Redis as cache
- 단순한 key-value 구조
- 인메모리 데이터 저장소(RAM)
- 빠른 성능 (평균 작업속도 < 1ms, 초당 수백만 건의 작업 가능)
캐싱 전략
읽기 전략 (Look - Aside)
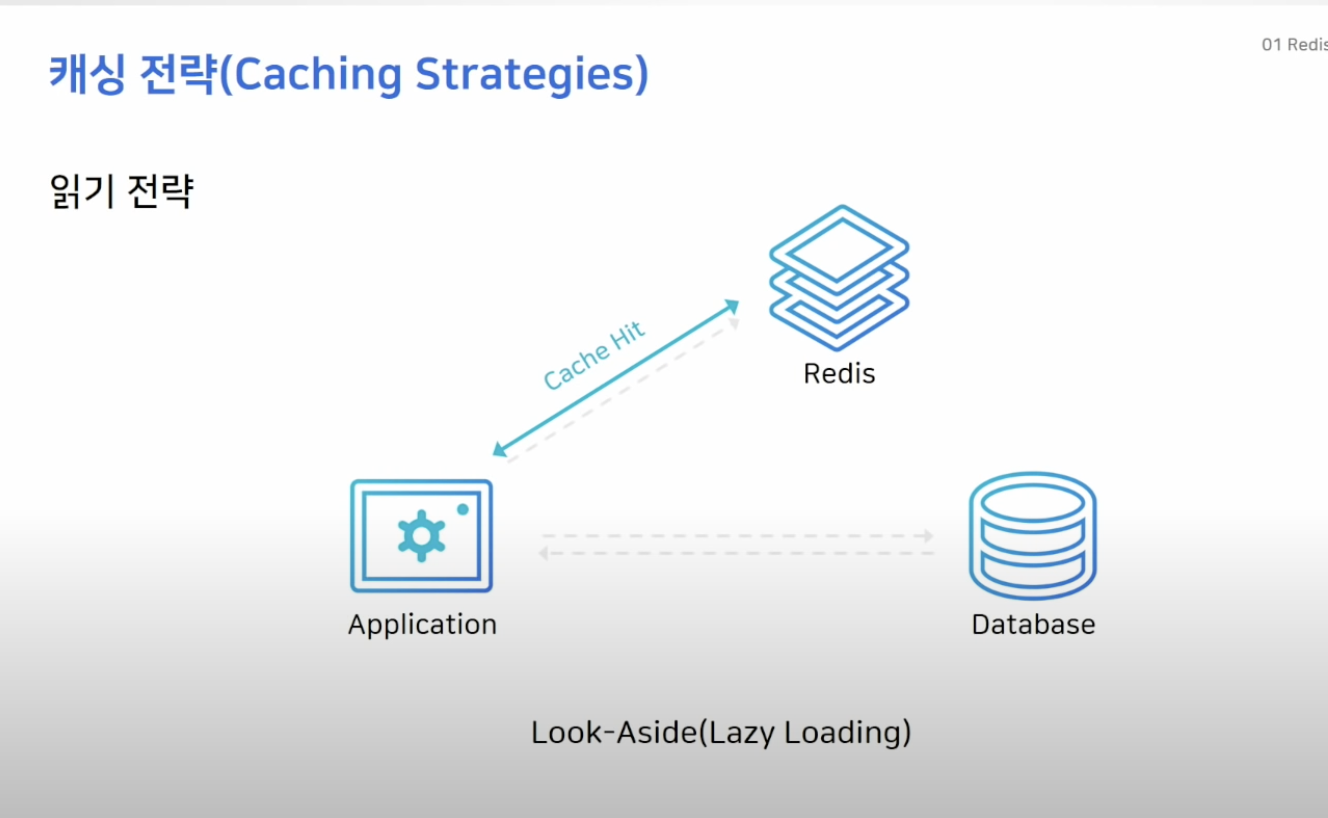
- 가장 일반적인 전략
- 레디스는 찾는 데이터가 없으면 DB로 가서 가져옴 (lazy-loading)
- 레디스가 다운되더라도 디비에서 데이터를 가져올 수 있음 대신 캐싱디비가 꺼지면 디비로 요청이 몰리기 때문에 디비 부하가 커질 수 있음
- 그래서 캐시를 새로 투입하거나 디비에만 데이터를 저장하면 캐시 미스가 발생해 성능 저하 발생
- 그래서 이럴때엔 디비에서 캐시로 미리 데이터를 밀어 넣을 수 있음 (cache warming)
- EX: 상품 오픈 전 상품의 정보를 디비에서 캐시로 미리 올리는 작업 수행
쓰기 전략 ( Write - Around, Write-Through)

-
Write - Around : 디비에만 데이터 저장, 캐시 미스가 발생한 경우 디비에서 케시로 데이터 보냄
단점: 디비와 캐시 내의 데이터가 다름 -
Write-Through : 디비에 저장할 때 함께 캐시에도 저장
단점: 저장할 때 마다 디비,캐시 두단계의 저장 단계가 필요시됨, 저장하는 데이터가 사용되지 않을 수 있어 무조건 저장하면 리소스 낭비
따라서, expire time 설정이 중요
Redis에서 데이터를 영구 저장하려면 ?

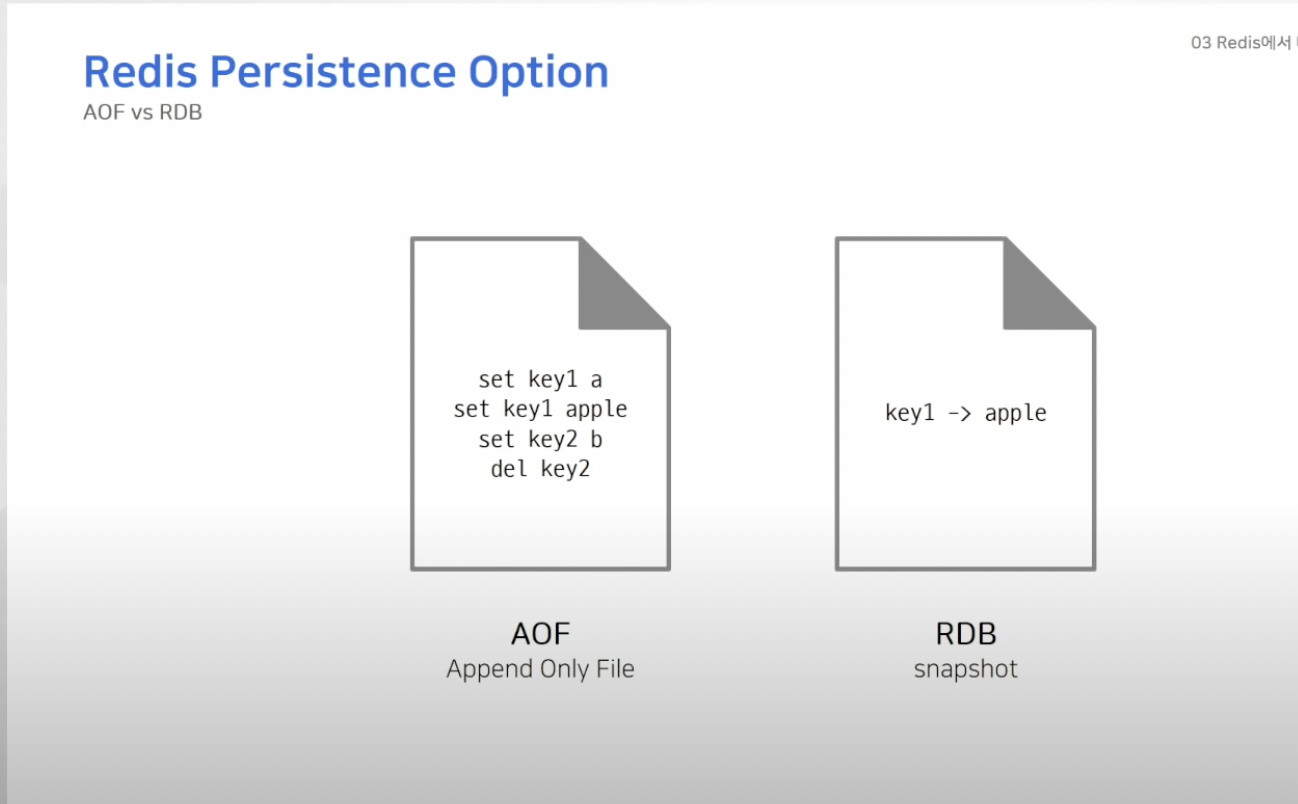
- 데이터를 영구적으로 저장하는 방법 2가지 ( AOF, RDB )
- Append Only File : 데이터를 변경하는 커맨드가 들어오면 커맨드를 모두 저장
- RDB : SNAPSHOT 방식으로 데이터 저장 , 당시에 존재하는 데이터를 사진 찍듯이 캡처하고 파일 형태로 저장
- 위의 사진처럼 AOF는 모든 데이터 추가/삭제 과정이 남아있음 (append only)
데이터가 추가되기만 해서 RDB보다 사이즈가 커지게됨 -> 압축 과정 필요
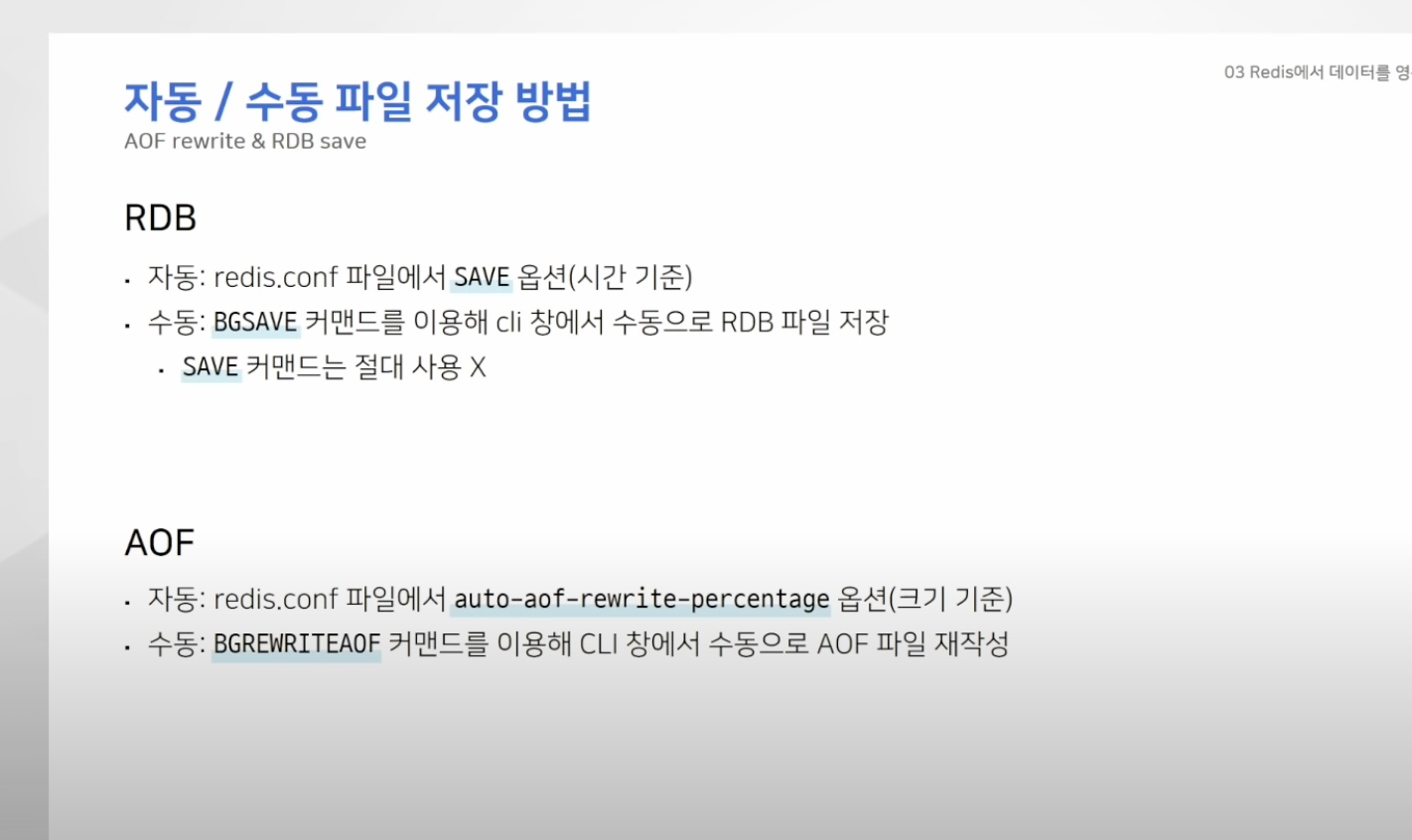
- RDB, AOF 모두 커맨드로 생성 가능
- 원하는 시점에 파일을 생성하도록 설정 가능
- RDB의 경우 시간단위 , AOF는 파일의 크기를 기준으로 특정 시점에 파일 생성 가능
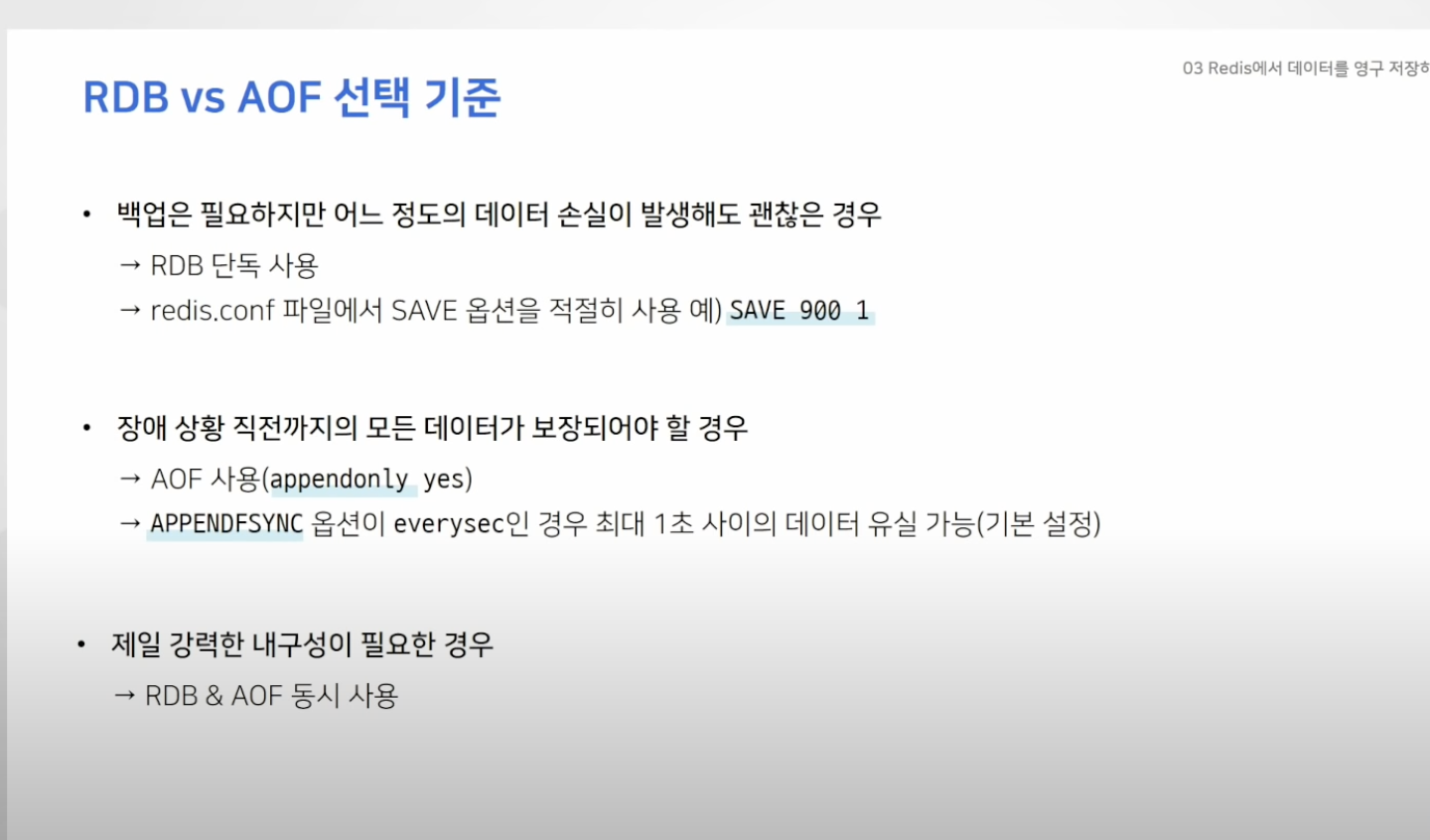
- Redis를 단순 캐시기능으로만 사용하면 위의 기능은 필요 X
- 우리는 어느정도 데이터 손실을 감수 할 수 있어! 라고 한다면 RDB 방식 적정
- 대신, redis.conf 파일에서 SAVE옵션을 적절히 사용해야함
- 가령 SAVE 900 1 이라고 한다면 900초동안 한 개 이상의 키가 변경됬을 때 RDB 파일 재작성
- 만약 장애 상황 직전까지의 모든 데이터가 보장되어야 하는 경우 : AOF 방식 적정
- APPENDSYNC 옵션이 everysec인 경우 최대 "1초" 사이의 데이터는 유실 가능성 있음
- 가장 강력한 내구성이 필요한 경우 : 둘 다 사용 !!
레디스 아키텍처 선택 노하우

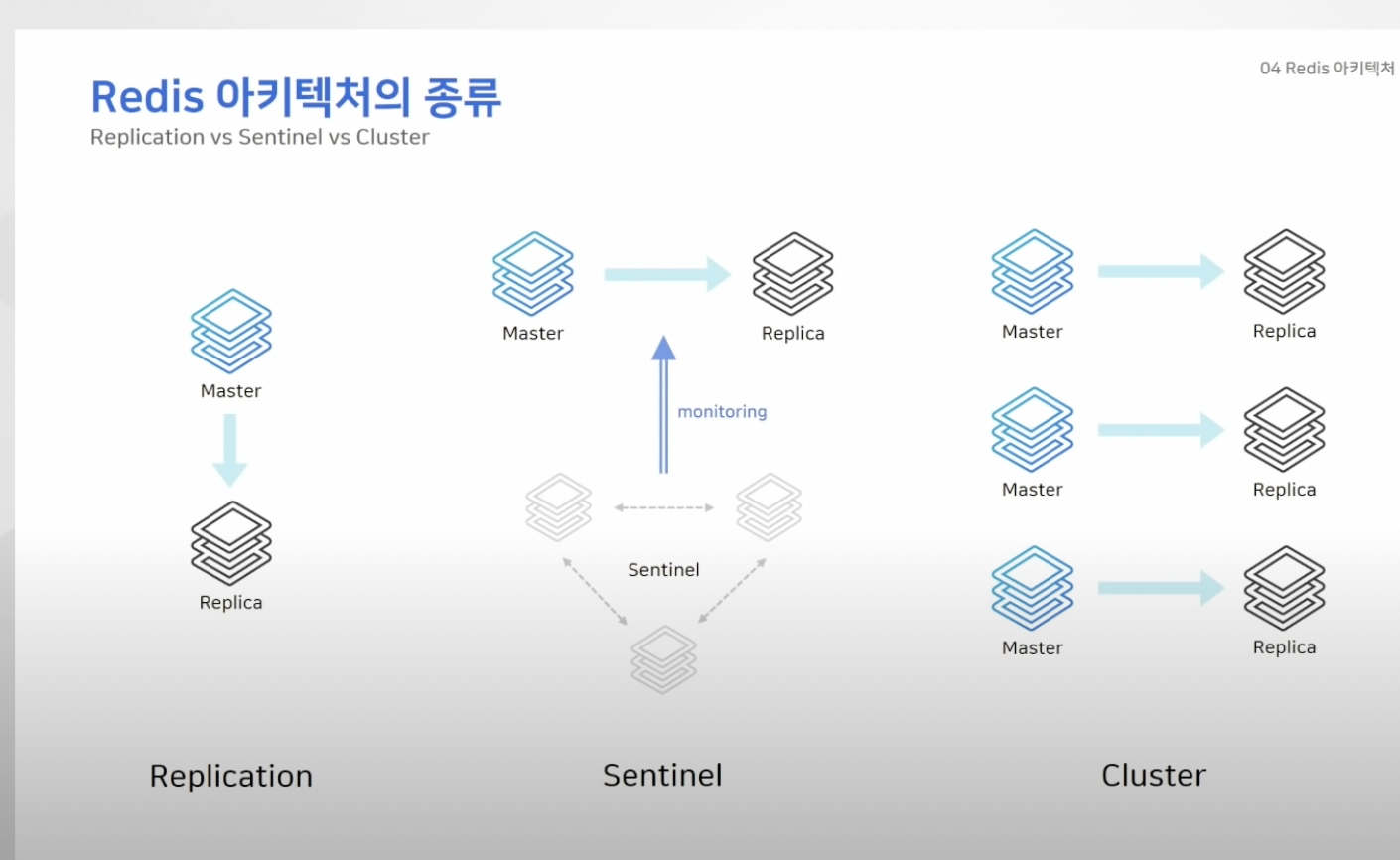
레디스 아키텍처 종류
1. 리플리케이션 (복제)
2. 센티널
3. 클러스터
리플리케이션 -> 마스터,리플리카로만 이루어진 가장 간단한 구성
센티널 -> 마스터와 리플리카 노드외에 추가로 센티널 노드 필요 (센티널은 일반 노드 모니터)
클러스터 -> 최소 3대의 마스터가 필요하며 샤딩 기능 제공

리플리케이션
- 단순히 복제만 연결된 상태
- 이 구성뿐만 아니라 레디스에서는 복제는 모두 비동기 방식으로 진행되는데 즉, 마스터의 복제본이 제대로 잘 전달 됬는지 매번 확인 하지는 않음
- 이 구조는 HA 기능이 없어 마스터 장애 상황 시 수동으로 변경 작업 많음
- 리플리카 노드에 직접 접근해 복제를 끊어야 하고 어플리케이션 단에서도 연결 설정을 변경해서 배포 해야함
센티널
- 일반적인 다른 노드들을 모니터링 하는 역할 담당
- 따라서 마스터 노드 장애 확인 시 리플리카 노드가 마스터 노드가 되도록 함
- 이때 어플리케이션에서는 연결 정보 변경 할 필요 X
- 어플리케이션은 센티널 노드만 알고 있음 되고 센티널이 변경된 마스터 노드로 바로 연결 시켜 준다.
- 이 프로세스를 경험하기 위해선 항상 3대 이상의 홀수 대의 센티널 노드 프로세스를 띄워줘야 함.
클러스터
- 데이터가 자동으로 마스터 노드에 분할 저장되는 샤딩 기능 제공
- 이 구성에서는 모든 노드가 서로를 감시하고 있다가 마스터가 비정상 일 때 자동으로 페일 오버 진행
- 최소 3대 이상의 마스터 노드가 필요
- 일반적인 방식은 하나의 마스터 노드에 하나의 리플리카 생성
아키텍처 선택 기준
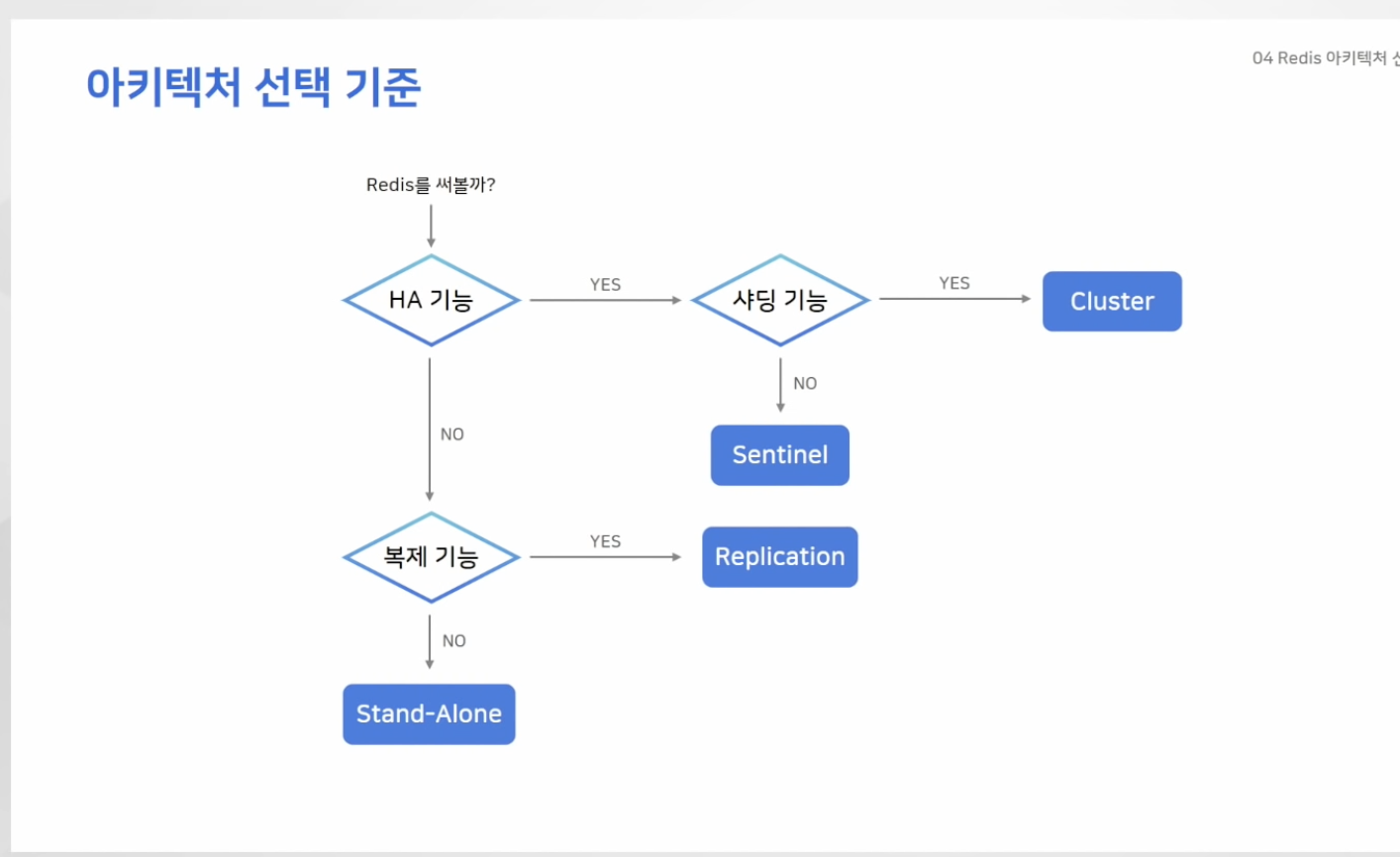
- HA : 자동으로 페일오버 되는 기능
- HA 기능 & 서비스 확장으로서의 샤딩 기능 모두 필요하면 : Cluster
- 단순 HA기능만 필요하면 센티널
레디스 운영 꿀팁 & 장애 포인트

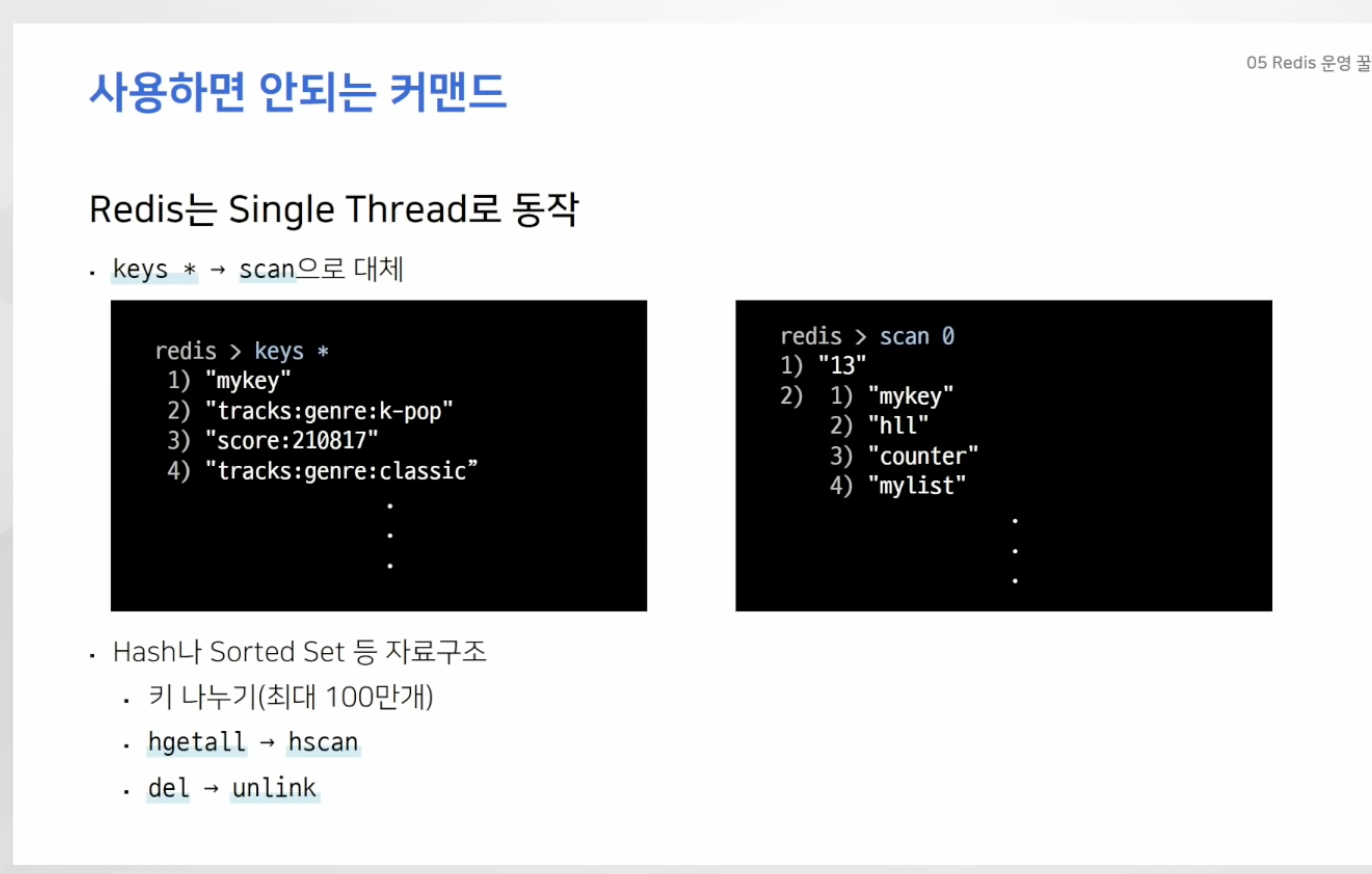
- 레디스는 싱글 스레드로 동작
- 한 사용자가 오래 걸리는 커멘드를 사용하면 나머지 모든 요청은 대기 상태에 머물게됨
- keys는 모든 키를 보여주는 커맨드인데, 주로 개발할 때 사용하다가 운용할 때 사용하게 되면
모든 작업이 대기 상태가 될 수 있음 ( 사용X ) - keys 커맨드는 "scan" 으로 대체 가능 -> 재귀적으로 키 호출 가능
- 키 내부에 아이템이 많아 질 수 록 성능저하, 하나의 키에 약 100만개의 데이터만 저장하는 것이 좋음
- 많은 데이터가 들어있을 때 delete로 데이터 지우면 해당 작업 끝날 때 까지 아무것도 할 수 X
- 하지만 unlink 커맨드를 사용하면 백그라운드에서 사용하게 되므로 해당 명령어 사용 추천!
변경하면 장애 막을 수 있는 기본 설정값

- STOP-WRITES-ON-BGSAVE-ERROR : RDB 파일이 정상적으로 저장되지 않았을 때, REDIS로 들어오는 모든 기능 차단
- 본인이 레디스에 대한 서버 모니터링을 적절히 하고 있다면 해당 기능은 꺼두는 것이 불필요한 장애를 막을 수 있는 방법
- MAXMEMORY-POLICY: 앞서 레디스를 캐시로 사용할거면 Expire Time을 설정하는 것이 중요 하다고 언급.
- 데이터가 가득 찼을 때 맥스 메모리 폴리시 기준 데이터 삭제
- 기본값은 noeviction인데 메모리에 데이터가 가득 차면 더이상 새로운 키 저장 X
- volate-lru : 가장 최근에 사용하지 않은 (즉, 오래된 놈) 데이터 부터 삭제 , 단 expire 설정에 있는 키 값만 삭제하기에 메모리에 expire설정 값이 없는 키만 남아 있다면, 위와 같은 장애가 발생함.
- allkeys-lru : 모든 키에 대해서 LRU 방식으로 데이터 삭제
-> 해당 설정으론 최소 모든 데이터가 가득차서 발생되는 장애 걱정 X
Cache Stampede
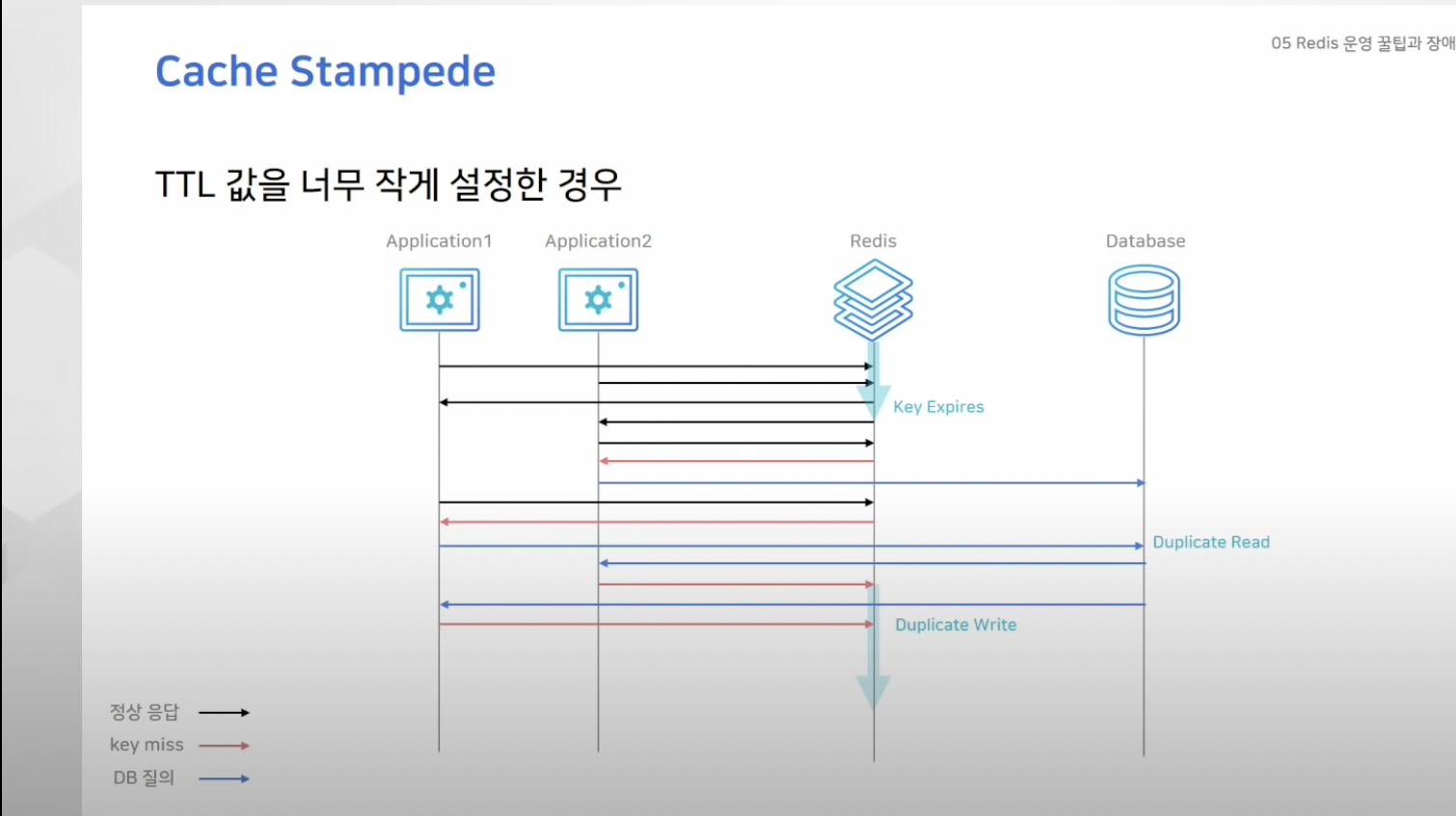
- Look-Aside 패턴에서 레디스에 데이터가 없으면 직접 디비로 데이터 요청 한 뒤 이를 다시 레디스에 저장
- 그런데 키가 만료되는 순간 많은 레디스 서버에서 해당 키를 함께 바라보고 있었다면 모든 어플리케이션 서버들이 동일한 키를 찾게되는 "duplicate read" 발생
- 또한 읽어온 값을 각각 write하는 "duplicate write" 발생
- 굉장히 비효율적, 처리량 상승, 불필요한 작업 늘어남
- 해당 기업에서는 인기 있는 공연이 오픈되면 한 공연 데이터를 읽기 위해 몇십개의 어플리케이션 서버에서 커넥션이 연결됬음
- TTL 시간을 넉넉히 잡아 해결
TTL (Time To Leave)
- 해당 패킷의 생존 시간 의미
- IP 패킷 내에 있는 값으로서 해당 패킷이 네트워크 내에 너무 오래 있어서 버려져야 하는지의 여부를 라우터에게 알려주는 역할
- 패킷들은 여러가지 이유로 적정 시간 내에 장소에 배달되지 못하는 수가 있다.
- 가령 부정확한 라우팅 테이블의 결합은 패킷을 끊임없이 순환하도록 한다.
- 그래서 일정한 시간이 지나면 해당 패킷을 버릴건지 혹은 재전송 할지 결정 해야함
- 이 방식을 정하기 위한 수단이 TTL
MaxMemory 값 설정
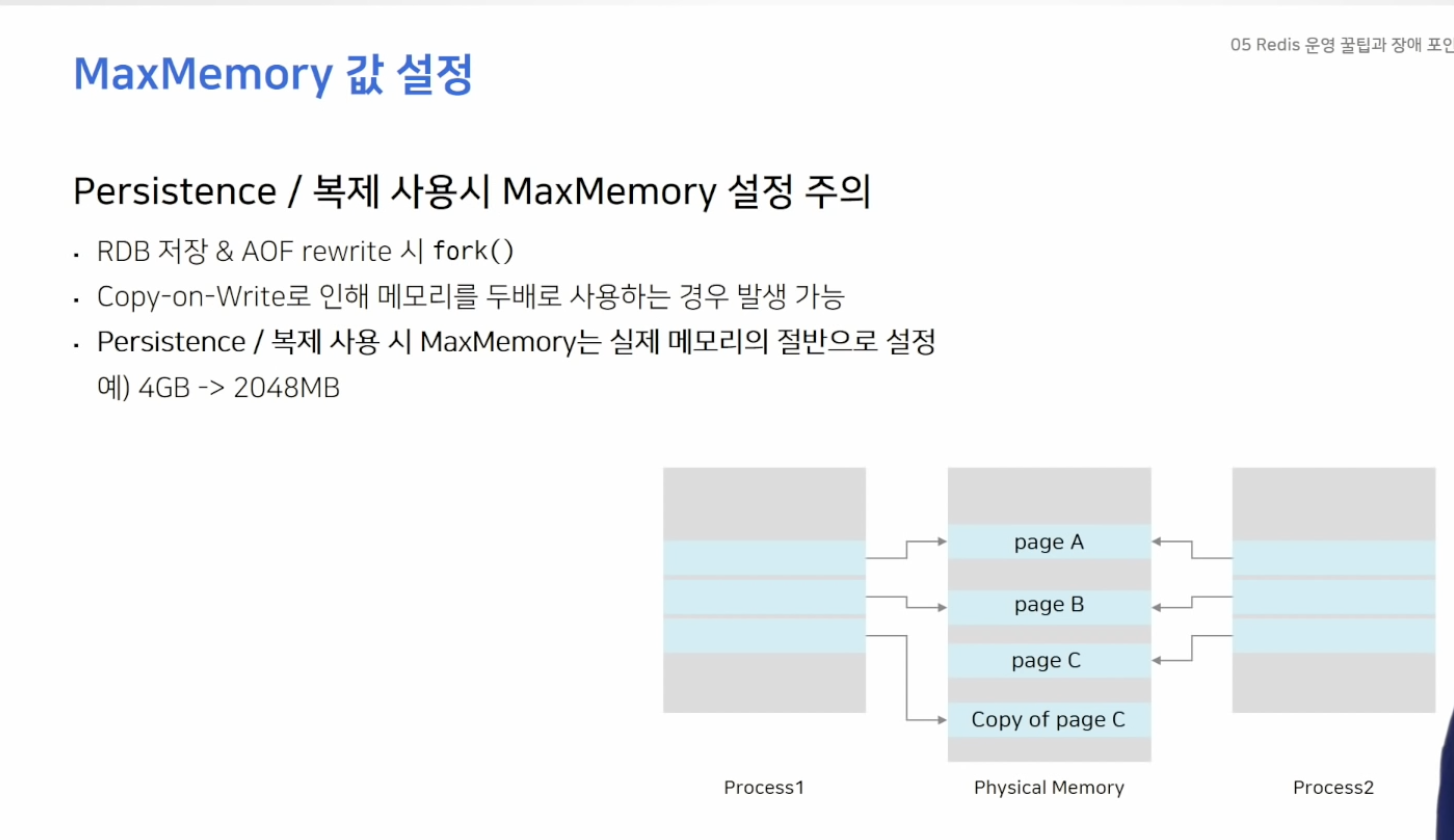
- 레디스에 데이터를 파일로 저장할 때 fork를 통해 자식 프로세스 생성
- 자식 프로세스로 백그라운더에서는 파일로 데이터를 저장하지만 원래 프로세스는 일반적인 요청을 받아 데이터를 처리함
- 이게 가능한 이유는 copy-on-write 기능으로 메모리를 복제해 사용하기 때문
- 이로 인해 서버 메모리 사용량이 2배로 커짐
- 만약 데이터를 영구 저장 하지 않더라도 복제 기능을 사용하고 있다면 주의 필요
- 복제 연결을 처음 시도 하거나 연결이 끊겨 연결을 재시도 할 때, 새로 RDB 파일을 저장하는 과정을 거치기 때문
- 따라서 맥스 메모리는 실제 메모리의 "절반"으로 설정 하는 것이 좋음
- 예상치 못한 상황에 메모리가 풀로 차서 장애 발생 할 수 있기에

WILL is ALL