논문스터디
1.[논문리뷰] Refined Feature-Space Window Attention Vision Transformer for Image Classification
요약 최근 Vision Transformer(ViT) 모델은 이미지 분류에서 뛰어난 성능을 보여주며 주목받고 있다. 특히, Transformer의 강력한 전역적 학습 능력 덕분에 복잡한 이미지에서도 우수한 분류 성능을 발휘할 수 있다. 하지만, ViT의 계산량과 자원의
2.[논문리뷰] FSwin Transformer: Feature-Space Window Attention Vision Transformer for Image Classification

요약 윈도우 기반의 Vision transformer(ViT)는 이미지 크기에 따라 2차 계산복잡도를 나타낸다. 이 문제를 해결하기 위해 윈도우 기반의 self-attention ViT는 attention영역을 특정 윈도우로 제한하여 계산 복잡도를 완화시킨다. 그러나
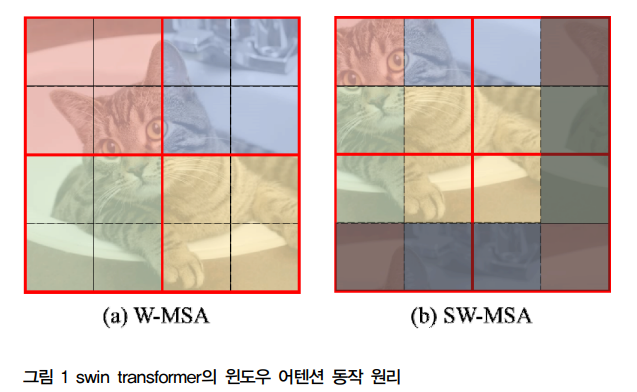
3.[논문리뷰] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
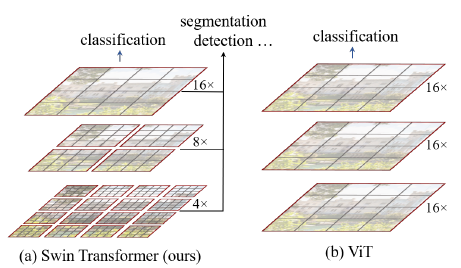
요약 컴퓨터 비전 분야는 주로 CNN(Convolutional Neural Networks)이 지배해왔다. 그러나 NLP(Natural Language Processing)에서 성공을 거둔 Transformer 모델을 비전 분야에 적용하려는 시도가 계속되어 왔으며 이
4.[논문리뷰] (Vision Transformer) An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
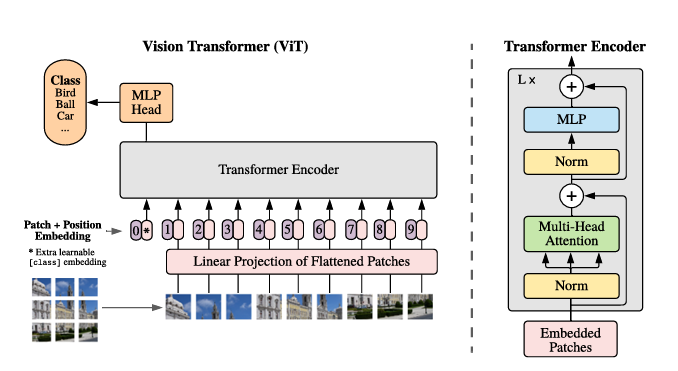
CNN구조였던 Vision문제에 NLP에서 표준이 된 Transformer 아키텍처를 이미지 인식 문제에 적용한 연구이다. 이전의 Vision Task에서 Self-attention 적용에 한계가 있었다. Self-attention을 적용하려는 시도는 있었으나 Hard
5.[논문리뷰] U-Net: Convolutional Networks for Biomedical Image Segmentation
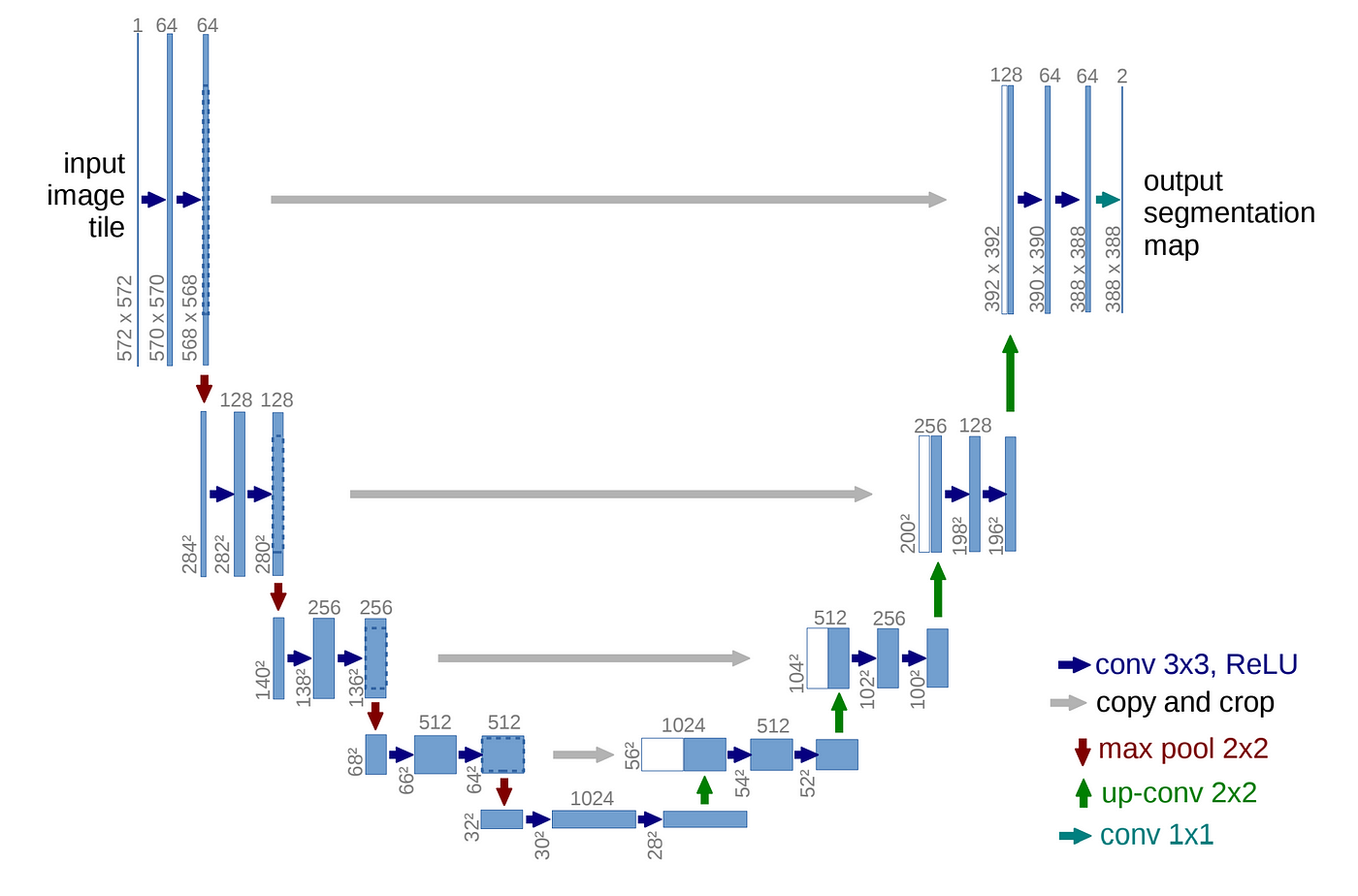
요약 본 논문은 Fully convolutional network를 기반으로 U자 형태의 네트워크로 설계됨. 신경망 구조의 skip connection을 평행하게 두고 가운데를 기준으로 좌우가 대칭이 되도록 레이어를 배치하였다. 왼쪽에 Contraction path와
6.[논문리뷰] Adding Conditional Control to Text-to-Image Diffusion Models
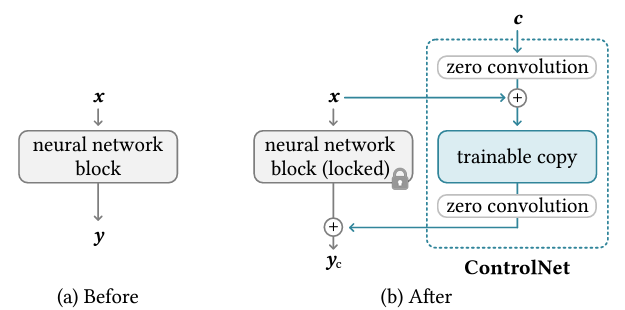
요약 대용량 이미지로 pretrained된 text to image diffusion model에 공간적 조건 제어 기능을 추가하는 모델이다. canny map, depth, segmentation, Human pose 등과 같은 다양한 조건 제어 방식을 Stabl