
고가용성과 확장성
확장성
애플리케이션 시스템이 조정을 통해 더 많은 양을 처리할 수 있다는 의미
수직 확장성
인스턴스의 크기 확장 (scale up/down)
ex) t2.micro => t2.large로 구동하게끔 바꿈
데이터 베이스와 같이 분산되지 않은 시스템에서 흔히 사용
=> 하위 인스턴스의 유형을 업그레이드해 수직적으로 확장할 수 있는 시스템
ex) RDC, ElastiCache
일반적으로 확장할 수 있는 정도에 한계가 있음 (하드웨어 제한)
수평 확장성 (탄력성)
애플리케이션에서 인스턴스나 시스템의 수를 늘리는 방법 (scale out/in)
ex) 다른 스케일링 그룹, 로드밸런서
분배 시스템이 있다는 것을 의미
ex) 웹, 현대적 애플리케이션
aws EC2 같은 클라우드 제공 업체 덕에 수평적인 확장이 더욱 수월해짐
고가용성
수평확장성과 같이 쓰이는 개념(항상은 아님)
애플리케이션 또는 시스템을 적어도 둘 이상의 AWS의 AZ가 데이터 센터에서 가동 중인 것을 의미
동일 애플리케이션의 동일 인스턴스를 다수의 AZ에 걸쳐 실행하는 경우
ex) 다중 AZ가 활성화된 자동 스케일러 그룹, 로드밸런서
데이터 센터에서의 손실에서 살아남는 것이 목표
=> 센터 하나가 멈춰도 계속 작동하게끔
수동적(passive)일 수 있음 (RDS 다중 AZ를 갖추고 있는 경우)
활성형(active)일 수 있음 (수평 확장을 하는 경우)
일래스틱 로드 밸런싱(ELB)
서버 혹은 서버셋으로 트래픽을 백엔드나 다운스트림 EC2 인스턴스 또는 서버들로 전달하는 역할
용도
- 부하를 다수의 다운스트림 인스턴스로 분산시키기 위해
- 애플리케이션에 단일 엑세스 지점(DNS)을 노출하게 하고 다운스트립 인스턴스의 장애를 원활하게 처리하기 위해
- 상태 확인 메커니즘으로 어떤 인스턴스로 트래픽을 보낼 수 없는지 확인해줌
- 인스턴스 상태 확인
- 포트와 라우트에서 이루어짐(
/health가 일반적) - 200으로 응답하지 않는다면 인스턴스 상태가 좋지 않다고 기록됨 => ELB가 트래픽을 보내지 않음
- 포트와 라우트에서 이루어짐(
- SSL 종료 가능 => 웹 사이트에 암호화된 HTTPS 트래픽을 가질 수 있음
- 쿠키로 고정도를 강화할 수 있음
- 영역에 걸친 고가용셩을 가짐
- 클라우드 내에서 개인 트래픽과 공공 트래픽 분리 가능
- 쓰는게 이득 => 자체 로드밸런서는 확장성 측면에서 번거로움
- aws의 다수 서비스들과 통합되어 있음(EC2 인스턴스, 스케일링 그룹, ECS와 인증서 관리, Route 53, ...)
- 관리형 로드밸런서이기도 함
- aws가 관리하며 어떤 경우에도 작동할 것을 보장
- aws가 업그레이드와 유지 완리 및 고가용성을 책임짐
- 로드밸런서의 작동 방식을 수정할 수 있게끔 일부 구성 놉(knobs)도 제공
관리형 로드 밸런서
-
클래식 로드 밸런서(CLB)
기존세대, V1이라고 함, 2009년도에 만들어짐
HTTP, HTTPS, TCP, SSL, secure TCP 지원
aws는 사용을 권장하지 않음 -
신형 로드 밸런서(ALB)
2016년 출시, V2
HTTP, HTTPS, WebSocket 프로토콜 지원 -
네트워크 로드 밸런서(NLB)
2016년 출시, V2
TCP, TLS, secure TCP, UDP 프로토콜 지원 -
게이트웨이 로드 밸런서(GWLB)
2020년 출시
네트워크 층에서 작동함 => 3계층과 IP 프로토콜에서 작동
일부 로드밸런서는 내부에 설정될 수 있어 네트워크에 개인적 접근이 가능함
웹 사이트와 공공 애플리케이션 모두에 사용이 가능한 외부 공공 로드밸런서도 있음
로드 밸런서와 보안 그룹
HTTP나 HTTPS를 사용해 어디서든 로드 밸런서에 접근 가능
포트 범위는 80 혹은 443
소스는 0.0.0.0/0
로드 밸런서는 들어오는 트래픽만을 허용해야 하기 때문에 EC2 인스턴스의 보안 그룹 규칙은 다름
=> 포트 80에서 HTTP 트래픽을 허용하여 소스는 IP 범위가 아니라 보안 그룹이 됨
EC2 인스턴스의 보안 그룹을 로드 밸런서의 보안 그룹으로 연결
=> EC2 인스턴스는 로드 밸런서에서 온 트래픽만을 허용할 수 있음, 보안 강화
애플리케이션 로드 밸런서(ALB, v2)
용도
- 7계층, HTTP 전용 로드 밸런서
- 머신(대상 그룹, target groups) 간 다수 HTTP 애플리케이션의 라우팅에 사용이 됨
- 동일 EC2 인스턴스 상의 여러 애플리케이션에 부하를 분산함
- 컨테이너, ECS 사용
- HTTP/2, 웹소켓 지원
- 리다이랙트 지원
- HTTP에서 HTTPS로 트래픽을 자동 리다이렉트 하려는 경우 로드 밸런서 레벨에서 가능
- 경로 라우팅도 지원
- 대상 그룹에 따른 라우팅으로는
- URL 대상 경로에 기반한 라우팅 (ex. test.com/users & test.com/posts)
URL 상의 서로 다른 경로이고 다른 대상 그룹에 리다이랙트 할 수 있음 - URL의 호스트 이름에 기반한 라우팅도 가능 (ex. one.test.com & two.test.com)
두 URL에 접근이 가능하다고 하면 두 개의 다른 대상 그룹에 라우팅이 될 수 있음 - 쿼리 문자열과 헤더에 기반한 라우팅도 가능 (ex. test.com/users?id=1&order=false)
test.com/users와 test.com/users?id=1&order=false가 다른 대상 그룹에 라우팅 될 수 있음
- URL 대상 경로에 기반한 라우팅 (ex. test.com/users & test.com/posts)
- 마이크로 서비스나 컨테이너 기반 애플리케이션에 가장 좋음 (ex 도커, 아마존 ECS)
- 포트 매핑 기능이 있어 ECS 인스턴스의 동적 포트로의 리다이랙션을 가능하게 해줌
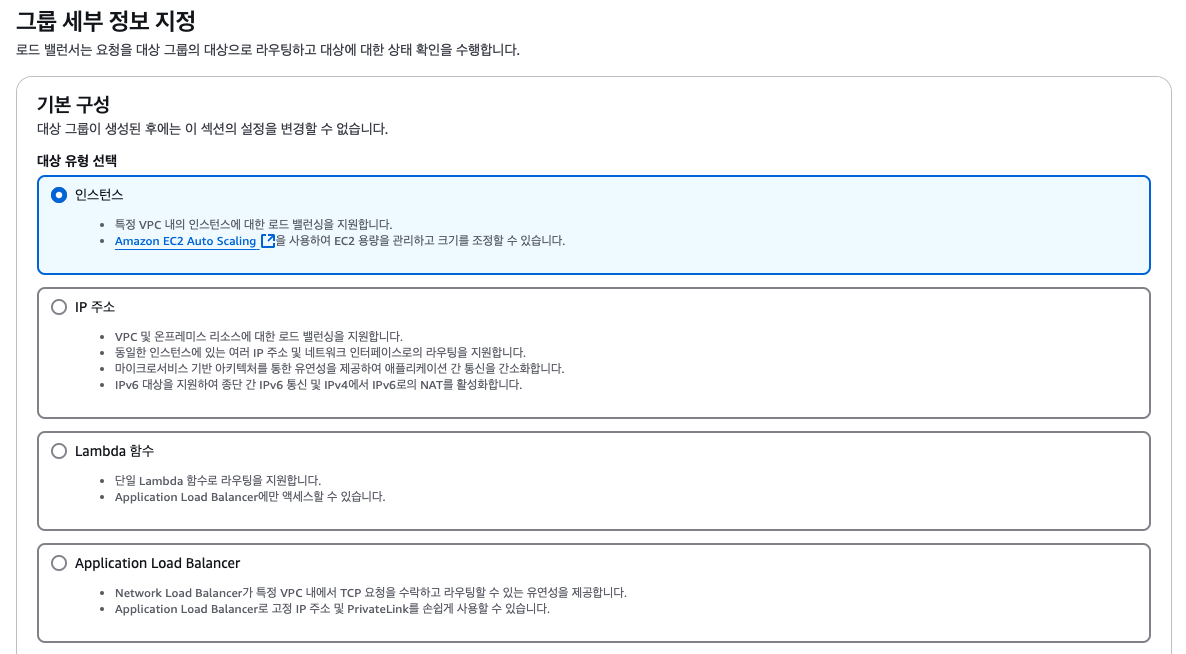
대상그룹(target groups)이란
- EC2 인스턴스(오토스케일링 그룹에 의해 관리될 수 있음) - HTTP
- EC2 작업(ECS 자체에 의해 관리됨) - HTTP
- 람다 함수(aws에서 serverless로 불리는 모든 것들의 기반이 되는 함수)의 앞에 위치 가능
- IP 주소의 앞에도 위치 가능 - 반드시 사설 IP 주소여야 함
- ALB는 여러 대상 그룹으로 라우팅 가능
- 상태 확인은 대상 그룹 레벨에서 이루어짐
알면 좋은 것
- 로드밸런서를 사용하는 경우에도 고정 호스트 이름이 부여됨 (ex. xxx.region.elb.amazonaws.com)
- 애플리케이션 서버는 클라이언트의 IP를 직접 보지 못함
- 클라이언트의 실제 IP는
X-Fowarded-For헤더에 삽입됨 X-Fowarded-Port를 사용하는 포트와X-Fowarded-Proto에 의해 사용되는 프로토콜도 얻게 됨- 클라이언트 IP가 로드 밸런서와 직접 통신해 연결 종료라는 기능을 수행하며, 로드밸런서가 EC2 인스턴스와 통신할 때에는 사설 IP인 로드밸런서 IP를 사용해 EC2 인스턴스로 들어가게 됨. EC2 인스턴스가 클라이언트 IP를 알기 위해서는
X-Fowarded-Port와X-Fowarded-Proto를 확인해야 함
- 클라이언트의 실제 IP는
로드밸런서 생성하기
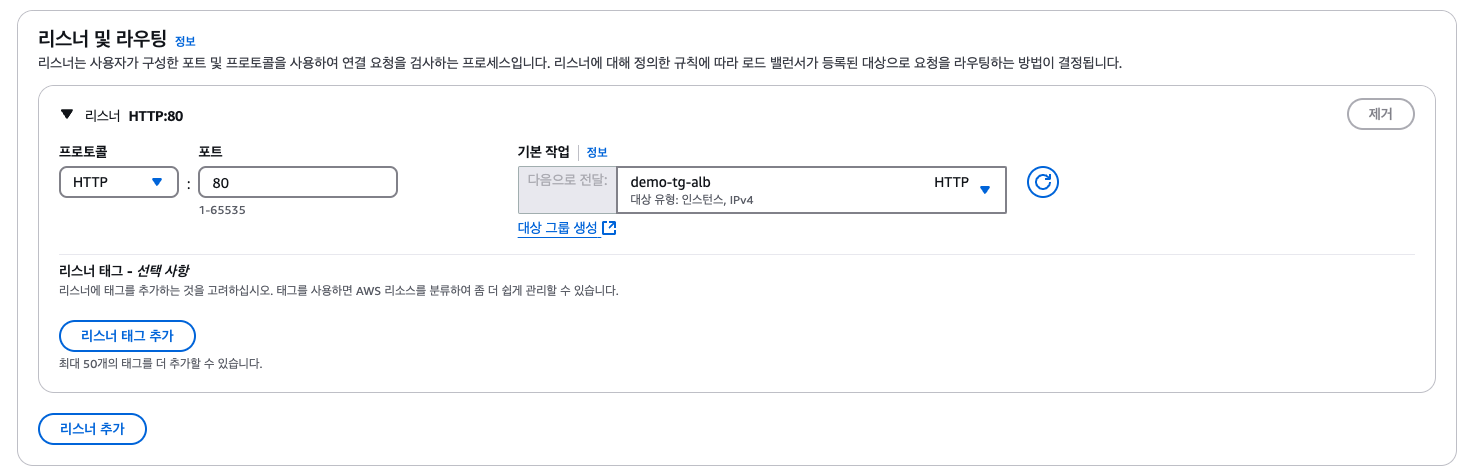
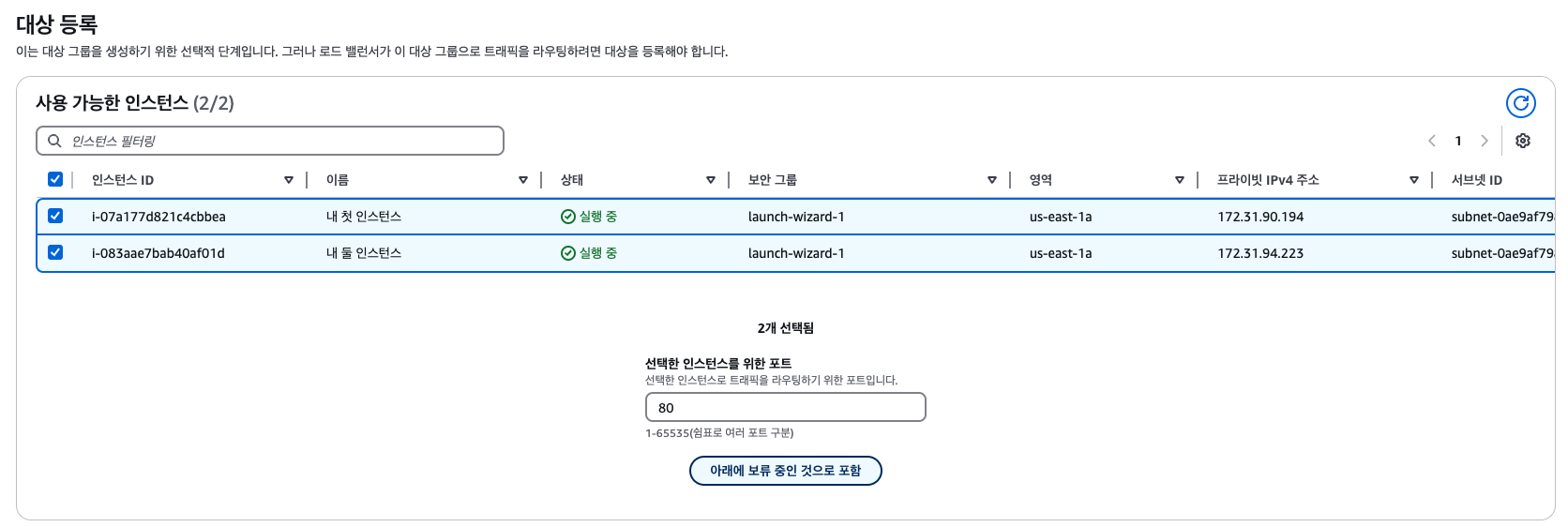
대상 그룹 생성하기
생성된 로드밸런서
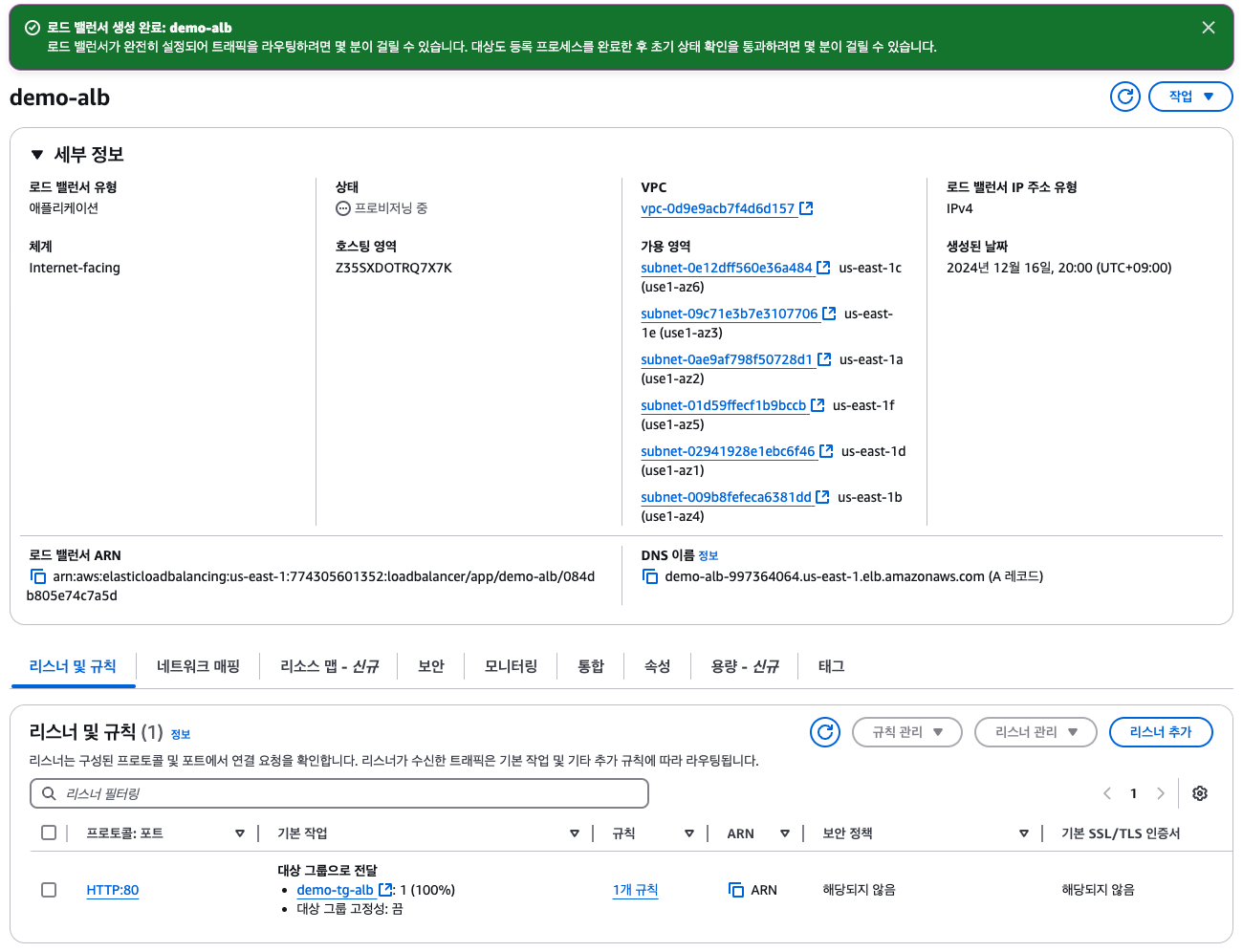

DNS주소에 들어가서 새로고침하면, 새로고침할 때마다 로드 밸런서가 두 EC2 인스턴스를 바꿔가며 리디렉션해주기 때문에 주소가 바뀜을 볼 수 있음
네트워크 보안
현재는 각 생성한 두 개의 인스턴스의 퍼블릭 IP를 통해 접근할 수 있음
또한 로드 밸런서의 DNS 이름을 통해서도 접근이 가능함
권장되는 방법은 EC2 인스턴스에 엑세스할 때는 로드 밸런서를 통해서 해야 함

인스턴스에서 설정한 보안 그룹에서 인바운드 규칙 편집하기를 해 해당 EC2 인스턴스로 허용되는 트래픽은 로드 밸런서를 통해서 오는 것만으로 설정한다

다음과 같이 인스턴스에 접근할 수 없기 때문에 타임아웃이 발생함, 로드밸런서 쪽은 정상적으로 접근이 가능함
애플리케이션 밸런서 규칙
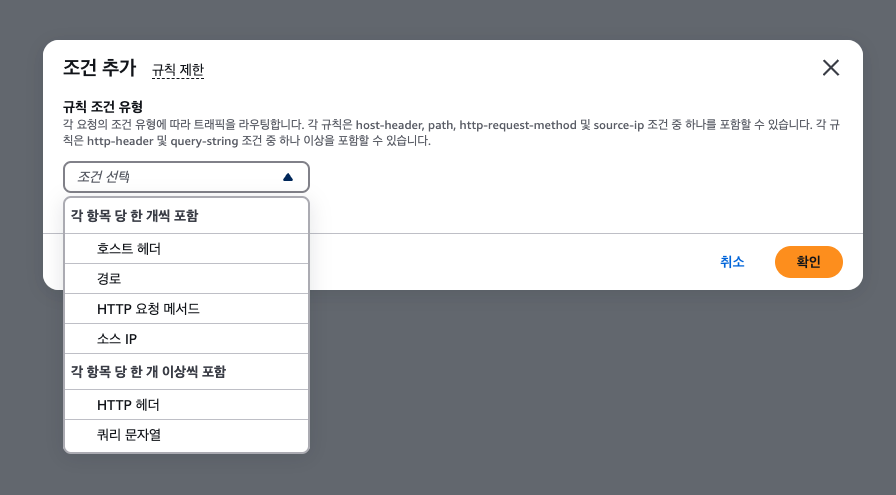
조건 : 역할의 요청을 무엇으로 필터할 것인가


/error로 접근하는 경우 해당 응답값을 반환할 예정임

/error로 접근하는 경우에 다음과 같이 뜸
네트워크 로드 밸런서(NLB)
네트워크 로드 밸런서란?
- 4계층 로드 밸런서이므로 TCP, UDP 트래픽 처리
- 초당 수백만건의 요청을 처리할 수 있는 고성능
- 애플리케이션 로드 밸런서 대비 짧은 지연시간(100밀리초)
- 가용 영역 당 하나의 고정 IP만 있음
- 각 가용 영역에 탄력적 IP 배정 가능
- 여러 고정 IP가 있는 애플리케이션을 노출해야 할 때 무척 유용함
- aws 프리티어에 포함되어 있지 않음
작동원리
대상 그룹을 생성하면 NLB가 리디렉션 함
TCP 트레래픽이나 백엔드는 HTTP를 사용하면서 프론트엔드는 여전히 TCP를 사용할 수도 있음
대상 그룹
- EC2 인스턴스
- NLB가 EC2 인스턴스로 리디렉션할 수 있고, TCP, UDP 트래픽을 그쪽으로 보낼 수 있음
- IP 주소 - 반드시 프라이빗 IP 주소여야 함
- 소유한 EC2 인스턴스의 프라이빗 IP를 보내도 되지만, 데이터 센터에 있는 서버의 프라이빗 IP를 사용할 수 있음 => 둘 다 같은 NLB를 사용할 수 있음
- 애플리케이션 로드 밸런서(ALB)
- NLB가 ALB 앞에 있게 됨
- NLB 덕분에 고정 IP 주소를 얻을 수 있고, ALB 덕분에 HTTP 트래픽을 처리하는 것과 관련한 모든 규칙을 얻을 수 있음
- NLB의 대상 그룹이 하는 상태 확인은 세 가지 프로토콜(TCP, HTTP, HTTPS)을 지원함
게이트웨이 로드 밸런서(GWLB)
게이트웨이 로드 밸런서란
- 배포 및 확장과 aws의 타사 네트워크 가상 어플라이언스의 플릿 관리에 사용
- GWLB는 네트워크의 모든 트래픽이 방화벽을 통과하게 하거나 침입 탐지 및 방지 시스템에 사용
- IDPS나 심층 패킷 분석 시스템 또는 일부 페이로드를 수정할 수 있으나 네트워크 수준에서 가능
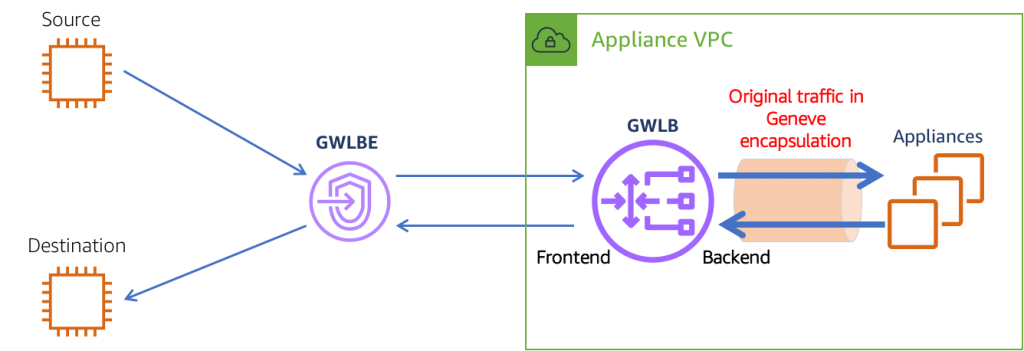
- GWLB를 생성하면 VPC에서 라우팅 테이블이 업데이트 됨
- 라우팅 테이블이 수정되면 모든 사용자 트래픽은 GWLB을 통과함
- GWLB는 가상 어플라이언스의 대상 그룹 전반으로 트래픽을 확산함
- 모든 트래픽은 어플라이언스에 도달하고 어플라이언스는 트래픽을 분석하고 처리함 (ex 방화벽, 침입 탐지)
- 이상이 없으면 다시 GWLB로 보내고 이상이 있으면 트래픽을 드롭함
- GWLB에서는 트래픽을 애플리케이션으로 보냄
=> GWLB의 기능은 네트워크 트래픽을 분석하는 것
-
작동 원리 : IP 패킷의 네트워크 계층인 L3에서 작동
-
투명 네트워크 게이트 웨이 : VCP의 모든 트래픽이 GWLB가 되는 단일 엔트리와 출구를 통과하기 때문
-
로드 밸런서 : 대상 그룹의 가상 어플라이언스 집합에 전반적으로 그 트래픽을 분산
-
6081번 포트의 GENEVE 프로토콜을 사용함
대상 그룹
- EC2 인스턴스
- IP 주소 - 반드시 프라이빗 IP
- 자체 네트워크나 자체 데이터 센터에서 가상 어플라이언스를 실행하면 IP로 수동 등록 가능
ELB - Sticky Sessions(Session Affinity)
일래스틱 로드 밸런서의 고정 세션(세션 밀집성)
- 고정성 혹은 고정 세션을 실행
- 로드 밸런서에 두 가지 요청을 수행하는 클아이언트가 요청에 응답하기 위해 백엔드에 동일한 인스턴스를 갖는 것
- 1번 클라이언트가 요청을 생성해 첫 번째 EC2 인스턴스를 통과하면 로드 밸런서에서 두 번째 요청을 통과할 때도 동일한 인스턴스로 이동함을 뜻함
- ALB와 CLB에서도 설정할 수 있음
- 쿠키를 사용해 클라이언트에서 로드 밸런서로 요청의 일부로서 전송됨
- 고정성과 만료 기간이 있음
- 쿠키가 만료되면 클라이언트가 다른 EC2 인스턴스로 리디렉션 됨
- 사용자 정보 같은 중요한 정보를 취하는 세션 데이터를 잃지 않기 위해 사용
- 고정성을 활성화하면 백엔드 EC2 인스턴스 부하에 불균형을 초래할 수 있음
Sticky Sessions - Cookie
Application-based Cookies(애플리케이션 기반 쿠키)
애플리케이션에서 기간을 지정할 수 있음
- 사용자 정의 쿠키(Custom Cookie)
- 대상(target)으로 생성됨
- 애플리케이션에 필요한 모든 사용자 정의 속성을 포함할 수 있음
- 쿠키 이름은 각 대상 그룹 별로 개별적으로 지정해야 함
- AWSALB, AWSALBAPP, AWSALBTG는 ELB에서 사용하므로 사용하면 안됨
- Application Cookie
- 로드 밸런서에서 생성
- 쿠키 이름 : AWSALBAPP
Duration-based Cookie(기간 기반 쿠키)
- 로드 밸런서에서 생성
- 쿠키 이름 : ALB에서는 AWSALB, CLB에서는 AWSELB
- 특정 기간을 기반으로 만료되며 그 기간이 로드 밸런서 자체에서 생성됨
고정 세션 활성화

대상 그룹으로 가서 작업 - 대상 그룹 속성 편집에서 고정 세션 활성화 가능
ELB - Cross-Zone Load Balancing
교차 영역 밸런싱
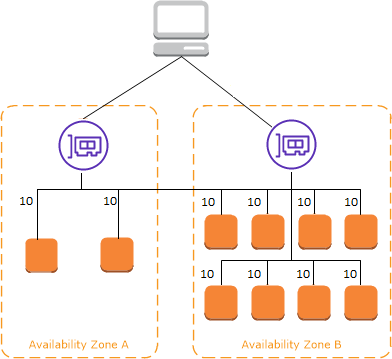
교차 영역 로드 밸런싱이 적용되면 각 로드 밸런서 인스턴스는 모든 가용 영역에 등록된 모든 인스턴스에 고르게 분포됨
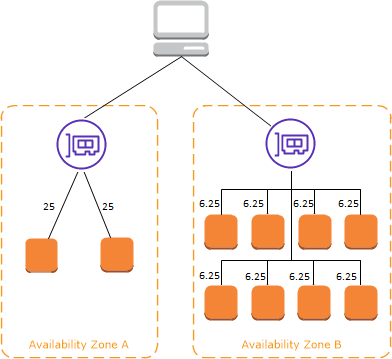
교차 영역 로드 밸런싱이 없는 경우에는 요청이 탄력적 로드 밸런서 노드의 인스턴스로 분산됨
각 ALB가 해당 영역에 있는 EC2 인스턴스로만 트래픽을 전송함
트래픽이 각 가용 영역에 한정되므로 각 가용 영역에 있는 EC2 인스턴스 개수가 불균형하면 특정 가용 영역에 있는 EC2 인스턴스는 더 많은 트래픽을 받게 됨
애플리케이션 로드 밸런서
- 기본적으로 교차 영역 로드 밸런싱 활성화
- 비활성화는 대상 그룹 레벨에서 가능
- 기본적으로 교차 영역 로드 밸런싱 활성화되어 있기 때문에 데이터가 가용 영역으로 넘어가도 요금이 부과되지 않음
네트워크 로드 밸런서 & 게이트웨이 로드 밸런서
- 기본적으로 교차 영역 로드 밸런싱 비활성화
- 데이터가 한 가용 영역에서 다른 영역으로 넘어가기 때문에 활성화하면 요금이 부과됨
ELB - SSL/TLS 인증서
SSL/TLS 인증서 기초
SSL 인증서는 클라이언트와 로드 밸런서 사이에서 트래픽이 전송되는 동안 암호화하도록 도와줌(전송 중 암호화)
즉 데이터가 네트워크를 통과하는 중에는 암호화되어 있고 발신자와 수신자만 해독 가능
SSL은 보안 소켓 계층이라는 뜻이며, 연결을 암호화할 때 사용됨
TLS는 SSL의 새 버전 이고 전송 계층 보안이라는 뜻
TLS가 더 주로 사용되지만 여전히 SSL이라고 부름
퍼블릭 SSL 인증서는 인증 기관(Certificate Authorities)에서 발행
로드 밸런서에 첨부된 퍼블릭 SSL 인증서를 활용하면 클라이언트와 로드 밸런서 사이의 연결을 암호화 가능
SSL 인증서에는 사용자가 정한 만료 날짜가 있으며, 인증서의 진위를 확인하기 위해 주기적으로 갱신해야 함
로드밸런서 측면에서 작동
사용자는 HTTPS를 통해 연결 (S는 SSL 인증서, 암호화 + 안전)
공용 인터넷을 통해 로드 밸런서에 연결
내부족으로 로드 밸런서는 SSL 종료
백엔드에서는 HTTP를 통해 EC2 인스턴스와 통신 => 암호화 x
트래픽은 VPC, 즉 프라이빗 트래픽(네트워크)를 통해 전송
로드밸런서는 X.509 인증서를 로딩(SSL/TLS 서버 인증서)
AWS는 ACM(AWS 인증서 매니저)를 활용해 SSL 인증서를 관리할 수 있음
ACM에 인증서 업로드도 가능
HTTPS 리스너를 설정할 때는
- 기본 인증서를 지정해줘야 함
- 인증서 목록을 추가해 여러 도메인 지원 가능(옵션)
- 클라이언트는 SNI(서버 이름 표시)라는걸 활용해 도달하려는 호스트 이름을 지정할 수 있음
- 특정 보안 정책을 설정해서 레거시 클라이언트라고도 부르는 SSL과 TLS의 구버전을 지원할 수도 있음
SNI - Server Name Indication
하나의 웹 서버에 여러 SSL 인증서를 로드해 웹 서버가 여러 웹 사이트를 지원하게 만드는 방법
클라이언트가 초기 SSL 핸드셰이크에서 대상 서버의 호스트 이름을 표시해야 하는 새 프로토콜
클라이언트가 '이 웹 사이트에 연결하고 싶다'고 하면 서버는 어떤 인증서를 로드해야 하는지 알 수 있음
모든 클라이언트가 지원하는 것은 아님, 최신 세대인 ALB, NLB를 활용할 때만 적용(CLB는 x), 혹은 CloudFront
SSL 인증서 지원
- ALB
여러 SSL 인증서로 여러 리스너 지원 가능
SNI 이용하면 됨
- NLB
여러 SSL 인증서로 여러 리스너 지원 가능
SNI 이용하면 됨
ELB - Connection Draining(연결 드레이닝)
이름
-
클래식 로드 밸런서인 경우에는 연결 드레이닝이라고 부름
-
애플리케이션 밸런서나 네트워크 로드 밸런서를 사용하는 경우에는 등록 취소 지연(Deregistration Delay)이라고 부름
개념
-
인스턴스가 등록 취소 혹은 비정상인 상태에 있을 때 인스턴스에 어느 정도 시간을 주어 인플라이트 요청, 즉 활성 요청을 완료할 수 있도록 함
-
연결이 드레이닝되면(인스턴스가 드레이닝되면) ELB는 등록 취소 중인 EC2 인스턴스로 새로운 요청을 보내지 않음
-
인스턴스가 Draining(드레이닝) 상태란?
- 로드 밸런서(LB)에서 해당 인스턴스를 제거하는 과정에서, 기존 연결을 유지하면서 새로운 연결을 차단하는 상태
- AWS의 ALB(Application Load Balancer)나 NLB(Network Load Balancer)에서 발생할 수 있음
-
Draining 상태가 되는 경우
- EC2 인스턴스를 수동으로 로드 밸런서에서 제거할 때
- 로드 밸런서에서 Target Group에서 제거될 때
- 기존 요청을 모두 처리한 후 Draining 상태 종료
- 로드 밸런서의 상태 체크(Health Check) 실패 시 로드 밸런서는 Draining 상태로 전환
- 오토 스케일링(Auto Scaling) 그룹에서 종료(Scale-In)될 때
- 오토 스케일링 정책에 의해 인스턴스가 종료될 예정이면, 로드 밸런서는 Draining 상태로 만들고 기존 연결을 유지하고 세션이 종료되면 인스턴스를 종료함
연결 드레이닝 파라미터
-
연결 드레이닝 파라미터는 매개변수로 표시 가능
-
1 ~ 3600초 사이의 값, 기본값은 300초(5분)
-
0으로 설정하면 전부 다 비활성화 할 수 있음 => 드레이닝이 일어나지 않는다
-
짧은 요청의 경우에는 낮은 값으로 설정
- 1초보다 적은 아주 짧은 요청에는 연결 드레이닝 파라미터를 30초 정도로 설정하면 됨
- 그래야 EC2 인스턴스가 빠르게 드레이닝되고 그 후에 오프라인 상태가 되어 교체 등의 작업을 할 수 있음
-
요청 시간이 매우 긴, 업로드 또는 오래 지속되는 요청 등의 경우에는 어느 정도 높은 값으로 설정하면 됨
- 그러면 EC2 인스턴스가 금방 사라지지 않고 연결 드레이닝 과정이 완료되기를 기다림
오토 스케일링 그룹(ASG)
개념
웹사이트나 애플리케이션을 배포하면 시간이 지나면서 로드가 변할 수 있음
클라우드에서 AWS에서는 EC2 인스턴스 생성 api 호출로 빠르게 서버를 생성하고 제거할 수 있음
=> 이를 자동화하고 싶을 때 오토 스케일링 그룹을 생성
스케일 아웃 : EC2 인스턴스를 추가해서 늘어난 로드에 맞춤
스케일 인 : 줄어든 로드에 맞추기 위해 EC2 인스턴스를 제거
따라서 ASG의 크기는 시간에 따라 달라짐
전체적으로 매개변수를 정의해서 ASG에서 언제든 실행할 수 있는 최소 및 최대 EC2 인스턴스의 개수를 정할 수 있음
로드 밸런서와 연결하면 ASG에 포함된 EC2 인스턴스가 로드 밸런서에 연결됨
- ASG에 등록된 인스턴스가 4개면 ELB가 즉시 모든 인스턴스에 트래픽을 분산시킴
어떤 인스턴스가 비정상이라고 여겨지면 이것을 종료하고 새 EC2 인스턴스를 만들어 대체함
- ELB는 상태 확인 기능을 활용해서 EC2 인스턴스의 상태도 점검할 수 있음
- 상태 확인 결과는 ASG에 전달될 수 있음 => 로드 밸런서가 인스턴스를 비정상으로 여기면 ASG가 인스턴스를 종료할 수 있음
- EC2 인스턴스를 추가하면(스케일 아웃) ELB가 트래픽을 분산시킴
무료이며 그 아래에 생성되는 EC2 인스턴스와 같은 리소스에 대해서만 비용을 내면 됨
속성
-
시작 템플릿을 만들어야 함
- ASG에서 인스턴스를 시작하는 방법에 관한 정보가 있음
- AMI + 인스턴스 유형
- EC2 사용자 데이터
- EBS 볼륨
- 보안 그룹
- SSH 키 페어
- EC2 인스턴스를 위한 IAM 역할
- 네트워크와 서브넷 정보
- 로드밸런서 정보
-
ASG의 최소 크기, 최대 크기, 초기 용량과 스케일링 정책을 정의해야 함
스케일링 정책 - CloudWatch 경보가 어떻게 오토 스케일링과 통합되는지
CloudWatch 경보를 기반한 ASG에서 스케일 인/아웃을 할 수 있음
평균 CPU를 관찰할 수 있는 지표나 원하는 사용자 지정 좌표가 경보를 울릴 수 있음
전체 평균 CPU가 너무 높으면 인스턴스를 추가
경보를 기반으로 스케일 인/아웃 정책을 만들어 인스턴스를 늘리거나 줄일 수 있음
오토 스케일링 그룹 - 스케일링 정책
동적 스케일링
-
목표 추적
- 설정이 매우 간단
- CPU 사용률과 같은 ASG에 대한 매트릭을 정의하고 40%와 같은 목표값을 정함
- 자동으로 ASG가 확장되거나 축소되어 이 메트릭을 약 40%로 유지 가능
-
단순/단계 스케일링
- 클라우드 와치 알람을 정의하여 오토 스케일링 그룹에 용량 단위를 추가하거나 제거하고자 할 때 알람이 발생
-
예약 스케일링
- 알려진 사용 패턴을 기반으로 스케일링을 예상할 수 있음
- ex. 금요일 오후 5시에 매번 사용자가 늘어나므로 최소 용량을 10으로 늘리려는 경우
-
예측 스케일링
- 지속적으로 부하를 예측한 다음 미리 예약을 시작하는 경우
- 반복되는 패턴이 있을 때 좋음
- 자동으로 과거 부하를 분석한 다음 예측치를 생성하여 예측치를 기반으로 스케일링 작업을 예약
- 주기적인 데이터가 있는 경우 매우 유용
어떤 좋은 메트릭을 활용해서 스케일링을 할까
애플리케이션이 수행하는 작업과 작동 방식에 따라 달라짐
- CPU 활용도
인스턴스가 요청을 받을 떄마다 일반적으로 일종의 계산을 수행하기 때문
따라서 일부 CPU를 사용하게 됨
따라서 모든 인스턴스의 평균 CPU사용률을 살펴본 후 이 비율이 높아지면 인스턴스 활용도가 더 높다는 의미
- 타겟당 요청 수
EC2 인스턴스는 한 번에 타깃 별로 1000개의 요청이라는 최적의 요청으로 작동
- 애플리케이션이 네트워크에 의존적인 경우
업로드와 다운로드가 너무 많고 네트워크가 EC2 인스턴스의 병목현상이 될 것이라고 예상된다면 평균 네트워크 사용량을 기준으로 스케일링을 설정
특정 임계값에 도달했을 때 자동으로 스케일링이 이루어지거나 클라우드 와치에 설정한 사용자 정의 메트릭을 기반으로 스케일링 조정 가능
스케일링 쿨다운
스카일링 작업이 있은 후에 인스턴스를 추가하거나 제거할 때마다 기본적으로 5분 쿨다운 시간에 들어감
쿨다운 시간 동안 ASG는 추가 인스턴스를 개시하거나 종료하지 않음
=> 메트릭이 안정화되도록 하고 새로운 인스턴스가 적용되어 새로운 메트릭이 어떻게 변할지 지켜보는 시간을 가지기 위해서
기본 쿨다운이 효과가 있는가?
효과가 있다 => 작업 무시
그렇지 않다 => 인스턴스를 시작하거나 종료하는 스케일링 작업
따라서 준비된 도구를 사용하여 EC2 인스턴스 설정 시간을 줄여 요청을 더 빠르게 처리할 수 있도록 하는 것이 좋음
EC2 인스턴스를 설정하는데 시간을 소비하지 않으면 즉시 효과가 나타날 수 있음
훨씬 더 빠르게 활성화될 수 있기 때문에 쿨다운 시간을 줄일 수 있고 ASG를 더욱 동적으로 확장 및 축소할 수 있음
인스턴스 새로고침
생성해 둔 시작 템플릿 덕분에 전체 오토 스케일링 그룹을 업데이트 할 수 있음
이에 따라 EC2 인스턴스를 다시 생성해야 함
=> 인스턴스를 종료하고 다시 나타날 때까지 기다리는 대신 오토 스케일링의 고유 기능인 인스턴스 새로고침을 사용할 수 있음
최소값의 정상 백분율 설정 가능
=> 시간이 지나면서 삭제되는 인스턴스의 개수를 오토 스케일링 그룹에 알림
=> 인스턴스가 종료되면 새 인스턴스가 새 시작 템플릿으로 나타남
=> EC2 새로고침
EC2 인스턴스가 준비되고 트래픽을 처리할 수 있는 충분한 시간이 있는지 확인하려면 워밍업 시간을 지정할 수 있음
새 인스턴스를 사용할 준비가 될 때까지 시간을 지정할 수 있음
