ref : https://www.youtube.com/watch?v=qzHjK1-07fI
1. What circumstances : E - commerce Data
- Aggregate from Multiple Domain Data
- Change Frequently and Instantly
- The more Displayed, The more Sales
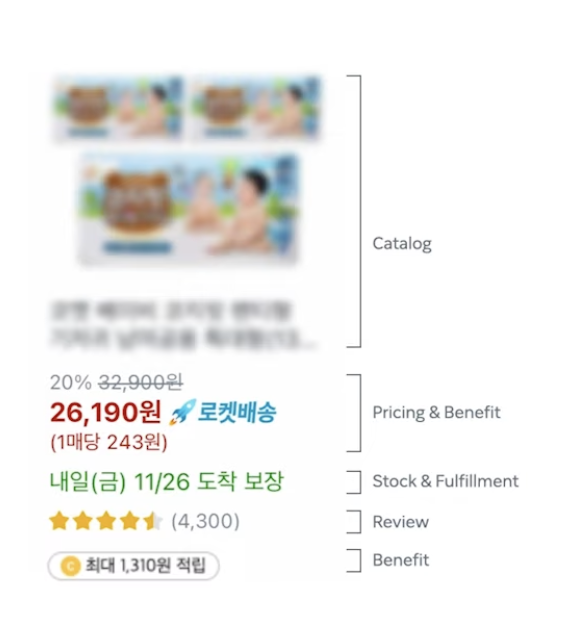
위의 이미지에서는 한 화면안에 Catalog, 가격, 도착예정일, 리뷰수, 평균평점 등 복합적인 데이터가 한번에 뿌려지고 있다.
해당 이미지 기준으로는 4300개의 리뷰가 있으니 4300개의 모든 평점을 더하고 해당 갯수로 나누어주면 평균 별점을 알 수 있을 것이다.
4300개의 데이터열을 읽는것도 많은데, 평균 계산까지 더해지고 상품 수는 해당 이미지의 상품만 있는것이 아니기에, 부하 요소가 커진다.
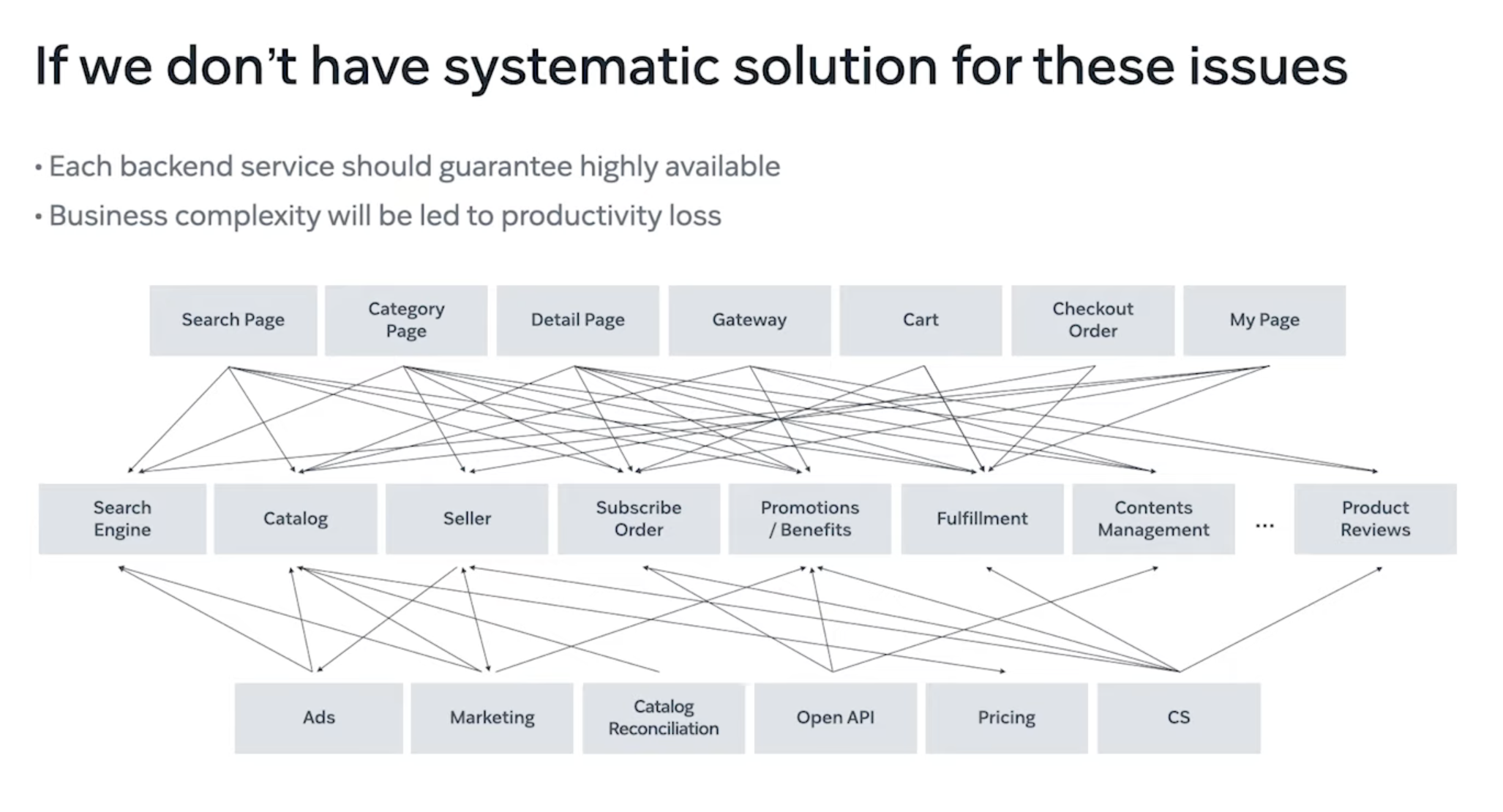
따라서, 약 100만명의 유저로 기준을 잡는다고 하면 100만명 모두에게 각각의 도메인에서 가져온 데이터를 뿌려줘야 한다면 각각의 백엔드 서버가 고가용성이 보장되어야 하며 공통으로 적용되는 비지니스 로직의 코드는 중복될 것.
따라서, 모든 페이지에서 공통으로 사용되어야 하는 데이터와 비지니스 로직을 처리하는 마이크로서비스가 필요한 이유.
결론적으로 쿠팡 코어 서빙 플랫폼은 모든 페이지에 고가용성, 저지연 데이터를 서빙하는 것이 목표 !
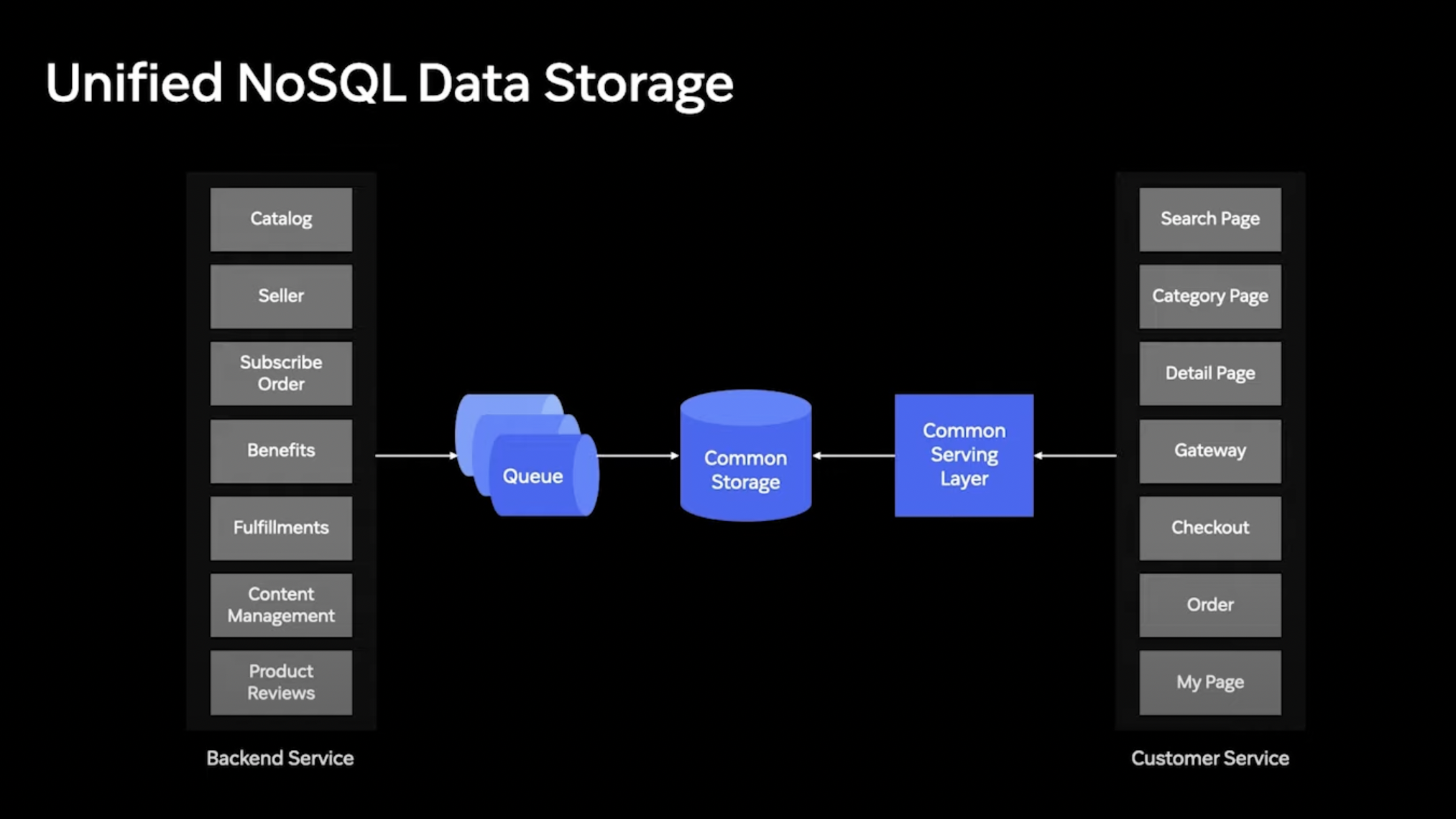
따라서, 모든 데이터를 한곳에 집중시켜 모으는 일종의 코어 서빙 레이어 구축
코어 서빙 레이어는 쿠팡에서 화면 구성에 필요로 하는 모든 데이터와 비즈니스 로직을 서빙한다.
그러한 데이터는 Common Storage(NoSQL) 로부터 받아서 서빙 한다.
그래서, 코어 서빙 레이어가 각각의 도메인을 일일이 예민하게 바라보고 있는것이 아닌, 각각의 도메인에서 데이터가 변경되면 큐에 보내고 해당 데이터를 NoSQL에 저장.
하나의 상품정보가 있다면, 각각의 필드가 다른 도메인에 의해 채워지는 것
하나의 비정규화된 커다란 테이블에 저장.
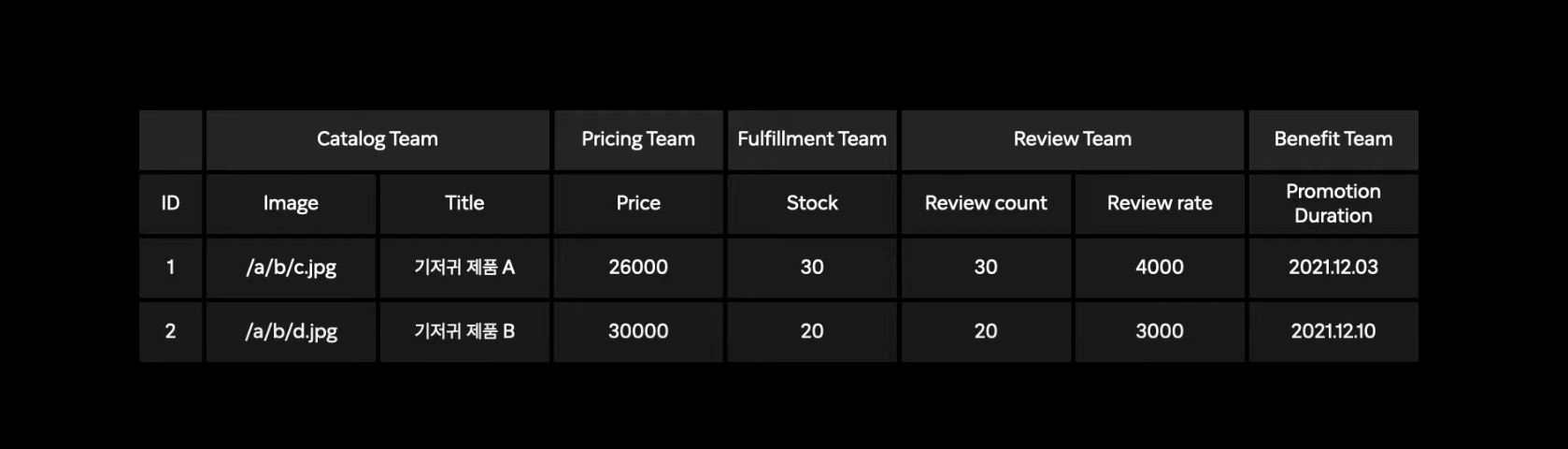
위의 이미지와 같이 Catalog Team에서는 이미지와 Title을 채우고 Pricing Team에서는 Price를 채우는 형식이다.
이렇게 하는 이유는 Read-Througput 때문.
NoSQL을 사용함으로써 트랜잭션 없이 언젠가는 반영되는 Eventual Consistency Model 사용.
한번의 Read 로 모든 도메인의 데이터 수취 가능 !!!
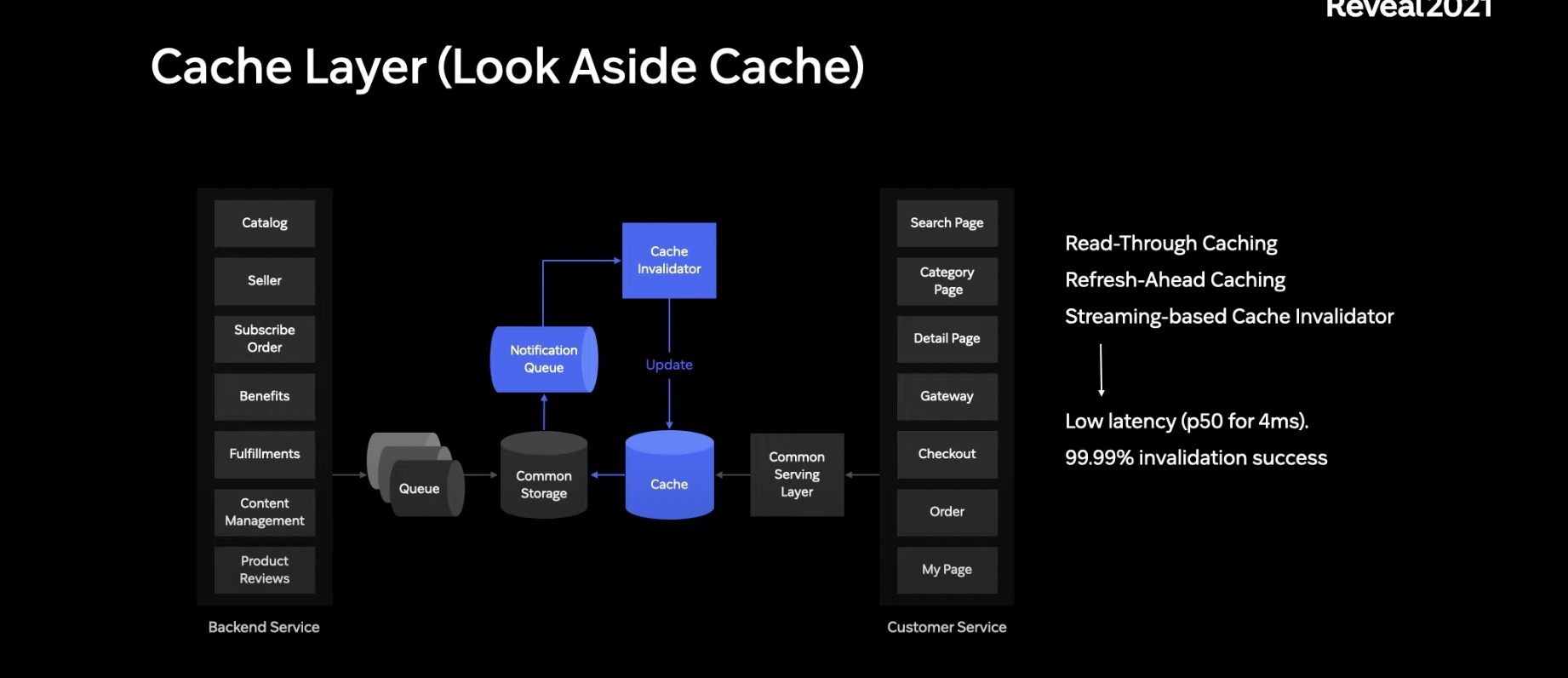
Unified 된 데이터 스토리지를 통하여 여러 도메인으로 뻗치는 I/O 수행을 줄여 서버 부하를 줄이고 또 Common Storage로 Read - Throughput 이 처리 가능 했지만, 더 많은 데이터 처리를 위해 Cache Layer를 따로둠.
Common Storage는 Persistent한 성격이 강하다면 Cache Layer는 이런 부분을 신경쓰기 보다는 높은 뜨루풋, 저지연에 집중
고성능 Cache Layer를 통해 10배 높은 뜨루풋과 1/3의 레이턴시로 줄임
캐시 레이어 사용시, 저지연이 가능하지만 주의할 점 있음 !!!
Storage에 반영된 데이터가 캐시에 반영되지 않아 캐시에 있는 "과거 데이터" 로 서빙되는 상황
타 도메인에서 가격을 변경하여 스토리지에 저장은 됬는데 캐시에는 반영되지 않는 것!!
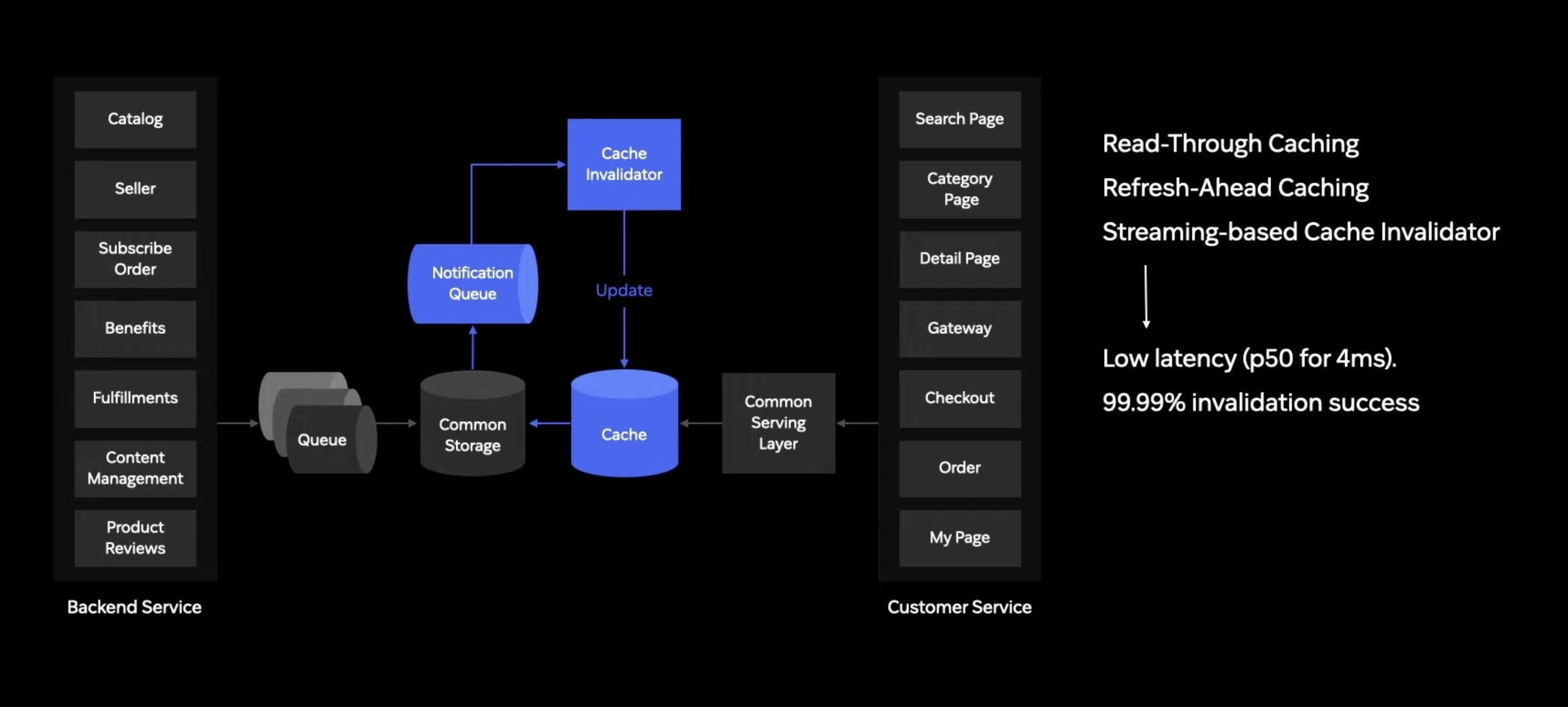
이러한 문제를 해결하기 위해 Cache Invalidator 가 존재
데이터가 변경될 때 마다 해당 데이터들은 Notification Queue에 보내지고 이 시그널들을 활용해 케시에 있는 데이터가 최신의 상황인지 확인 혹은 아니라면 최신데이터로 변화시킴.
이러한 메커니즘을 통해 Common Serving Layer에서 제공되는 99.9퍼센트의 데이터는 스토리지와 일치하는 최신의 데이터로 서빙됨.
분 단위로 수행하는 Cache Invalidation을 통해 정확성을 매우 높인다.
하지만, 가격,배송장소,재고와 같이 초단위로 변경되어야 하는 어떻게 처리...?
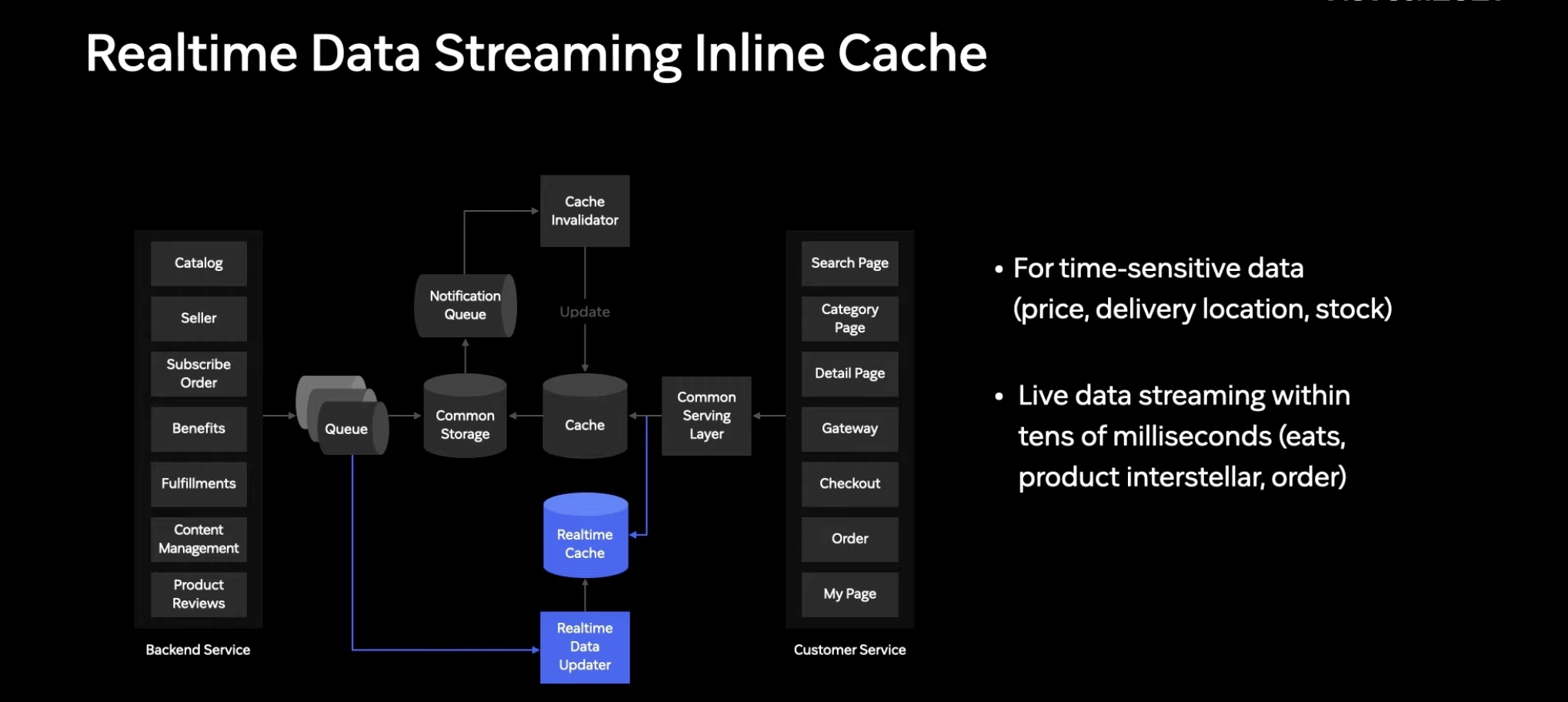
가격이나 할인정보가 바뀐후에 이전 정보를 보여주면 고객경험 수준이 낮아지고 회사에도 손해가 끼쳐짐.
특히 쿠팡은 로켓배송 상품은 실제로 배송되기 때문에 각 지역별 재고와 배송처리 능력에 따라 상품의 배송시간을 바꿔야 할 수도 품절을 시켜야 할 수 있음 -> RealTime Data Streaming 도입 이유
RealTime Data Streaming은 다른 도메인에서 변경된 데이터를 큐에서 읽고 별도의 캐시에 바로 씁니다.
커먼 서빙 레이어는 캐시와 리얼 타임 캐시를 "동시에" 읽고 보다 최신의 데이터를 해당 데이터로 서빙할 수 있게끔 설계
하지만 제일 중요한 것이 빠짐!!! 바로 가용성 !!!
가용성이란, 고객 경험에 직접적으로 연결되는 장애를 최소화 하는 것
예를들어 Real Time Cache에 장애가 나는 경우 페이지 자체를 서빙하지 못하는 것 보다, 최신의 데이터를 제공하지 못하는 쪽을 선택하는 것이 고객경험으로는 더 나을 수 있는 선택.
이러한 목표를 달성하기 위해 코어 서빙 레이어는 모든 I/O가 일어나는 곳에 장애가 일어날시, 해당 장애를 아이솔레이션 시켜 Cascading 되지 않도록 해야함.
코어 서빙 레이어는 Circuit Breaker 라는 기술을 통해 해당 컴포넌트의 장애를 고립시키고 필요시 수동으로 해당 컴포넌트로 가는 I/O들을 끌 수 있도록 설계되어 있음.
가용성 측면에서 또 다뤄야할 중요한 개념 : CSP
Critical Serving Path
쿠팡에는 굉장히 많은 페이지가 존재하며 그 중 고객경험에 중대한 경험을 끼치는 페이지가 존재
홈, 검색, 주문 페이지 등..
주문에 직접적인 영향을 미치는 페이지
이 페이지 중 하나라도 내려가면 고객 경험이 크게 낮아짐
이러한 중요한 페이지만을 다루는 클러스가 존재
-> CSP Cluster
그리고 그 외의 페이지만을 모아놓은 클러스터
-> NCSP Cluser
이렇게 분리한 이유는 서로의 독립적인 클러스터는 서로에게 영향을 끼치지 않음
NCSP 클러스터의 캐시가 문제가 일어나도 CSP Cluster에게 문제가 전가되지 않음.
또 CSP 클러스터에 문제가 생기면 배포 없이 동적으로 CSP에 해당하는 모든 페이지가 NCSP Cluster를 바라보게 할 수 도 있음.
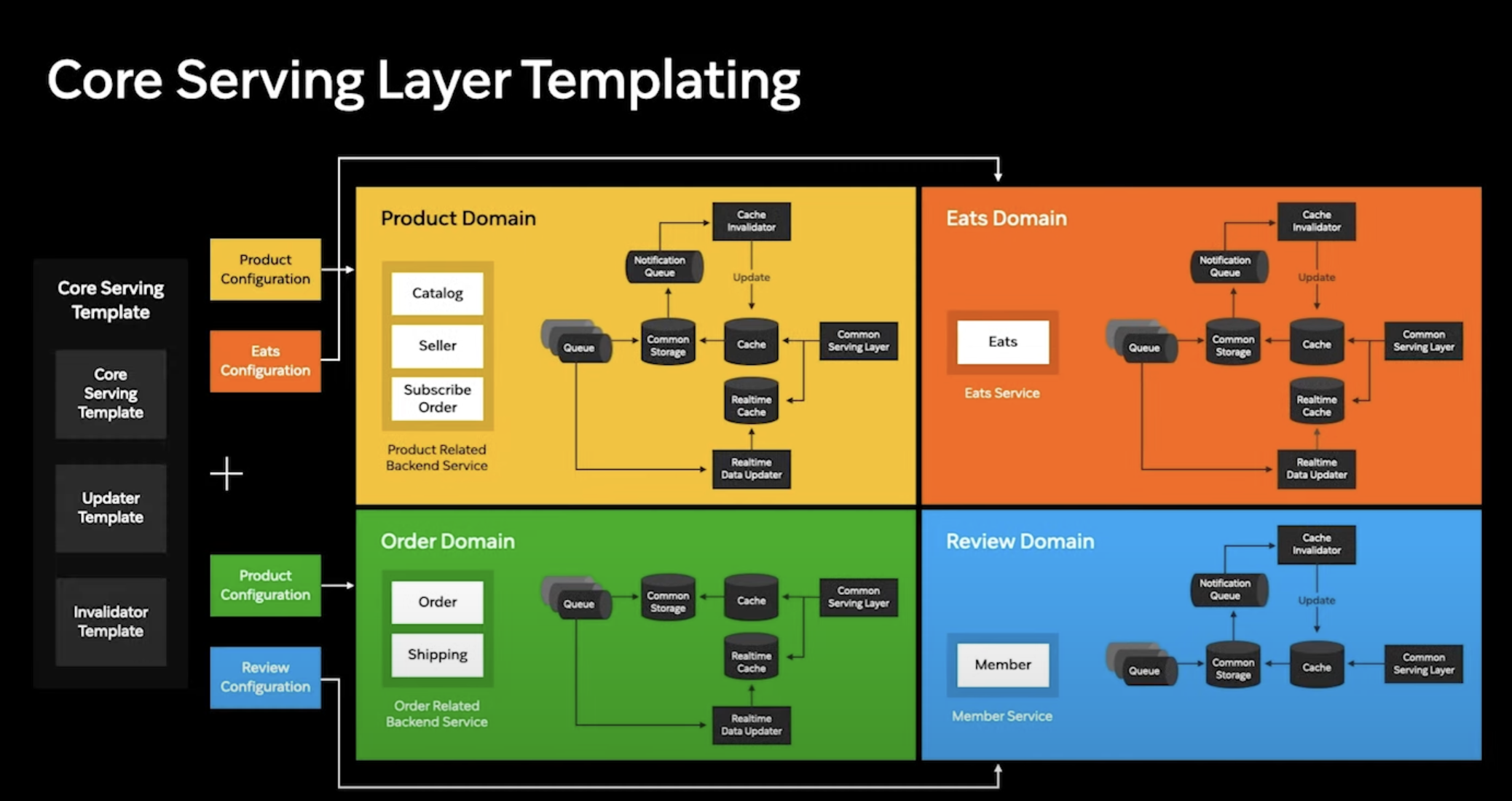
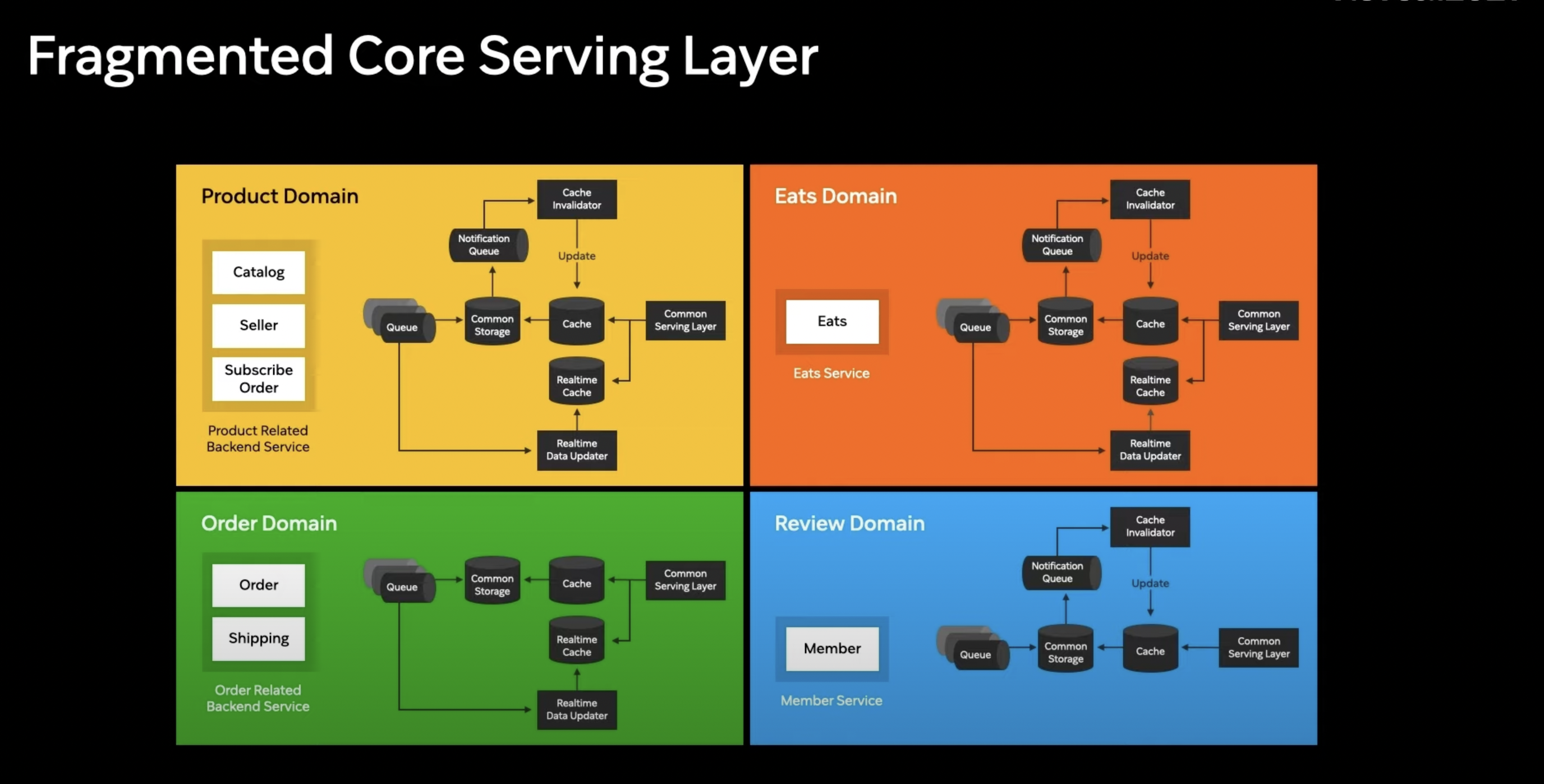
코어 서빙 레이어에는 상품 정보를 제공하는 도메인 뿐만 아니라 위의 그림과 같은 도메인들 역시 존재 (고가용성과 저지연이 요구되는 도메인)
만약 각각의 도메인이 구조는 같지만 다른 코드 베이스로 적용된다면 앞서 전략을 수행하기 위한 중복 코드가 증가
-> 관리 어려움
따라서 이러한 로직들을 쉽게 구성하기 위해 코어 서빙 레이어를 쉽게 만들어야함
코어 서빙 레이어를 쉽게 하기 위해 코어 서빙 레이어 템플릿을 만듦.
코어 서빙 템플릿은 기본적인 핵심 로직을 공유하고 Configuration에 의해 동작이 변경되는 Configuration as Code를 지향.
바라봐야 하는 Common Storage 주소, 캐시의 주소, 리얼 타임 캐시의 주소와 추가적으로 Configuration만 변경하면 새로운 도메인의 코어 서빙 레이어가 생성됨
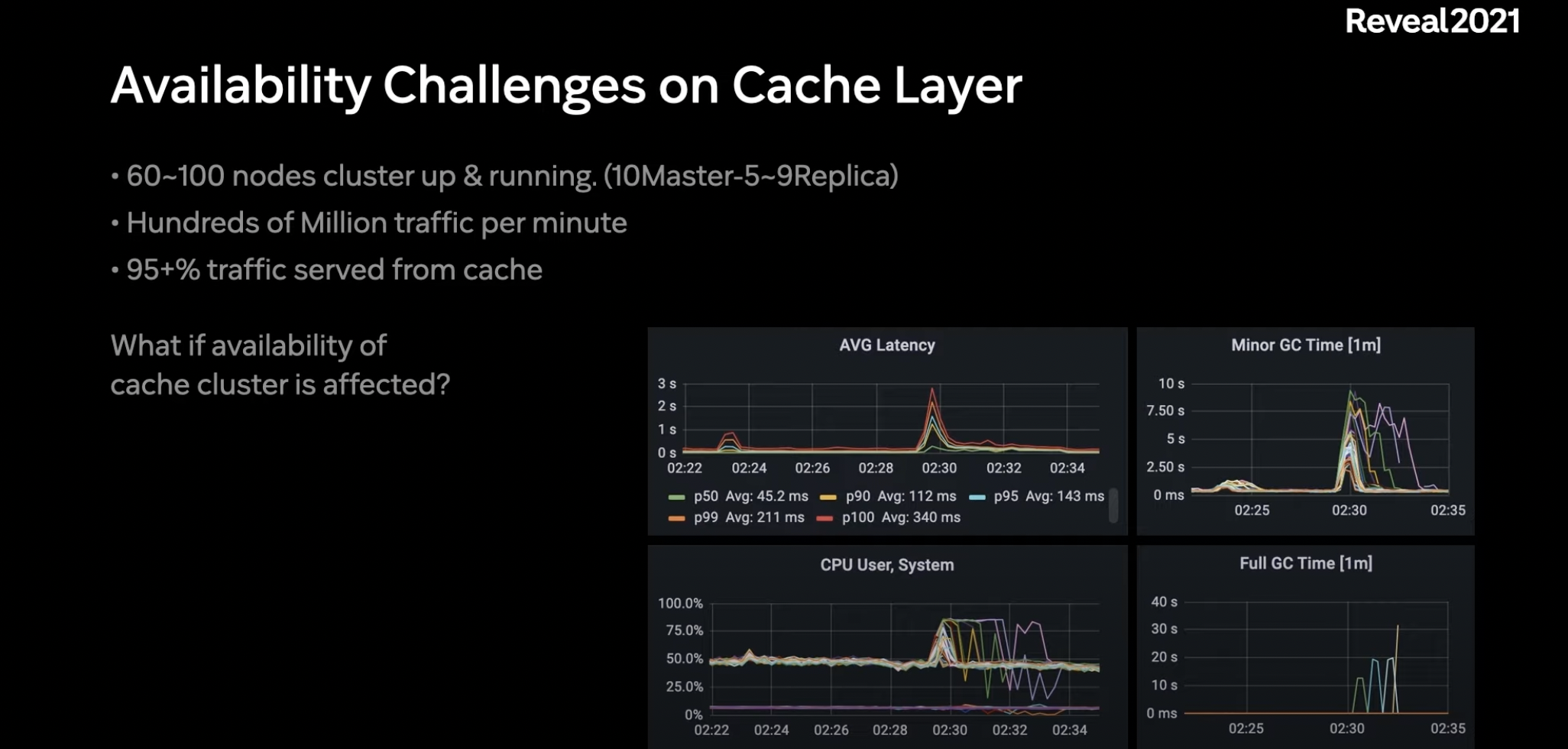
코어 서빙 레이어의 기술점 어려움 / 개선하기 위한 노력
- Avaiability -> 하드웨어,소프트웨어 문제
- Througput -> 서버의 처리량을 넘어서는 급격한 사용자 유입
Avaiability에 영향을 가장 크게 주는건 캐시 레이어
높은 뜨루풋 처리와 실시간 데이터 반영을 위해 2개의 캐시 클러스터 사용
트래픽이 많은 만큼 캐시 클러스터의 노드 갯수만 60-100대로 구성
분당 억대의 트래픽을 처리.
전체 트래픽 중 캐시와 데이터 스토리지 처리량을 비교해보면 95% 이상을 "캐시"에서 처리.
캐시 클러스터의 이용도가 높은 만큼 캐시 클러스터의 Availabilty가 전체 플랫폼 Availabilty에 많은 영향을 끼침.
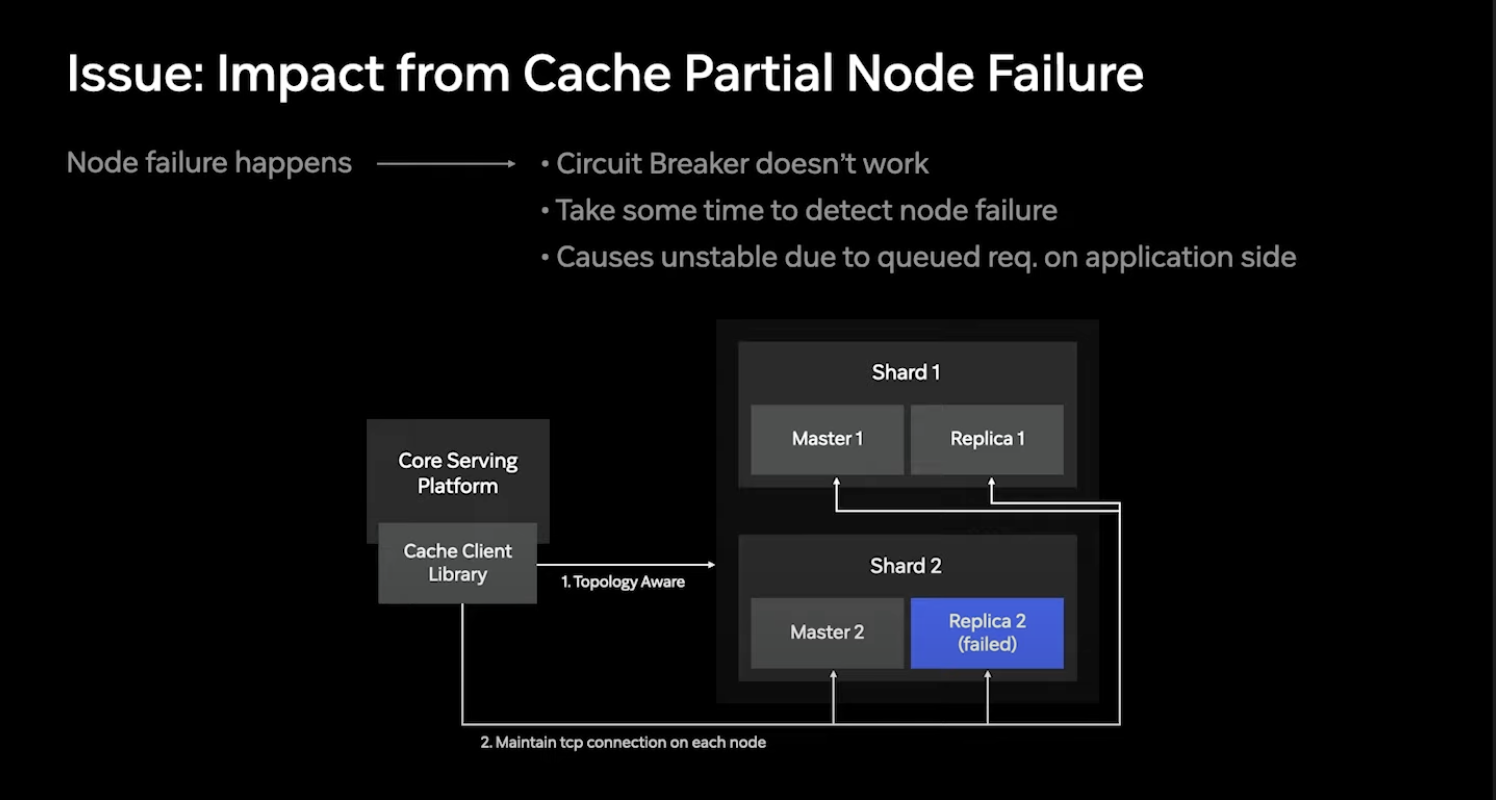
한 클러스터 내에서 포함되는 노드들의 갯수가 많다보니 개별 노드들이 다운되는 것은 흔한 현상
특정 노드들의 다운은 해당 노드들만의 문제이므로 Circuit Breaker만으로는 해결되지 않음.
캐시 클러스터는 빠르게 실패 노드들을 찾아서 클러스터 Topology를 변경해 주지만 이러한 도구 작업 에도 시간이 필요하고 그 시간에 처리되지 못하는 요청들은 타임아웃 혹은 내부 큐에 쌓임.
또한 클러스터 토폴로지 변경이 실제 사용되는 TCP 연결과 일치 하지 않아 다운된 노드로 트래픽이 계속해서 들어가는 현상 발생.
시스템 안정성을 높이기 위해 다운된 노드로 가는 트래픽을 빠르게 배제할 수 있는 해결책 필요
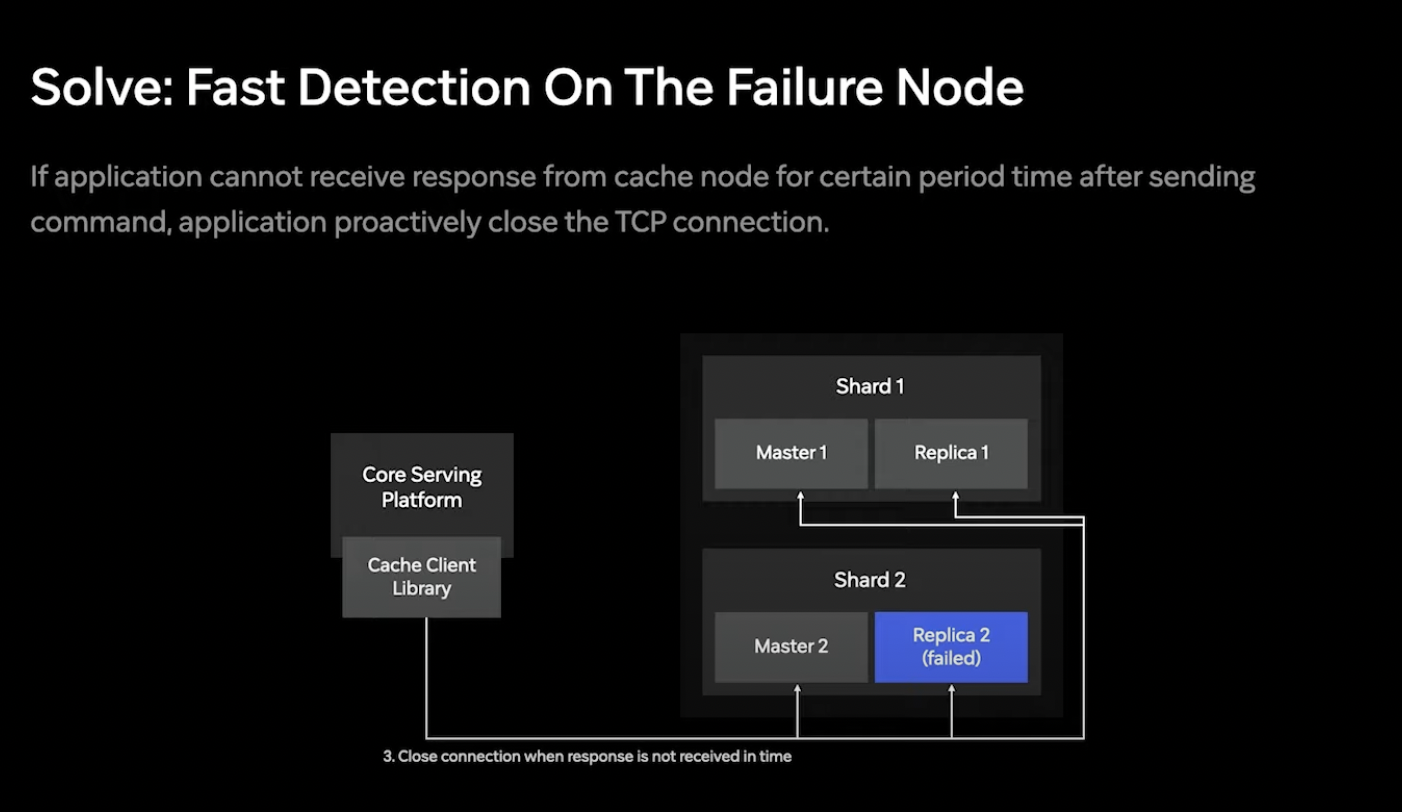
이를 위해 캐시 클러스터가 재공해주는 토폴로지 리프레시 뿐만 아니라 TCP연결의 응답이 빠르게 오는지 감시 !
일반적으로 캐시 레이어의 응답속도는 수 ms 정도여서 1초동안 응답이 오지 않는 connection은 문제가 있는 것으로 판단하고 자동으로 close 하게 설정.
이로 인해 실패한 노드들을 빨리 색출할 수 이었고 안정성이 높아짐.
높은 트래픽은 다운된 노드가 캐시 클러스터로 다시 recovery하는 과정에도 문제를 발생시킴.
다운된 노드가 다시 뜨면 full sync 과정을 거쳐 다시 클러스터로 들어오게됨.
이떄 클러스터 마스터 노드는 풀싱크 과정중에 들어오는 write command 들을 buffer에 저장하게 되는데 캐시로 들어오는 높은 트래픽은 버퍼보다 더 많은 write command 발생시켜 recovery, full sync를 실패하게 만듦.
해결책: full sync 과정동안 Write command 수와 사이즈를 예상하여 적정한 buffer사이즈 찾음
예측지에 따라 버퍼 사이즈를 주고 여러번 테스트 했지만 쉽게 해결되지 않음.
그러던중, full sync 과정에서 에상된 write command 보다 더 많은 write command가 발생한다는걸 눈치챔.
예상보다 많은 write는 full sync과정에서 새로 뜬 replica들이 empty data set으로 데이터를 서빙하는 것이 문제.
이 현상이 캐시 클러스터에 데이터가 없다고 "인식"시켜 write command들을 급격하게 증가시킴
이부분의 순환고리를 끊기 위해 replica의 데이터 사이즈나 상태정보를 이용하여 정상적으로 서빙할 수 있는 replica가 아니면 트래픽 유입 차단.
이를 통해 급격한 write command 증가를 제거, full sync 실패 과정 해결.
또다른 문제로는 캐시 클러스터가 크다 보니 각 노드별 수용하는 트래픽이 불균형.
노드 별 처리량 데이터가 5~10배 차이가 나는 경우도 있고 트래픽이 차이나는 만큼 CPU 사용률도 노드별로 제각각.
이러한 문제로 인해 캐시 클러스터의 크기를 정해야 할 경우 트래픽을 가장 많이 수용하는 노드를 기준으로 CPU를 할당해야 했고 불필요하게 과할당된 노드가 존재하게 됨.
이러한 불균형의 원인 : 캐시 클라이언트
기존의 캐시 클라이언트에서는 최초 연결시 각 샤드 별 가장 빠르게 응답하는 노드 선택 후 통신.
해결점 : 커넥션 모드를 조종하여 최초 커넥션시 연결되는 고정된 노드가 아닌 요청 마다 랜덤으로 가장 빠른 노드를 선택하게함. (분산처리)
