Learning Objective
1) On-premises vs cloud computing
2) IT infrastructure
3) How to make infrastructure
4) Mutable and immutable infrastructure
On-premises (On - prem )
특정 기업이나 조직이 본인의 컴퓨터, 서버 데이터 센터를 본인이 직접 구축/운영 하는걸 의미함.
필요한 소프트웨어를 그곳에 올리고 스스로 온전히 관리하는 것을 의미함.
본인이 직접 데이터 센터를 만들더라도 가령 부서나 사람들에게 필요할 때 빌려줄 수 있는 시스템은 퍼블릭 클라우드와 비슷.
다만, 애초에 데이터 센터를 본인이 설립하고 운영/관리 하는것이 On-premise의 방점.
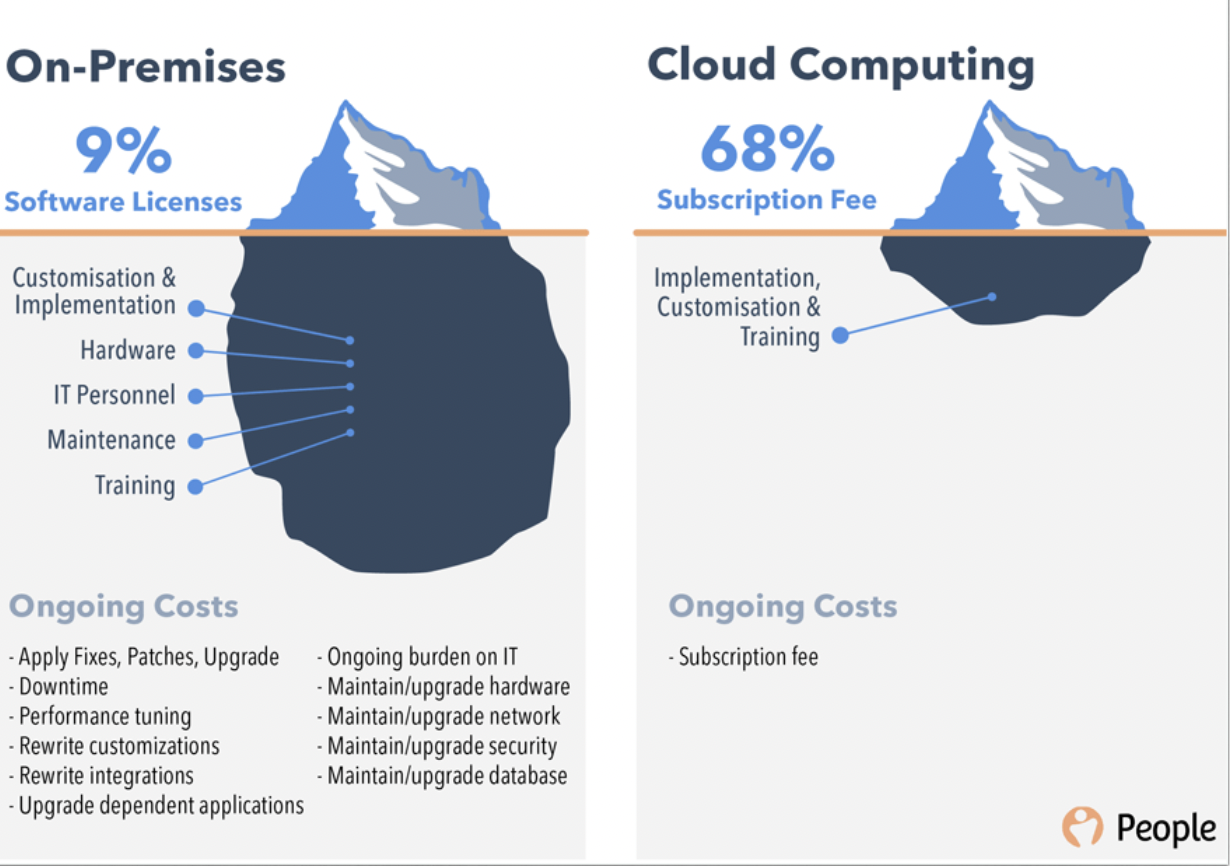
퍼블릭 클라우드의 경우 사용한 만큼 비용을 지불해야하니 구독료는 많이 청구될 수 있으나 시스템 밑단이 어떻게 구성되고 어떻게 운영해야 할지 사용자 입장에서 고민할 필요가 없음.
하지만 On-premises 같은 경우 그림과 같이 직원들 교육비, 유지비, 하드웨어, 관리자 고용 등에 대한 고려가 필요함.
On-Premises VS Cloud Servers

Source: https://medium.com/@routdeepak/a-data-engineers-perspective-on-iac-51705fa670d9
왼쪽의 경우 온프레미스의 방식. 사용자가 직접 컴퓨터를 구입하고 연결시키는 모든 과정을 도맡아 함.
즉, 자신만의 컴퓨터가 구축되었다고 믿을 수 있는 여지가 크기에 서버에 대한 높은 호감도가 생성될 것.
하지만, 이러한 서버가 기하급수적으로 늘어날 경우 서버에 이름을 어떤식으로 붙일 수 있을까?
결국 이런식으로 사랑스러운 시각으로 네이밍을 하는것이 애로사항으로 발생할 수 있음.
왜냐하면 자신의 서버가 다른 서버에 비해 유니크하고 특별하길 바라지만 서버는 단순히 도구에 불과함.
이에 반해 cattle model의 경우 정이라고는 없는 단순히 나의 목적을 이루기 위한 수단으로서의 서버다.
CPU가 필요 시, 루시,제우스,키티 등 특정한 서버가 필요하다고 말하는 것이 아니라 인텔CP i7, 3G HZ 옥탈코어 등과 같이 디테일하고 구체적으로 요구할 것이다.
우리는 컴퓨터를 단순히 일꾼으로서 바라봐야 하며 worker1, worker2, worker3 와 같이 네이밍 할 것이다.
Cloud Models
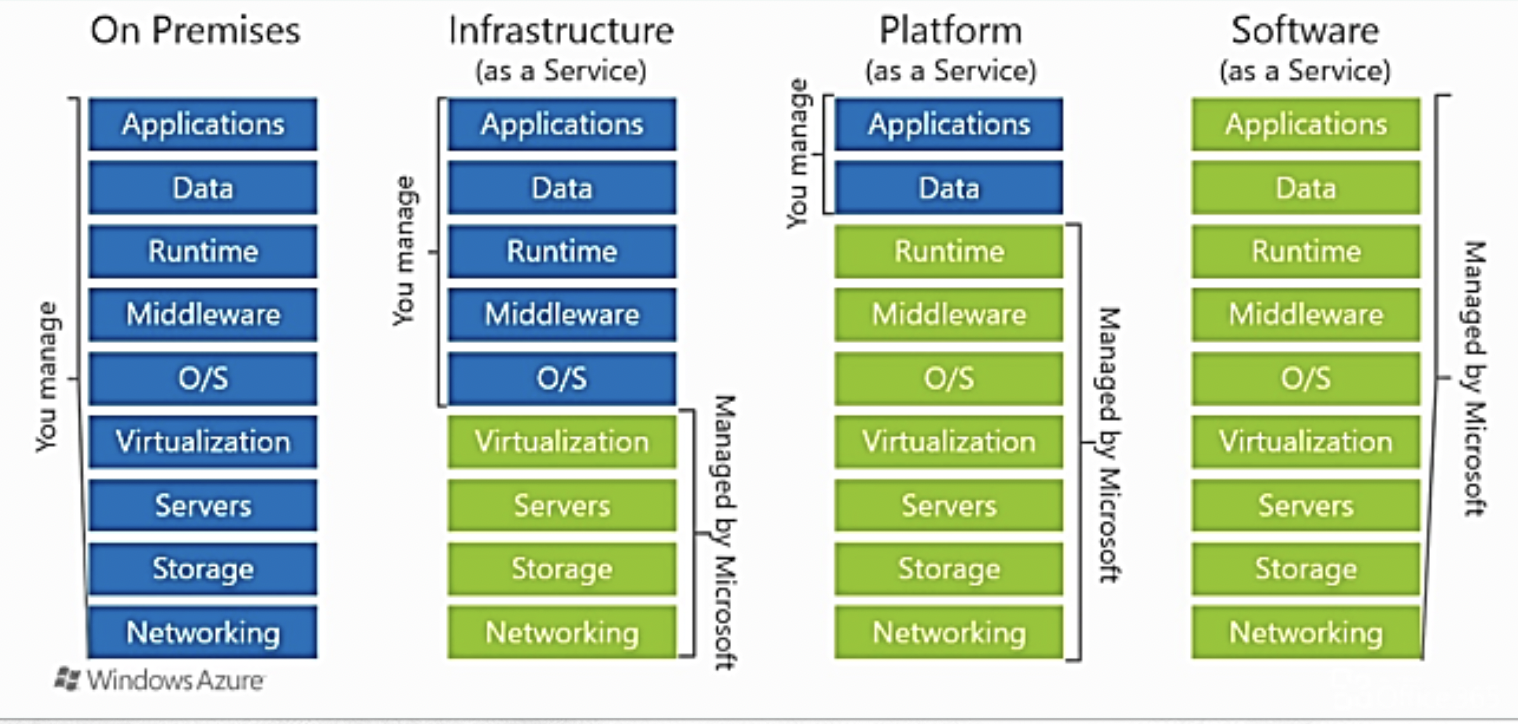
초록색 부분이 내가 빌려쓰는 부분.
IaaS, PaaS, SaaS는 퍼블릭 클라우드를 빌려쓰는 걸 전제로 어디 범위까지 빌려쓰느냐를 정하는 것.
IaaS -> 가짜 기계가 운영될 수 있는 근본적인 인프라 ( CPU, Storage, Networking 등) 를 빌려주고 그 위에서 운영되어야 하는 O/S를 비롯 어플리케이션은 직접 만드는 것.
On-premise의 경우 장비를 구입해 서버 구축하고, 네트워크로 서버끼리 연결하고, 가짜 기계를 비롯 OS, 미들웨어, 런타임 등 모든것을 본인 스스로 만들어야 하니 해야할 일이 많음.
Infrastructure

보통 인프라라고 하는 경우, 하드웨어와 네트워크 그 위에 올라가는 운영체제 그리고 OS 위에서 사용자가 만들고자 하는 어플리케이션 생성에 도움을 주는 미들웨어를 뜻함.
Server
1) CPU (중앙 처리 장치)
-> 프로세서. 소프트웨어가 돌아가기 위한 하드웨어로서의 프로세서.
2) Memory (RAM)
-> 컴퓨터 동작에 있어 운영체제와 소프트웨어가 운영되거나 빠르게 처리해야하는 데이터들이 들어가 있는 곳이 메모리
3) Storage (보조 기억 장치)
-> 전원이 꺼져 있을 때 데이터를 저장하는 장소. (HDD, SSD)
Web Server
웹 서버란 클라이언트 요청 시, 요청하는 데이터를 반환.
클라이언트가 처리를 원하는 요청을 한다면 전달받은 정보를 기반으로 프로세싱 후 전달 가능.
근본적으로 웹서버를 가능하게 하는 기술은 HTTP 프로토콜.
HTTP가 가장 많이 전달하는 파일 형태는 HTML.
Database Server
대규모 데이터를 전용의 소프트웨어가 관리.
필요할 때 마다 데이터를 합칠 수도, 저장할 수도, 찾아달라고도 할 수 도 있음. ( DBMS )
SQL server
Structured Query Language.
구조화된 데이터를 쿼리 (질의어) 를 통해 관리.
컬럼 / 로우로 이루어짐 (테이블 형태)
What is NoSQL ?
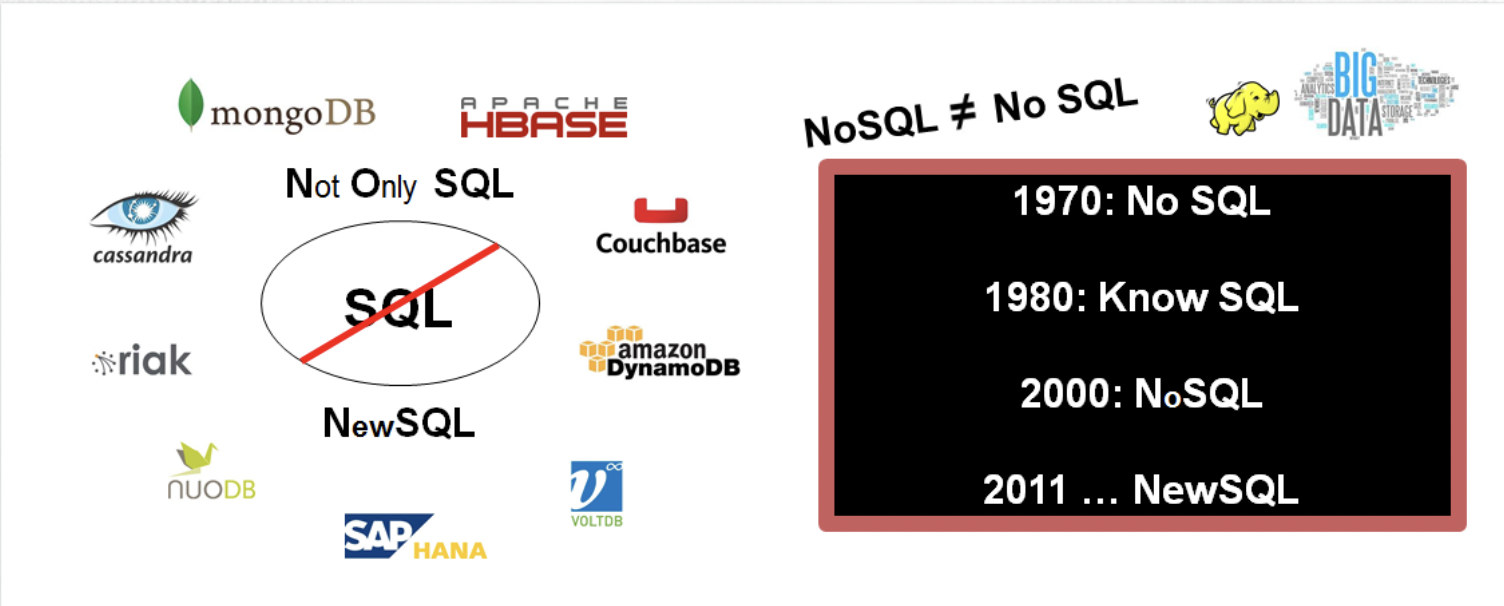
Source: https://biguru.files.wordpress.com/2014/09/nosql.png
{kind=link}
SQL 같은 경우 엑셀 차트와 같은 테이블 형태로서 존재.
NoSQL은 그래프와 같은 형태.
따라서 비정형 데이터라고함. (사실 형태는 있지만 2차원 테이블 형태는 아닌 것 )
최근에는 NoSQL 역시 SQL의 성질을 포함하는 부분이 많아서, No SQL이 아닌 Not Only SQL 의 의미로서 전통적인 SQL을 기반으로 아닌것도 확대 포함 한다는 의미로서 사용.
Operating System (OS)
.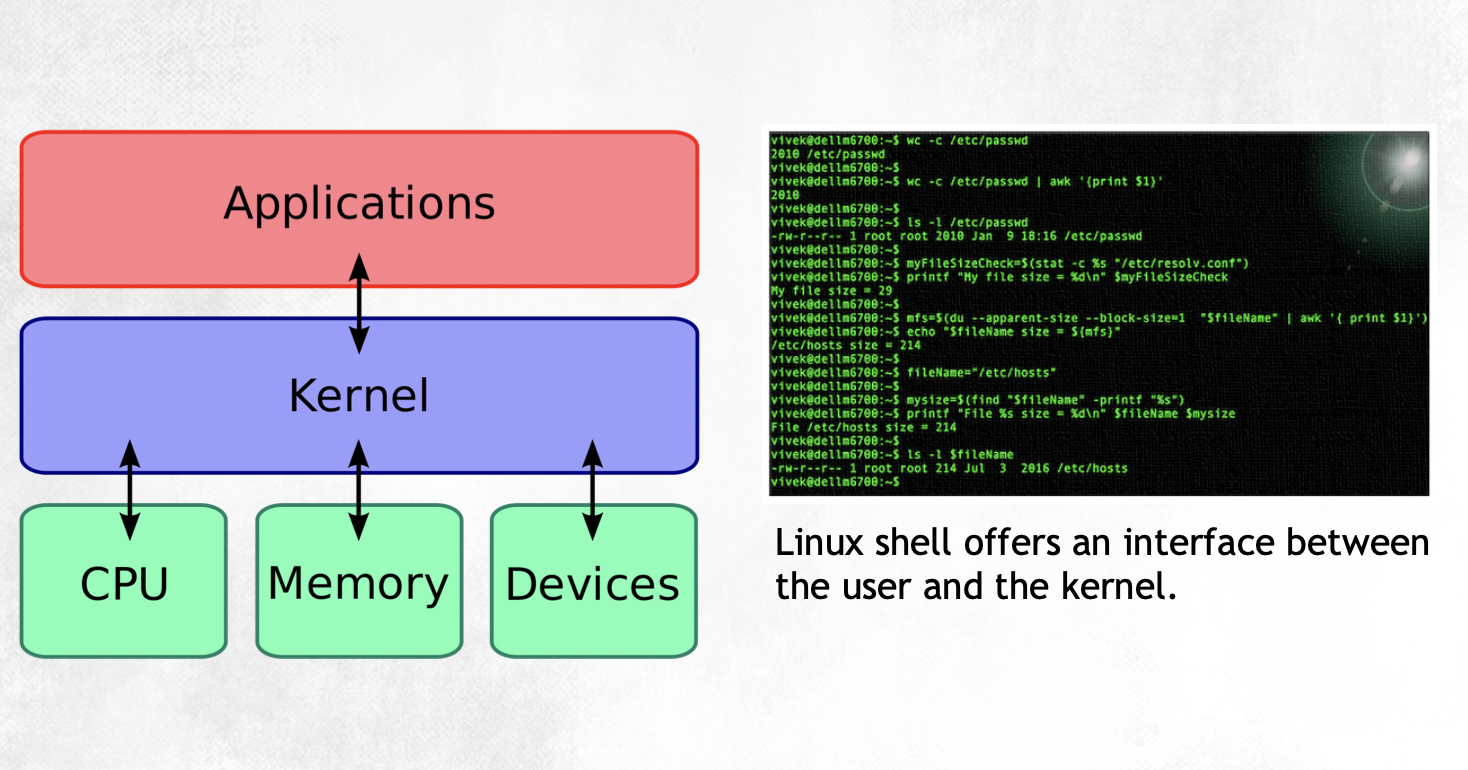
Source: https://blog.digilentinc.com/demystifiying-the-linux-kernel/
MiddleWare
어플리케이션과 운영체제 가운데 사이.
어플리케이션이 필요하지만 운영체제가 제공하지 않는 기능을 제공함.
개발에 사용하는 라이브러리 , 프레임워크 등.
운영체제 보완 개념.
Architecture
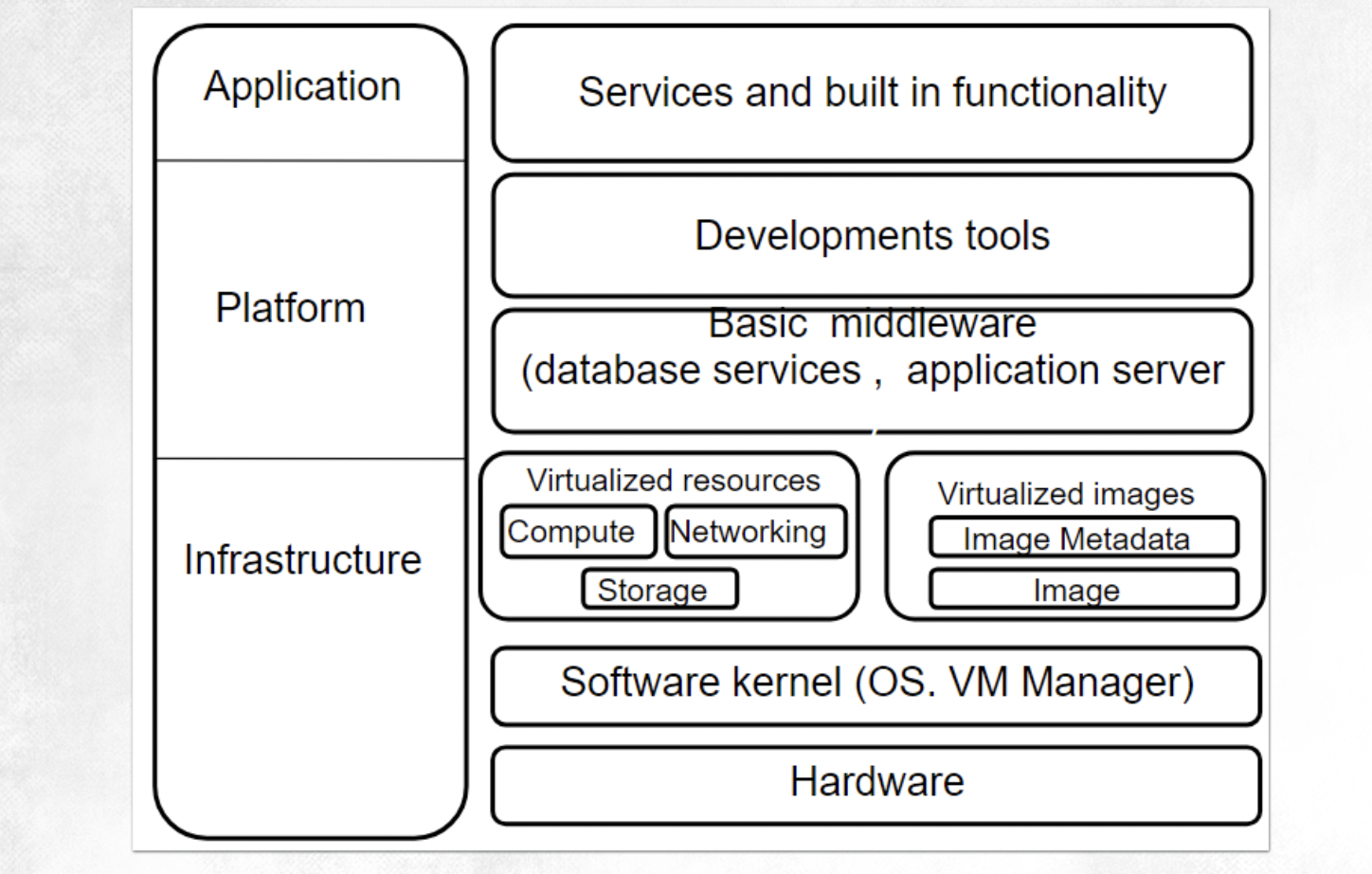
미들웨어 : 데이터베이스 서버, 웹 서버 설치형 프로그램 (아파치 , nginx)
Drawbacks to this Process
직접 온프레미스 환경 구축 시, 나에게 필요한 컴퓨터를 사야함.
하지만 내가 필요한 컴퓨터는 무엇이지 ?
데이터 센터에 있는 rack에 해당 컴퓨터가 꽂히나?
전원은 충분한가?
또한 내가 필요한 컴퓨터가 돈으로 살 수 없으면 만들어서 주문 제작 해야함.
즉, 하드웨어를 구매하는건 복잡하고 고민스러운 일.
이렇게 환경관리를 하기 위해서는 시간, 사람, 돈에 대한 비용이 많이 듬.
또한 이러한 하드웨어가 있을 만한 공간 (부동산) 이 필요함.
Infrastructure as Code ( IaC )

서버위에 무언갈 올릴 때 굉장히 작은 것을 올릴 것.
대부분 컴퓨터 하나 위에 소프트웨어를 개발함에 있어 컴퓨터 하나가 모든 일을 수행하도록 했음 ( 우리가 가진 건 컴퓨터 1대 이므로 )
하지만, 수천 수만대의 CPU를 사용할 수 있다면 굳이 내가 한 컴퓨터에서 모든 일을 수행시킬 필요가 없음. 굉장히 작은 일의 단위로 쪼개 수행하도록 할 수 있음.
따라서 우리가 가용 가능한 CPU가 무수히 많으니 극단적으로 작은 함수 1,2개 정도만 특정 CPU 위에서 돌리고 해당 함수가 사용될 일이 많아지면 CPU 개수를 늘릴 수 있음. ( 마이크로 서비스 )
무수히 많은 서버가 있다라는 것이 포인트가 아닌 이렇게 무수히 많은 서버를 이용해서 우리가 만들고자 하는 소프트웨어 설계를 어떤식으로 이뤄내고 관리할 것인지에 대한 문제.
또한 내가 급박하게 소프트웨어를 개발하고 서로 다른 환경의 서버에게 배포 시, 일일이 환경을 맞춰주는 것은 불가능하므로 개발자가 특정 환경을 요구하면 밑에 있는 인프라는 요구시 되는 환경을 구축해줌.
물리적으로 존재하는 인프라를 어플리케이션이 필요할 때 필요한만큼 할당받고 환경설정하고 운영하고 반납하는 일련의 과정을 사람의 개입없이 자동화 하는 것.
개발자는 어떤 하드웨어에서 운영될지, 어떤 용량만큼의 스토리지가 제공되는지 등의 고민 없이 본인이 필요한 환경을 기술하고 해당 환경 위에서 프로그램을 운영할 것이라고 선언만 한다면 데이터 센터는 해당 환경을
제공함.
Benefits of Infrastructure as Code
1) Speed and Simplicity
2) Configuration consistency
3) Minimization of risk
4) Increased efficiency in software development
5) Cost savings
Mutable Infrastructure
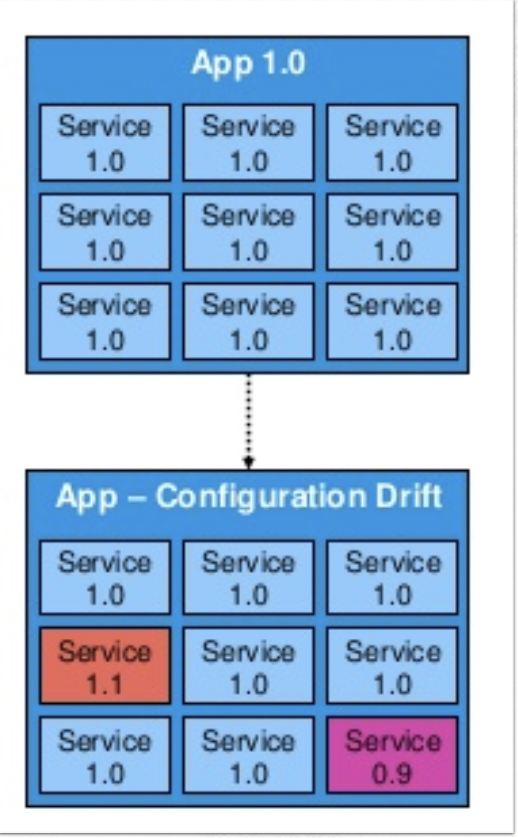
Source: https://www.slideshare.net/LiorKamrat/infrastructure-as-code-getting-started-concepts-tools
그림과 같이 1.0, 1.1, 0.9 버전의 각기 다른 서비스가 존재.
서버 증설이나 소프트웨어 관리적 차원에서 복잡해지고 운영이 어려워짐
Immutable Infrastructure
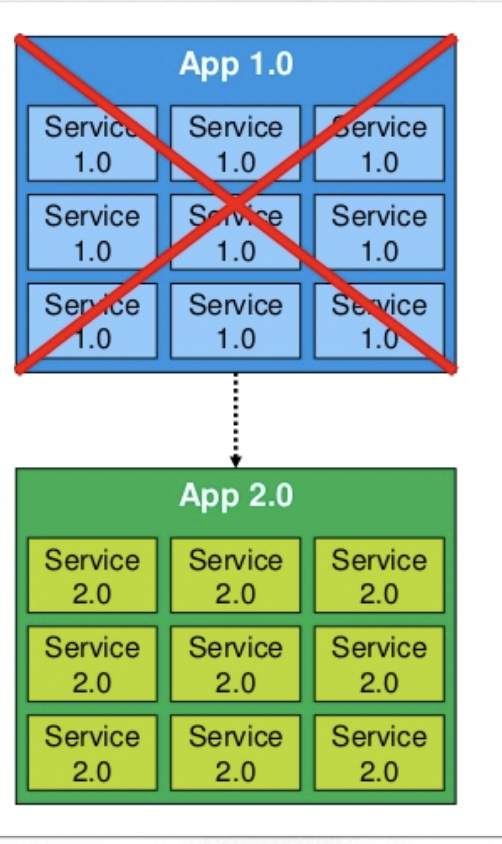
Source: https://www.slideshare.net/LiorKamrat/infrastructure-as-code-getting-started-concepts-tools
mmutable infrastructure(불변 인프라스트럭처)는 인프라스트럭처 자체를 불변으로 관리하는 개념.
서버나 인프라스트럭처를 일회성으로 구성하여 더 이상 변경하지 않고, 필요한 경우에는 새로운 인프라스트럭처를 구성하고 이전 인프라스트럭처를 버리는 방식으로 운영하는 것을 말합니다.
이러한 불변 인프라의 가장 큰 장점은 관리에 대한 부분이다.
계속해서 소프트웨어의 버전을 추적할 필요가 없어짐.
한 서비스에 대해서는 하나의 이미지, 하나의 소스코드만 유지하면 되므로 서로의 코드가 복잡하게 꼬여 제어불가능한 상태를 미연에 방지함.
안정성이 높아짐: 불변 인프라스트럭처는 변경이 일어나지 않기 때문에, 인프라스트럭처가 안정적이고 예측 가능.
서버나 인프라스트럭처의 변경으로 인한 문제나 에러를 방지할 수 있습니다.
보안성이 높아짐: 불변 인프라스트럭처는 변경이 일어나지 않기 때문에, 외부에서의 침입이나 변조를 방지할 수 있습니다.
배포가 용이함: 불변 인프라스트럭처는 이미 빌드된 상태로 존재하기 때문에, 배포가 용이.
새로운 인프라스트럭처를 띄우기만 하면 되기 때문에, 배포 시간이 줄어들고 문제 발생 시 롤백도 쉬움.
확장성이 용이함: 불변 인프라스트럭처는 이미 빌드된 상태로 존재하기 때문에, 필요에 따라 새로운 인프라스트럭처를 띄워서 확장 가능.
자동화에 용이함: 불변 인프라스트럭처는 변경이 일어나지 않기 때문에, 대부분의 작업 자동화 가능.
인프라스트럭처의 운영이 쉬워지며, 인프라스트럭처 관리에 드는 비용과 시간을 줄일 수 있습니다.
따라서, 불변 인프라스트럭처는 안정적이고 예측 가능한 시스템을 구성하고, 빠른 배포와 확장이 가능하며, 자동화에 용이하다는 장점을 가지고 있음.
