
엘라스틱서치
프로젝트 도중 RAG를 통해 해당 학습데이터를 임베딩처리후 엘라스틱에 색인과정을 거쳐 fast API로 LLM을 통해 응답을 받는 구조로 진행되었을 때
엘라스틱에 대해 조금 더 공부를 진행해 보려고 한다.
중간에 에러가 나면 밑에까지 읽고 판단하자
엘라스틱 서치
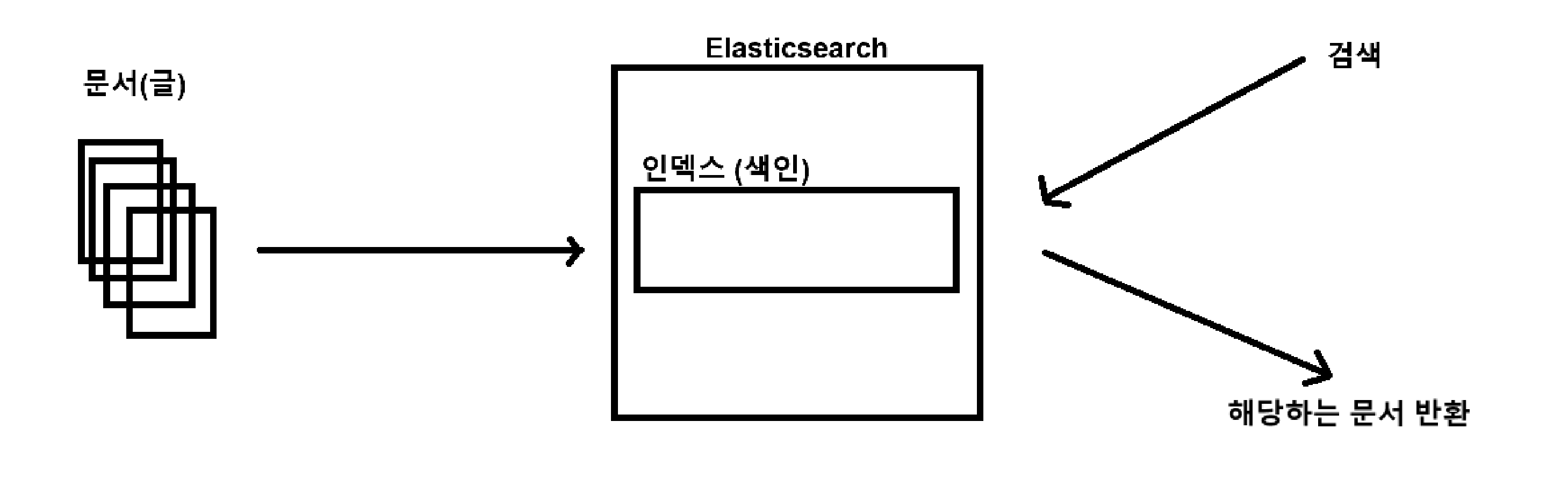
검색엔진을 활용해 수많은 문서중 특정 키워드를 가진 문서를 찾기 위해 문서들을 인덱스화 시키고, 인덱스를 통해 검색한다.
동작 원리
수많은 문서 중 검색어에 대해 특정 문서를 빠르고 정확하게 찾기 위해선 아래 과정이 필요하다.
문서를 기반으로 인덱스를 만드는 부분, 만들어진 인덱스를 기반으로 검색을 하는 부분으로 나뉜다.
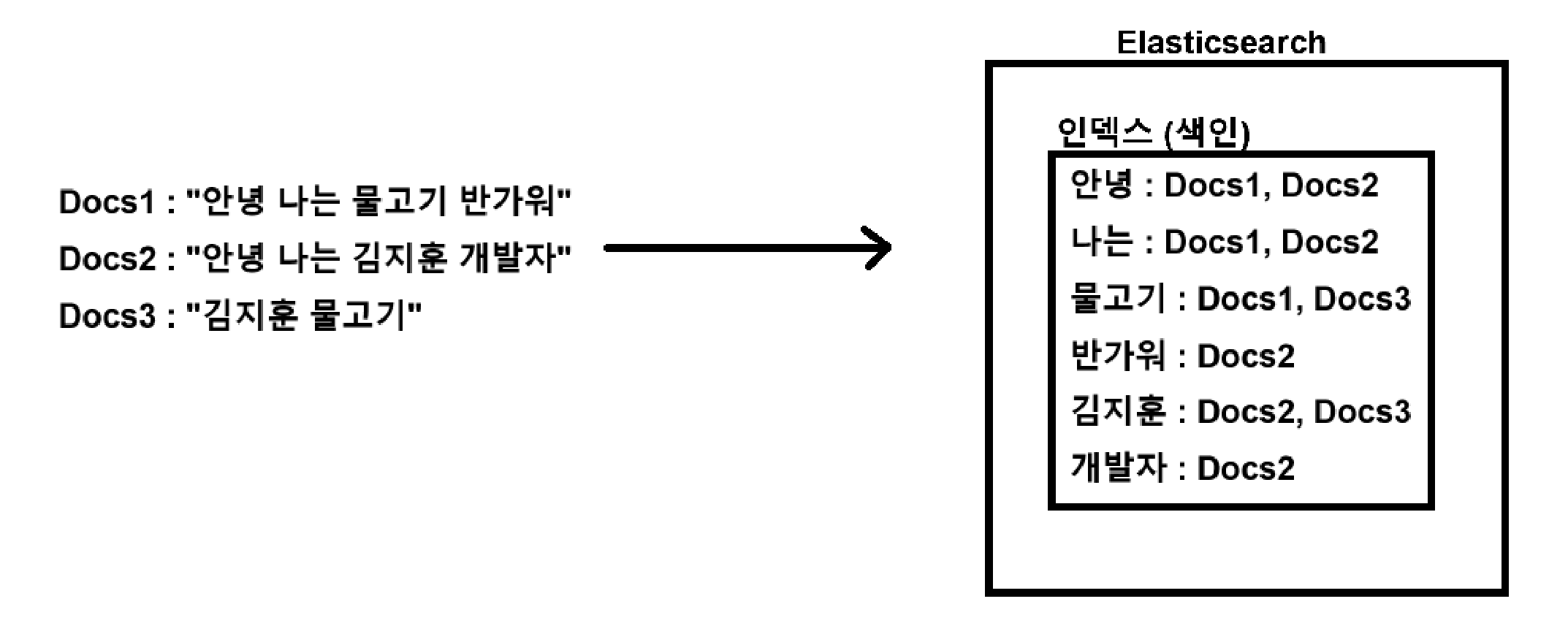
인덱스(색인)는
문서를 빠르게 찾도록 만든 테이블이다.
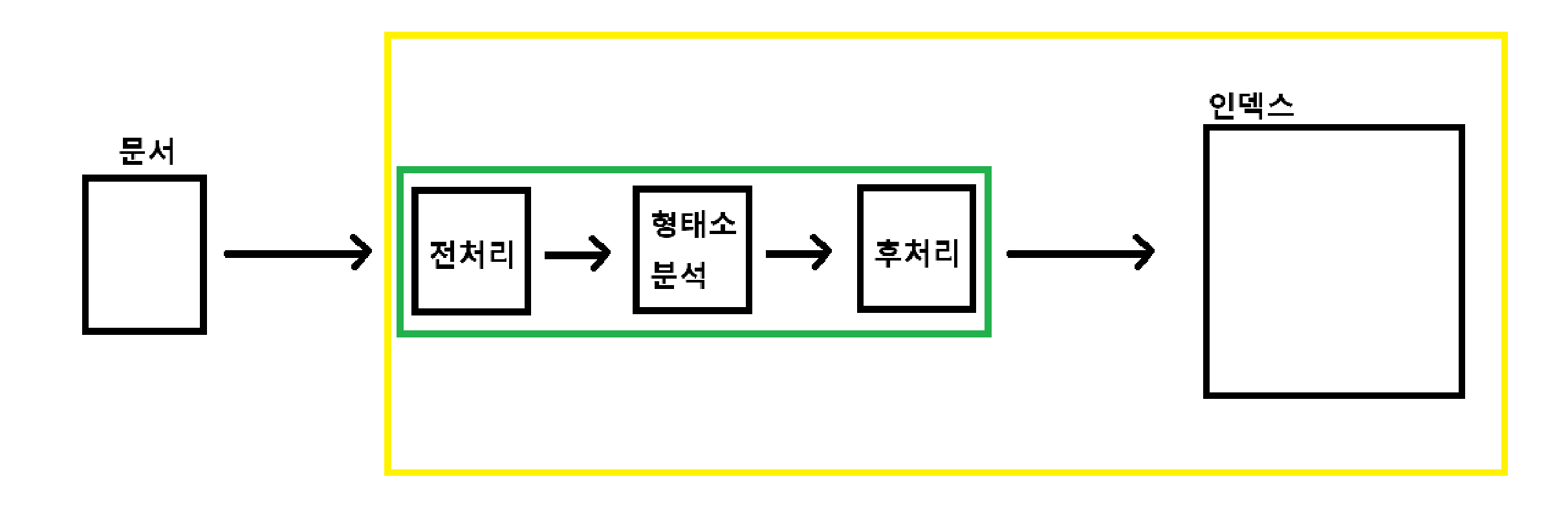
인덱스를 만드는 과정
가장 중요한 포인트로 문서를 전처리, 형태소 분석, 후처리 과정을 통해 의미 있는 형태소만 인덱스로 만들어 검색이 잘 될 수 있도록 해야한다.
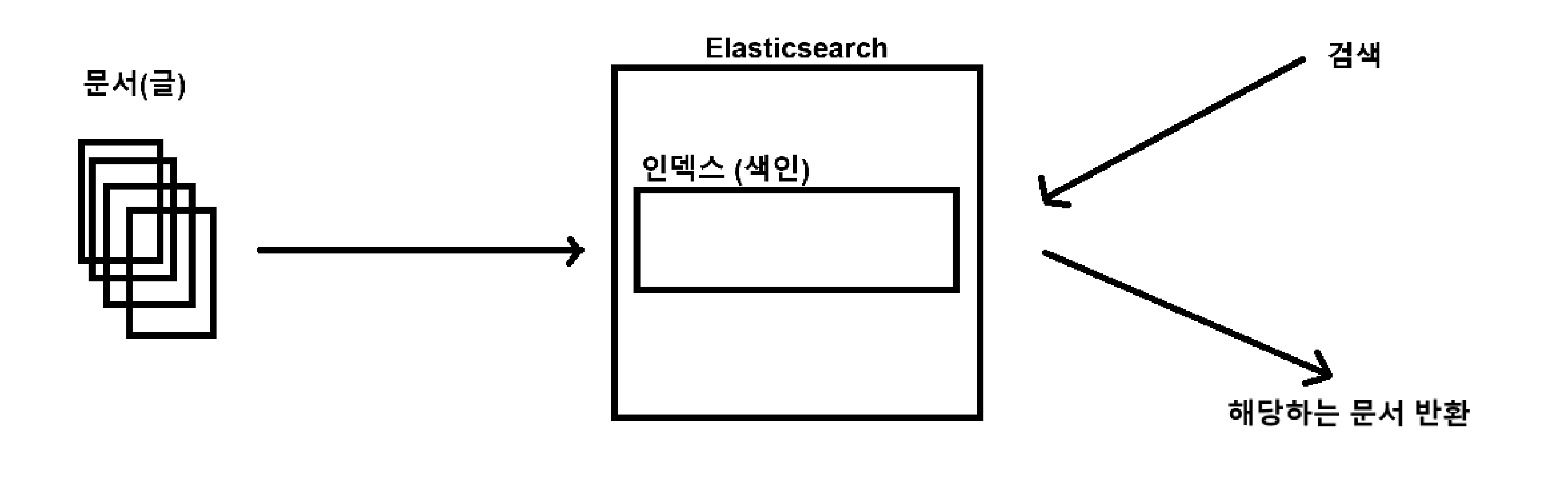
인덱스를 만든 결과에 따라 전혀 다른 검색 결과를 가짐.
-
후처리 단계에서 영어 대문자를 모두 소문자로 바꿈 : 대소문자 검색 결과가 같음
-
형태소 분석 단계에서 운동화가 "운 + 동화" 로 분리 됨 : 동화라고 검색했는데, 운동화 문서가 검색 됨
이 부분이 여타 DB와도 비교되는 부분입니다.
MongoDB, MySQL과 같은 데이터베이스도 FTS를 지원하지만, 위 과정을 강력하게 커스텀 할 수 없기 때문에 검색에는 꼭 Elasticsearch가 필요
fts: Full-Text Search (전문 검색)
데이터베이스나 문서에서 전체 텍스트를 검색하는 기술.
예를 들어, MySQL, Elasticsearch, PostgreSQL 같은 데서 지원하는 z기능
키워드만 검색하는 게 아니라 문장이나 문서 전체 내용 안에서 단어를 찾아주는 방식
설치
- mac 기준
- 도커
- 남는 메모리 2GB이상
도커 네트워크
최초 한번 실행
docker network create myela도커 실행
- 엘라스틱을 GUI -> kibana 실행해도 되지만 CLI를 선택함
docker run -d \
--name elasticsearch \
-p 9200:9200 \
-p 9300:9300 \
-e "discovery.type=single-node" \
docker.elastic.co/elasticsearch/elasticsearch:7.17.4kibana
docker run -d \
--name kibana \
--network myela \
-p 5601:5601 \
-e ELASTICSEARCH_HOSTS=http://elasticsearch1:9200 \
docker.elastic.co/kibana/kibana:7.17.4
-d : 도커 컨테이너 백그라운드 실행
--restart unless-stopped : 서버 실행시 도커 컨테이너 자동 실행 (수동 정지시 제외)
--name elasticsearch1 : 컨테이너 이름
-p 9200:9200 : 엘라스틱서치 CRUD용 API 포트
-p 9300:9300 : 엘라스틱서치 클러스터 통신용 포트
--network : 도커 네트워크 설정
-e “discovery.type=single-node” : 엘라스틱서치를 클러스터 없이 단일 노드로만 사용
-e “ES_JAVA_OPTS=-Xms2g -Xmx2g” : 자바 힙 최소 최대 메모리 설정
노드와 클러스터 내용 및 힙 메모리 설정 내용이 아래에 있슴돠!
생성한 컨테이너 확인
docker ps - a내부 네트워크 들어가기
docker exec -it elasticsearch1 bash만약 컨테이너가 Exited상태이면 실행(Running)으로 돌려야함
docker ps -a
docker start elasticsearch1
-
나가기
exit
기본 접속 설정
설치한 엘라스틱서치에 인덱스를 만들고 데이터를 CRUD하기 위해선 엘라스틱서치 포트 (9200)에 REST API 요청
하지만, 엘라스틱 포트는 기본적으로 비밀번호 설정이 있기 때문에 암호 재설정이 필요
ES 컨테이너 접속
sudo docker exec -it elasticsearch1 /bin/bash
비밀번호 재설정 명령
bin/elasticsearch-setup-passwords interactive
비밀번호 재설정이 기본 있었다는데 나는 없었다.
나가기 > 컨테이너 재시작
docker restart elasticsearch1접속
정상 출력
{
"name" : "f586d83c753d",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "g0fJZh0-QNeicln12vOcdQ",
"version" : {
"number" : "7.17.4",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "79878662c54c886ae89206c685d9f1051a9d6411",
"build_date" : "2022-05-18T18:04:20.964345128Z",
"build_snapshot" : false,
"lucene_version" : "8.11.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}키바나 : kibana
엘라스틱서치의 상태와 데이터 모니터링을 할 수 있는 키바나 대시보드를 설치하겠습니다.
docker run -d --restart unless-stopped --name kibana1 --network myela -p 5601:5601 docker.elastic.co/kibana/kibana:8.17.2kibana 컨테이너 접속
docker exec -it kibana1 /bin/bash접속
http://아이피:5601/비밀번호를 컨테이너에서 가져오고 접속해야하는데 나는 비밀번호 설정도 필요없었고 접속도 요청도 잘되었어서
만약 비밀번호 설정이 필요하다면 해당 글을 참조하기 바란다.
https://www.devyummi.com/page?id=67b9fcf18bf05dec22e1102a검색용 인덱스 생성
만들기 전
필요한 이유
게시판 서비스를 만들었다고 가정합니다. 그럼 우리 DB에는 사용자들이 작성한 글들이 쌓여갑니다.
이제 수많은 글 중 사용자가 원하는 글을 찾기 위해 검색 시스템을 구축해야 합니다. 어떻게 해야 할까요?
DB Like 쿼리
초심자의 기준에서 쉽게 떠올릴 수 있는 방법은 Like 쿼리입니다. (MySQL이나 MongoDB)
Like 쿼리를 통해 특정 단어가 포함되어 있는 문서를 찾는 방법은 아주 쉽게 구현을 할 수 있습니다.
하지만, 다음과 같은 문제가 있습니다.
- FTS 불가능 “%스프링 시큐리티%” 라고 검색하면 가능하지만, “%스프링 프레임워크%”라고 하면 안됨
- 대소문자 구분해서 검색해야 함
- 동의어 구분해서 검색해야 함 (스프링, Spring 다른 단어로 의식)
- Score 불가능
DB FTS : 인덱스 도입
위 LIKE 쿼리에서 가장 문제되는 부분이 FTS
LIKE 쿼리는 '%검색어%' 형태에서 검색어가 길어지면 원하는 결과를 얻지 못할 확률이 높아짐
따라서 그 문제를 해결하는 방법이 LIKE가 아닌 인덱스를 만들고 Full Text Search를 활용하는 방법
FTS는 아래와 같은 인덱스를 만들어 검색을 수행
(엘라스틱 서치도 기본 원리는 아래와 같이 동작)
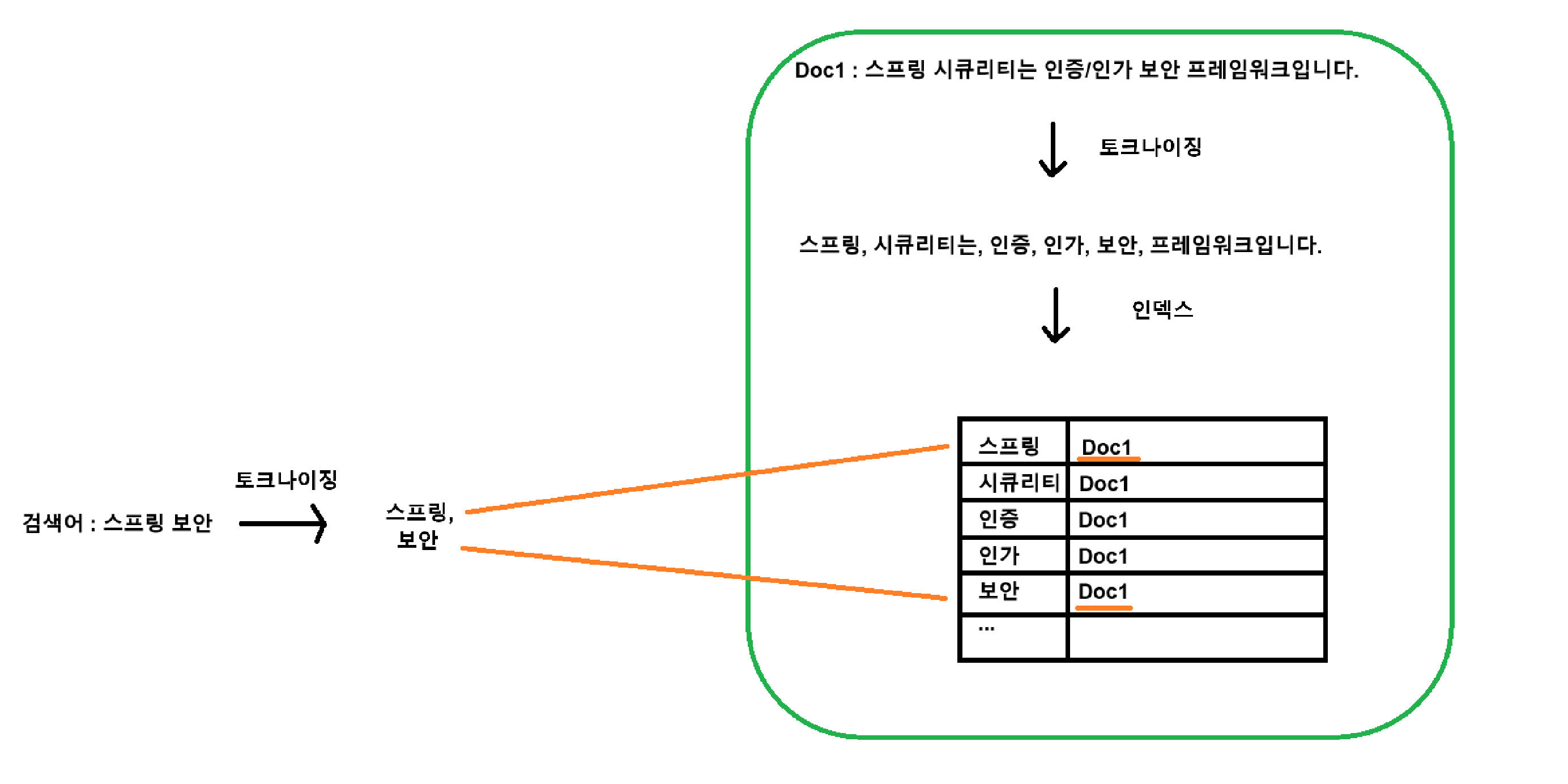
위와 같이 문장을 토큰화하여 인덱스를 만든다면, 검색어에 대해 빠르고 언급한 단어를 모두 찾아줄 수 있습니다.
FTS를 지원하는 DB들이 많습니다. (MongoDB, MySQL, …) 그럼 엘라스틱서치를 사용하지 않아도 될까?
가능은 하지만, 기업에서 엘라스틱서치를 도입하는 이유는 FTS를 위해 색인 테이블에 넣을 문장 토크나이징을 더욱 강력하게 지원하기 때문입니다. (커스텀 가능)
- 일반적인 DB에서 인덱스를 만든다면
스프링 시큐리티는 -> 스프링, 시큐리티는
("시큐리티는" 이라고 나옴 그럼 "시큐리티" 검색시 매칭 불가)
Spring Security -> Spring, Security
(소문자 검색시 검색 불가)
편두통 있습니다. -> 편두통, 있습니다.
("두통"이라고 검색한다면 검색 불가)- 엘라스틱서치에서 커스텀을 잘 한다면
스프링 시큐리티는 -> 스프링, 시큐리티
Spring Security -> spring, security
(검색어도 자동 소문자 처리)
편두통 있습니다. -> 편두통, 두통, 있다엘라스틱은 아래 테이블을 잘 만들기 위해 문자 분석 과정을 커스텀할 수 있다.
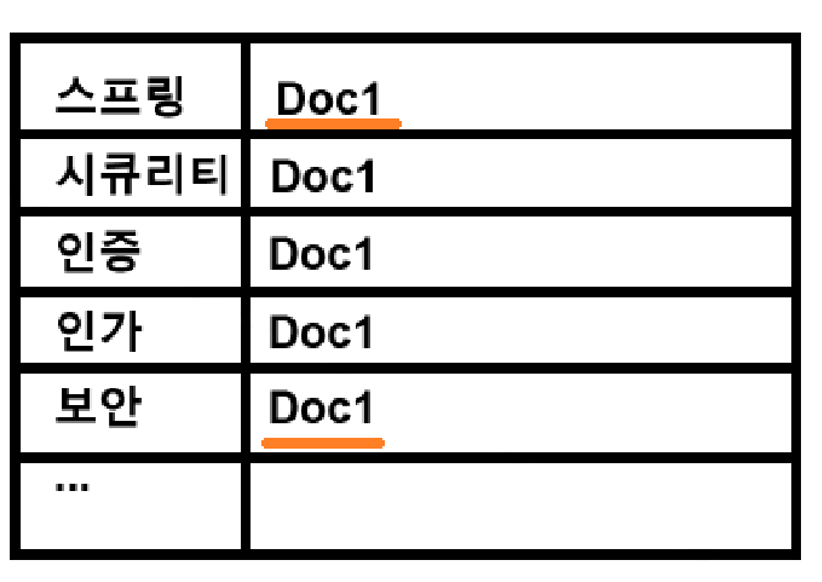
대략적인 색인을 만드는 과정
엘라스틱서치는 문서를 아래의 3과정을 통해 색인을 생성
“char_filter” → “ tokinizer” → “token_filter”
문서를 엘라스틱서치에 넣었을 때
기본적으로 문서를 저장 후, 문서에서 검색이 필요한 (사전에 셋팅한) 필드에 대해 아래 과정을 통해 색인을 생성
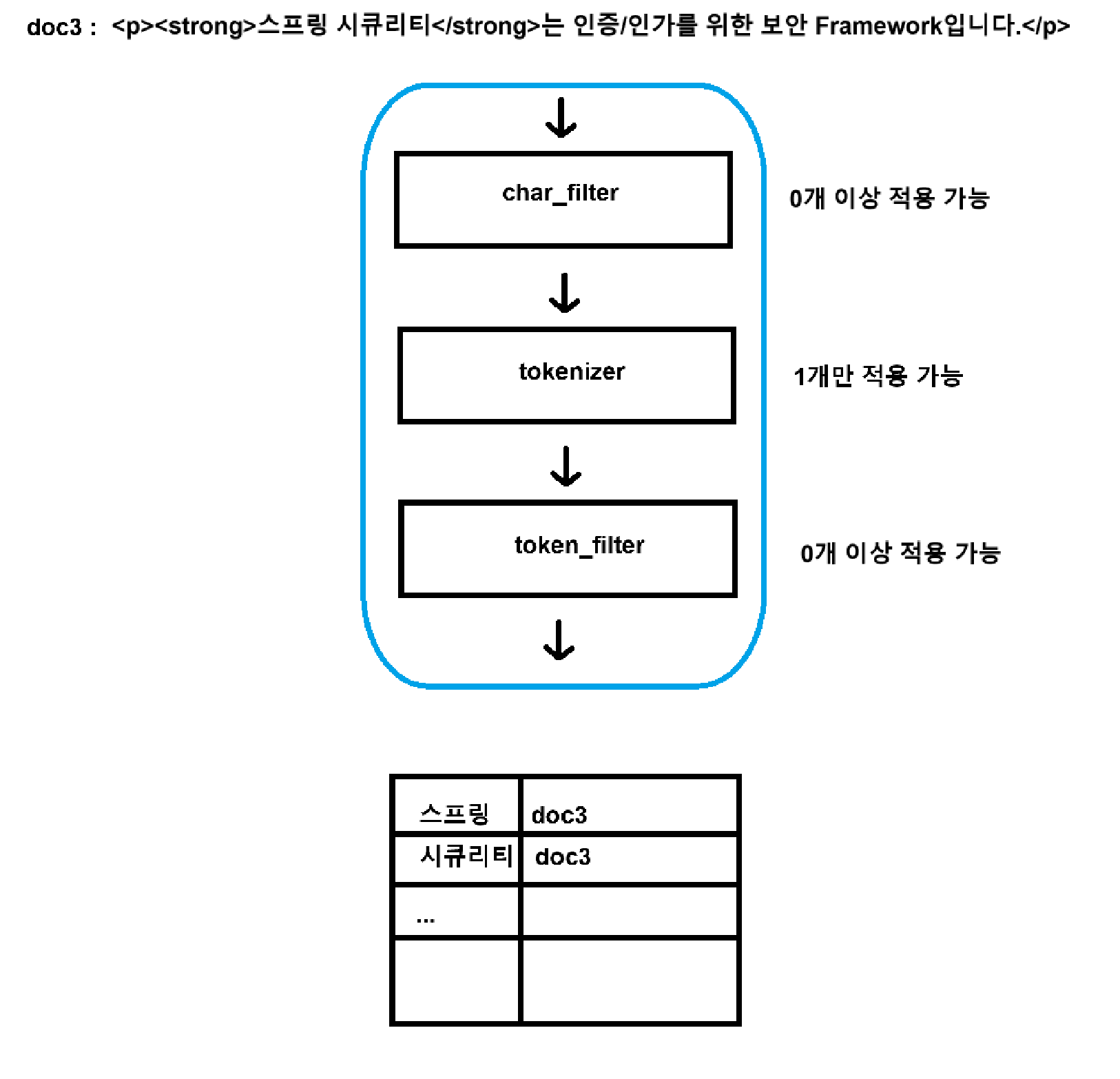
색인은 3단계를 거칩니다. 각 단계는 n개의 sub 필터로 구성
각 필터는 순서가 중요. 앞서 이뤄진 작업이 뒤에 영향을 미치기 때문에 적용 순서를 주의
1. char_filter
가장 먼저 적용되는 구획이며, 0개 이상을 적용할 수 있습니다.
대표적으로 3가지 필터가 있습니다.
HTML strip : HTML 제거
Mapping character : 특정 문자 대치
Pattern replace : 특정 패턴 대치 (정규식)
이 단계는 sanitize 단계로 불필요한 HTML을 제거하고, 외국 숫자(٢٥٠١٥)를 아리비아 숫자(1,2,3)로 바꾸는 단계입니다.
2. tokenizer
아주 중요한 단계로 1개의 토크나이저 필터만 적용됩니다.
1단계에서 정제된 문자열을 토큰화 시키는 단계입니다. (hi my name is jihun → hi, my, name, is, jihun), (안녕하세요. 개발자 유미입니다. → 안녕, 개발자, 유미)
검색을 위해 인덱스를 만드는데 가장 중요한 단계라고 볼 수 있습니다.
다양한 토크나이저가 있지만 자주 사용하는 2가지가 있습니다.
standard : 기본 토크나이저로 공백, 구두점, 문법으로 분리합니다. (한국어에 부적합)
nori_tokenizer : 한국어를 위한 토크나이저로 동일한 단어라도 형식, 어간, 어미에 따라 생김새가 다른 단어를 분리하기에 좋습니다.
엘라스틱서치에서 분석이 잘된다. ->
엘라스틱서치 (명사)
에서 (조사)
분석 (명사)
이 (조사)
잘 (부사)
된다 (동사)한국어를 다루면 거의 99%로 NORI 토크나이저를 사용
NORI 토크나이저도 완벽하지 않기 때문에 “사용자 사전”이라는 것을 추가하여 단어 분해를 커스텀할 수 있고, 분리한 단어 중 명사와 같은 POS 만 남길 수 있음
3. token_filter
토큰화가 완료된 토큰들을 색인 전 후처리하는 단계입니다.
필터의 종류가 아주 많지만 대표적인 필터는 아래와 같습니다.
lowercase : 영어 대문자를 모두 소문자 처리
stop : 토큰과정에서 “이, 가, 의”와 같이 stopword 제거 처리
synonym : 동의어 “에이브릴 → avril” 처리 (아주 중요한 부분)
stemmer : 동사, 명사 변형을 처리 (doing → do, foxes → fox) (한글 지원 불가)
엘라스틱 인덱스 만들때 json으로 적용가능
인덱스 생성
엘라스틱 서치는 모든 과정을 REST API로 제공
PUT : https://아이피:9200/인덱스이름위 API로 생성할 인덱스를 JSON body로 정의해서 보내면 됩니다.
인덱스 생성을 위한 JSON body 작성
body 정의 요소
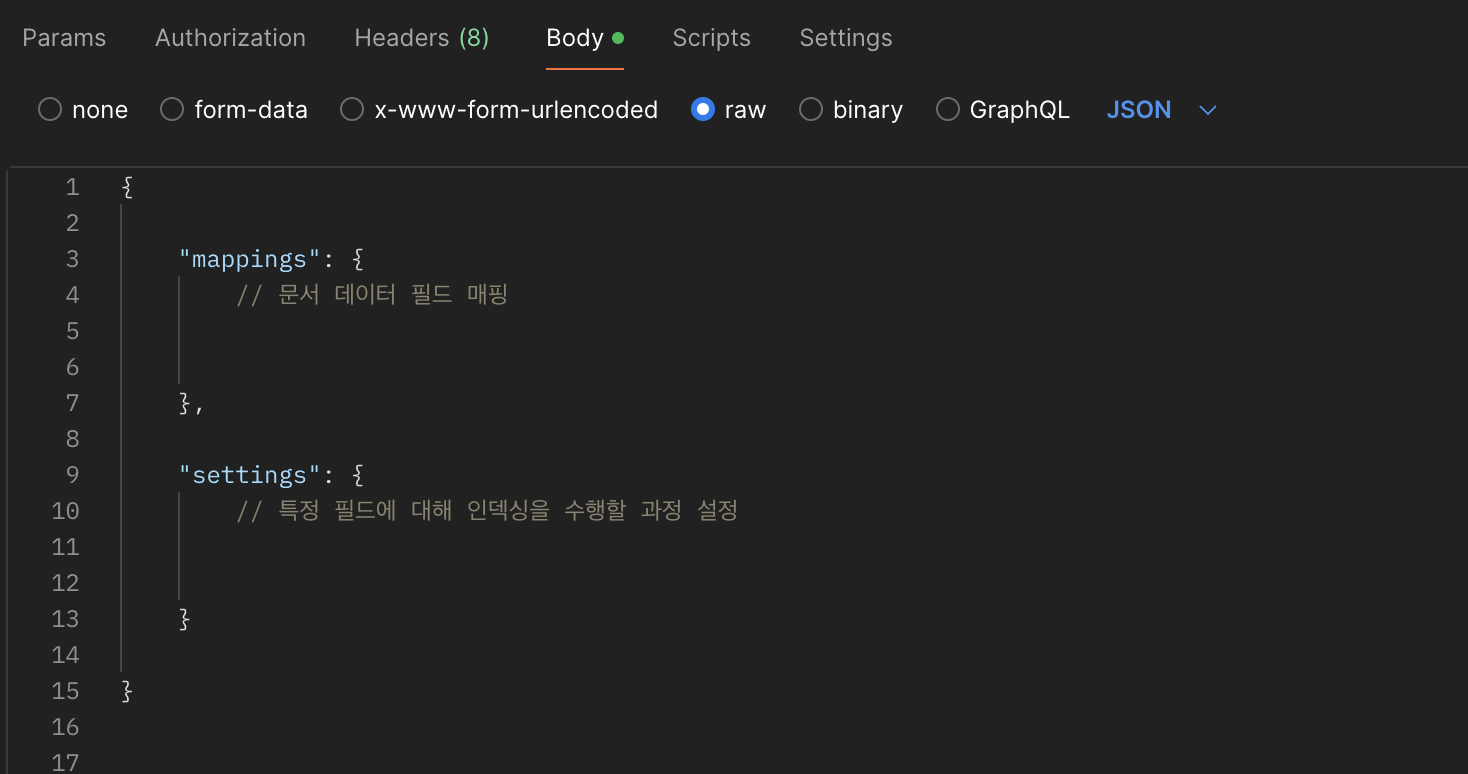
필드 매핑 (mappings) : 엘라스틱서치에 밀어 넣을 문서의 데이터 필드
인덱싱 설정 (settings) : 문서 필드에 대해 인덱싱을 위해 수행할 “char_filter → tokenizer → token_filter” 설정 (원하는 필드만 인덱싱 가능)
필드에 대한 타입 및 인덱스 생성 여부 설정
{
"mappings": {
"properties": {
"id": {
"type": "long",
"index": false
},
"title": {
"type": "text",
"analyzer": ""
},
"content": {
"type": "text",
"analyzer": ""
},
"created": {
"type": "date",
"index": false
}
}
}
}주로 사용하는 type은 text, keyword, nested, date, long이라고 보시면 될 거 같습니다.
analyzer는 인덱싱 설정 (settings) 후 연결할 수 있습니다.
인덱싱 설정 (settings)
특정 필드에 대해 인덱싱을 수행하는 “char_filter → tokenizer → token_filter” 과정을 정의 (분석기라고 불립니다.)
분석기에 등록할 필터들 등록
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"char_filter": [],
"tokenizer": "",
"filter": []
}
},
"char_filter": {
},
"tokenizer": {
},
"filter": {
}
}
}
}커스텀 필터 등록
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"char_filter": [],
"tokenizer": "standard_tokenizer",
"filter": ["lowercase_filter"]
}
},
"char_filter": {
},
"tokenizer": {
"standard_tokenizer": {
"type": "standard"
}
},
"filter": {
"lowercase_filter": {
"type": "lowercase"
}
}
}
}
}현재 프로젝트 넣었던 인덱스 요소
{
"mappings": {
"properties": {
"Vector": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "l2_norm"
},
"text": {
"type": "text",
"index": false
},
"href": {
"type": "text",
"index": false
}
}
}
}"similarity": "l2_norm"는 두 벡터간의 거리 계산중 유클리디안 거리 기준 유사도를 판단
분석기 테스트 : _analyze API
GET : https://아이피:9200/인덱스이름/_analyze {
"analyzer": "my_custom_analyzer",
"text": "테스트할 텍스트를 여기에 입력하세요. Hi"
}단순하게 띄어쓰기로 단위로만 토큰화를 진행하므로 따라서 "시큐리티는" 이라는 토큰 생성
한글 형태소 분석에 최적화되어 있는nori분석기설치하고 적용
엘라스틱서치 컨테이너 접속
docker exec -it elasticsearch1 /bin/bashnori 분석기 설치
엘라스틱 서치에서 한글 분석 플로그인인 nori를 공식적으로 지원
기본적으로 설치 되진 않아서 추가 설치 진행 필요
엘라스틱서치 컨테이너 접속
docker exec -it elasticsearch1 /bin/bashnori 형태소 분석기 설치
bin/elasticsearch-plugin install analysis-nori
nori tokenizer 적용
기존에 인덱스를 생성할 때 적용했던 standard 토크나이저 대신 nori 토크나이저를 적용
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"char_filter": [],
"tokenizer": "my_nori_tokenizer",
"filter": ["lowercase_filter"]
}
},
"char_filter": {
},
"tokenizer": {
"my_nori_tokenizer": {
"type": "nori_tokenizer",
"decompound_mode": "mixed",
"discard_punctuation": "true",
"lenient": true
}
},
"filter": {
"lowercase_filter": {
"type": "lowercase"
}
}
}
}
}decompound_mode : mixed 설정은 합성어 처리 방법으로 mixed로 설정하면 합성어를 분해하고 원본 단어도 유지합니다. (가곡역 → 가곡, 역, 가곡역)
discard_punctuation : true 설정은 구두점 제거 여부입니다. (반가워! → 반가워)
lenient : true 설정은 형태소 분석 과정에서 오류 발생시 skip 여부
적용했던 프로젝트에서는 dense한 벡터 검색 기반으로 진행하기 때문에 텍스트 분석아니라
-> Tokenizer/Filter 적용 불가
text에서의 sparse한 검색일때 적용하면 될 듯 하다
사용자 사전
nori 토크나이저를 사용하면 특정한 단어가 원하지 않게 분해되는 경우가 있다 이를 대비하여 사용자 사전을 등록해 특정 단어는 토크나이징이 되지 않도록 설정할 수 있습니다.
사용자 사전은 2가지 방식으로 설정할 수 있습니다.
- 직접 JSON에 명시
- txt 파일 경로 명시 (대게 이 방법 사용)
"tokenizer": {
"my_nori_tokenizer": {
"type": "nori_tokenizer",
"decompound_mode": "mixed",
"discard_punctuation": "true",
"user_dictionary": "userdict_ko.txt",
"lenient": true
}
}문제
userdict_ko.txt 라는 사용자 사전 파일을 도커 외부에서 마운트해야 하는데, 2강에서 엘라스틱서치 도커 컨테이너 생성시 마운트를 하지 않음
따라서 엘라스틱서치 컨테이너 새로 생성 요구됨.
컨테이너 외부 환경에 userdict_ko.txt 생성
mkdir elastic_dict
cd elastic_dict
touch userdict_ko.txt기존 컨테이너 제거
docker stop elasticsearch1
docker rm elasticsearch1
docker ps -aES 컨테이너 새로 생성 (elastic_dict 경로를 내부로 마운트 적용)
docker run -d --restart unless-stopped --name elasticsearch1 -v /home/xxxjjhhh/elastic_dict/:/usr/share/elasticsearch/config/dict/ -p 9200:9200 -p 9300:9300 --network myela -e "discovery.type=single-node" -e "ES_JAVA_OPTS=-Xms2g -Xmx2g" docker.elastic.co/elasticsearch/elasticsearch:8.17.2물론 비밀번호 설정도 다시해줘야하고, nori 형태소도 다시 설치해야함
# 비밀번호 재설치
docker exec -it elasticsearch1 /bin/bash
bin/elasticsearch-setup-passwords interactive
# nori 형태소 재설치
bin/elasticsearch-plugin install analysis-nori
docker restart elasticsearch1마운트확인
인덱스 생성 (nori 토크나이저 및 사용자 사전 등록)
{
"mappings": {
"properties": {
"id": {
"type": "long",
"index": false
},
"title": {
"type": "text",
"analyzer": "my_custom_analyzer"
},
"content": {
"type": "text",
"analyzer": "my_custom_analyzer"
},
"created": {
"type": "date",
"index": false
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"char_filter": [],
"tokenizer": "my_nori_tokenizer",
"filter": [
"lowercase_filter"
]
}
},
"char_filter": {},
"tokenizer": {
"my_nori_tokenizer": {
"type": "nori_tokenizer",
"decompound_mode": "mixed",
"discard_punctuation": "true",
"user_dictionary": "dict/userdict_ko.txt",
"lenient": true
}
},
"filter": {
"lowercase_filter": {
"type": "lowercase"
}
}
}
}
}
userdict_ko.txt 작성
nori_tokenizer가 하지 못하는 토큰화를 직접 커스텀하기 위해 작성
운동화 운동 화
신사역 신사 역
왓사용자 사전 업데이트시
사용자 사전을 업데이트 했다면 인덱스를 새로 만들거나 reindex를 진행해야 합니다.
대부분의 회사들이 일정 주기마다 전체 색인을 진행합니다.
- 사용자 사전이 없는 상태로 토큰화
운동화 → 운동, 화
신사역 → 신사, 역
왓 → 오, 앗- 사용자 사전 추가 후 토큰화
운동화 → 운동화, 운동, 화
신사역 → 신사역, 신사, 역
왓 → 왓동의어 토큰 필터
“char_filter → tokenizer → token_filter” 과정에서 token_filter는 분해한 토큰을 후처리
이 token_filter 단계에서 중요한 작업이 동의어 작업
동의어 필터
동의어 필터는 특정 단어를 의미가 비슷한 단어로 치환, 확장 할 수 있습니다.
치환 또는 확장을 해야 더 좋은 검색 결과를 가짐
책 = 서적 = book등록방법
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"char_filter": [],
"tokenizer": "my_nori_tokenizer",
"filter": [
"lowercase_filter",
"synonym_filter"
]
}
},
"char_filter": {},
"tokenizer": {
"my_nori_tokenizer": {
"type": "nori_tokenizer",
"decompound_mode": "mixed",
"discard_punctuation": "true",
"user_dictionary": "dict/userdict_ko.txt",
"lenient": true
}
},
"filter": {
"lowercase_filter": {
"type": "lowercase"
},
"synonym_filter": {
"type": "synonym",
"lenient": true
}
}
}
}동의어 사전
동의어 필터는 동의어 사전 등록을 통해 처리할 수 있다.
동의어 사전 등록 방식은 2가지로 설정하실 수 있습니다.
직접 JSON에 명시
txt 파일 경로 명시 (대게 이 방법 사용)
"synonym_filter": {
"type": "synonym",
"synonyms_path": "dict/synonym-set.txt",
"lenient": true
}도커 외부 환경에 sysnonym-set.txt 추가 (이전 사용자 사전 추가 경로)
cd elastic_dict
touch synonym-set.txt재시작하지 않아도 마운트되어 있어서 엘라스틱서치에서 참조 가능
동의어 사전 작성 방법
- 확장
ipod, i-pod, i pod
computer, pc, laptop특정 토큰에 대해 의미가 비슷한 토큰을 추가로 넣어주는 것
- 치환
personal computer => pc
sea biscuit, sea biscit => seabiscuit특정 토큰을 다른 토큰으로 변경
최종 인덱스
{
"mappings": {
"properties": {
"id": {
"type": "long",
"index": false
},
"title": {
"type": "text",
"analyzer": "my_custom_analyzer"
},
"content": {
"type": "text",
"analyzer": "my_custom_analyzer"
},
"created": {
"type": "date",
"index": false
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"char_filter": [],
"tokenizer": "my_nori_tokenizer",
"filter": [
"lowercase_filter",
"synonym_filter"
]
}
},
"char_filter": {},
"tokenizer": {
"my_nori_tokenizer": {
"type": "nori_tokenizer",
"decompound_mode": "mixed",
"discard_punctuation": "true",
"user_dictionary": "dict/userdict_ko.txt",
"lenient": true
}
},
"filter": {
"lowercase_filter": {
"type": "lowercase"
},
"synonym_filter": {
"type": "synonym",
"synonyms_path": "dict/synonym-set.txt",
"lenient": true
}
}
}
}
}한글 복합어 동의어 에러
한국어 복합어 문제
우리는 nori tokenizer 단계에서 복합어를 mixed(discard) 처리를 진행 이는 복합어를 분리
문제는 tokenizer에서 분리할 단어를 동의어 사전에서 명시를 하면 에러가 터짐
- synonym 사전
왓, what위와 같이 동의어 필터에서 “왓”을 설정할 경우 에러가 발생
“왓”은 → “오, 앗” 으로 분리 가능 이렇게 분리 가능한 복합어를 동의어 필터에서 명시하는 경우 에러가 발생
해결 방안
해결 방안은 nori tokenizer 사용자 사전에 “왓”을 등록해 분리가 안되도록 설정하고, 동의어 필터에서 “왓”을 사용X
엘라스틱서치 인덱스에 문서 CRUD
저번 시간들을 통해 인덱스를 만들었기 때문에 그 인덱스에 문서를 CRUD
인덱스 생성과 마찬가지로 엘라스틱서치는 모든 작업을 REST하게 API로 제공하고 있기 때문에 API 요청으로 인덱스에 문서를 CRUD 할 수 있음
문서 Create : 주로 사용 (색인)
POST : https://아이피:9200/인덱스명/_doc{
"id": "1",
"title": "문서1",
"content": "문서1 내용",
"created": "2025-03-07T00:00:00Z"
}bulk API
게시판 DB에 담겨 있는 문서를 주기적으로 엘라스틱서치 인덱스에 밀어 넣는 상황이 자주 발생합니다. (전체 색인)
이 경우 개별 API를 수천 번씩 실행할 경우 색인이 제대로 생기지 않는 문제가 발생합니다.
이 문제를 해결하기 위해 엘라스틱서치는 bulk API를 제공
- bulk API
POST : https://아이피:포트/_bulkbody 작성 방법
- 추가 : index (_id 값이 : 없다면 추가, 있다면 수정)
{ "index" : { "_index" : "my_index" } }
{ "id": "1", "title" : "제목1", "content": "내용1", "created": "2025-03-09T00:00:00Z" }삭제
{ "delete" : { "_index" : "my_index", "_id" : "" } }수정
{ "update" : { "_id" : "1", "_index" : "my_index" } }
{ "doc" : { "id": "1", "title" : "제목1", "content": "내용1", "created": "2025-03-09T00:00:00Z" } }NDJSON
body는 단순 JSON이 아니라 Newline Delimits JSON
따라서 bulk로 묶을 각 작업은 각각의 JSON으로 작성하고, 개행으로 구분
또, 마지막 라인은 개행이 추가
- 밑에 내용추가
- 헤더
Content-Type: application/x-ndjson기타
read
_bulk API는 Read를 지원하지는 않음 (_mget 사용)
최대값
bulk 최대 값은 HTTP 요청 한계 값인 100MB입니다. 다만 100MB를 다 사용하지 않고 1000 ~ 2000개씩 끊어서 요청
우리 프로젝트에선 벌크하게 임베딩파일을 업로드 하였다.
import json
import requests
import time
from typing import List, Dict, Any
def upload_embeddings_to_elasticsearch(
file_path: str,
index_name: str,
elasticsearch_url: str = "http://localhost:9200",
batch_size: int = 20,
sleep_time: float = 0.5
) -> None:
"""임베딩 데이터를 Elasticsearch에 업로드합니다."""
print(f"{file_path} 파일에서 데이터를 읽어오는 중...")
try:
# 기존 인덱스 삭제
try:
delete_response = requests.delete(f"{elasticsearch_url}/{index_name}")
print(f"기존 인덱스 삭제 응답: {delete_response.status_code}")
time.sleep(1) # 삭제 후 잠시 대기
except Exception as e:
print(f"인덱스 삭제 중 오류 (무시 가능): {str(e)}")
# 인덱스 매핑 생성
mapping = {
"mappings": {
"properties": {
"script": {"type": "text", "analyzer": "standard"},
"script_Vector": {
"type": "dense_vector",
"dims": 768, # jhgan/ko-sroberta-multitask 모델은 768차원 벡터 사용
"index": True,
"similarity": "cosine"
},
"href": {"type": "keyword"}
}
}
}
create_response = requests.put(
f"{elasticsearch_url}/{index_name}",
headers={"Content-Type": "application/json"},
json=mapping
)
print(f"인덱스 생성 응답: {create_response.status_code} - {create_response.text}")
time.sleep(1) # 생성 후 잠시 대기
# 임베딩 파일 로드
with open(file_path, "r", encoding="utf-8") as file:
data = json.load(file)
print(f"로드된 문서 수: {len(data)}")
# 데이터 형식 확인 및 변환
documents = []
for doc in data:
scripts = doc.get("script", [])
vectors = doc.get("script_Vector", [])
href = doc.get("links", "")
# 각 스크립트 항목별로 문서 생성
if len(scripts) != len(vectors):
print(f"경고: script({len(scripts)})와 script_Vector({len(vectors)})의 길이가 다릅니다.")
continue
# 모든 스크립트를 하나의 문서로 통합
documents.append({
"script": scripts,
"script_Vector": vectors[0] if vectors else [], # 첫 번째 벡터를 대표 벡터로 사용
"href": href
})
print(f"처리된 문서 수: {len(documents)}")
# 첫 번째 문서 구조 확인
if documents:
print("\n첫 번째 문서 구조:")
for key, value in documents[0].items():
if key == "script_Vector":
print(f"script_Vector: 벡터 (길이: {len(value)})")
elif key == "script":
print(f"script: 리스트 (항목 수: {len(value)})")
if value:
print(f" 첫 번째 항목: {value[0][:100]}")
else:
print(f"{key}: {value}")
# 배치 단위로 처리
batches = [documents[i:i + batch_size] for i in range(0, len(documents), batch_size)]
success_count = 0
error_count = 0
for batch_idx, batch in enumerate(batches):
print(f"\n배치 {batch_idx+1}/{len(batches)} 처리 중... ({len(batch)}개 문서)")
# 벌크 요청 데이터 준비
bulk_data = []
for doc in batch:
# script_Vector 필드 유효성 검사
vector = doc.get("script_Vector", [])
if not vector or not isinstance(vector, list) or len(vector) != 768:
print(f" 경고: 유효하지 않은 벡터 (길이: {len(vector) if isinstance(vector, list) else 'N/A'})")
continue
# 인덱스 요청 추가
bulk_data.append({"index": {"_index": index_name}})
bulk_data.append(doc)
if not bulk_data:
print(" 처리할 문서가 없습니다.")
continue
# 벌크 업로드 요청
try:
bulk_response = requests.post(
f"{elasticsearch_url}/_bulk",
headers={"Content-Type": "application/x-ndjson"},
data="\n".join(json.dumps(item) for item in bulk_data) + "\n"
)
if bulk_response.status_code in (200, 201):
response_data = bulk_response.json()
has_errors = response_data.get("errors", False)
if has_errors:
errors = [item for item in response_data["items"] if "error" in item.get("index", {})]
error_count += len(errors)
success_count += len(bulk_data) // 2 - len(errors)
if errors:
first_error = errors[0]["index"]["error"]
print(f" 오류 발생: {len(errors)}개 문서")
print(f" 첫 번째 오류: {first_error.get('type')}: {first_error.get('reason')}")
else:
success_count += len(bulk_data) // 2
print(f" 성공: {len(bulk_data) // 2}개 문서")
else:
error_count += len(bulk_data) // 2
print(f" 요청 실패: {bulk_response.status_code} - {bulk_response.text[:200]}")
except Exception as e:
error_count += len(bulk_data) // 2
print(f" 요청 오류: {str(e)}")
# 서버 부하 방지 대기
time.sleep(sleep_time)
print(f"\n업로드 완료: 성공 {success_count}개, 실패 {error_count}개")
# 인덱스 상태 확인
try:
stats_response = requests.get(f"{elasticsearch_url}/{index_name}/_stats")
if stats_response.status_code == 200:
stats_data = stats_response.json()
doc_count = stats_data["indices"][index_name]["total"]["docs"]["count"]
print(f"인덱스 문서 수: {doc_count}")
else:
print(f"인덱스 상태 확인 실패: {stats_response.status_code}")
except Exception as e:
print(f"인덱스 상태 확인 오류: {str(e)}")
except FileNotFoundError:
print(f"오류: {file_path} 파일을 찾을 수 없습니다.")
except json.JSONDecodeError:
print(f"오류: {file_path} 파일의 JSON 형식이 올바르지 않습니다.")
except Exception as e:
print(f"오류 발생: {str(e)}")
if __name__ == "__main__":
# 설정
file_path = "rag/mimmim_embeding.json" # 임베딩 데이터 파일
index_name = "loveledger_dense" # Elasticsearch 인덱스 이름
elasticsearch_url = "http://localhost:9200" # Elasticsearch URL
# 업로드 실행
upload_embeddings_to_elasticsearch(
file_path=file_path,
index_name=index_name,
elasticsearch_url=elasticsearch_url,
batch_size=10, # 한 번에 처리할 문서 수 (작게 설정)
sleep_time=1.0 # 배치 간 대기 시간 (충분히 길게)
)전체 색인
아키텍처
보통 엘라스틱서치가 구성되는 아키텍처
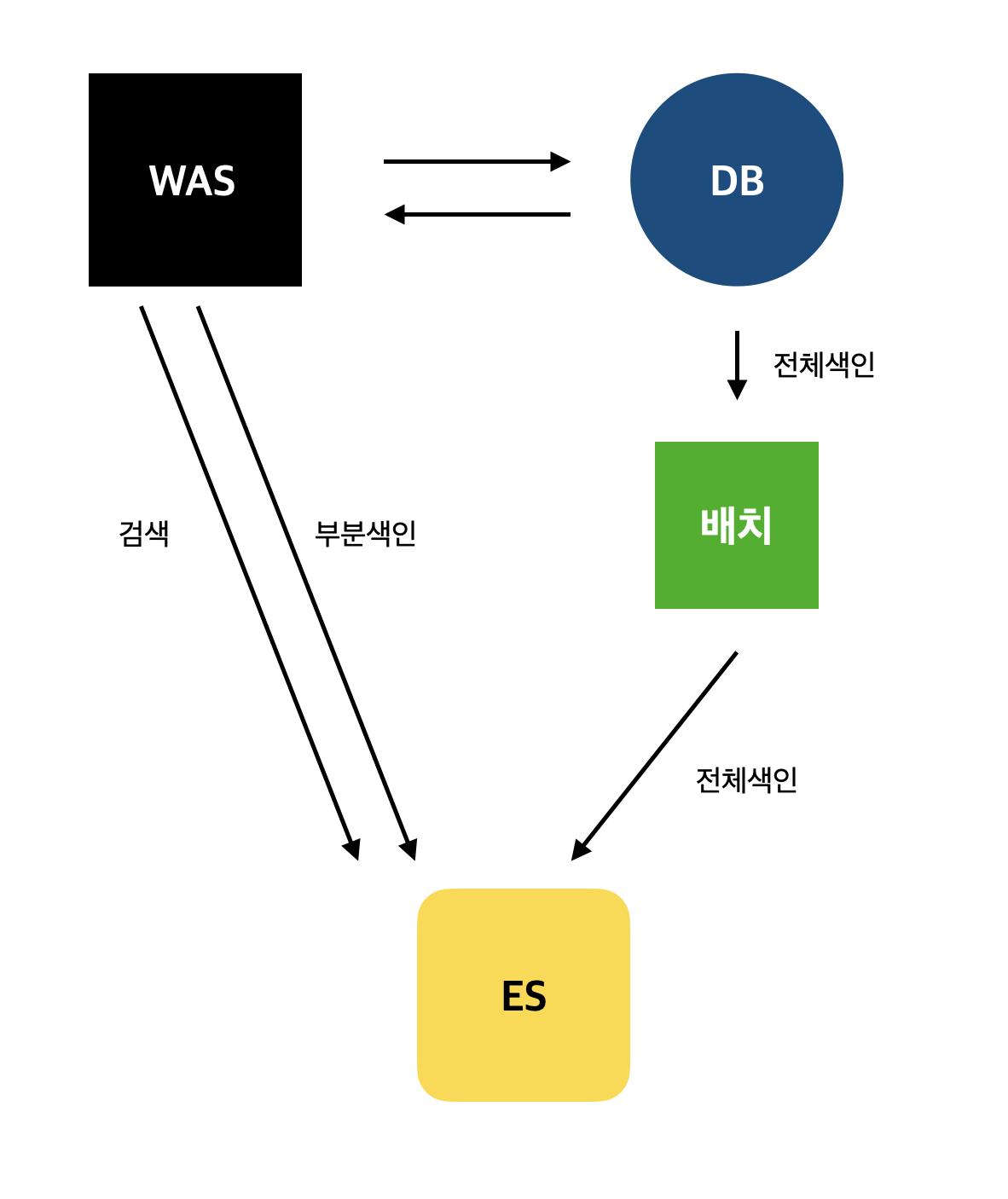
WAS : 스프링 부트와 같은 백엔드 웹 어플리케이션
DB : 게시판 글 데이터를 담을 MySQL과 같은 DB
ES : 엘라스틱서치
전체색인 : 주기적으로 ES에 새로운 색인을 만들고 DB 모든 데이터를 밀어 넣음
부분색인 : WAS에서 CRUD로 변경되는 데이터 실시간으로 ES 색인에 반영
배치 : 전체 색인을 위한 배치 작업
전체 색인의 필요
- 사용자/동의어 사전 변경
- 색인 누락
reindex?
엘라스틱서치는 reindex라는 API를 제공
reindex는 기존에 인덱스에 밀어 넣었던 문서를 다시 재색인 할 수 있습니다.
다만, 아래 이슈가 존재합니다.
- 검색과 함께 사용하면 느림
- 이미 DB로 부터 누락된 색인은 감지 불가 (기존 색인을 재색인 하는 개념)
그래서 reindex는 추천 X
따라서 우리는 아래 전체/부분 색인 메커니즘 사용
전체/부분 색인 메커니즘
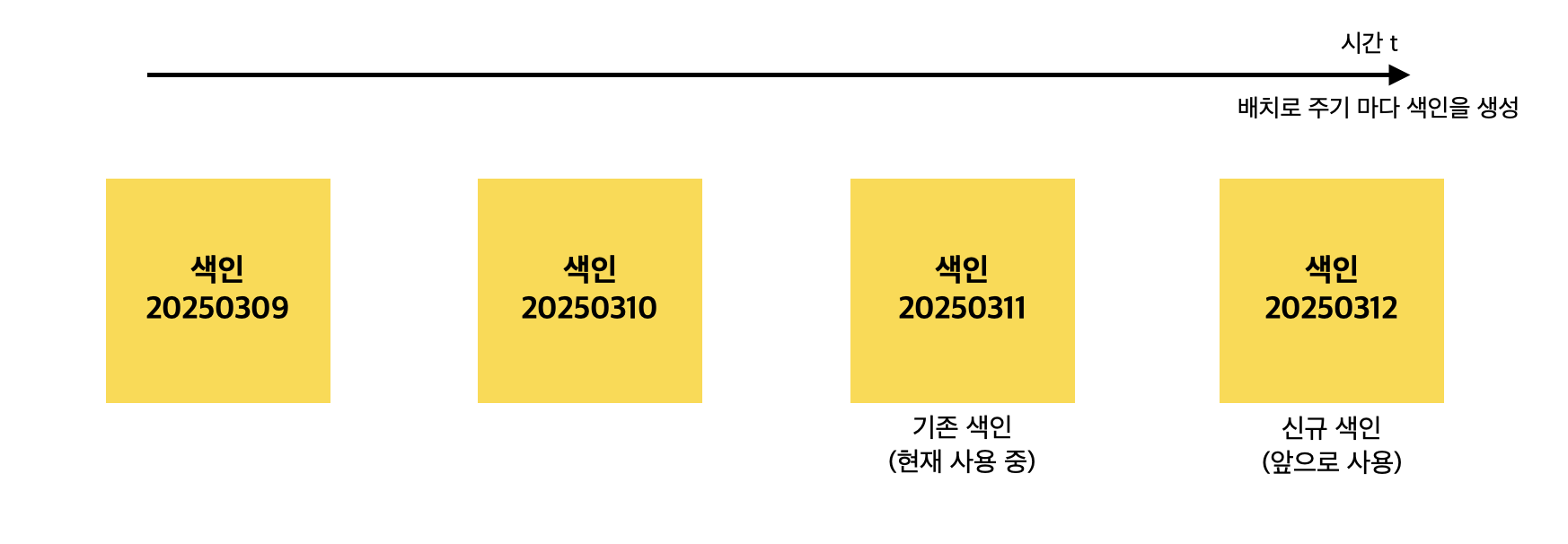
주기별로 색인 재생성 (전체 색인용)
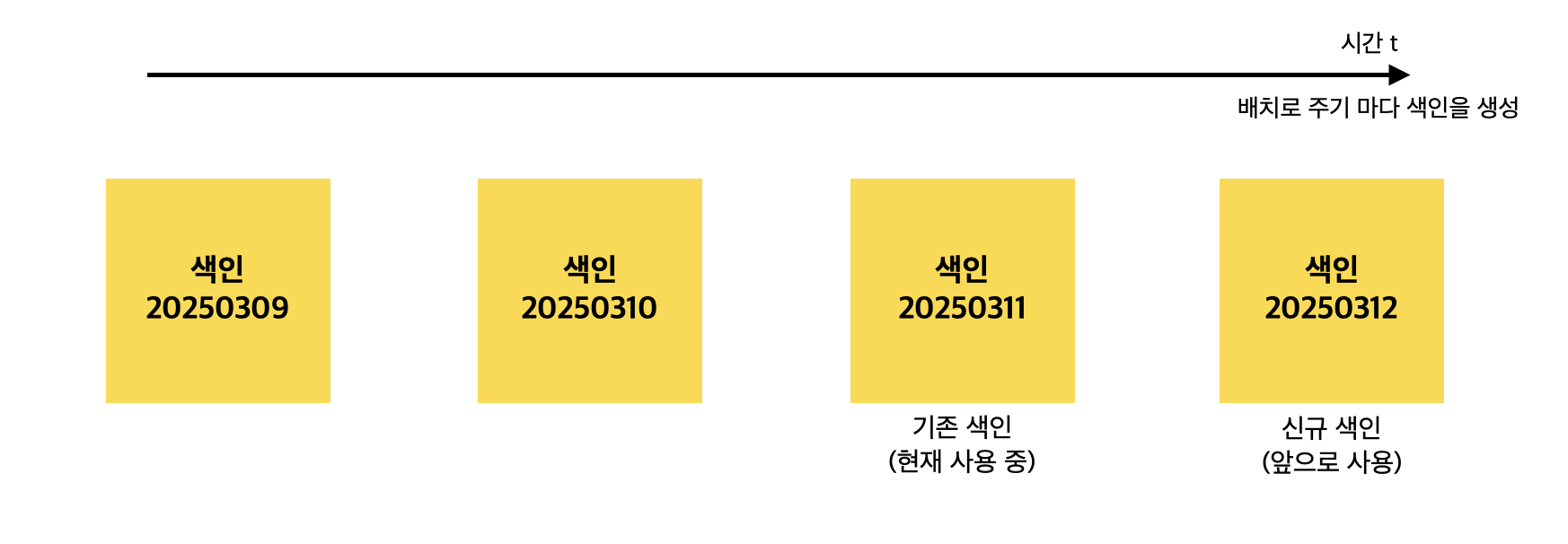
전체 색인을 위해 일정 주기 마다 색인을 재생성
색인 작명은 대게 색인명 뒤에 날짜를 붙임
-
신규 색인은
앞으로 사용할 신규 색인은 DB로 부터 배치 처리를 통해 bulk로 밀어넣음
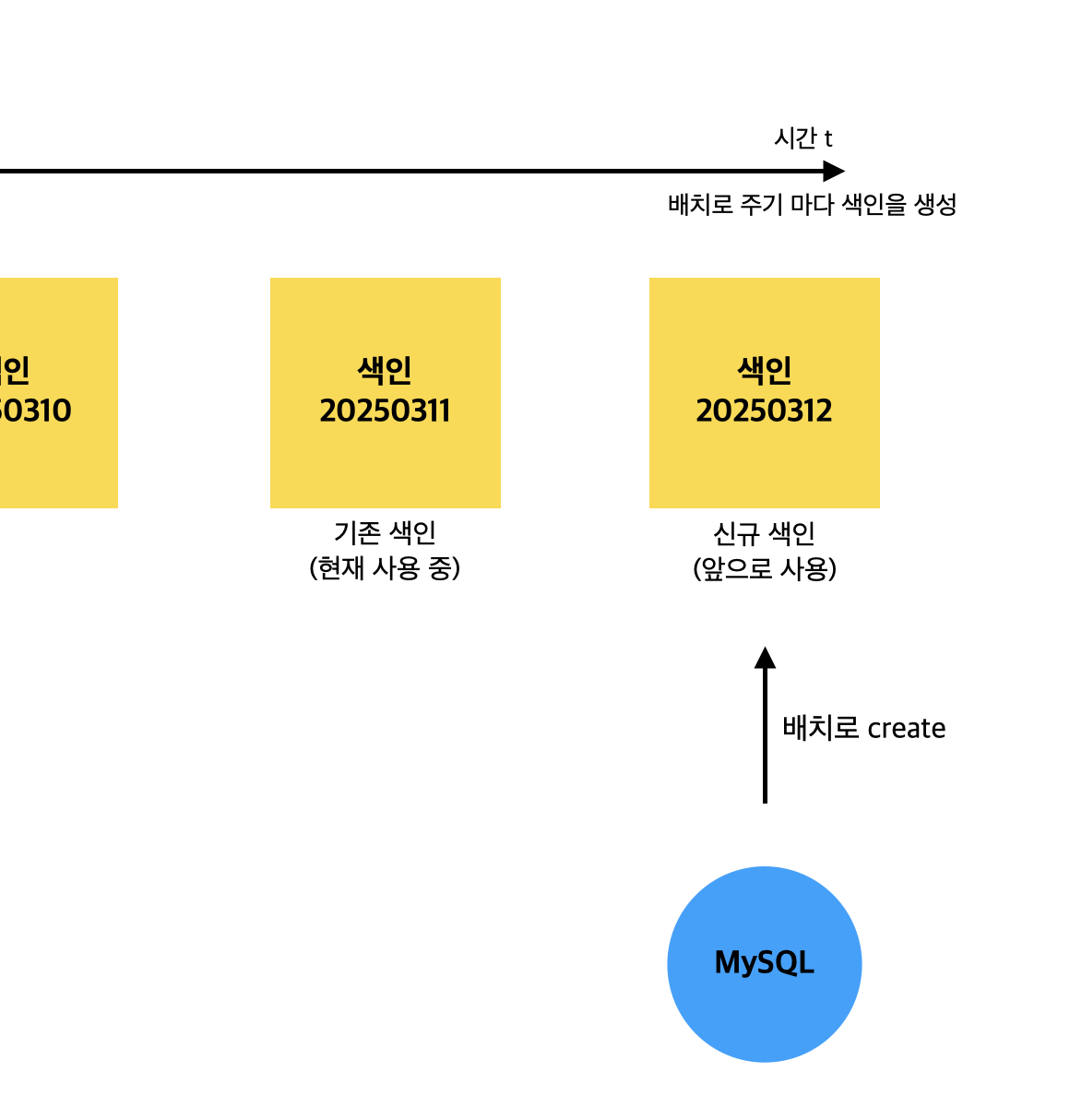
-
고민점 : DB로 부터 밀어 넣는 시간이 오래 걸림
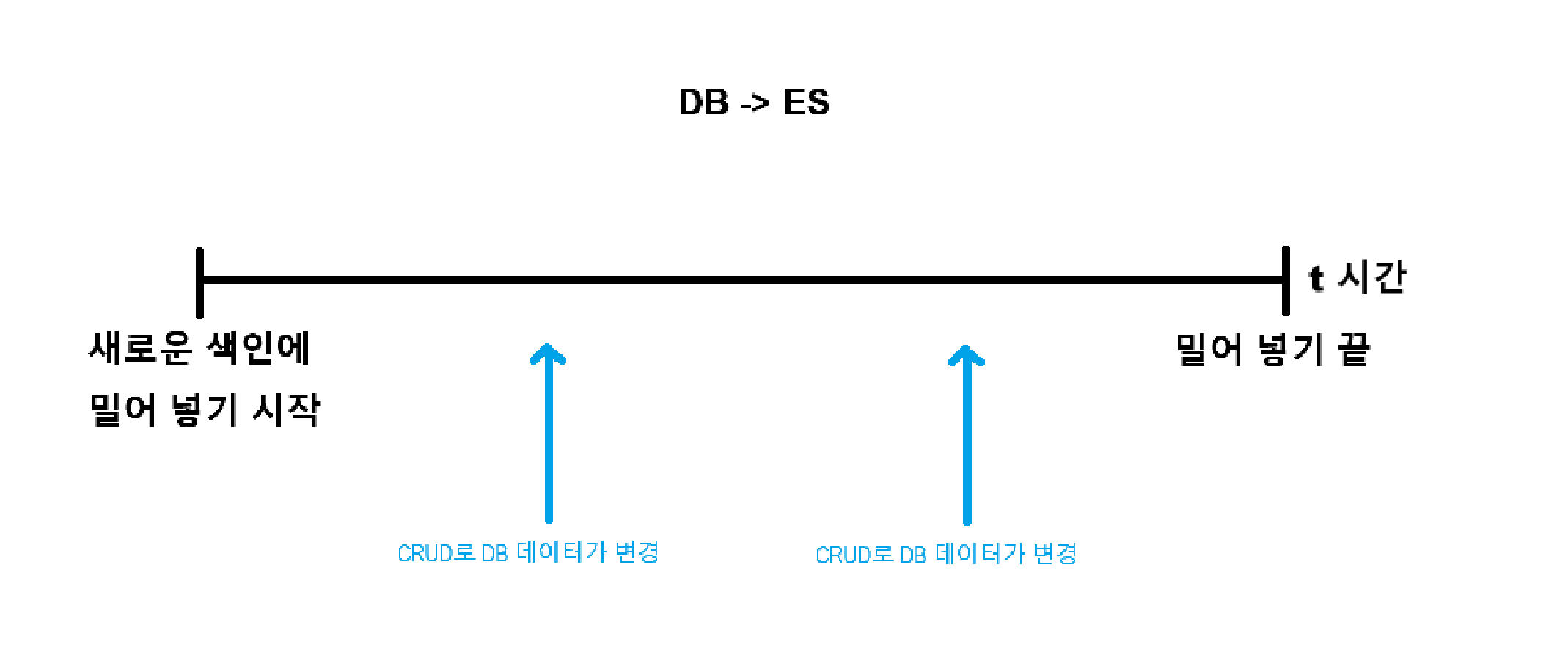
-
색인을 만드는 동안 사용자가 서비스를 사용하여 DB에 CRUD가 발생하면?
-
색인에 대한 CUD와 검색은 색인을 옮기는 동안 어떤 인덱스를 바라봐야 할 지?
sol. 전체 색인 범위는
"전체 색인을 시작하는 시점"에 DB가 가진 데이터만 전체 색인을 하도록 설정 전체 색인 시점 DB 마지막 id 값 이후로 새로 들어온 데이터는 전체 색인 배치에서 제외 함.
sol. 전체 색인 과정에서 발생하는 Create는?
전체 색인 과정을 수행하는 도중 신규로 DB에 추가되는 데이터는 WAS 단에서 DB와 ES에 모두에 넣어줌
(전체 색인 시작시, 기존 데이터의 마지막 id 값 까지만 진행하도록 설계하여 중복을 방지)
sol. 전체 색인 과정에서 발생하는 Delete, Update는?
Update도 DB와 ES에 모두 진행하면 됩니다.
- case1. 이미 update할 데이터를 색인으로 만들었을 경우
- case2. update할 데이터를 아직 색인으로 안 만들었을 경우
- case3. 이미 delete할 데이터를 색인으로 만들었을 경우
- case4. delete할 데이터를 아직 색인으로 안 만들었을 경우
위 케이스 모두 안전하게 진행 가능합니다.
부분 색인?
전체 색인이 진행되지 않을때, 부분 색인은 WAS에서 DB와 ES에 모두 적용시키면 됩니다.
alias
매 전체 색인시 색인명이 변경되면, WAS에서 색인명을 변경해야 할까요?
다행이 alias라는게 존재 alias는 별칭으로 대표가 되는 이름을 정해두고, 내부적으로 redirect를 진행 가능
POST : https://아이피:9200/_aliasesalias 설정
{
"actions": [
{
"add": {
"index": "my-index-날짜",
"alias": "my-index"
}
}
]
}검색과 CUD alias 분리
전체 색인을 진행하는 동안 CUD는 새로운 색인, 검색은 기존 색인에 대해 진행해
이 문제는 alias를 통해 해결 가능
- 검색용 alias
- CUD용 alias
workflow
- 검색용 alias, CUD용 alias 모두 기존 색인을 가리킴
- 신규 색인 생성
- CUD용 alias는 신규 색인을 가리킴
- 신규 색인 완료
- 검색용 alias는 추후 신규 색인을 가리킴
검색 API
검색을 위해 인덱스를 만들고 문서를 밀어 넣음 이제 그 결과에 검색을 진행
검색 또한 API로 진행할 수 있으며, 다양한 기능을 제공 (엄청나게 많은 기능이 있지만, 우선 간단하게 알아보겠습니다.)
POST : https://아이피:9200/인덱스/_search
POST : https://아이피:9200/_search검색 종류
match 쿼리
형태소 분석된 인덱스 필드에 대해, 검색어도 형태소 분석을 진행 (BM25 기반)
term 쿼리
형태소 분석된 인덱스 필드에 대해, 검색어는 입력 그대로를 사용
문서 인덱싱 : (제목 왓더헬 → 제목, 왓, 더, 헬)
검색시 : “제목” 이라고 검색하면 찾아지지만, “제목 왓” 이라고 검색하면 검색 안됨
bool 쿼리
여러 쿼리를 조합하고, 논리 연산 추가를 사용하여 검색합니다. must, must_not, should, filter 4개의 Occur를 제공하고 각 Occur에 대해 여러개의 match와 term 쿼리를 작성할 수 있습니다.
must : 속한 match, term이 AND와 같이 모두 있어야 함
should : 속한 match, term이 OR과 같이 하나 이상 있어야 함
filter : 속한 match, term이 AND로 모두 있어야 하지만, score는 계산하지 않음
must_not : 속한 match, term이 있다면 검색되지 않음
사용예시
{
"query": {
"match": {
"인덱스필드명": "제목 왓"
}
}
}bool 쿼리
{
"query": {
"bool": {
"must": [
{
"match": {
"인덱스필드명": "제목 왓"
}
},
{
"match": {
"인덱스필드명": "제목 왓"
}
}
],
"filter": [],
"should": [],
"must_not": []
}
}
}사용하고 싶은 연산자 (must, filter, should, must_not)을 명시하고, 그 리스트 내부에 match, term 쿼리를 작성
검색 옵션
엘라스틱서치 검색 API는 검색을 위한 “query” 이외에도 다양한 옵션을 제공
{
"query": {
"match": {
"인덱스필드명": "제목 왓"
}
}
}페이지 네이션
{
"from": 10,
"size": 10
}BM25 min score
{
"min_score": 1.0
}필드에 대한 가중치 부여
bool 쿼리로 여러 필드에 대해 검색시, 특정 필드에 대한 가중치를 부여
{
"query": {
"bool": {
"must": [
{
"match": {
"title": {
"query": "고양이",
"boost": 10
}
}
},
{
"match": {
"content": "고양이"
}
}
],
"filter": [],
"should": [],
"must_not": []
}
}
}nori stoptags
nori tokenizer에서 분해한 토큰
nori tokenizer는 텍스트를 형태소 단위로 분리.
이 토큰들은 품사로 분류 할 수 있습니다. (어미, 어간, 감탄사, 조사, etc …)
문제는 의미가 없는 품사라도 인덱스 테이블에 들어감
(엘라스틱서치는 → 는, 초코파이는 → 는 : 과 같이 조사인 “는”은 문장에 대한 큰 의미를 가지지 않는 토큰이지만 인덱스에 들어감)
따라서 품사 중 필요 없는 것은 인덱스에 포함되지 않도록 제외해야함
작업은 “char_filter → tokenizer → token_filter” 중 token_filter에서 처리할 수 있습니다.
nori_part_of_speech 필터
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"char_filter": [],
"tokenizer": "my_nori_tokenizer",
"filter": [
"my_pos_filter",
"lowercase_filter",
"synonym_filter"
]
}
},
"char_filter": {},
"tokenizer": {
"my_nori_tokenizer": {
"type": "nori_tokenizer",
"decompound_mode": "mixed",
"discard_punctuation": "true",
"user_dictionary": "dict/userdict_ko.txt",
"lenient": true
}
},
"filter": {
"my_pos_filter": {
"type": "nori_part_of_speech",
"stoptags": [
]
},
"lowercase_filter": {
"type": "lowercase"
},
"synonym_filter": {
"type": "synonym",
"synonyms_path": "dict/synonym-set.txt",
"lenient": false
}
}
}
}
}여기서 stoptags에 걸러낼 품사를 명시
인덱스
{
"mappings": {
"properties": {
"id": {
"type": "long",
"index": false
},
"title": {
"type": "text",
"analyzer": "my_custom_analyzer"
},
"content": {
"type": "text",
"analyzer": "my_custom_analyzer"
},
"created": {
"type": "date",
"index": false
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"char_filter": [],
"tokenizer": "my_nori_tokenizer",
"filter": [
"my_pos_filter",
"lowercase_filter",
"synonym_filter"
]
}
},
"char_filter": {},
"tokenizer": {
"my_nori_tokenizer": {
"type": "nori_tokenizer",
"decompound_mode": "mixed",
"discard_punctuation": "true",
"user_dictionary": "dict/userdict_ko.txt",
"lenient": true
}
},
"filter": {
"my_pos_filter": {
"type": "nori_part_of_speech",
"stoptags": [
"J"
]
},
"lowercase_filter": {
"type": "lowercase"
},
"synonym_filter": {
"type": "synonym",
"synonyms_path": "dict/synonym-set.txt",
"lenient": false
}
}
}
}
}nested 필드
엘라스틱서치의 nested 필드는 객체를 담을 수 있도록 만들어 짐
- 하나의 데이터에 대해 부가 정보가 리스트로 의존될 경우
{
"music_name": "Something Just Like This"
"artist": "여러명인데?(단순하게 가수명 뿐만 아니라 추가 정보 까지 가진다면?)"
}SQL JOIN 구조를 기반으로 ES 인덱스를 만들 때 발생하는 경우가 많습니다. (음악 서비스, 음악에 대한 뮤지션의 조인)
nested 필드 mapping
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "my_custom_analyzer"
},
"musicians": {
"type": "nested",
"properties": {
"name": {
"type": "text",
"analyzer": "my_custom_analyzer"
},
"agency": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
}
}
}
}데이터 넣기
POST : https://아이피:9200/인덱스/_doc{
"title": "Something Just Like This",
"musicians": [
{
"name": "The Chainsomkers",
"agency": "Disruptor Records00000 "
},
{
"name": "Coldplay",
"agency": "워너 뮤직 그룹"
}
]
}- nested 사용시 주의점
색인 및 재색인 비용 증가 및 속도 문제
mapping 필드 설계 및 검색 복잡성 증가
UX적 효율 API (fuzzy, suggest)
엘라스틱서치 검색 API 기반으로 검색을 진행하는 플랫폼이 존재한다고 가정
이때 End 유저들은 항상 올바른 검색어를 입력하는 케이스는 100% 일 수 없다.
(즉, 오타를 적거나 정확한 검색어는 모르지만 검색하는 케이스가 존재하게 됩니다.)
우리는 이런 상황을 대비해 조금 더 나은 검색 결과를 가지기 위한 아래 도구들을 알아보자.
fuzzy : 오타 허용
suggest : 자동 완성
fuzzy Query
fuzzy Query는 검색어 오타에 대해 흡사한 문서를 찾을 수 있습니다.
-
필드에 대한 문서 저장 값
문서
-
오타 검색어
문사
fuzzy 0 : match에 대해 한 글자라도 다르면 못 찾음
fuzzy 1 : match에 대해 한 글자가 달라도 찾음
fuzzy N : match에 대해 N 글자가 달라도 찾음
즉, 아래는 “문서” 라는 단어에 대해 한 획이 다른 케이스
→ 문아, 문사, 분사, 아서, 등등
- 검색 API와 함께 사용 (bool 예시)
{
"query": {
"bool": {
"must": [
{
"match": {
"title": {
"query": "문사",
"fuzziness": 0
}
}
}
],
"filter": [],
"should": [],
"must_not": []
}
}
}- 레벤슈타인 편집 거리
위의 오타 허용 방법은 레벤슈타인 편집 거리 매커니즘 기반으로 측정
레벤슈타인 편집 거리는 두 단어 사이에서 어느 정도 거리(글자) 만큼 다른지를 측정
-
ES에서 특징
문장에서 단어 단위로 레벤슈타인 편집 거리를 적용하며, 위치 변경에 대해선 측정하지 않음 -
단점
연산 과정이 필요하기 때문에 거리(n) 값이 커질수록 자원 소모가 큽니다.
자동완성
자동 완성을 위한 Suggest API 존재하지만, 보통은 하나의 N-gram용 인덱스를 더 생성하여 사용자의 검색어 로그를 인덱싱 함
- 인덱스 필드
- 검색어
- 카운트 ( 검색어 검색 횟수 )
- 구현방법
- 검색창의 사용자 검색 로그를 수집
- 수집한 검색 로그와 카운트 수를 ES 인덱스에 넣음
- ES 인덱스에서 검색어는 n - gram 기반으로 슬라이싱해서 넣음
- 사용자의 입력 검색어에 대해 ES에서 매번 찾은 후 카운트 높은 순 정렬
- 스케쥴
주기적으로 검색어 로그와 카운트 수를 ES인덱스에 업데이트 하는 전체 색인 작업이 요구 됨
추가 궁금사항
도커 네트워크 :
컨테이너끼리 같은 네트워크에 있어야 통신이 가능 (bridge, custom network 등)
FastAPI + Elasticsearch 같이 연결하려는 경우,둘 다 같은 도커 네트워크 안에 있지 않으면 "연결 안 됨" 에러
- 맥에서는 같은 네트워크로 자동 연결
- 리눅스환경에서는 설정 필요
엘라스틱 설치시 포트 번호가 다른이유 :
✅ 9200: HTTP 통신용 포트
우리가 브라우저나 Postman, FastAPI, curl 같은 걸로 접근할 때 쓰는 포트
Elasticsearch의 REST API가 이 포트로 열림
curl http://localhost:9200/✅ 9300: 노드 간 통신용 포트 (Transport Layer)
Elasticsearch 클러스터가 여러 개의 노드로 구성될 때, 노드들끼리 통신하는 포트
단일 노드로만 쓸 경우엔 거의 필요 없지만, 클러스터를 구성할 때 필수
예: discovery, replica shard 이동, cluster 상태 전달 등 내부 기능에 사용
🔧 왜 단일 노드인데도 9300 포트를 열까?
습관적으로 열어두는 경우도 있고,
나중에 클러스터 구성을 염두에 두고 미리 여는 경우,
Elasticsearch가 내부적으로라도 해당 포트를 필요로 할 수 있어서.
클러스터 :
여러 개의 Elasticsearch 노드(서버)를 묶어 하나처럼 동작하게 만든 집합
- 데이터가 많아질수록 한 대의 서버로는 버티기 힘듬
- 여러 노드에 데이터를 나눠 저장 및 서로 협업면서 더 빠르고 안정적으로 처리하게 만듬
ES에서 왜 힙 설정을 왜함 ?:
자바에서 객체(Object) 들이 저장되는 동적 메모리 영역
우리가 new로 만드는 객체들 대부분이 힙(Heap) 안에 저장.
📌 메모리 구조 간단 정리
영역 역할
Heap 동적으로 생성한 객체 저장 공간 (ex: new ArrayList<>)
Stack 메서드 호출 시 생기는 지역변수 저장 (속도 빠름)
Code 실행 코드 저장
Method Area 클래스, static 변수 등 저장
📦 그럼 Elasticsearch는 왜 힙을 써?
Elasticsearch는 Java 기반이라서,
인덱싱/검색 시 수많은 객체를 메모리에서 처리하거든.
예: 쿼리 캐시, 인덱스 버퍼, 검색 결과, Lucene 세그먼트 등
➡️ 이걸 전부 힙 메모리에 올려서 빠르게 처리하려는 거야.
즉, 시작할 때도 2GB, 최대로 써도 2GB로 고정
이렇게 고정해놓으면 성능적으로 안정적이야 (GC 오버헤드 감소)
❗ 왜 중요하냐?
힙이 너무 작으면 → OOM(Out Of Memory) 발생
힙이 너무 크면 → GC(Garbage Collection) 시간이 너무 오래 걸려서 렉 생김
특히 Elasticsearch는 힙 사이즈 조절이 성능에 핵심적인 영향을 줘
kibana? :
Elasticsearch 데이터를 시각적으로 보여주는 웹 인터페이스
(쉽게 말해 Elasticsearch의 GUI 툴)
💡 즉, 너의 흐름은 이런 거야:
사용자가 질문을 함 → 이걸 768차원 벡터로 인코딩
그 벡터를 Elasticsearch에 Vector 필드 기준으로 유사도 검색함
유사한 벡터들이 담긴 문서를 찾아서
그 문서의 text / href를 응답으로 보여주는 구조
NDJSON? :
Newline Delimited JSON
줄바꿈으로 구분된 JSON 형식
Elasticsearch를 비롯해 로그 처리, 데이터 스트리밍 등에서 진짜 자주 등장하는 형식
📦 예시
{"index":{"_index":"my-index","_id":"1"}}
{"name":"Alice","age":30}
{"index":{"_index":"my-index","_id":"2"}}
{"name":"Bob","age":25}각 줄은 하나의 JSON 객체
줄바꿈(\n)으로 다음 JSON과 구분
여러 JSON을 한꺼번에 보낼 때 사용됨 (특히 Elasticsearch Bulk API에서 필수)
사용이유
✅ 스트리밍 친화적 : 한 줄씩 읽고 처리하기 쉽다
✅ 대용량 데이터에 적합 : JSON 배열 대신 한 줄씩 처리하므로 메모리 부담 적음
✅ Elasticsearch와 잘 맞음 : Bulk API, _msearch, _bulk, _update_by_query 등에 사용됨
