ocsvm_val_pred)
# 모델 결과 확인
unique, counts = np.unique(ocsvm_val_pred, return_counts=True)
unique, counts
ocsvm_contamination = counts[1] / counts[0]
print(f'클래스 : {unique}, 클래스별 개수 : {counts}')
print(f'정상 데이터 : {counts[0]}, 사기 데이터 : {counts[1]}')
print(f'검증 데이터의 사기 비율 : [{ocsvm_contamination}]')
# 모델 성능 확인
print(classification_report(y_val, ocsvm_val_pred))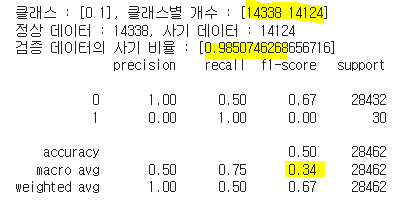
EllipticEnvelope
# 모델 학습
ell = EllipticEnvelope(contamination=val_contamination)
ell.fit(X_train)
ell_val_pred = ell.predict(X_val)
ell_val_pred = get_pred_label(ell_val_pred)
# 모델 결과 확인
unique, counts = np.unique(ell_val_pred, return_counts=True)
ell_contamination = counts[1] / counts[0]
print(f'클래스 : {unique}, 클래스별 개수 : {counts}')
print(f'정상 데이터 : {counts[0]}, 사기 데이터 : {counts[1]}')
print(f'검증 데이터의 사기 비율 : [{ell_contamination}]')
# 모델 성능 확인
print(classification_report(y_val, ell_val_pred))
LOF
# 모델 학습
lof = LocalOutlierFactor(contamination=val_contamination)
lof_val_pred = lof.fit_predict(X_val)
lof_val_pred = get_pred_label(lof_val_pred)
# 모델 결과 확인
unique, counts = np.unique(lof_val_pred, return_counts=True)
lof_contamination = counts[1] / counts[0]
print(f'클래스 : {unique}, 클래스별 개수 : {counts}')
print(f'정상 데이터 : {counts[0]}, 사기 데이터 : {counts[1]}')
print(f'검증 데이터의 사기 비율 : [{lof_contamination}]')
# 모델 성능 확인
print(classification_report(y_val, lof_val_pred))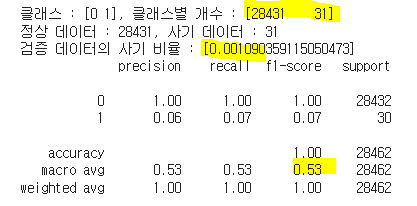
성능 결과
정리하자면 아래와 같다. (0=정상거래 / 1=사기거래)
| 모델 | IF | K-Means | MeanShift | GMM | DBSCAN | One Class SVM | EllipticEnvelope | LOF |
|---|---|---|---|---|---|---|---|---|
| 클래스 | [0,1] | [0,1] | [0,1] | [0,1] | [0,1] | [0,1] | [0,1] | [0,1] |
| 클래스별 개수 | [28435, 27] | [27911, 551] | 내용 8 | [17872, 10590] | [26246, 2216] | [14338, 14124] | [28437, 25] | [28431, 31] |
| 검증 데이터 사기비율 | [0.0009] | [0.0197] | 내용8 | [0.5925] | [0.0844] | [0.9850] | [0.0008] | [0.0010] |
| f1_macro | 0.68 | 0.49 | 내용 12 | 0.39 | 0.48 | 0.34 | 0.50 | 0.53 |
데이콘에서 제시한 Base Code에 나온 IsolationForest가 성능이 너무 괜찮아서(심지어 HP 튜닝도 안 했는데...) 다른 것들도 그러겠지이 했는데 웬걸.... 다들 성능 레기 나와서 심히 당황했다😨
결국 구글링의 도움으로 열심히 찾은 모델 중 기본 모델로도 성능이 괜찮게 나온
- IsolationForest
- EllipticEnvelope
- LOF
모델의 하이퍼 파라미터 튜닝을 통해 성능을 높여보기로 하였다.
그건 다음 포스팅에😉

완료주의