요약
대용량 이미지로 pretrained된 text to image diffusion model에 공간적 조건 제어 기능을 추가하는 모델이다. canny map, depth, segmentation, Human pose 등과 같은 다양한 조건 제어 방식을 Stable Diffusion 모델에서 단일 또는 다중 조건으로, 프롬프트를 사용하거나 사용하지 않는 방식으로 테스트한다.
소개
controlnet은 입력조건을 학습하기 위해 대규모 데이터셋을 학습한 diffusion model을 제어하는 모델
허용가능한 시간과 메모리 내에서 특정 task에 대해 대형모델의 빠른 학습을 위해서 최적화하는 fine-tuning이나 transfer learning이 필요하다.
저자는 diffusion model중 stable diffusion model과 사용하는 것에 대해 제안하고 있다.
방법
- Image Diffusion
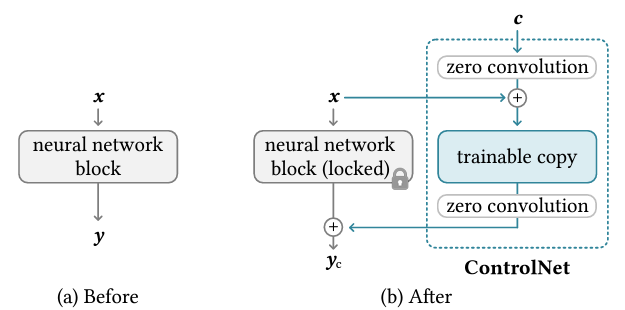
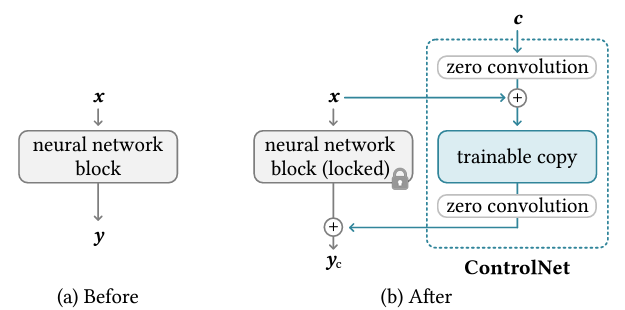
기존 neural network block에 Controlnet블럭을 추가한 구조의 장점은 먼저 c 벡터인 조건을 추가할 수 있다는 점이며 이를 통해 anime스타일이나 canny map, depth, open pose등 다양한 조건을 추가하여 diffusion모델을 제어할 수 있다. 다음으로 회색블럭을 보면 locked라고 되어 있는데 이는 copy 파라미터를 고정하여 gradient 연산을 요구하지 않아 연산복잡도를 효율적으로 할 수 있어 학습속도를 줄일 수 있으며 GPU메모리 사용량을 줄일 수 있다.
zero convolution layer는 가우시안 가중치와 bias가 0으로 초기화된 1x1 convolution layer이다. 이를 사용함으로써 학습과정에 있어 노이즈를 방지할 수 있기 때문에 고품질의 이미지를 예측할 수 있다. 그리고 trainable copy는 원래의 가중치를 직접 학습하는 대신 사본을 만들어 데이터 셋이 작을 때의 과적합을 방지할 수 있고 대규모 데이터셋으로 사전학습된 모델의 성능을 최대한 유지할 수 있다는 장점이 있다.
- Stable Diffusion 구조
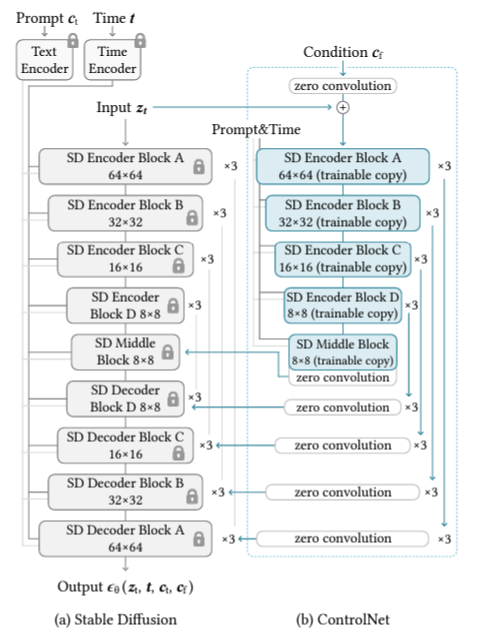
stable diffusion의 U-net 구조는 controlnet의 encoder블럭과 middle블럭이 연결되어 있음.
고정된 회색 블럭은 stable diffusion이며 모두 25개의 블럭으로 구성되있으며 encoder와 decoder가 모두 12개이고, 이 블럭 중 8개의 블럭은 다운샘플링 또는 업샘플링 conv layer를 뜻함. 나머지 17개의 블럭은 4개의 resnet 레이어와 2개의 vit를 포함하는 기본블럭이다. 각 vit에는 몇가지 cross attention과 self attention 매커니즘이 적용되어 있다. (SD Encoder Block은 Resnet레이어 4개와 vit 2개로 구성되어있고 x3은 블럭을 3번 반복 한다는 의미) middle 블럭이 controlnet의 trainable copy인 새로운 파라미터를 받는 encoder 블럭과 연결되어 있다.
텍스트는 OpenAI CLIP으로 인코딩되고 diffusion timestep은 위치 인코딩으로 인코딩된다.
Stable Diffusion은 VQ-GAN과 유사한 전처리 방법을 사용하여 안정화된 학습을 위해 512×512 이미지의 전체 데이터셋을 더 작은 64×64 크기의 latent 이미지로 변환한다. 이를 위해서는 convolution 크기와 일치하도록 이미지 기반 조건들을 64×64 feature space로 변환하는 ControlNet이 필요함
- controlnet 구조
12개 블럭으로 되어 있는 trainable copy와 stable diffusion의 middle 블럭 1개를 사용. 4개의 해상도를 가지는 3개의 블럭으로 되어있다. 12개의 skip connection 과 middle블럭을 지나 출력이 나옴. 전형적인 u-net구조로 되어있기 때문에 다른 diffusion모델과 적용해도 된다고 함. zero conv layer는 가중치와 bias가 0인 1x1 conv layer를 뜻하는데 stable Diffusion의 decoder블럭과 연결된다( concat)
이게 무엇을 뜻하냐면 zero convolution은 학습을 통해 0에서 최적화된 파라미터로 점진적으로 성장하는 고유한 유형의 연결 레이어가 된다.
이 방식으로 진행할시 copy 파라미터가 고정되어 있고 gradient computation이 요구되지 않기 때문에 효율적인 연산복잡도를 가짐.
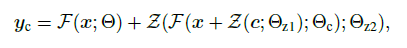
x=input feature map, F(x; Θ)=neural network블럭, Z(·; ·)=zero conv layer, Θz1 and Θz2= zero conv parameter, yc=controlnet블럭의 최종 output
- Training과정
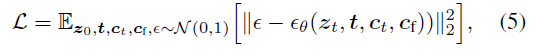
loss계산은 기존 stable diffusion과 동일하다.
zt=노이즈 이미지, t=타임스텝, ct=텍스트 프롬프트, cf=입력하는 조건들
모델은 t시점에 추가된 노이즈를 예측하고 예측된 노이즈와 t시점에 실제로 추가된 노이즈와의 차를 구해서 loss로 사용함
controlnet의 학습과정 중 입력되는 텍스트 프롬프트의 경우 학습과정에서는 50%는 랜덤하게 빈 문자열로 변환되어 학습된다. 이는 프롬프트의 정보를 제한하고 인풋되는 조건에서 의미론적인 내용들을 학습하고자 하는 방향으로 학습하는 것임.
sudden convergence phenomenon이 관찰(갑작스러운 수렴 현상)
주어진 조건들이 잘 반영된 이미지들을 모델이 갑자기 생성하는 현상. 보통 1만optimization step 이전쯤에 갑작스러운 수렴 현상이 관찰된다고 함.
아래 사과 이미지의 경우 6100 step 까지는 안 나오다가 1만optimization step 이전인 6133 step 에서 갑자기 잘 나오게 되는 것을 확인할 수 있음

zero conv가 최적화되지 않다 하더라도 기존 stable diffusion의 파라미터를 freeze 즉, copy해서 사용하고 있기 때문에 고품질의 이미지를 생성할 수 있다. 6100까진 학습이 최적화되지 않더라도 이미 freeze에서 사용하고 있는 파라미터에 의해서 고품질의 이미지가 생성됨을 확인할 수 있고 조건이 반영되지 않은 고품질의 이미지를 생성하다가 zero conv의 최적화가 진행되면서 조건을 잘 이해할 정도로 최적화가 되었을때 조건이 반영된 고품질의 이미지를 갑자기 생성해내는 것
- Inference
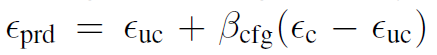
denoising diffusion 프로세스에서 controlnet에 주어진 추가적인 조건 정보들을 제어할 수 있는 방법에 대해 소개하고 있다. 기존 stable diffusion 추론과정에서는 classifier free guidance 라는 개념을 사용.
앱실론prd=최종output, 앱실론uc= 조건정보를 반영하지 않은 ouput, 앱실론c= 조건정보를 사용해서 도출하는 output, 베타cfg =guidance scale(조건정보를 얼마나 반영하여서 이미지를 생성할 것인가를 제어할 수 있는 사용자 지정 가중치)
classifier free guidance 베타값을 통해서 stable diffusion은 얼마나 이 조건정보를 반영하여 이미지를 생성할 수 있을지 제어할 수 있는 것. classifier free guidance 통해 실험을 진행. 맨 좌측에 input conditioning이미지. 프롬프트가 없는 상태로 실험을 진행.
실험 결과
CGF-scale:9.0
sampler: DDIM
여러가지 Task에 대한 실험을 했음.
스케치 이미지 condition과 4가지 프롬프트 세팅에 대한 실험결과

각각 모델 구조를 변형
a=논문에서 제안한 구조
b=zero conv를 Gaussian가중치로 초기화된 standard conv로 대체
c=Trainable copy대신 단일conv로 변경
첫번째 열은 프롬프트를 빈 문자열로 생성한 것
두번째 열은 정보가 부족한 텍스트
세번째 열은 무관한 텍스트
네번쨰 열은 완벽한 텍스트
결론은 프롬프트를 잘 입력할 수록 좋은 성능을 보임.
Trainable copy와 zero conv의 효과가 강력한것으로 보임
zero conv가 없거나 Trainable copy를 사용하지 않은 구조의 경우 Trainable copy가 가지고 있었던 사전학습된 정보들이 파인튜닝 과정에서 destroy되어 이미지 생성을 제대로 못하고 있는 것을 알 수 있었다.
