변수는 어디에 저장되는가? 메모리에 저장된다. 그 위치를 주소라고 부른다. 주소는 어떻게 알아내는가? 변수 앞에 '&'를 붙여서 알아낸다.
int year = 2002;
int month = 10;
cout << "year의 주소 : " << &year << endl;
cout << "month의 주소 : " << &month << endl;실행 결과.
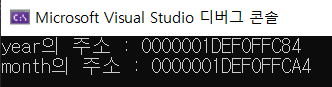
16진수 표기가 메모리를 나타내는 가장 일반적인 방법이다. 주소를 보면, year의 주소가 month의 주소보다 앞서고, 32만큼 차이가 난다. 이는 year를 먼저 저장했기 때문에 숫자가 더 작은 것이고, int가 4바이트이기 때문에 32bit만큼 차이가 나는 것이다. 어떤 컴파일러에서는 이들을 인접한 위치에 저장하지 않는다.
주소에 대한 간단 워밍업을 하면 포인터를 배울 수 있다. 많은 개발자들이 한 번 거쳐가는 고비(?)이지만 그만큼 재밌을(?) 수도 있다. 일단 포인터가 뭔지는 모르겠지만, 장점 먼저 알고 가자.
객체 지향 프로그래밍은 컴파일 시간(compile time)이 아닌 실행 시간(run time)에 어떤 결정을 내린다는 것을 강조한다. 컴파일 시간이란 컴파일러가 코드 소스를 변환하는 시간을 말하고, 실행 시간은 프로그램이 실제로 실행되는 시간을 말한다. 여행으로 따지면, 컴파일 시간은 여행 전에 계획한대로 무조건 움직이는 것을 말하고, 실행 시간은 여행 중에 상황에 맞게 그때그때 계획을 바꾸는 것을 말한다. 당연히 실행 시간을 중요시하는 게 융통성도 있고 좋다. 왜냐?
예를 들어 우리가 배운 배열을 보자. 배열을 만들 건데, 우리가 필요한 배열의 갯수가 몇 개인지 모를 수도 있다. 그러면 평소에는 20개면 되지만, 예외적인 경우를 생각해서 200개를 만들어야 할 수 있다. 이는 메모리 낭비로 이어진다. 하지만 객체 지향 프로그래밍에서는, 이를 실행 시간에 결정하게 해서 메모리를 절약할 수 있다.
포인터랑 일반 변수는 완전 다른 개념이다. 일반 변수가 값을 저장하는 게 베이스고 주소를 알 수 있는 게 부수적이라면, 포인터는 주소를 저장하는 게 베이스고 값과 주소의 주소를 알 수 있는 게 부수적이다.
int val = 6;
int* p_val = &val;
cout << "val의 값 : " << val << endl;
cout << "val의 주소 : " << &val << endl;
cout << "p_val의 값 : " << p_val << endl;
cout << "p_val의 참조 값 : " << *p_val << endl;
cout << "p_val의 주소 : " << &p_val << endl;
*p_val = *p_val + 1;
cout << "p_val의 참조 값 : " << *p_val << endl;실행 결과.
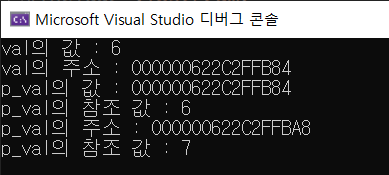
포인터 변수를 선언할 때는 자료형과 변수 이름 사이에 *를 붙인다. *는 간접값 연산자 혹은 간접 참조 연산자라고 부른다. (간단하게 참조 연산자라고도 부른다.) 그리고 값으로 초기화 하는 게 아니라, 주소로 초기화 한다. 가독성을 위해서 변수 이름 앞에 p를 붙이는 게 관행이다. 위의 실행 결과를 보면, val의 주소랑 p_val의 값이 같은 걸 알 수 있다. 또한 참조값을 이용해서 값을 바꿀 수도 있다.
포인터를 선언할 때 다음과 같이 선언하면 헷갈릴 수 있다.
int* p1, p2;이는 p1은 포인터 변수로, p2는 보통의 변수로 생성한다. p1,p2 모두 포인터 변수로 생성하고 싶다면 변수 이름 앞에 *를 붙이면 된다
포인터는 매우 조심스럽게 사용해야 한다. 가령 다음과 같은 코드를 보자.
long* p_val;
*p_val = 597109;포인터 변수 p_val의 주소는 어디일까? 아무도 알 수 없다. 일반 변수는 값을 저장하기 위한 메모리를 대입한다. 포인터 변수는 주소를 저장하기 위해 메모리를 대입한다. 그런데 주소를 저장하지 않고 값을 저장한다? 문제가 생기는 것이다.
포인터와 const
포인터와 const를 결합하면 의미가 조금 복잡해진다. 가령 다음과 같은 코드는 포인터를 사용해서 포인터가 가리키는 값을 변경할 수 없다는 의미이다. 포인터 자체는 바꿀 수 있다.
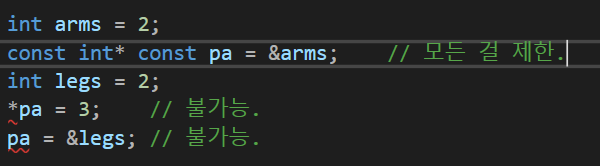
int age = 29;
const int* pAge = &age;
*pAge += 1; // 불가능.
cin >> *pAge; // 불가능.
age = 20; // 가능.
int bage = 30;
pAge = &bage; // 가능.지금까지 우리는 일반 변수와 일반 포인터, 일반 변수와 const 포인터 관계를 알아보았다. 남은 건 이제 2가지다. 즉 const변수와 일반 포인터와 const변수와 const 포인터다. 후자는 가능하지만 전자는 불가능하다.
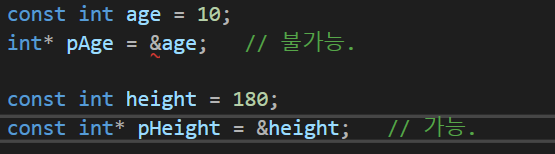
const 일반 변수에 일반 포인터가 불가능한 이유는 간단하다. const를 붙인다는 것은 변경하지 않겠다는 의미이다. 포인터는 원본에 접근한다는 뜻이다. 둘의 의미는 충돌한다. 그래서 안되는 것이다.
const 일반 변수에 const 포인터는 둘 다 값을 변경할 수 없다.
const를 사용하는 또 하나의 방법은 포인터 자신의 값을 바꾸지 못하게 하는 것이다.
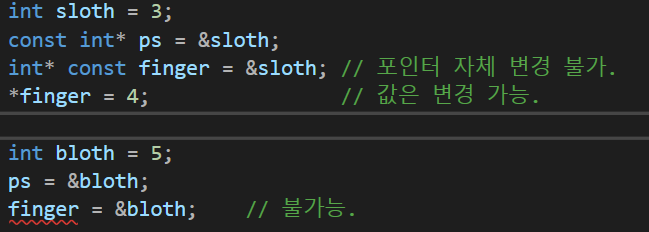
원한다면, const를 양쪽으로 쓸 수도 있다.
new를 사용한 메모리 대입
지금까지는 포인터 변수의 메모리에 접근할 수 있는 방법이 2가지였다. 즉 포인터 변수를 통해서, 그리고 주소를 준 변수를 통해서 메모리에 접근할 수 있었다. 하지만 오직 한 가지 방법을 통해 접근할 수 있게 만드는 방법도 있다. 바로 new 연산자를 이용한 방법이다.
int* pn = new int;이렇게 선언을 하면 pn은 주소가 되고 *pn은 그 값이 된다. new int 부분은 int형 데이터를 저장할 메모리가 필요하다고 알려주는 역할을 한다. int를 통해 몇 바이트가 필요한 지 말해준다. new 연산자를 사용한 포인터는 일반적으로 다음과 같은 모양을 따른다.
자료형 * 변수 이름 = new 자료형
포인터의 크기
포인터의 크기는 운영체제와 관련이 있다. 32비트면 4바이트고, 64비트면 8바이트다.
int val = 6;
int* p_val = &val;
double* p_dbval = new double;
*p_dbval = 10;
cout << "sizeof(val) : " << sizeof(val) << endl;
cout << "sizeof(p_val) : " << sizeof(p_val) << endl;
cout << "sizeof(*p_val) : " << sizeof(*p_val) << endl;
cout << "sizeof(p_dbval) : " << sizeof(p_dbval) << endl;
cout << "sizeof(*p_dbval) : " << sizeof(*p_dbval) << endl;실행 결과.
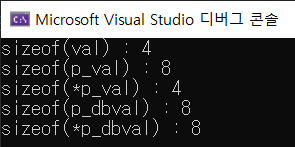
값은 자료형의 크기를 그대로 따르고, 포인터 변수는 모두 8바이트인 것을 확인할 수 있다.
delete를 사용한 메모리 해제
사용 후 필요가 없어진 메모리는 delete 연산자를 사용하여 해제할 수 있다. 그 메모리는 나중에 다른 프로그램이 사용할 수 있다. 이것이 최대 장점이고 프로그램을 효율적으로 만들 수 있는 최고의 방법인 것 같다.
int* ps = new int; // 메모리 대입.
...
delete ps; // 메모리 해제.이렇게 하면 ps가 지시하는 메모리가 해제된다. new를 사용하면 반드시 delete를 사용해야 한다. 그렇지 않으면 대입은 되었지만 더이상 사용하지 않는 메모리 누수가 발생할 수 있다. 그러면 많은 메모리를 요구하는 게임에서는 더이상 사용할 메모리가 없어질 수도 있다. 그래서 new 연산자와 delete를 동시에 코드에 작성하고 그 사이를 꾸미는 게 잊어버리지 않기 위한 하나의 방법일 수 있다.
new를 사용한 동적 배열의 생성
이전에 포인터를 사용하면 생기는 장점에 대해 상기해보자. 컴파일 시간이 아닌 실행 시간에 메모리를 차지할 수도 있고, 없을 수도 있었다. 컴파일 시간에 메모리가 대입되는 걸 '정적 바인딩'이라고 한다. 반면 실행 시간에 메모리가 대입되는 걸 '동적 바인딩'이라고 한다. 만약 실행 시간에 배열을 만든다고 하면 그게 '동적 배열'인 것이다. 복잡한 자료형을 사용할 때는 단순한 자료형을 사용할 때보다 더 큰 메모리가 필요하기 때문에 new를 사용하는 게 더 효율적이다. 동적 배열은 다음과 같이 생성 및 해제한다.
int* psome = new int[10];
...
delete [] psome;포인터 변수 이름에 그 배열의 첫 번째 원소의 주소가 대입된다.
이렇게 만든 동적 배열을 어떻게 사용할 수 있을까? 우선 psome이 첫 번째 원소의 주소를 가리키기 때문에, *psome은 첫 번째 원소의 값을 나타내게 된다. 또한 배열의 특징을 살려, psome[0]도 가능하다. 두 번째 부터는 psome[1] 이런 식으로도 가능하다.
double* p3 = new double[3];
p3[0] = 0.2;
p3[1] = 0.5;
p3[2] = 0.8;
cout << "p3[0] : " << p3[0] << endl;
cout << "p3[1] : " << p3[1] << endl;
cout << "p3[2] : " << p3[2] << endl;
p3 = p3 + 1;
cout << "포인터를 옮긴 후" << endl;
cout << "p3[0] : " << p3[0] << endl; // p3의 위치가 바뀌었다.
cout << "p3[1] : " << p3[1] << endl;
cout << "p3[2] : " << p3[2] << endl; // 쓰레기 값이 들어가있다.
p3 = p3 - 1; // 포인터가 가리키는 지점을 다시 원상복구 해주어야 한다.
delete[] p3;실행 결과.

p3 = p3 + 1 구문을 통해 포인터가 가리키는 값을 한 칸 오른쪽으로 옮길 수 있다. 이러면 대입하지 않은 p3[2]에는 쓰레기 값이 들어가있다. 그리고 이 상태로 메모리 해제를 하면, 초기화 할 때 3의 크기만큼 했기 때문에, 만들지 않은 메모리를 해제하려고 하고 이는 에러로 이어진다. 그래서 메모리 해제 전에 반드시 포인터의 위치를 원래대로 맞춰주어야 한다.
조금 헷갈릴만한 것은 값을 참조하는데 참조 연산자를 안 써도 되는 방법이 있다는 것이다. 참조 연산자는 다음과 같이 사용하면 된다
cout << "p3[1]의 값 = " << *(p3 + 1) << endl;p3에다가 +1를 하면 포인터가 이동이 된다. 그걸 소괄호로 묶은 상태에서 참조를 하면 p3[1]의 값이 나온다.
