python의 data type 이해하기
📌 data type이 다양한 이유
컴퓨터는 '변수'라는 개념을 통해 데이터를 관리한다. 이때 변수는 물리적인 메모리의 주소 공간을 의미하며 컴퓨터는 '변수'라는 공간에 데이터를 할당한다. 기업에서 다루고자 하는 data는 단순히 정수뿐만 실수, 문자, 리스트 등 다양한 종류가 있다. 이러한 data type 마다 data를 연산하는 방법, 연산의 결과 값이 다르기 때문에 각 data type의 특징을 이해하는 것을 필수적으로 요구한다.
🗂 Python : data types
- 숫자 데이터(Numeric Data Types)
- 정수형
- 실수형
- 문자열(String)
- 집합(Set)
- 연속형 데이터(Sequential Data Types)
- 리스트(List)
- 튜플(Tuple)
- 사전(Dictionary)
🗂 연속형 데이터, 리스트와 튜플의 차이
연속형 데이터는 여러개의 데이터를 하나의 변수에 가지고 있는 데이터 타입이다. 리스트와 튜플은 비슷하지만 리스트는 유연하게 수정이 가능하지만 튜플은 생성 후에 변경이 불가능하다.
- mutable한 data type : list와 dict, set
- immutable한 data type : int, float, string, tuple, frozenset
immutable한 data type을 사용할 경우에 data를 생성하면 이후에 수정을 할 수 없기 때문에 기존의 데이터가 변경되지 않는다는 장점이 있다.
data type을 잘 이용하면 데이터 분석할 때 실수를 줄이고 어디서 문제가 발생했는지 확인할 수 있어 시행착오를 줄일 수 있다. 프로젝트 진행 시 mutable한 data type을 이용하면 데이터 분실이 발생할 수 있는데, immutable한 data type은 수정자체가 불가능하기 때문에 데이터 수정이나 분실을 막을 수 있다.
🗂 집합의 연산
집합은 중복되는 원소를 표시하지 않는다.
- 교집합
s1 & s2
s1.intersection(s2) == s2.intersection(s1)
- 합집합
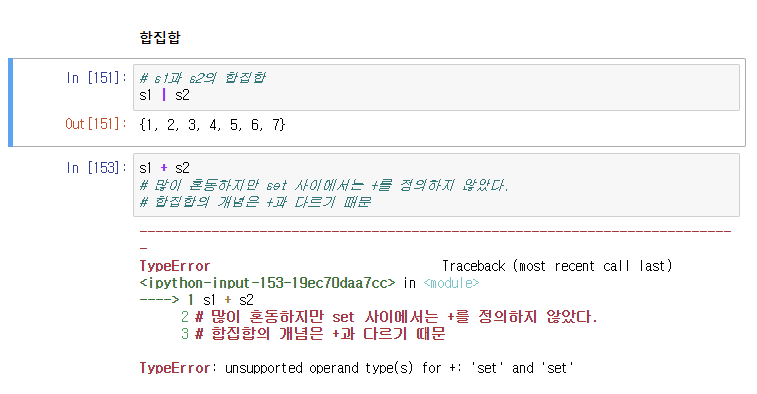
- 차집합
s2 - s1 # 당연히 s1 - s2와 다르다.
2주차 강의 내용 중 data type에 관한 내용을 간단히 정리했고 다음은 파이썬 함수와 함수를 사용한 예제에 관한 내용을 정리할 예정이다.
