
RDS
관계형 데이터베이스 서비스
SQL을 쿼리 언어로 사용하는 데이터베이스에 대한 관리형 데이터베이스 서비스
클라우드에서 RDS 서비스인 데이터베이스를 만들 수 있고 이러한 데이터베이스는 aws에서 관리함
- Postgres, MySQL, MariaDM, Oracle, IBM DB2, Microsoft SQL Server, Aurora(AWS 독점)
EC2 인스턴스 위에 자체 데티어베이스 서비스를 구축하는 대신 RDS를 사용하는 이유?
=> RDS는 관리형 서비스이기 때문에 데이터베이스를 제공하는 것 외에 많은 서비스 제공
- 데이터베이스 프로비저닝은 완전히 자동화되어 있음
- 기본 운영 체제 패치
- 지속적인 백업이 이루어지고 특정 타임스탬프로 복원됨(특정시점복원)
- 모니터링 대시보드를 사용하여 데이터베이스 성능 확인 가능
- 읽기 복제본을 가질 수 있음
- 읽기 성능을 향상시키기 때문에 다중 가용 영역 설정 가능(재해 복구)
- 업그레이드를 위한 유지보수 창이 있음
- 인스턴스 유형을 늘려 수직적으로 확장하거나 읽기 전용 복제본을 추가하여 수평적으로 확장할 수 있는 기능이 있음
- EBS의 지원을 받음(gp2, io1)
=> 그러나 RDS 인스턴스에 SSH를 적용할 수 없음
관리형 서비스이기 때문에 aws는 서비스를 제공하지만 기저 EC2 인스턴스에 접근할 수 없음
그러나 EC2 자체 데이터베이스 엔진을 배포하려는 경우 자체적으로 설정해야 하는 모든 항목을 갖기 때문에 그리 나쁘지 않음
RDS 스토리지 오토 스케일링
RDS 데이터베이스를 생성할 때 원하는 스토리지 용량을 지정해야 함
여유공간이 부족한 경우 이를 감지하여 RDS 스토리지가 자동으로 스케일업 함
=> 스토리지를 늘리기 위해 데이터베이스를 중단하는 등의 작업을 할 필요가 없음
데이터베이스 스토리지를 수동으로 스케일링 하는 작업을 방지함
이를 위해선 최대 저장 임계값을 설정해야 함(스토리지 확장을 원하는 최대 한도)
예측할 수 없는 업무량을 가진 애플리케이션에 매우 유용함
RDS용 모든 데이터베이스 엔진을 지원함
RDS 읽기 전용 복제본과 다중 AZ
RDS 읽기 전용 복제본
주된 데이터베이스 인스턴스가 너무 많은 요청을 받아 충분히 스케일링을 할 수가 없기에 읽기를 스케일링 한다고 했을 떄
- 읽기 전용 복제본을 최대 5개 생성 가능
- 동일한 가용 영역 또는 가용 영역이나 리전을 걸쳐서 생성 가능
- 주된 RDS 데이터베이스 인스턴스와 두 읽기 전용 복제본 사이에 비동기식 복제가 발생함
- 비동기식이란 결국 읽기가 일관적으로 유지된다는 뜻
- 애플리케이션에서 데이터를 복제하기 전 읽기 전용 복제본을 읽어들이면 모든 데이터를 얻을 수 있음
- 일관적인 비동기식 복제를 의미
- 복제본을 데이터베이스로도 승격시켜 이용할 수 있음
- 자체적인 생애 주기를 가짐
- 읽기 전용 복제본을 이용하는 경우에는 주요 애플리케이션에 있는 모든 연결을 업데이트 해야 하며 이를 통해 RDS 클러스터 상의 읽기 전용 복제본 전체 목록을 활용할 수 있음
네트워킹 비용
- aws에서는 하나의 가용 영역에서 다른 가용 영역으로 데이터가 이동할 때에 비용이 발생
- RDS 읽기 전용 복제본은 관리형 서비스이기 때문에 다른 az여도 동일한 리전 내에 있을 때는 비용이 발생하지 않음
다중 AZ(재해 복구)
- 동기적으로 복제
- 애플리케이션 마스터에 쓰이는 변경 사항이 대기 인스턴스에도 그대로 복제됨
- 하나의 DNS 이름을 갖고 애플리케이션 또한 하나의 DNS 이름으로 통신하며 마스터에 문제가 생기면 스탠바이 데이터베이스에 자동으로 장애 조치가 수행됨
- 가용성을 높일 수 있음
- 전체 az 또는 네트워크가 손실될 때에 대비한 장애 조치이자 마스터 데이터베이스의 인스턴스 또는 스토리지에 장애가 발생할 때 스탠바이 데이터베이스가 새로운 마스터가 될 수 있도록 함
- 따로 앱에 수동으로 조치를 취할 필요가 없음
- 자동으로 데이터베이스에 연결이 시도되고 장애 조치가 필요하게 될 때에도 스탠바이가 마스터로 승격되는 과정이 자동으로 이루어짐
- 스케일링에 이용되지 않음
- 스탠바이 데이터베이스는 단지 대기 목적 하나만 수행
- 읽거나 쓸 수 없음
- 마스터 데이터베이스에 문제가 발생할 경우를 대비한 장애 조치일 뿐
- 재해 복구를 대비해서 읽기 전용 복제본을 다중 az로 설정할 수 있음
- 단일 az에서 다중 az로 RDS 데이터베이스 전환이 가능함
- 다운타임이 전혀 없음, 즉 단일 az에서 다중 az로 전환할 때에 데이터베이스를 중지할 필요가 없음
- 데이터베이스 수정을 클릭하고 다중 az 기능을 활성화하기만 하면 됨
오로라 (Aurora)
- aws의 독점 기술(오픈소스 아님)
- postgres, MySQL과 호환하도록 만들어짐
- 오로라 데이터베이스에는 호환 가능한 드라이버가 있으며 postgres, MySQL 데이터베이스에 연결하는 것처럼 드라이버가 작동한다는 의미
- 클라우드 최적화가 되어 있음
- MySQL보다 5배 뛰어난 성능
- postgres보다 3배 뛰어난 성능
- Aurora 스토리지는 자동으로 늘어남, 10GB ~ 128 TB
- 읽기 전용 복제본인 경우, 15개의 복제본까지 가질 수 있음, 또한 복제가 더 빠름
- Aurora에서 장애 조치를 수행하는 경우 즉각적으로 이루어짐
- RDS보다 20% 많은 비용이 들지만 효율이 더 좋음, 규모 면에서 절약에 더 유리
Aurora의 고가용성과 확장성
- 3개의 az에 걸쳐 무엇이든 쓸 때마다 데이터의 6개 사본을 저장
- 쓰기에는 6개 중 4개 사본만 필요함
- 읽기에는 6개 중 3개의 사본이 필요 => 읽기에 대한 가용성이 높다
- 자가 복구 프로세스(peer to peer 복제를 함)
- 하나가 아닌 수백 개의 볼륨에 의지함
- 쓰기를 담당하는 것은 Aurora의 마스터임
- 마스터가 작동하지 않으면 평균 30초 이내에 장애 조치가 이루어짐
- 마스터 외에도 최대 15개의 읽기 전용 복제본이 모두 읽기를 제공함
- 읽기 전용 복제본은 리전 간 복제를 지원함
Aurora DB Cluster
클라이언트가 있을 때 이 모든 인스턴스와 어떻게 인터페이스를 할 수 있을까?
- 마스터가 스토리지에 씀
- 마스터는 변경되고 장애가 발생할 수 있기 때문에 Aurora는 라이터 엔드포인트라는 것을 제공
- DNS 이름이며 항상 마스터를 가르키고 있음
- 마스터에 장애가 발생해도 클라이언트는 여전히 라이터 엔드포인트에게 말을 걸 수 있으며 올바른 인스턴스에 리디랙션 됨
- 읽기 전용 복제본 외에도 오토 스케일링을 보유하고 있음
- 올바른 개수의 읽기 전용 복제본을 가질 수 있음
- 이 때문에 애플리케이션이 추적하기 어려운 사항이 있음
- 레플리카가 어디 있는지 url의 여부, 어떻게 연결하는지
- 리더 엔드포인트라는 것이 있고, 라이터 엔드포인트와 동일한 기능을 가짐
- 연결 로드 밸런싱을 지원하며 모든 읽기 전용 복제본에 자동으로 연결
- 클라이언트가 리더 엔드포인트에 연결할 때마다 읽기 전용 복제본 중 하나에 연결되어 이러한 방식으로 로드 밸런싱이 이루어짐
Aurora의 기능
- 자동 장애 조치
- 백업 및 복구
- 격리성 및 보단
- 산업 규정 준수
- 오토 스케일링을 통한 푸시 버튼 스케일링
- 제로 가동 중지 자동 패치
- 고급 모니터링
- 정기 유지 관리
- 백트랙(언제든지 데이터를 복원할 수 있는 기능, 백업에 의존하고 있지 않음)
RDS & Aurora 보안
미사용 데이터 암호화(At-rest encryption)
- 데이터가 볼륨에서 암호화됨
- 이를 위해 KMS를 사용하여 마스터와 복제본을 암호화 해야함(데이터 베이스를 처음 실행하는 동안 실행 시간에 정의되어야 함)
- 마스터 데이터베이스, 즉 주요 데이터베이스를 암호화하지 못 한 경우, 읽기 전용 복제본이 암호화될 수 없음
- 암호화되지 않은 기존 데이터베이스를 암호화하려면 암호화되지 않은 데이터베이스에서 데이터베이스 스냅샷을 가져온 다음, 해당 데이터베이스 스냅샷을 암호화된 데이터베이스로 복원하면 됨
전송 중(In-flight) 암호화
- 클라이언트와 데이터베이스 간의 암호화
- 기본적으로 전송 중 암호화를 사용할 준비가 되어 있음
- 클라이언트는 aws의 TLS 루트 인증서를 사용해야 함
IAM Authentication
- aws 이므로 iam 역할을 사용하여 데이터베이스에 인증하여 연결할 수 있음(유저 이름, 비밀번호 대신)
보안 그룹
- 네트워크 엑세스 제어 가능
- 특정 포트, IPS, 보안 그룹을 허용하거나 차단 가능
SSH 엑세스를 갖고 있지 않음
- 관리형 서비스이기 때문
- RDS Custiom은 예외
감사 로그가 필요한 경우
- 쿼리와 시간이 지나면서 데이터베이스에서 일어나는 일을 파악하려면 감사 로그를 활성화 하면 됨
- 오랜 기간 보관하고 싶다면 AWS CloudWatch 로그 서비스하는 전용 서비스에 전송하면 됨
RDS Proxy(RDS 프록시)
- vpc에 RDS 데이터베이스를 배포할 수 있음
- RDS의 완전 관리형 데이터베이스 프록시도 배포할 수 있음 => RDS 데이터베이스로 직접 엑세스 가능
- RDS Proxy를 사용하면 애플리케이션이 데이터베이스로 설정된 데이터베이스 연결을 풀링하고 공유할 수 있음
- 모든 애플리메이션을 데이터베이스 인스턴스가 아닌 프록시에 연결
- CPU, RAM 등 데이터베이스 리소스에 대한 스트레스를 줄여서 데이터베이스 효율성을 향상해 줌
- 열린 연결과 데이터베이스에 대한 시간 초과 최소화
- 서버리스, 오토 스케일링 => 용량 관리 안해도 됨
- 높은 가용성(다중 az)
- 프라이머리 인스턴스에서 대기 인스턴스로 이동하는데 RDS 프록시 덕분이 장애 조치 시간이 최대 66% 줄어듦
- RDS(MySQL, postgreSQL, MariaDB), Aurora(MySQL, postgreSQL)에 대해 RES 지원,
- 애플리케이션에서 코드를 변경하지 않아도 됨
- 데이터베이스의 IAM 인증을 시행함(IAM을 사용해야만 RDS 데이터베이스 인스턴스에 연결 가능)
- 자격 증명은 AWS Secrets Manager라는 서비스에 안전하게 저장
- 프록시에는 공개적으로 엑세스 불가능, VPC에서만 가능
ElastiCache(일래스틱캐시)
- RDS가 관리된 관계형 데이터베이스를 갖는 것과 같은 방식
- ElastiCache는 캐시 기술은 관리형 Redis, Memcached를 얻을 수 있도록 도와줌
- 캐시란 굉장히 높은 성능과 짧은 대기 시간을 가진 인 메모리 데이터베이스
- 읽기 집약적인 워크로드에 대한 데이터베이스의 부하를 줄일 수 있도록 도와줌
- 일반적인 쿼리가 캐시되기 때문에 데이터베이스는 매번 쿼리되지 않음
- 애플리케이션 상태를 ElastiCache에 입력하여 애플리케이션을 무상태로 만드는데 도움을 줌
- aws는 동일한 운영 체제와 패칭, 최적화, 설정 구성, 모니터링, 장애 복구, 백업을 처리함
- 과도한 애플리케이션 코드 변경을 다뤄야 함
- 데이터베이스를 쿼리하기 전후에 애플리케이션을 변경하여 캐시를 쿼리해야 함
ElastiCache 아키텍쳐(ElastiCache Solution Architecture)
DB Cache
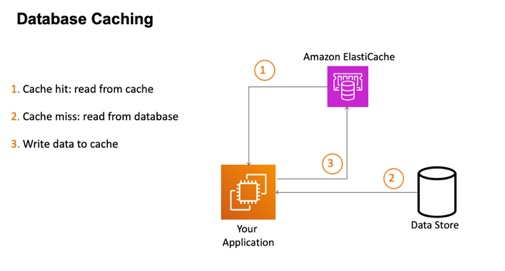
- 애플리케이션이 ElastiCache를 쿼리하여 쿼리 오류가 발생했는지, 이미 발생하여 ElastiCache에 저장했는지 확인: 캐시 적중(Cache hit)
- 캐시 누락인 경우(Cache miss): 데이터베이스에서 읽어옴
- 데이터를 캐시에 다시 쓸 수 있음 => 다음에 수행되는 쿼리가 캐시 적중으로 이어짐 => RDS 부하 줄어듦
- 최신 데이터만 사용하도록 캐시 무료화 전략이 있어야 함
User Session Store(사용자 세션 저장)
- 사용자가 어떤 정류의 애플리케이션이건 로그인하면 애플리케이션이 ElastiCache로 세션 데이터를 씀
- 애플리케이션의 또 다른 인스턴스로 리디렉션되면 애플리케이션은 ElastiCache에서 직접 세션의 세션 캐시를 검색 => 사용자는 여전히 로그인된 상태를 유지할 수 있음
- ElastiCache로 사용자의 세션 데이터를 써서 애플리케이션을 무상태로 만듦
Redis vs Memcached
Redis
- 자동 장애 조치를 가진 다중 AZ가 있음
- 읽기 전용 복제본(Read Replicas)이 있어서 읽기를 스케일링하고 고가용성 보유
- AOF 지속성을 사용하는 데이터 내구성이 있으며
- AOF(Append On File)
- redis의 모든 쓰기 작업(write/update) 연산 자체를 모두 log 파일에 기록하는 형태
- 데이터 복구/영속성을 제공하기 위한 로그 파일 방식
- AOF(Append On File)
- 백업과 복원 기능
- 세트와 정렬 세트를 지원함
Memcached
- 데이터 파티셔닝에 다중 노드 사용(샤딩)
- 고가용성이 없으며 복제도 발생하지 않음
- 지속적인 캐시가 아님
- 백업과 복원 기능 없음
- 다중 스레드 아키텍쳐 => 샤딩을 통해 Memcached에서 작동하는 여러 인스턴스를 보유
- 분산된 순수 캐시, 데이터 손실을 감당해야 함
ElastiCache 전략 및 고려사항
- 데이터를 캐싱하는 것은 보통 안전한가?
- 최신 데이터가 아닐 수 있지만 결국엔 일관성을 유지
- 캐싱해도 괜찮을 때만 데이터를 캐싱해야 함
- 캐싱이 데이터에 효과적인가?
- 패턴 : 데이터가 천천히 바뀌고 자주 필요한 키가 적을 경우엔 괜찮음
- 안티 패턴 : 데이터가 빠르게 바뀌고 데이터셋의 모든 키가 필요한 경우에는 효과적이지 않음
- 데이터 구조가 캐싱에 적합한가?
- 키값이 있고 집계 결과를 저장하고 싶을 때 좋음
- 데이터의 구조가 적합한지 캐싱하기 전에 확인해야 함
어떤 캐싱 설계 패턴이 가장 적합한가?
- 레이지 로딩(Lazy Loading, Cache-Aside, Lazy Population)
a. 애플리케이션이 읽기 원하면 ElastiCache에 먼저 요청함
b. 레디스나 멤캐시드인 ElastiCache가 캐시 히트를 보내면 무언가를 가지고 있단 뜻
c. 캐시 미스인 경우에는 ElastiCache에 데이터가 없는 경우이기 때문에 데이터를 찾기 위해 RDS(데이터베이스)에 가서 읽으려고 함
d. 올바른 데이터를 갖고 같은 데이터를 요청하는 다른 애플리케이션에 캐시 히트를 바로 주기 위해 해당 데이터를 ElastiCache에 기록
장점
- 오직 요청된 데이터만 캐싱됨
- RDS에서 요청 받은 데이터가 없는 경우 캐싱 되지 않음
- 캐시가 삭제되거나 노드 실패가 발생해도 치명적이지 않음
- 캐시를 예열(모든 읽기가 RDS로 간 뒤 캐싱 되어야 함을 의미)해야 하므로 대기 시간은 늘어남
단점
- 캐시 미스인 경우에 애플리케이션에서 ElastiCache로 3번의 네트워크 호출이 이루어짐 => 사용자 입장에서 지연 시간 발생(읽기 패널티)
- 캐시 미스인 애플리케이션에서 RDS로
- 데이터베이스를 읽으면서
- 캐시를 쓰면서
- 오래된 데이터
- 데이터가 RDS에서 업데이트 돼도 ElastiCache 캐시에서 업데이트 되는 것이 아니므로 오래된 데이터가 남아있을 수 있음
- 최신 데이터가 아니어도 일관성을 유지하는게 중요 여부가 필요
- 라이트 스루(Write Through)
데이터베이스가 업데이트 될 때 캐시를 추가하거나 업데이트하는 것을 의미
캐시 미스인 경우 RDS에서 쓰기를 할 때 먼저 캐시에 씀
ElastiCache를 통해 RDS에 씀
장점
- 케시 데이터는 절대 오래될 수 없음
- RDS가 바뀔 때마다 캐시도 자동으로 바뀜
- 데이터베이스에 쓸 때 쓰기 페널티를 갖게 됨, 2번의 호출 필요 => 읽기보다 쓰기에 시간이 더 필요함
- 데이터베이스로 한 번
- 캐시로 한 번
단점
- RDS가 업데이트되거나 추가될 때까지 데이터 누락이 발생할 수 있음
- RDS에 기록되기 전에 일래스틱 캐시 또는 일반 캐시가 필요한 모든 데이터를 갖지 못함
- 캐시 이탈률
- RDS에 많은 데이터를 추가할 경우 절대 읽히지 않을 가능성이 있음
- 모든 데이터 쓰기 요청이 캐시와 RDS 모두에 적용되므로 저장된 데이터 중 일부는 이후 사용되지 않거나 읽히지 않을 가능성이 있음
- 캐시 용량이 작을 경우에는 문제될 수가 있음
- RDS에 많은 데이터를 추가할 경우 절대 읽히지 않을 가능성이 있음
- 캐시 제거와 Time-to-Live(TTL)
캐시에 제한된 크기가 있음
- 따라서 캐시 데이터를 제거하기 위해 Cache Eviction이란 방법을 사용
- 항목을 캐시에서 명시적으로 삭제
- 캐시 메모리가 꽉 찼을 때 사용 => 가장 최근에 사용하지 않은 항목이 제거(LRU, Least Recently Used)
- 항목을 TTL로 설정할 수 있음(이 항목은 5분 동안만 사용 => 5분 후엔 캐시에서 삭제)
- TTL은 리더보드, 코멘트, 활동 스트림 등 어떤 종류의 데이터에도 유용함
- TTL은 짧으면 몇 초에서 몇 시간 또는 며칠까지 갈 수 있음
- 만약 메모리가 꽉 차서 너무 많이 제거된다면 확장을 통해 캐시 크기를 늘려야 함
- 레이지 로딩과 캐시 어사이드 전략
- 쉽게 구현 가능
- 많은 상황에서 기초로 사용됨, 여러 애플리케이션에서 사용 추천
- 특히 읽기 성능 개선
- 라이트 스루
- 손이 더 감
- 자체로 캐시 전략이라기 보다는 레이지 로딩의 후속 효과로 인해 발생하는 최적화 문제
- TTL
- 라이트 스루를 사용할 때를 제회하면 좋음
- 애플리케이션에 적합한 값을 설정해야 함
- 필요한 데이터에만 캐싱을 적용할 것(사용자 프로필, 블로그, ..)
Redis용 Amazon MemoryDB
- Redis와 호환되고 내구성이 뛰어난 인 메모리 데이터베이스 서비스
- Redis는 약간의 내구성을 갖춘 캐시, MemoryDB는 Redis와 호환되는 api가 있는 데이터베이스
- 초당 1억 6천만건의 요청을 처리하는 초고속 성능을 제공
- 인메모리 데이터 및 내구성이 좋은 데이터 스토리지로서 다중 az 트랜잭션 로그를 갖추고 있음
- 10 기가바이트 ~ 100 테라바이트 이상의 크기 조정 가능
- 웹 및 모바일 애플리케이션, 온라인 게임, 미디어 스트리밍, .. 에 사용
