하이퍼 파라미터 튜닝
전 포스팅에서 선택했던 모델들의 HP 튜닝을 진행하였다.
기본적으로는 RandomizedSearchCV를 이용했다(cv=5, n_iter=50 했더니 시간이 어마무시하게 걸리더라....).
다만, 아직 개념을 다 이해 못 해서인지 EllipticEnvelope은 안 되더라(어차피 튜닝할 HP도 많이 없었음).
IsolationForest
# IF 모델 튜닝 후
# 모델 학습
IF = IsolationForest(contamination=val_contamination,
bootstrap=True,
max_features=11,
max_samples=100,
n_estimators=330,
random_state=42)
IF.fit(X_train)
IF_val_pred = IF.predict(X_val)
IF_val_pred = get_pred_label(IF_val_pred)
# 모델 결과 확인
unique, counts = np.unique(IF_val_pred, return_counts=True)
IF_contamination = counts[1] / counts[0]
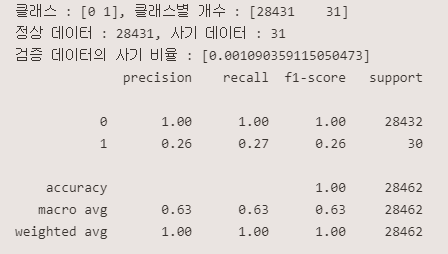
print(f'클래스 : {unique}, 클래스별 개수 : {counts}')
print(f'정상 데이터 : {counts[0]}, 사기 데이터 : {counts[1]}')
print(f'검증 데이터의 사기 비율 : [{IF_contamination}]')
print(classification_report(y_val, IF_val_pred))<튜닝전>
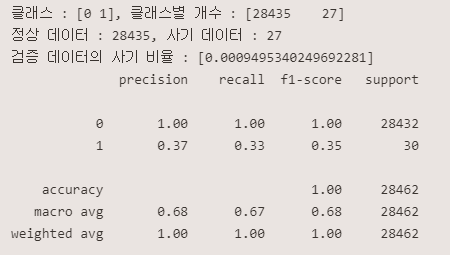
<튜닝후>
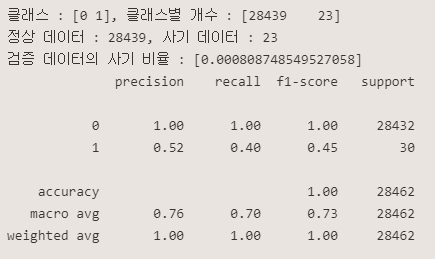
EllipticEnvelope
# ell 모델 튜닝 후
# 모델 학습
ell = EllipticEnvelope(store_precision=True,
assume_centered = True,
support_fraction = 0.5,
contamination=val_contamination)
ell.fit(X_train)
ell_val_pred = ell.predict(X_val)
ell_val_pred = get_pred_label(ell_val_pred)
# 모델 결과 확인
unique, counts = np.unique(ell_val_pred, return_counts=True)
ell_contamination = counts[1] / counts[0]
print(f'클래스 : {unique}, 클래스별 개수 : {counts}')
print(f'정상 데이터 : {counts[0]}, 사기 데이터 : {counts[1]}')
print(f'검증 데이터의 사기 비율 : [{ell_contamination}]')
# 모델 성능 확인
print(classification_report(y_val, ell_val_pred))<튜닝전>
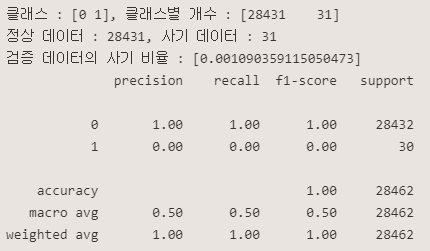
<튜닝후>

LOF
# lof 모델 튜닝 후
# 모델 학습
lof = LocalOutlierFactor(contamination=val_contamination,
algorithm='ball_tree',
leaf_size=20,
p=7)
lof_val_pred = lof.fit_predict(X_val)
lof_val_pred = get_pred_label(lof_val_pred)
# 모델 결과 확인
unique, counts = np.unique(lof_val_pred, return_counts=True)
lof_contamination = counts[1] / counts[0]
print(f'클래스 : {unique}, 클래스별 개수 : {counts}')
print(f'정상 데이터 : {counts[0]}, 사기 데이터 : {counts[1]}')
print(f'검증 데이터의 사기 비율 : [{lof_contamination}]')
# 모델 성능 확인
print(classification_report(y_val, lof_val_pred))<튜닝전>
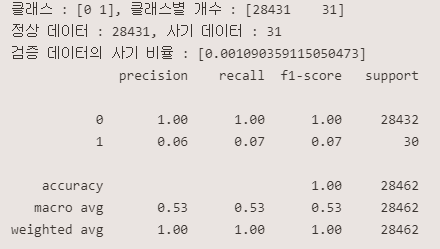
<튜닝후>
결론 🏆
IsolationForest가 성능이 가장 좋았고, 도전해볼만한 알고리즘은 LOF인 것 같다.
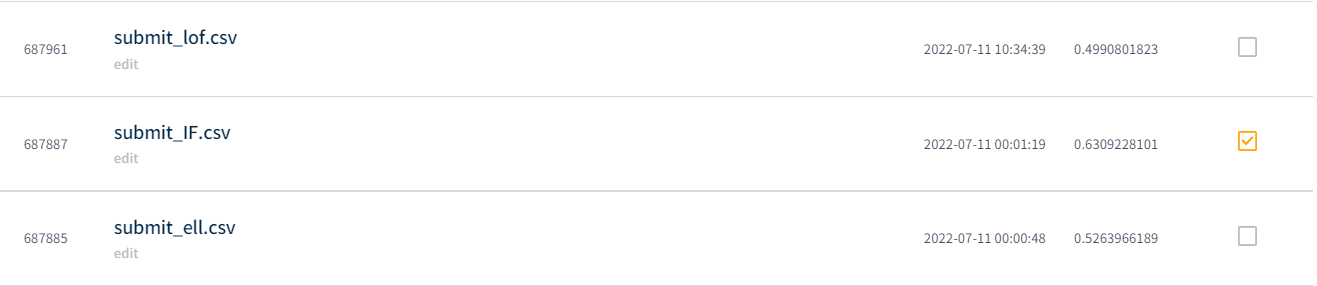
IsolationForest 모델이 가장 성능이 좋게 나왔다.😭😢😭
🛑해결할 문제🛑
- One Class SVM 다시 해보기 : 이렇게 성능이 떨어질리 없다!⛔
- MeanShift 다시 해보기
- 딥러닝 모델 : 한 번 건드려는 보자💨
- 피쳐 선택

완료주의