shiyu-coder/Kronos · ⭐ 16k · Python · MIT
AAAI 2026 · arXiv 2508.02739
TL;DR
- Kronos는 전 세계 45개 거래소의 K-line(캔들차트)로 사전학습된 금융 시계열 파운데이션 모델이다. 오늘 GitHub 트렌딩 2위(+1,985).
- 가장 간단한 사용법(
prediction_example.py그대로, Kronos-small, zero-shot)을 BTC 시간봉과 삼성전자 일봉에 한 번씩 돌려봤다. - 같은 데이터에 두 가지 단순 baseline(마지막 값 유지 / 직선 외삽)도 같이 돌려서 비교했다.
- 이 한 번의 zero-shot 실험에서는 Kronos가 두 baseline보다 못했다.
- BTC 5일 예측: naive last-value MAPE 0.97% vs Kronos 4.87%
- Samsung 60일 예측: naive last-value MAPE 22.2% vs Kronos 63.2%
- 다만 이 결과는 fine-tuning 없이 가장 작은 모델만 본 결과이고, 특히 BTC는 변동성이 매우 낮은 기간이라 naive baseline에 유리했다는 caveat가 있다 (자세한 건 마지막에).
- 결론은 "Kronos가 못한다"가 아니라, "zero-shot으로 그대로 갖다 쓰면 단순 baseline에도 밀릴 수 있고, fine-tuning과 평가 설정에 신경 써야 한다"는 정도로 읽는 게 안전하다.
뭐 하는 프로젝트인가
Kronos의 풀 제목은 "A Foundation Model for the Language of Financial Markets"다. 저자들의 비유가 명확하다 — 금융 K-line(캔들차트)을 하나의 "언어"로 보고, 그 언어 위에 GPT를 앉힌다는 거다. 자연어에 BPE 토크나이저 + autoregressive Transformer가 있는 것처럼, K-line에는 전용 토크나이저 + autoregressive Transformer가 있다는 구도.
구조: 토크나이저 + 디코더 전용 트랜스포머
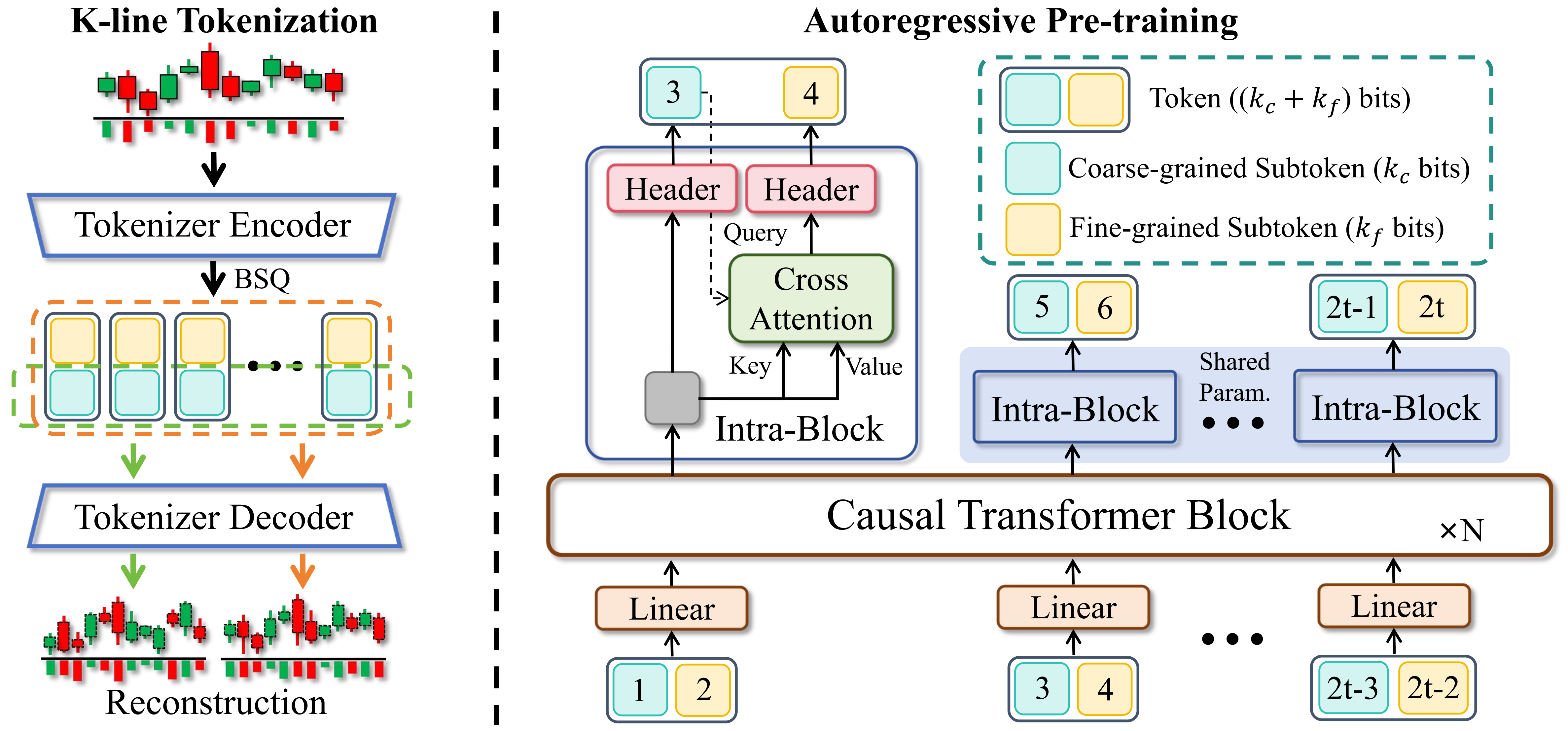
출처: Kronos GitHub repo (figures/overview.png), MIT License. Shi et al., AAAI 2026.
위 그림이 Kronos의 전체 구조다. 왼쪽이 토크나이저, 오른쪽이 사전학습 본체.
1. 토크나이저 (왼쪽) — Encoder-Decoder 구조의 양자화기다. K-line 시퀀스를 받아 encoder가 latent로 압축한 뒤 BSQ(Binary Spherical Quantization) 로 이산화하고, decoder가 그걸로 원래 K-line을 reconstruct하는 식으로 학습된다. VQ-VAE 계열의 친숙한 패턴이다.
핵심 디테일은 "계층적 토큰"의 진짜 의미에 있다. 한 K-line bar가 하나의 토큰으로 떨어지는 게 아니라, 두 단위로 쪼갠다:
- Coarse-grained subtoken ( bits) — 큰 단위 패턴을 잡는 상위 토큰
- Fine-grained subtoken ( bits) — 미세 변동을 잡는 하위 토큰
즉 한 시점이 bits짜리 합성 토큰으로 표현된다. 자연어의 BPE 단일 vocabulary와 달리, 가격 시계열의 자릿수(scale) 차이를 두 단계로 분리해 다룬 셈이다. 이게 "hierarchical discrete tokens"의 실체다. (정확한 , 값은 논문 본문을 봐야 함.)
2. 디코더 트랜스포머 (오른쪽) — Causal Transformer 본체가 토큰 시퀀스를 받아 다음 토큰을 autoregressive하게 예측한다. 여기서도 디테일이 하나 있는데, coarse·fine subtoken을 하나의 head가 같이 뱉는 게 아니라 두 개의 header가 분리해서 예측한다. fine header가 coarse header의 출력에 cross-attention으로 conditioning되는 구조다. 즉 "큰 그림을 먼저 정하고 그 안에서 미세 조정"하는 식의 prediction 분해.
학습 목적함수는 순수 autoregressive loss, 별도 작업 손실 없음.
이 구조 자체는 "encoder-decoder 양자화 + autoregressive transformer"라는 점에서 시계열·오디오 분야의 다른 모델들과 비슷하다. Kronos의 진짜 베팅은 모델 구조가 아니라 데이터에 있다.
사전학습 데이터: 12B records, 45개 거래소
논문 abstract에 따르면 Kronos는 45개 글로벌 거래소의 120억(12B) K-line 레코드로 사전학습됐다. 시계열 foundation 모델 중에서도 데이터 규모가 큰 편이고, 무엇보다 금융 K-line이라는 한 도메인에 12B를 부었다는 게 차별점이다 — TimesFM·Chronos·Moirai 같은 범용 모델은 같은 규모의 데이터를 IoT·전력·교통 등 여러 도메인에 분산해 쓴다.
다만 45개 거래소가 어디인지, 자산 클래스 비중(암호화폐/주식/외환/원자재)이 어떻게 되는지, timeframe 구성(분봉/시봉/일봉)이 어떻게 되는지는 README에도 abstract에도 공개돼 있지 않다. 이 부분이 모델의 zero-shot 일반화 범위를 가늠하는 데 가장 중요한 정보인데 빠져 있는 게 아쉽다.
모델 변종 (4가지)
| 모델 | 파라미터 | 컨텍스트 길이 | 공개 여부 |
|---|---|---|---|
| Kronos-mini | 4.1M | 2048 | ✅ |
| Kronos-small | 24.7M | 512 | ✅ |
| Kronos-base | 102.3M | 512 | ✅ |
| Kronos-large | 499.2M | 512 | ❌ (비공개) |
가장 큰 large 모델만 미공개. small·base는 RTX 3090 Ti 정도의 소비자 GPU에서 추론·fine-tuning 모두 충분히 들어간다.
저자들이 강조하는 task는 forecast 하나가 아니다
여기가 글을 쓰면서 제일 의외였던 부분이다. 모델 이름과 README만 보면 "가격 예측 모델"인 것 같지만, 논문 abstract는 다른 작업도 강조한다.
- Price/return forecasting — 가장 흔한 task
- Volatility forecasting — 변동성 예측 (옵션 가격·리스크 관리에 직접 쓰임)
- Synthetic K-line generation — 가짜 캔들 시퀀스 생성 (백테스팅·데이터 증강용)
논문이 자랑하는 수치도 이 셋에 걸쳐 있다.
| 작업 | 비교 대상 | 향상 |
|---|---|---|
| Price forecasting (RankIC) | leading TSFM | +93 % |
| Price forecasting (RankIC) | best non-pretrained baseline | +87 % |
| Volatility forecasting (MAE) | — | −9 % |
| Synthetic generation (fidelity) | — | +22 % |
여기서 주의해야 할 게 두 가지 있다.
- RankIC는 절대 가격을 맞췄는지가 아니라, 종목들의 미래 수익률 순위를 얼마나 잘 예측했는지를 보는 metric이다. 퀀트 리서치에서 stock-picking 성능을 잴 때 쓰는 표준 지표다. 본인이 이 글에서 사용한 MAPE/MAE는 절대 가격 오차이고, RankIC와는 측정하는 게 다르다. 즉 논문의 "93% 향상"과 본인 실험의 "5배 부정확"이 직접 비교 가능한 수치는 아니다.
- 논문이 자랑하는 RankIC 수치가 fine-tuned 결과인지 zero-shot 결과인지는 abstract만 봐서는 명확하지 않다. 본문을 읽어봐야 한다.
이 글의 실험은 가장 직관적인 absolute forecast(MAE/MAPE) 기준이지 RankIC 기준이 아니다. 두 평가 framework는 보완적이지 대체 관계가 아니라는 점을 글의 한계로 같이 봐야 한다. (이 부분은 마지막 "한계" 섹션에서 다시 다룬다.)
KronosPredictor API
사용법 자체는 매우 단순하다.
from model import Kronos, KronosTokenizer, KronosPredictor
tokenizer = KronosTokenizer.from_pretrained("NeoQuasar/Kronos-Tokenizer-base")
model = Kronos.from_pretrained("NeoQuasar/Kronos-small")
predictor = KronosPredictor(model, tokenizer, max_context=512)
pred_df = predictor.predict(
df=x_df, # 과거 OHLCV+amount DataFrame
x_timestamp=x_ts,
y_timestamp=y_ts,
pred_len=120,
T=1.0, # temperature: 샘플링 sharpness
top_p=0.9, # nucleus sampling threshold
sample_count=1, # forecast path 개수 (>1이면 평균 반환)
)LLM에 익숙하다면 T(temperature)와 top_p(nucleus sampling)는 그대로 같은 의미다. 확률적 forecasting을 한다는 점이 이 모델의 LLM 출신다운 부분이다. 단 여러 path를 보고 싶으면 sample_count=1로 K번 호출해서 직접 stack해야 한다 (자세한 건 막힌 점 섹션에).
코드 구조
| 폴더 | 내용 |
|---|---|
model/ | Kronos, KronosTokenizer, KronosPredictor 핵심 클래스 |
examples/ | prediction_example.py 등 zero-shot 사용 예제 |
finetune/ | Qlib 기반 fine-tuning 파이프라인 (train_tokenizer.py, train_predictor.py, 백테스트 qlib_test.py) |
finetune_csv/ | CSV 입력 fine-tuning 대안 |
webui/ | BTC/USDT 24시간 라이브 데모 인프라 (데모 페이지) |
tests/ | 테스트 |
figures/ | 논문/README용 이미지 |
이 구조 자체가 이 프로젝트가 "단순 모델 weight 공개"가 아니라 "fine-tuning 워크플로우 전체"를 함께 배포하는 것이라는 걸 보여준다. 저자들이 zero-shot보다 fine-tuned 사용을 메인으로 가정하고 있다는 강한 신호다. (이 점이 본인 실험 결과를 해석할 때 결정적이다.)
왜 지금 뜨고 있나
뜨는 이유는 비교적 명확하다.
- 시계열 파운데이션 모델 흐름의 연장선. 작년부터 TimesFM(Google), Chronos(Amazon), Moirai(Salesforce) 등이 잇따라 공개됐는데 모두 범용이었다. Kronos는 거기서 금융 K-line이라는 도메인에 12B 레코드 전부를 베팅한 첫 공개 모델이다.
- AAAI 2026 accept 이후의 정식 공개 타이밍. 논문 자체는 2025년 8월 arXiv에 올라왔지만, 코드·모델·fine-tuning 파이프라인이 한 번에 정리돼 트렌딩에 오른 건 최근.
- MIT 라이선스 + Hugging Face 배포 + qlib 백테스트 파이프라인 + 라이브 데모까지 묶여 나왔다. 진입 장벽이 낮다.
- 그리고 저자들이 강조하는 use case가 forecast 하나가 아니라는 점(volatility / synthetic generation)도 차별점이다. 단순 가격 예측 모델이 아니라 "금융 시계열을 위한 범용 backbone"을 노린다.
설명만 보면 굉장히 매력적이다. 그래서 직접 돌려봤다.
실험 1 — BTC/USDT 시간봉 zero-shot
설정
- 데이터: binance, BTC/USDT 1h, 520봉 (2026-03-22 17:00 → 2026-04-13 08:00)
- 모델: Kronos-small (24.7M, max_context=512)
- lookback = 400시간, 예측 = 120시간 (5일)
- T=1.0, top_p=0.9
- 데이터 수집은
ccxt한 줄, 추론은 GPU(RTX 3090 Ti)에서 약 1초.
결과
| metric | value |
|---|---|
| MAE | 3,524 USDT |
| RMSE | 4,265 USDT |
| MAPE | 4.87 % |
| DirAcc | 0.546 |
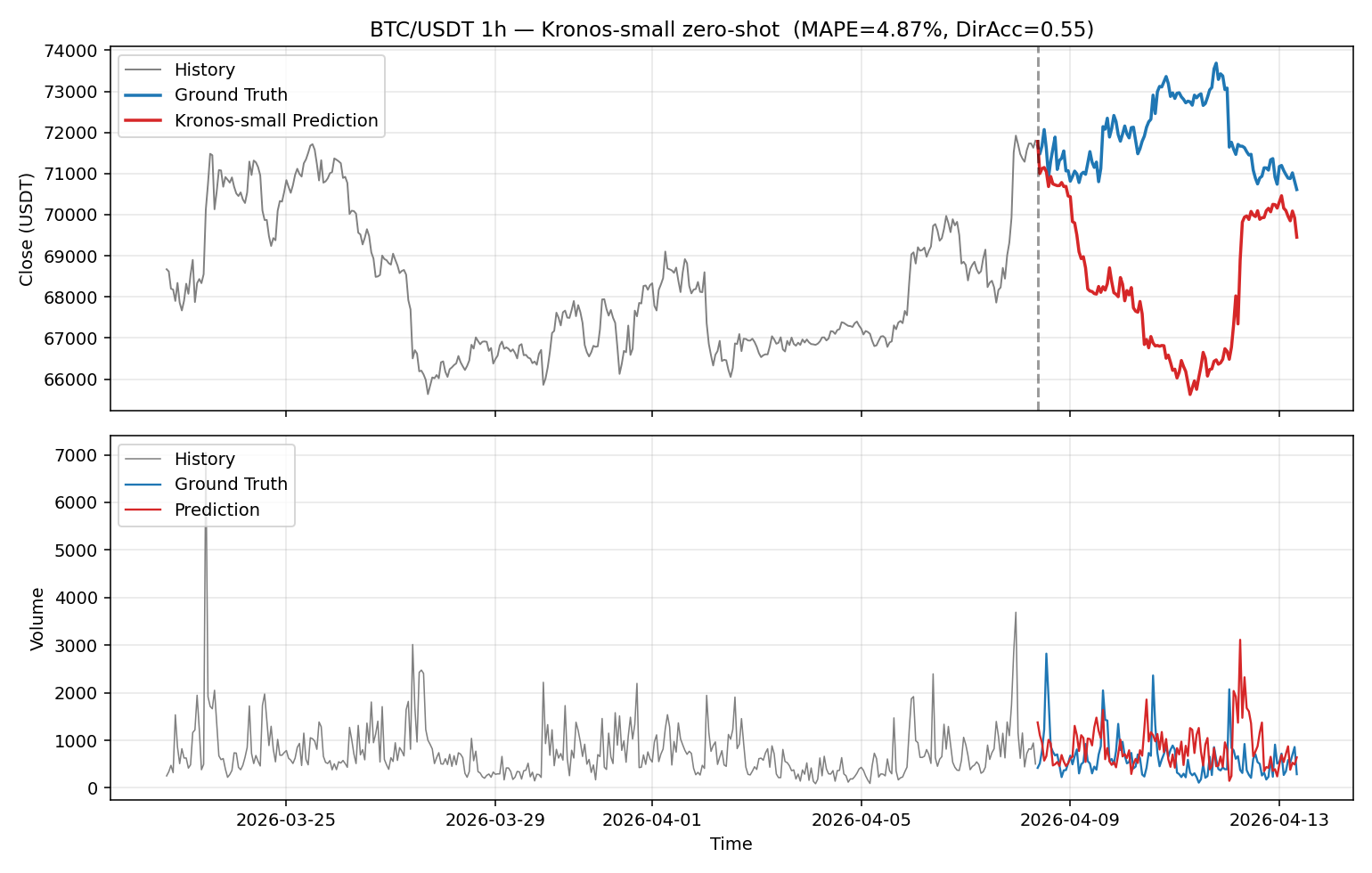
점선이 forecast 시작점이다. 모델은 lookback 끝의 단기 하락 모멘텀을 받아 5일 내내 하락을 예측했지만, 실제 BTC는 횡보 후 오히려 상승했다. 두 곡선은 거의 항상 반대 방향으로 움직인다.
MAPE 4.87%라는 숫자만 보면 작아 보일 수 있다. 그래서 가장 게으른 두 baseline과 직접 비교해봤다.
- naive last-value: "5일 뒤 가격 = 지금 가격". 학습도, 데이터도, 모델도 없다. 그냥 상수.
- drift: lookback 첫·마지막 점을 직선으로 이어 외삽. 이것도 학습 없음.
| method | MAE | MAPE | DirAcc |
|---|---|---|---|
| naive last-value | $701 | 0.97 % | — |
| drift (linear) | $775 | 1.08 % | 0.521 |
| Kronos-small | $3,524 | 4.87 % | 0.546 |
이 window에서는 Kronos가 naive baseline보다 약 5배 큰 절대 오차를 냈다. 그리고 방향성에서도 두 baseline과 비슷한 수준(코인던지기 근처)에 머물렀다.
다만 이 숫자는 그대로 받기 전에 한 가지 caveat를 같이 봐야 한다. 이 5일 동안 BTC가 거의 안 움직였다. naive baseline MAPE가 0.97%까지 떨어지려면 가격 변동이 정말 작아야 한다. 변동성이 낮은 기간에는 어떤 모델도 noise를 추가하면 naive를 이기기 어렵다. 만약 BTC가 ±15% 출렁이는 기간이었다면 naive baseline MAPE도 5–10%로 올라가서 Kronos의 4.87%가 비슷하거나 더 좋아 보였을 수 있다. 즉 "5배"라는 비율은 이 차분한 기간 효과가 일정 부분 들어가 있는 숫자다.
그래도 방향성이 틀린 건 변동성과 무관한 별개 문제다. 모델은 5일 내내 하락을 가리켰지만 시장은 횡보~상승했다.
(naive last-value의 DirAcc은 정의되지 않는다 — 모든 예측값이 상수라 diff=0이 되어 부호가 없다.)
확률적 forecast의 함정
Kronos는 단일 forecast가 아니라 temperature 기반 확률적 forecasting을 한다는 게 LLM 출신 모델다운 부분이다. 그래서 같은 입력으로 30번 forecast를 돌려서 분포를 봤다.
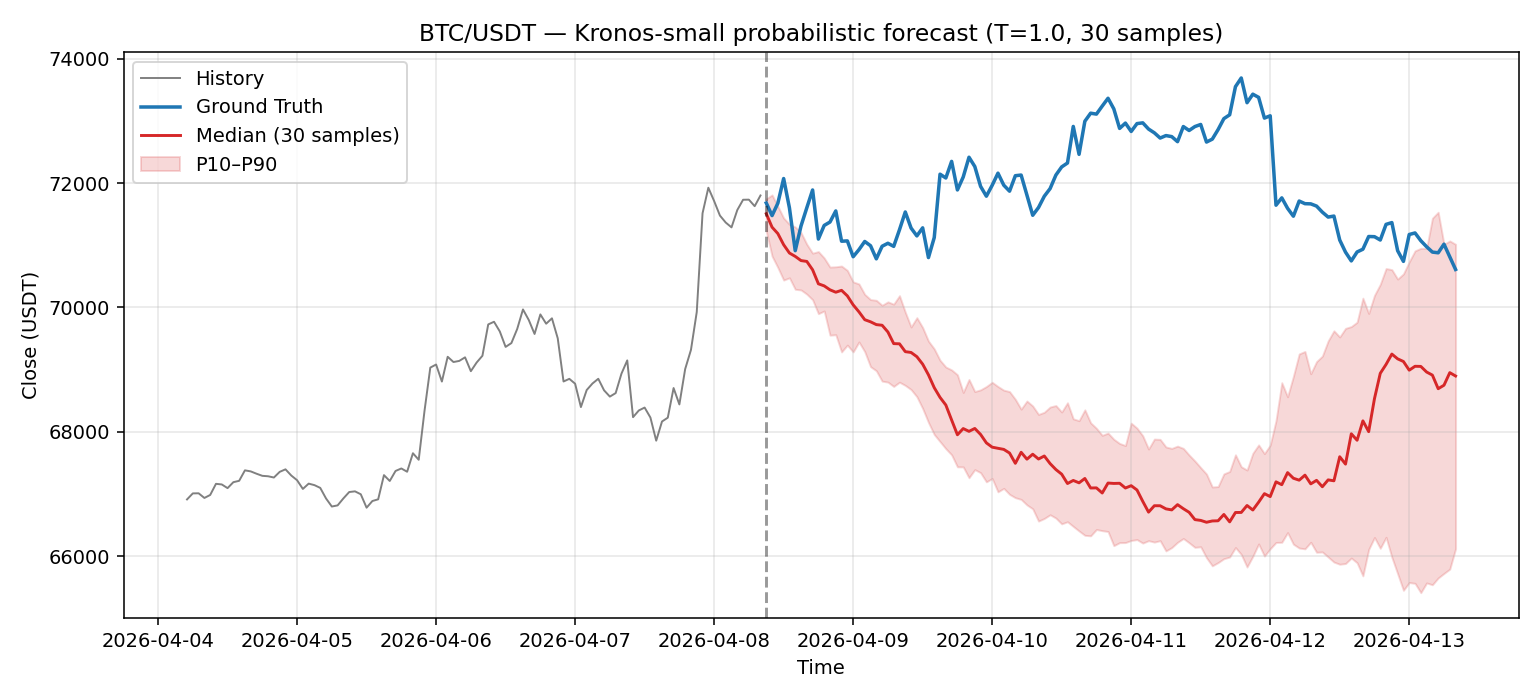
빨간 영역이 30개 샘플의 P10~P90 신뢰 구간이다. ground truth(파란 선)가 거의 전 구간에서 이 영역 밖에 있다. 95% 신뢰 영역도 아니고 단지 P10–P90인데도 cover를 거의 못 한다. 30개 샘플 모두가 "내려간다"는 한 방향에 몰려 있고, 그 방향이 틀렸다.
이건 단순한 예측 오류가 아니라 모델이 자기 예측에 과신하고 있다(miscalibrated)는 신호다. 게다가 분포 자체가 잘못된 곳에 떠 있는 systematic bias이지, sampling 분산이 부족한 게 아니다. 확률적 forecasting을 한다는 사실이 곧 "calibrated된 불확실성을 준다"를 의미하지 않는다는 걸 시각적으로 보여주는 사례다.
여기까지가 사전학습 분포에 가장 가까운 데이터(글로벌 거래소의 시간봉 OHLCV) 에서의 결과다. 즉 모델한테 가장 유리한 조건이다. 그런데도 방향성·calibration 둘 다 무너졌다. 다음 실험에서는 분포 밖으로 한 발만 더 나가본다.
실험 2 — 삼성전자 005930 일봉 zero-shot
같은 모델, 같은 코드, 같은 절차. 데이터만 한국 주식 일봉으로 바꿨다.
설정
- 데이터:
pykrx, 005930(삼성전자) 일봉 460개 (2024-05-22 → 2026-04-13) - 모델: 동일 (Kronos-small)
- lookback = 400일, 예측 = 60일 (약 3개월)
결과 (baseline 비교 포함)
| method | MAE (KRW) | MAPE | DirAcc |
|---|---|---|---|
| naive last-value | 41,516 | 22.2 % | — |
| drift (linear) | 36,937 | 19.7 % | 0.542 |
| Kronos-small | 114,300 | 63.2 % | 0.492 |
Samsung 역시 이 window에서는 Kronos가 두 baseline보다 부정확했다. drift baseline 대비 약 3배. 그리고 drift baseline의 directional accuracy(0.542)가 Kronos(0.492)보다 높다 — 직선 외삽이 foundation 모델보다 추세 방향을 더 잘 잡았다는 뜻이다.
다만 이건 lookback 후반부터 시작된 강한 상승 추세 직후를 자른 단 한 번의 시도다. 다른 시점이나 다른 종목에서는 양상이 다를 수 있다. 다만 mean-reversion 쪽으로 강하게 끌리는 모습 자체는 한 번의 시도라도 의미 있는 신호로 보였다.
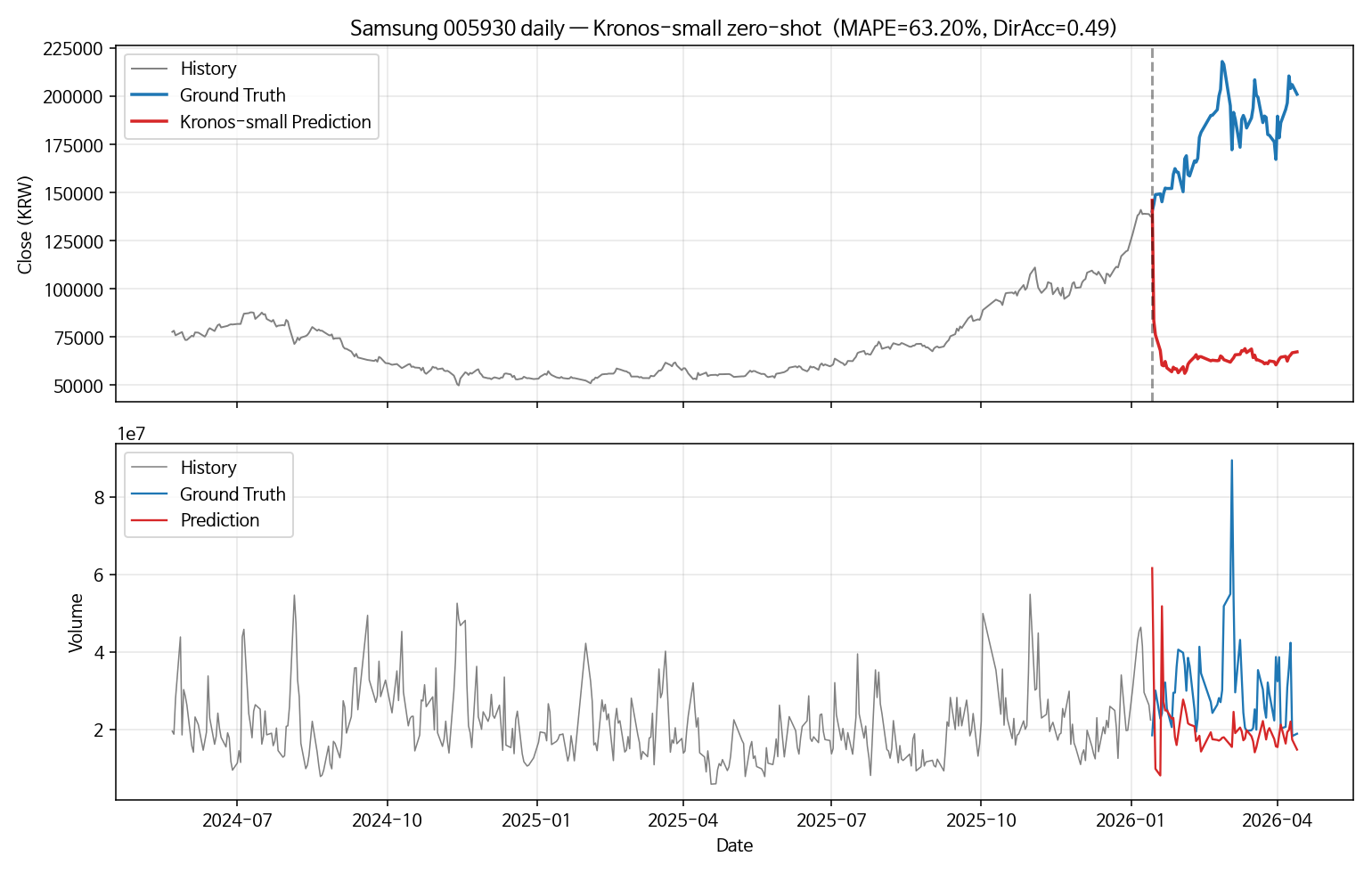
이 plot이 이 글의 핵심 한 장이다. 삼성전자는 lookback 후반에 약 6만 원에서 14만 원까지 강한 상승 추세를 그렸다. 그런데 Kronos는 forecast 시작 직후 즉시 6~7만 원대로 폭락하는 60일짜리 예측을 낸다. 실제 ground truth는 그 뒤로도 20만 원까지 더 오른다.
거래량 plot도 마찬가지다. 모델은 거래량이 history 평균 수준으로 잠잠해질 거라고 예측하지만, 실제는 추세 가속과 함께 거래량도 폭증한다.
30개 샘플도 똑같이 틀린다
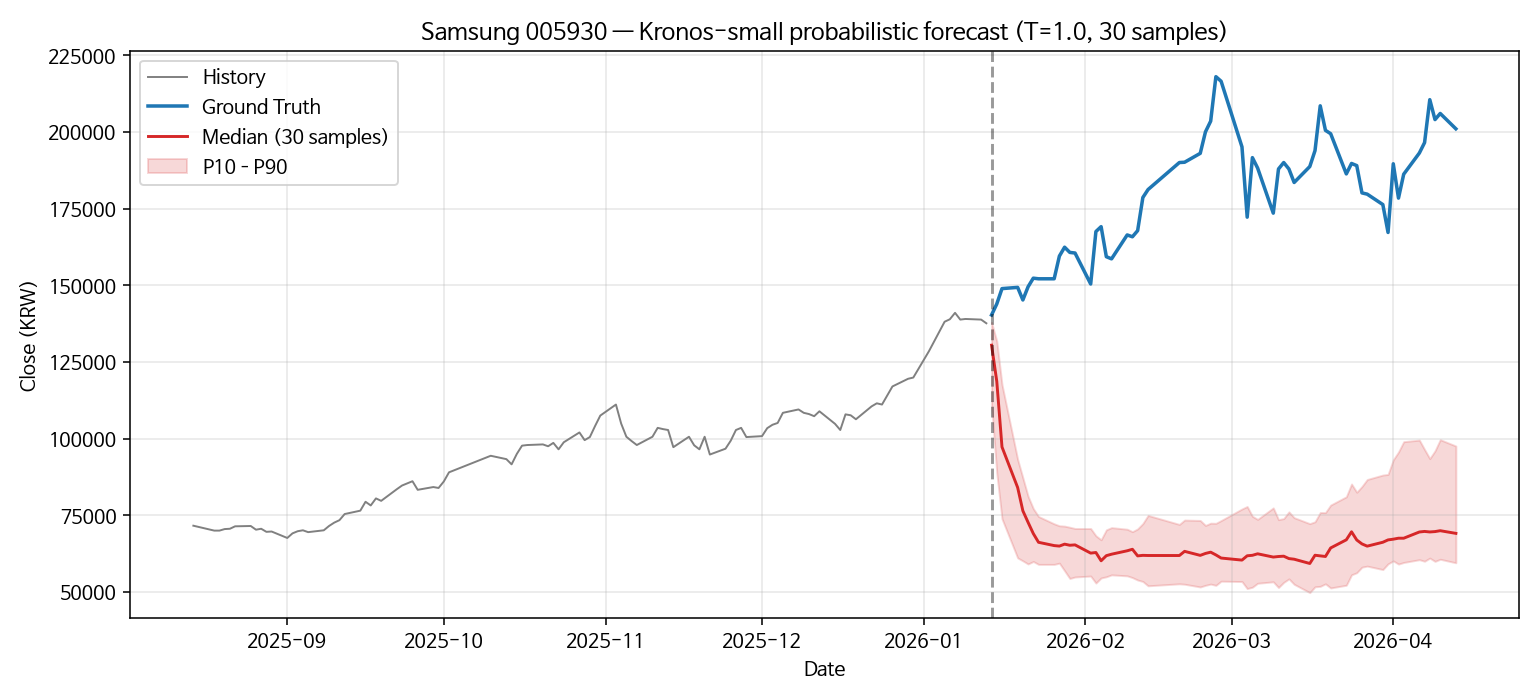
BTC에서도 같은 패턴이었지만 절대 가격대가 비슷해서 한눈에 안 들어왔다. Samsung에서는 그 패턴이 극단적으로 드러난다. 30개 샘플 전부가 폭락 시나리오에 몰려 있고, 빨간 band가 ground truth와 한참 떨어진 곳에 떠 있다.
BTC 결과와 합쳐서 보면 결론이 분명해진다. Kronos의 확률적 forecast는 BTC에서도 Samsung에서도 같은 방식으로 무너진다 — 30개 샘플이 한 방향으로 몰리고, 그 방향이 틀린다. 차이는 단지 절대 가격대의 스케일뿐이다.
왜 이렇게 갈렸는가 — distribution shift 가설
엄밀히 말하면 두 실험의 차이는 "성공 vs 실패"가 아니라 "같은 종류의 실패가 얼마나 노골적으로 드러나는가"의 차이다. 그래도 MAPE가 4.87% → 63.20%로 13배 차이가 나는 건 분명 의미 있는 격차다. 가능한 설명을 정리하면:
가설 1. Timeframe shift: 일봉은 OOD다
Kronos가 학습한 45개 거래소의 K-line은 분봉·시봉 비중이 압도적으로 많을 가능성이 높다. 거래소 API에서 수집할 수 있는 raw bar는 1m·5m·15m·1h가 기본이고, 일봉은 그것들의 aggregate일 뿐이다. 모델이 본 적 없는 timeframe에 zero-shot으로 들어가면 무너지는 게 자연스럽다.
가설 2. 평균회귀 vs 추세 분포 shift
사전학습 데이터의 K-line이 어느 자산 클래스에 편향됐는지가 결정적이다. 거래소 = 주로 암호화폐. 암호화폐는 변동성이 크고 단기적으로는 평균회귀형 패턴이 자주 나타난다. 반면 삼성전자 일봉은 수개월짜리 단방향 추세가 자연스러운 시계열이다.
모델은 본인이 학습한 분포 안에서 "이런 모양 다음에는 보통 어떻게 됐었지?"를 떠올린다. 학습 분포가 평균회귀에 편향돼 있으면, 강한 추세 입력을 받았을 때 "곧 평균으로 회귀할 거야"라고 우긴다. Samsung plot이 정확히 그 모습이다.
가설 3. 한국 시장의 미시구조 차이
KOSPI는 가격제한폭(±30%), 사이드카, VI 같은 제도가 있고 거래 시간도 짧다. 글로벌 거래소 K-line으로 학습된 모델에는 이런 미시구조가 사전 정보로 들어가 있지 않다.
세 가설 중 어느 게 가장 큰 비중을 차지하는지는 추가 실험 없이는 단언할 수 없다. 다만 방향성은 명확하다: 사전학습 분포에서 멀어질수록 fall-off가 가파르다.
비슷한 프로젝트와 비교
| 프로젝트 | 사전학습 도메인 | 차별점 |
|---|---|---|
| Kronos | 금융 K-line (45개 거래소) | OHLCV 전용 토크나이저, 확률적 forecast |
| TimesFM (Google) | 범용 시계열 | 도메인 비특화, 단변량 중심 |
| Chronos (Amazon) | 범용 시계열 | 언어모델 토크나이저 재활용 |
| Moirai (Salesforce) | 범용 시계열 | 임의 변량·주기 지원 |
특이한 건, "금융에 특화했다"는 게 반드시 "금융 전반에 일반화된다"를 의미하지 않는다는 점이다. Kronos는 BTC에서도 방향성을 못 잡았고, Samsung에서는 거기에 더해 스케일까지 무너졌다. 범용 모델 셋과의 직접 비교는 별도 실험이 필요하지만, 적어도 "금융 특화"라는 라벨만 보고 도메인 적합성을 가정해선 안 된다는 것 정도는 분명해 보인다.
언제 쓰면 좋은가, 언제 안 좋은가
쓸 만한 시나리오 (그래도 검증 전제):
- 시계열 토크나이저 자체를 공부하고 싶을 때. 코드 품질이 좋고 OHLCV → 이산 토큰 변환 아이디어를 그대로 가져다 다른 데이터에 적용해볼 수 있다.
- 연구/벤치마크용 baseline. "이 모델보다는 잘해야 한다"는 하한선으로.
- 본인 도메인에 fine-tuning 해볼 출발점. 단, 이 글의 결과로 보면 zero-shot 성능을 그대로 신뢰하면 안 된다.
쓰면 안 되는(혹은 보정 필수) 시나리오:
- 트레이딩 의사결정에 zero-shot으로 그대로 사용 — BTC 시간봉(거의 home turf)에서도 방향성이 무너진다.
- 일봉 이상의 timeframe
- 강한 단방향 추세가 있는 종목/시장
- 한국 시장처럼 미시구조가 다른 곳
- 확률 영역(예측 구간)을 그대로 의사결정에 사용 — calibration 안 됨, 30 샘플이 한 방향으로 몰림
이 실험의 한계
이 글의 결과를 "Kronos가 못한다"로 일반화하지 않으려면 다음 한계를 같이 봐야 한다.
- Zero-shot만 본 결과다. Kronos 레포는
finetune/·finetune_csv/폴더와 함께 fine-tuning 워크플로우를 강조하고 있고, README의 Chinese A-share 시연도 fine-tuned 모델 결과다. 이 글은 "import해서 그대로 돌리면 어떻게 되는가"이지 "Kronos의 잠재력"을 평가한 게 아니다. fine-tuning을 거치면 결과가 달라질 가능성이 충분하다. - 측정 metric이 논문이 자랑하는 metric과 다르다. 논문은 주로 RankIC(종목 수익률 순위 예측)로 성능을 보고하고 거기서 leading TSFM 대비 +93%를 주장한다. 본인은 MAPE/MAE(절대 가격 오차)로 봤다. 둘은 다른 작업을 측정한다 — RankIC는 "어느 종목이 더 오를지 줄 세우기"에 가깝고 MAPE는 "내일 가격 얼마"를 묻는다. 본인 실험에서 baseline에 졌다는 게 곧 "RankIC에서도 진다"를 의미하지 않는다.
- 가장 작은 모델(Kronos-small, 24.7M)만 봤다. Kronos-base(102M)는 24GB VRAM에 충분히 들어가지만 시간상 안 돌려봤다. 모델 크기에 따라 결과가 다를 수 있다.
- 각 데이터셋에서 단 1번의 window만 봤다. 통계적으로 의미를 가지려면 여러 시점을 sliding window로 평가해야 한다. 이 글의 결과는 "한 번의 사례 보고"에 가깝다.
- BTC 결과의 "5배 차이"는 변동성이 낮은 기간 효과를 포함한다 (위에서 설명). 변동성이 큰 기간이었다면 비율이 줄어들었을 가능성이 있다.
- 하이퍼파라미터는 예제 기본값(T=1.0, top_p=0.9) 그대로다. 튜닝 없이.
- baseline도 가장 단순한 두 가지(naive, drift) 만 봤다. ARIMA·Prophet·간단한 LSTM 등 다른 baseline과 비교하지 않았다.
요약하면 이건 "Kronos를 처음 만난 사람이 zero-shot으로 한 번 돌렸을 때 무슨 일이 일어나는가"의 단일 사례 보고이지, Kronos의 능력을 측정한 글이 아니다. 그래도 첫 사용 인상으로는 다음을 남길 만하다.
- 평가 시 baseline 비교는 반드시 같이 가야 한다.
- 확률적 forecasting의 신뢰 구간을 그대로 의사결정에 쓰면 안 된다.
- "금융 파운데이션 모델"이라는 라벨만 보고 도메인 적합성을 가정해선 안 된다.
내 도메인 관점에서
내 도메인은 금융·물류·공급망 시계열이다. 하지만, 지금은 물류·공급망에 집중하고 있기에 Kronos를 본인 도메인에 그대로 갖다 쓸 일은 없다. OHLCV 형식 자체가 안 맞아서, 가져다 쓰려면 토크나이저부터 다시 학습해야 한다.
다만 이 실험을 하면서 다시 확인한 본인의 일반적인 입장 하나는 적어두고 싶다.
주식·자산 가격에 대한 장기 시계열 예측은 본질적으로 무의미하거나 거의 불가능하다고 본다.
가격은 efficient market hypothesis가 완벽하게 성립하진 않더라도, 시점이 멀어질수록 예측 가능한 신호 대비 예측 불가능한 노이즈의 비율이 폭발적으로 커진다. 5일·60일짜리 가격 예측은 모델 성능 문제가 아니라 문제 정의 자체가 비대칭적으로 어려운 쪽으로 잡혀 있는 작업이다. 이건 Kronos든 다른 어떤 모델이든 마찬가지다.의미 있다고 생각하는 방향은 정반대다. tick 데이터 수준의 고빈도 데이터에서, 짧은 horizon에 대해 마이크로 구조적 패턴을 잡아내는 단타성 예측. 여기엔 정보 이론적으로 학습 가능한 신호가 분명히 존재하고, 모델·데이터·실행 인프라가 잘 갖춰지면 실제로 alpha가 나온다.
그래서 Kronos 같은 "일봉/시봉 기반 장기 horizon forecast" 자체에 본인은 처음부터 회의적이었다. 이 실험 결과가 그 회의를 강화하긴 했지만, 결과가 달랐어도 입장이 크게 바뀌진 않았을 것 같다.
이 입장이 모두에게 동의를 받을 만한 건 아니라는 걸 안다. 다만 본인 도메인 안에서 시계열 모델을 평가할 때의 기준점을 같이 적어두는 게 솔직한 글이 된다고 본다.
정리
- Kronos는 프로젝트로서는 잘 만들어졌다. 코드 품질·라이선스·Hugging Face 배포·재현성·fine-tuning 파이프라인까지 모범적이다. 트렌딩에 오르는 게 이상하지 않다.
- 다만 이번 zero-shot 실험에서는 두 데이터셋 모두에서 가장 단순한 baseline보다 부정확했다. 이게 fine-tuning이나 더 큰 모델에서도 같은 양상일지는 별도 검증이 필요하다.
- 이 글에서 가져갈 건 "Kronos는 안 된다"는 단정이 아니라, 새 모델을 처음 만났을 때 어떻게 검증할지에 대한 작은 절차다.
- 베이스라인 비교 없는 metric은 의미가 없다. "MAPE 5%니까 그럴듯해 보인다"는 직관은 그 baseline이 0.97%인 순간 무너진다. 새 모델을 평가할 때 가장 먼저 할 일은 가장 게으른 baseline을 돌리는 것이다.
- MAPE 같은 절대 오차 단일 metric에 끌려가면 안 된다. 방향성·calibration·baseline 비교를 같이 봐야 한다.
- 확률적 forecasting을 한다는 사실이 곧 calibrated uncertainty를 준다는 의미가 아니다. P10–P90 band를 의사결정에 쓰기 전에 반드시 보정 단계를 끼워야 한다.
- 그리고 본인 입장에서는, 일봉/시봉 기반 장기 horizon forecast 자체에 회의적이라 (위 코멘트 참조), 이 결과가 본인 연구 방향을 바꾸진 않는다.
재현 정보
이 글의 모든 plot과 metric은 다음에서 재현 가능하다.
- 스크립트:
experiments/2026-W15-kronos/run_btc.py,run_samsung.py,run_baselines.py - baseline 비교:
outputs/baseline_comparison.txt - 환경: WSL2, Python 3.11, PyTorch (cu124), RTX 3090 Ti (24GB)
- 외부 데이터 의존성:
ccxt(BTC, since 핀 사용),pykrx(KOSPI). 둘 다 인증 불필요.
참고
- GitHub: https://github.com/shiyu-coder/Kronos
- Paper (AAAI 2026): https://arxiv.org/abs/2508.02739
- Hugging Face: https://huggingface.co/NeoQuasar
