Data Processing
Feature Scaling
1. 정규화
정규화는 원소 중 최솟값을 모든 원소에서 빼주고 (분자로 둠), 원소의 최댓값에서 최솟값을 뺀 것으로 (분모로 둠) 나누는 행위.
- 0 ~ 1 사이의 범위로 조정
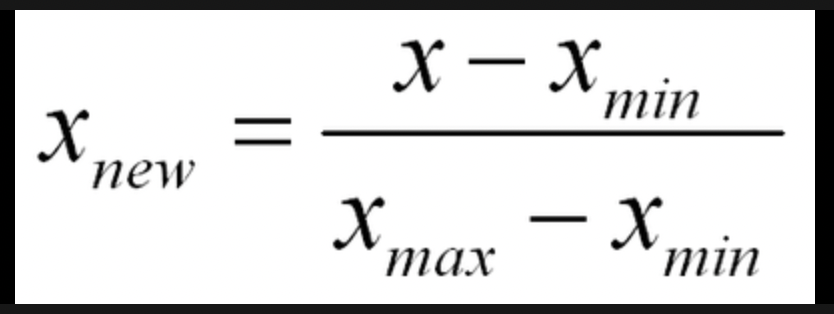
2. 표준화
각 원소들에서 원소들의 평균을 빼고 표준편차로 나누는 작업
- -3 ~ 3 사이의 범위로 조정
- 극단적인 값이 존재할 경우 해당 범위를 벗어날 수 있음
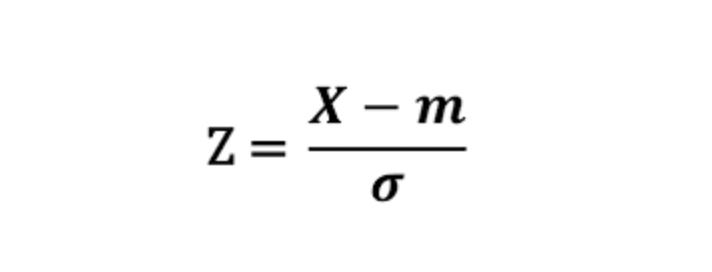
정규화가 필요한 이유
특정 feature 들간의 상관관계를 그룹핑 지을 때, 각 요소 간 차이가 각각 다를 경우 "구체적인 기준"을 어디다 두어야 할지 막연하기 때문
가령, 연봉과 나이라는 feature가 존재하고 홍길동이라는 사람과 비슷한 유형의 사람들로 그룹핑 짓고 싶을 때, 춘향이와 몽룡이가 있다고 하자.
길동이와 춘향이의 연봉 차이는 8000달러, 하지만 나이 차이는 4년
길동이와 몽룡이의 연봉 차이는 10000달러, 하지만 나이 차이는 1년
이런 경우, 춘향이와 몽룡이 중 홍길동과 비슷한 그룹으로 누구를 넣어야 할까?
나이의 경우 지금은 단위가 year이지만 분, 초와 같은 경우로 환산될 경우 더욱 더 구체적인 분류 기준점을 잡기 어려울 것이다.
따라서 정규화의 과정을 통해 특정 범의의 구간으로 Feature들을 집약시켜 "구분" 할 수 있도록 하는 것이다.
Data Processing
1. Importing the LB
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd2. Importing the dataset
독립 변수 및 종속 변수
- 기계학습에서는 독립 변수를 기준으로 우리가 관찰하고자 하는 종속 변수에 대한 변화를 측정한다.
EX ) 국가,나이,연봉 -> 독립 변수 / 구매 내역(YES or NO) -> 종속 변수
따라서, 데이터셋을 불러올 때 독립/종속 변수에 대한 각각의 변수 할당이 필요하다.
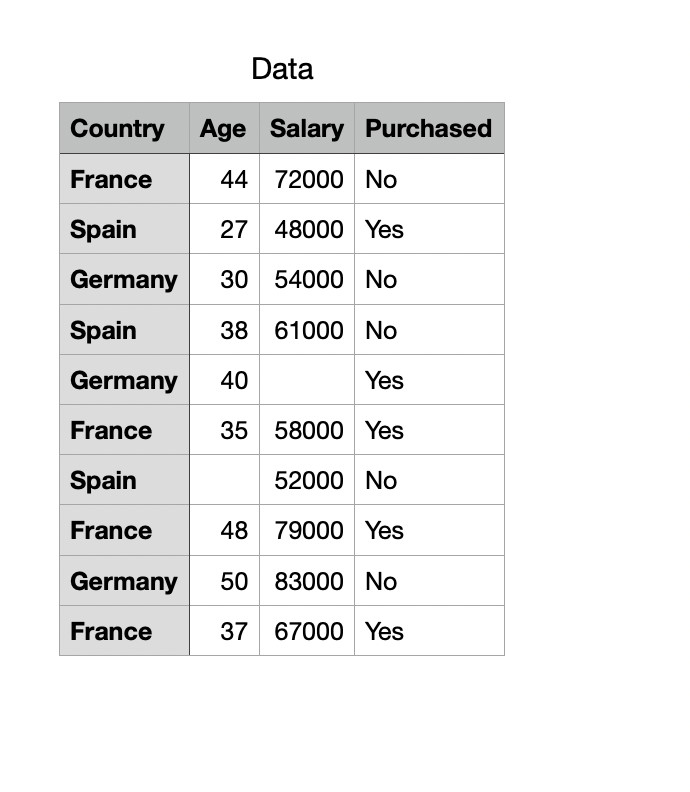
dataset = pd.read_csv('Data.csv')
# 독립 변수
# iloc => 인덱스 위치
# 모든 범위의 행을 X로 지정 (:)
# 모든 행을 선택하면서 각 행에서는 마지막 열을 제외한 모든 열을 선택 (:-1)
X = dataset.iloc[:, :-1].values
# 모든 행을 선택하면서 마지막 열만 선택.
y = dataset.iloc[:, -1].values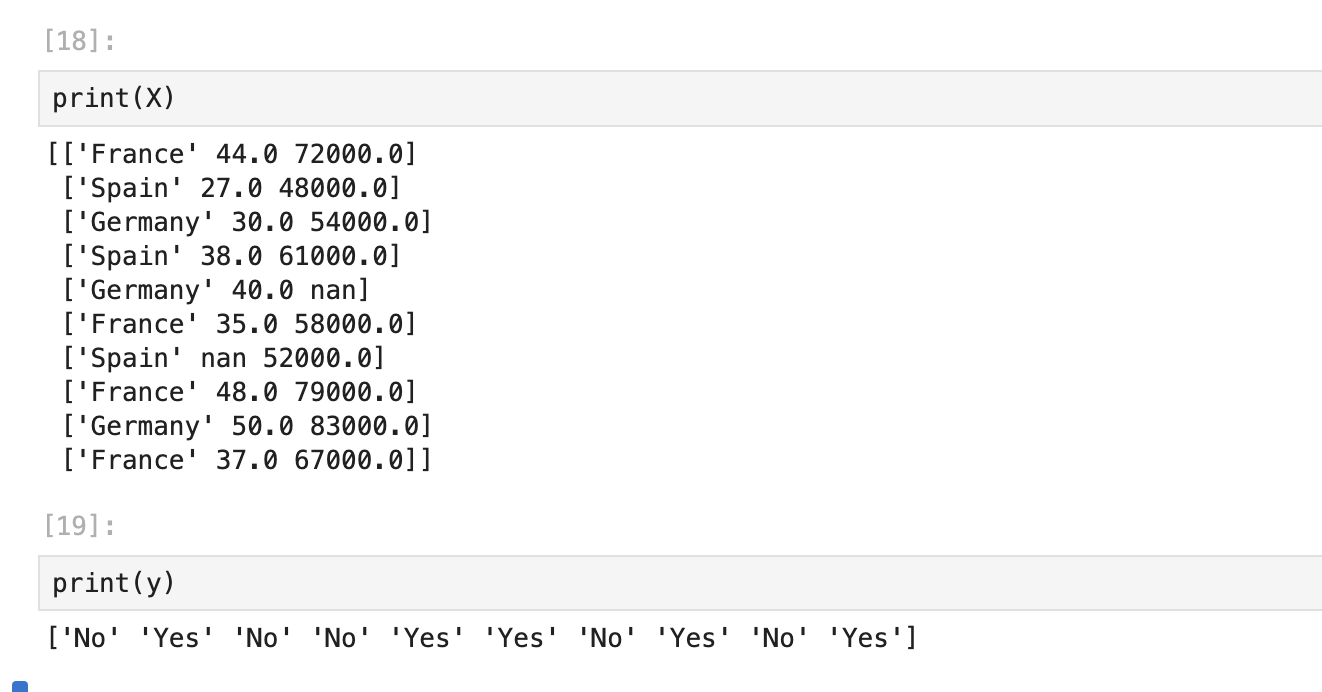
3. Encoding categorical data
특정 컬럼에 등록되지 않은 feature의 blank정보를 해당 열의 평균값으로 대체하자.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer.fit(X[:, 1:3])
X[:, 1:3] = imputer.transform(X[:, 1:3])SimpleImputer 클래스는 scikit-learn에서 제공하는 결측값(missing values)을 대체하는 도구입니다. 결측값은 데이터셋에서 값이 없거나 비어있는 경우를 나타냅니다. 이러한 결측값이 있는 경우, 일부 머신러닝 알고리즘은 이를 처리하지 못하므로, 이를 적절한 값으로 대체해야 합니다.
SimpleImputer 클래스의 인스턴스를 생성합니다. 이때, missing_values 매개변수에는 대체할 결측값의 형태를 지정하고, strategy 매개변수에는 결측값을 대체하는 전략을 지정합니다. 여기서는 결측값을 평균(mean)으로 대체하도록 설정했습니다.
생성한 imputer 객체를 사용하여 데이터의 일부인 X 배열의 1부터 2까지 열(인덱스 1과 2에 해당하는 열)에서 결측값을 대체하기 위한 평균을 계산합니다. (fit 메서드는 대체 전략에 따라 평균을 계산하거나 다른 대체값을 찾습니다.)
X[:, 1:3] = imputer.transform(X[:, 1:3]): 계산된 평균을 사용하여 실제로 결측값을 대체합니다. 이때, transform 메서드를 사용합니다. 여기서는 1부터 2까지 열에 대해서만 결측값을 대체합니다.
최종적으로, X의 1부터 2까지 열에 있는 결측값들이 해당 열의 평균값으로 대체되었습니다. 이렇게 함으로써 데이터셋에서 결측값의 영향을 줄일 수 있습니다.
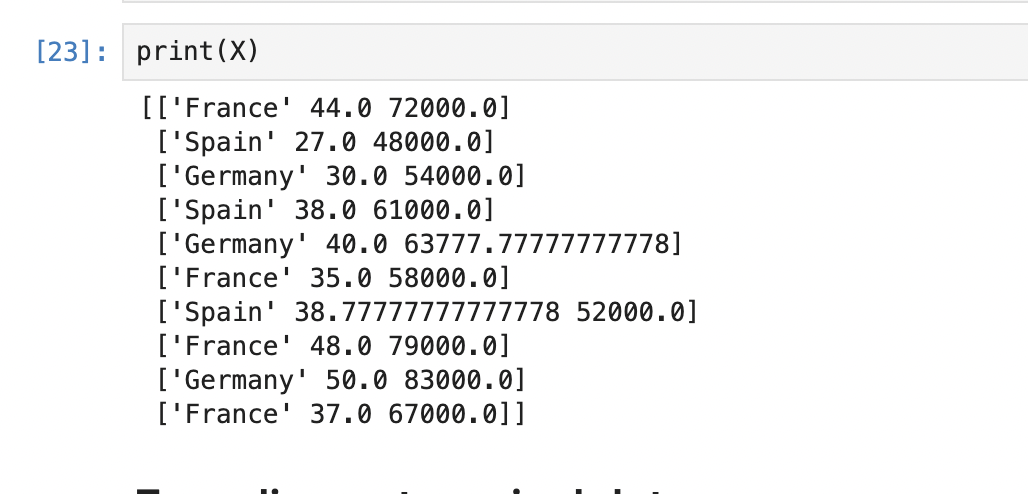
4. Encoding the Independent Variable
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoding
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [0])], remainder='passthrough')
X = np.array(ct.fit_transform(X))ColumnTransformer를 사용하여 데이터의 특성을 변환하는 과정을 나타냅니다. 주로 범주형 데이터의 인코딩에 사용됩니다.
이 클래스는 데이터프레임의 열에 대한 변환을 조정하는 데 사용됩니다.
scikit-learn에서 OneHotEncoder 클래스를 불러옵니다. 이 클래스는 범주형 데이터를 원-핫 인코딩으로 변환하는 데 사용됩니다.
변환자(transformer) 목록에는 ('encoder', OneHotEncoder(), [0])이 포함되어 있습니다. 이는 첫 번째 열([0])에 대해 OneHotEncoder를 사용하여 변환하겠다는 의미입니다.
remainder='passthrough'는 나머지 열은 변환하지 않고 그대로 전달하겠다는 의미입니다.
fit_transform 메서드를 사용하여 변환 작업을 수행하고, 결과를 다시 X에 할당합니다.
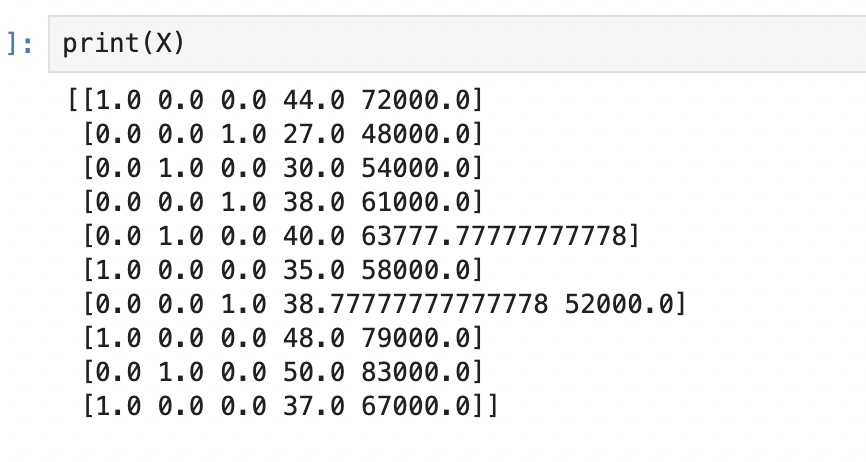
5. Encoding the Dependent Variable
# one-hot Encoding.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)le = LabelEncoder(): LabelEncoder 클래스의 인스턴스를 생성합니다.
y = le.fit_transform(y): 생성한 LabelEncoder를 사용하여 범주형 레이블 y를 숫자로 변환합니다. fit_transform 메서드를 사용하여 변환 작업을 수행하고, 결과를 다시 y에 할당합니다.

6. Splitting the dataset into the Training set and Test set
7번에서 수행할 Feature Scailing 을 수행하기 전, 데이터셋을 훈련 데이터와 테스트 데이터 셋으로 우선적으로 분리하는 이유는 피쳐 스케일링을 수행 후 테스트 데이터셋을 분리하게 되면 기존의 테스트 데이터가 가지고 있는 고유의 값을 해쳐 테스트를 하는 본질에 훼손이 가기 때문.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state = 1)from sklearn.model_selection import train_test_split: scikit-learn에서 train_test_split 함수를 불러옵니다. 이 함수는 데이터를 훈련 세트와 테스트 세트로 나누는 데 사용됩니다.
특징 행렬 X와 대상 변수 y를 훈련 세트와 테스트 세트로 나눕니다.
test_size 매개변수는 테스트 세트의 비율을 나타냅니다. 여기서는 전체 데이터의 20%를 테스트 세트로 사용하도록 설정했습니다.
random_state를 특정한 숫자로 설정하면, 같은 시드를 사용하여 항상 동일한 난수가 생성되어 데이터를 나누게 됩니다. 이렇게 하면 코드를 여러 번 실행해도 항상 같은 훈련 세트와 테스트 세트가 생성되므로, 결과를 재현하기 쉽습니다.
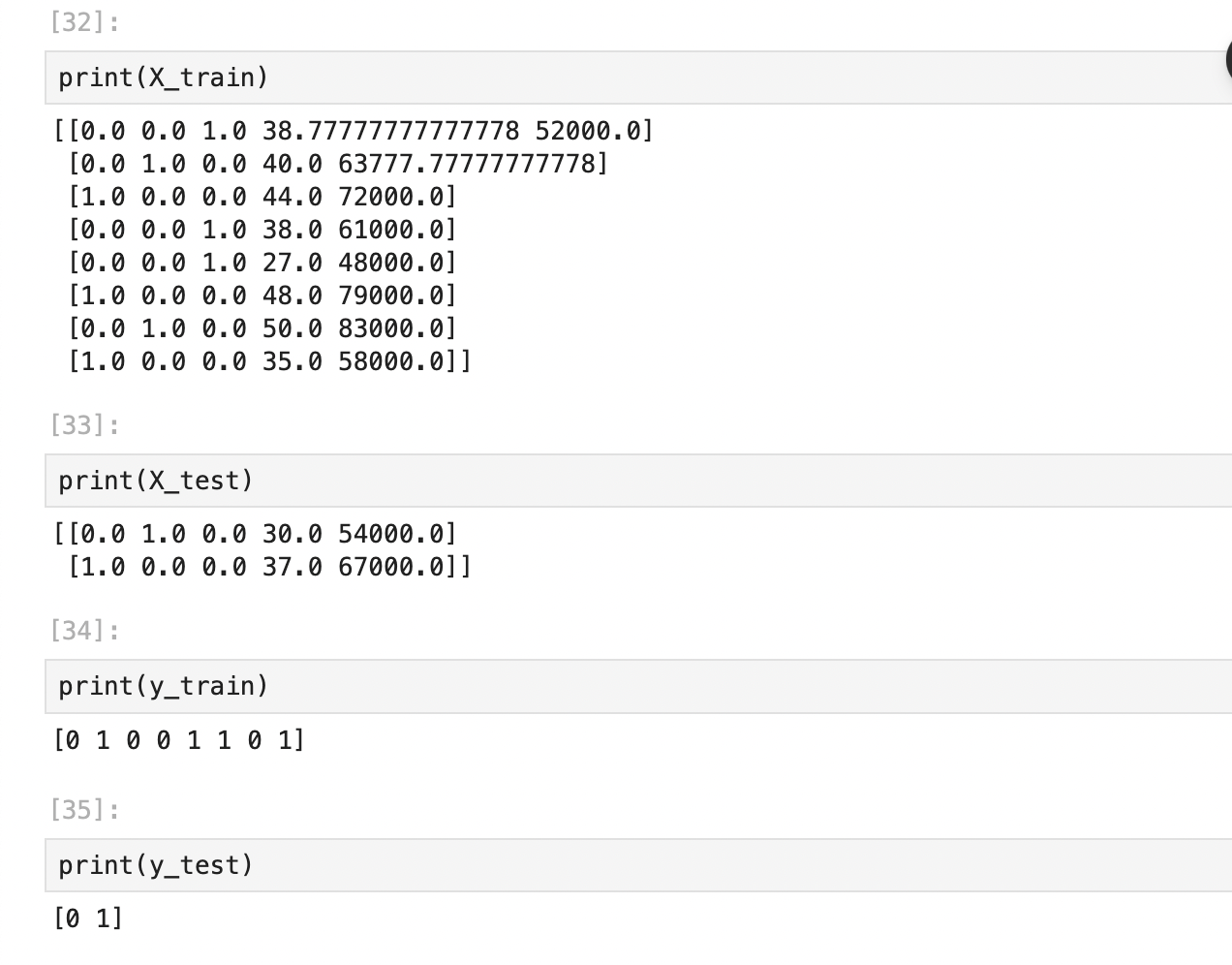
Feautre Scaling

https://www.kdnuggets.com/2020/04/data-transformation-standardization-normalization.html
- 표준화: 모든 원소의 평균을 뺸 것을 분자로 가지고 모든 원소의 표준편차를 분모로 갖는다.
- 표준화 적용 시 모든 feature의 범위는 -3~3으로 수렴한다.
- 정규화: 원소의 최솟값을 각 원소에서 뺀 것을 분자로 가지고 최댓값에서 최솟값을 뺸 값을 분모로 갖는다.
- 0 과 1 사이의 범위로 환원된다.
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
# Country에 대해서는 ont-hot Encdoing이 적용이 이미 되었기에 표준화를 할 이유가 없음.
# 모든 행(:), 열(3열 부터 끝까지)
X_train[:, 3:] = sc.fit_transform(X_train[:, 3:])
X_test[:, 3:] = sc.transform(X_test[:, 3:])scikit-learn에서 StandardScaler 클래스를 불러옵니다. 이 클래스는 데이터의 특성을 표준화하는데 사용됩니다.
훈련 세트의 특성 중 3번째 열부터 끝까지([:, 3:])에 대해 표준화를 수행합니다. fit_transform 메서드를 사용하여 평균과 표준 편차를 계산하고 동시에 데이터를 표준화합니다. 이 결과를 다시 X_train에 할당합니다.
테스트 세트에 대해서는 훈련 세트에서 계산된 평균과 표준 편차를 사용하여 동일한 표준화를 수행합니다. transform 메서드를 사용하여 표준화된 값을 계산하고, 이를 다시 X_test에 할당합니다.
