C++
1.0. 유용한 단축키
Ctrl + K + C : 코드 주석 처리.Ctrl + K + U : 코드 주석 해제.F5 : 디버깅 실행.F10 : 코드 한 구문씩 실행(함수로 안 들어감.)F11 : 코드 한 구문씩 실행(함수로 들어감.)
2.1. visual studio 설치
int main(){ cout << "Hello World!"" << endl;}
3.2. 데이터 처리(1) - 간단한 변수
데이터에 대해 알아보자. 우리는 게임을 하면서 데이터를 저장할 필요성을 느낀다. 예를 들어 스타크래프트 유닛 공격력, 방어력, 자원 등등을 표기하기 위해서는 이를 데이터 안에 저장해 두어야 한다. 데이터는 단순형과 복잡형으로 나눌 수 있다. 먼저 단순형에 대해 알아
4.2. 데이터 처리(2) - const 제한자
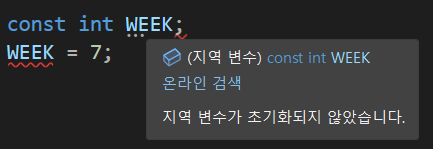
값이 정해져있는 상수를 표현할 때 const 제한자를 사용하면 편리하다. const를 사용하면 실수로라도 값을 바꿀 가능성도 제한하기 때문이다.선언 방법은 const 자료형 변수이름 이다. 나중에 바꾸려고 해도 바꿀 수가 없다.선언과 동시에 초기화를 해주지 않으면 에러
5.2. 데이터 처리(3) - 부동 소수점수

지금까지 우리는 정수형 변수만 알아보았다. 다음으로는 부동 소수점수를 알아보겠다. '부동'은 안 움직인다는 뜻도 있지만, 여기서는 물이나 공기 중에 떠서 움직인다는 의미이다. 따라서 부동 소수점수는 소수점이 자유롭게 움직인다는 뜻이다. 부동 소수점수를 쓰려면 기존의 자
6.2. 데이터 처리(4) - 산술 연산자
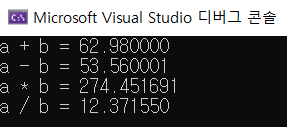
ㅇㅇ
7.3. 복합 데이터형(1) - 배열
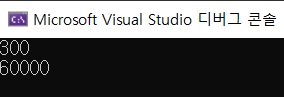
단순 데이터형을 배웠으니 복잡 데이터형을 알아보자. 그 중에 제일 첫 번째는 배열이다. 배열은 데이터형이 같은 여러 개의 값을 연속적으로 저장할 수 있는 데이터 구조이다. 배열은 데이터형 배열이름배열원소 개수로 선언한다.여기서 배열원소 개수안에 들어가는 수는 상수로서
8.3. 복합 데이터형(2) - 문자열
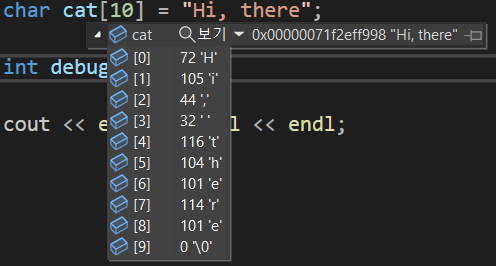
문자열이란 메모리 바이트 단위로 연속적으로 저장되어 있는 문자들을 말한다. 예를 들어 "Programming is challenging"를 저장할 수 있다. 여기서 중요한 점은 문자열의 끝 문자는 항상 널 문자(\\0)이어야 한다는 점이다. c++는 문자열을 출력할 때
9.3. 복합 데이터형(3) - string 클래스
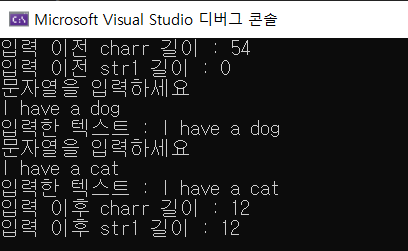
문자 배열을 사용하는 대신에 string 클래스를 사용하면 훨씬 편하다. string 클래스는 std 이름 공간 안에 속해있다. 특징들을 알아보자. 실행 결과. 초기화 하기도 쉽고 배열처럼 쉽게 접근도 가능하다. 문자 배열과의 큰 차이점은 배열로 선언할 필요가 없다
10.3. 복합 데이터형(4) - 구조체

다음으로 알아볼 것은 구조체이다. 게임에서 하나의 유닛에 대한 정보를 입력한다고 생각해보자. 예를 들어 스타크래프트의 유닛들은 각각 공격력, 방어력, 이동 속도, 등등이 다르다. 이 정보들을 묶을 수 있는 데이터 형식이 있으면 좋을 것이다. 배열은 이로 적합하지 않다.
11.3. 복합 데이터형(5) - 공용체

구조체와 비슷한 것이 공용체가 있다. 공용체는 서로 다른 데이터형 중에서 한 가지만 보관할 수 있다. 다음을 보자.각각 멤버에 넣을 때 디버깅을 통해 구조체 안에 어떤 변수가 들어갔는지 확인해보자.멤버 중 picture 값을 대입했을 경우에는 picture에 값이 잘
12.3. 복합 데이터형(6) - 열거체
구조체랑 비슷하면서도 const를 사용한 것 같이 상수를 만들어주는 기능이 있는데, 그게 바로 열거체다.
13.3. 복합 데이터형(7) - 포인터와 메모리 해제
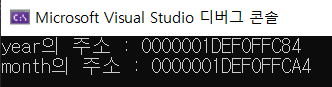
변수는 어디에 저장되는가? 메모리에 저장된다. 그 위치를 주소라고 부른다. 주소는 어떻게 알아내는가? 변수 앞에 '&'를 붙여서 알아낸다.실행 결과.16진수 표기가 메모리를 나타내는 가장 일반적인 방법이다. 주소를 보면, year의 주소가 month의 주소보다 앞서고,
14.3. 복합 데이터형(8) - 포인터(문자열, char 주소, new 구조체)
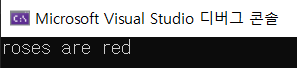
포인터와 문자열문자열을 포인터와 연관 시키면 조금 복잡해진다. 실행 결과.배열 이름은 첫 번째 원소의 주소이다. 그래서 널 문자를 만날 때까지 출력이 되었다. 그럼 오른쪽에 "s are red"는 뭘까? 문자열 출력에 일관성이 있으려면 큰 따옴표로 둘러싸인 문자열도 반
15.4. 루프와 관계 표현식(1) - for 루프

드디어 루프다. 루프는 반복문으로써 반복해서 입력할 일이 많을 때 사용한다. 그중 for 루프를 먼저 보자.실행 결과.형식은 for(초기화; 조건 검사; 갱신)하고 밑에다가 반복해서 작업할 코드를 입력한다. 한 문장을 쓰면 위와 같이 쓰면 되지만, 여러 줄이라면 코드
16.4. 루프와 관계 표현식(2) - while 루프
while 루프는 for 루프에서 초기화 부분과 갱신 부분을 없애고, 루프 몸체와 조건 검사 부분만 남겨 놓은 것이다.이런식으로 쓰는데, while문에 입장하면 먼저 조건 검사가 맞는지 확인한다. true로 평가되면, 몸체를 실행한 후, 다시 조건 검사식으로 들어온다.
17.4. 루프와 관계 표현식(3) - do while 루프
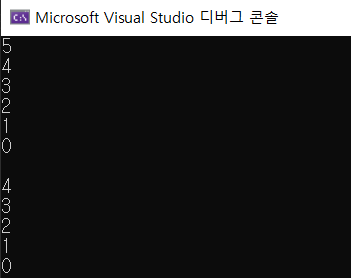
do while 루프는 while 루프랑 조그만한 차이가 있다. 바로 조건 검사식을 검사하기 전에 몸체를 먼저 한 번 실행한다. 코드는 이렇게 작성한다.세미 콜론이 붙는 걸 조심해야 한다. 간단한 코드를 작성해서 비교해보면,실행 결과.do while문은 조건 검사식 검
18.4. 루프와 관계 표현식(4) - Range 기반의 for 루프
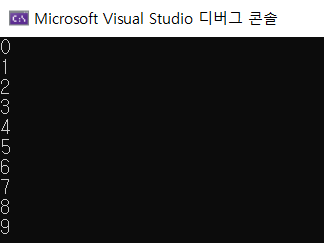
범위 기반 반복문은 특정 배열 안에 있는 모든 값들이 다 출력이 된다. 이 반복문은 다음과 같이 사용한다.실행 결과.위의 예시에서는 arrays안에 있는 배열을 다 돈 것이다. 비슷하게, vector에도 사용할 수 있다.
19.4. 루프와 관계 표현식(5) - 중첩 루프와 2차원 배열
우리는 지금까지 1차원 배열만 배웠다. 근데 2차원 배열로 작성하는 방법도 있다. 이렇게 작성하는 것이다.이러면 arrays의 10개 각 원소가 또 20개의 원소를 배열로 가지고 있게 되는 것이다. 이 값은 어떻게 초기화 할까?이런 식으로 하면 된다. 하지만 이보다 더
20.5. 루프와 관계 표현식(1) - if 구문

스킬 쿨이 돌았다면 사용할 수 있고, 아직 안 돌았다면 사용하지 못 한다. 이런 건 어떻게 구분할까? 바로 if로 구분한다. if는 이렇게 사용한다.while문이랑 비슷하게 쓰인다. 조건식이 맞으면 body가 실행되고, 아니면 건너 뛴다. while문과 마찬가지로 세미
21.5. 루프와 관계 표현식(2) - 논리 표현식
때로는 하나 이상의 조건을 검사해야 하는 경우가 있다. 예를 들어 보통 게임 캐릭터의 체력은 0미만이 되서도 안되지만 지정 체력을 초과해서도 안 된다. 이같이 주어진 표현식을 조합하거나 변경하는 세 가지 연산자가 있다. 각각 논리합, 논리곱, 논리부정이라 부른다.논리합
22.5. 루프와 관계 표현식(3) - ? : 연산자

if else로 쓸 수 있는 간단한 구문은 ? : 연산자로도 쓸 수 있다. 이 연산자는 조건 연산자 or 삼항 연산자라고도 부른다. 이렇게 사용한다.expression1에는 조건식을 넣는다. 그리고 그 조건이 true면 expression2가, false면 expres
23.5. 루프와 관계 표현식(4) - switch 구문
특정 조건에서는 if else 구문이랑 비슷하면서도 좀 더 쉽게 구현할 수 있다. switch 구문을 사용하는 것이다.integer-expression에는 정수, 문자, 열거자를 쓰는 것이 좋다. if else 구문은 위에서부터 밑으로 계속해서 검사해 나가지만, swi
24.5. 루프와 관계 표현식(5) - break와 continue 구문

break와 continue 구문은
25.6. 함수(1) - 함수의 기초

ㅇ
26.6. 함수(2) - 함수 매개변수
함수는 매개변수를 받는다. 다음과 같은 식이다.
27.6. 함수(3) - 함수와 배열
함수에는 배열과 같이 복잡한 데이터형도 사용 가능하다. 매개변수로 배열을 받아야 하는 경우도 있을 것이다. 그럴때는 이렇게 쓴다.이렇게 사용하면 Sum_Arr의 첫 번째 매개변수를 마치 배열을 뜻하는 것처럼 보인다 하지만 실상은 포인터다.코드에서 배열의 매개변수를 배열
28.6. 함수(4) - 재귀 호출
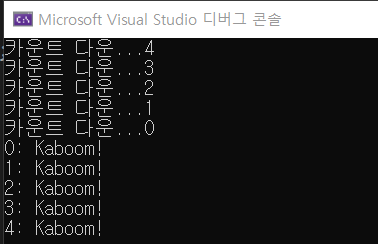
단일 재귀 호출재귀 호출은 함수 안에 함수를 넣는 것이다. 그러면 함수가 무한히 반복되니 빠져나오는 구문을 적는 것이 중요하다. 그 중 하나는 if문을 작성하는 것이다. 실행 결과.이런 재귀 함수의 재밌는 특징은, if 구문 이전의 코드는 순차적으로 진행되지만, 이후의
29.6. 함수(5) - 함수를 지시하는 포인터
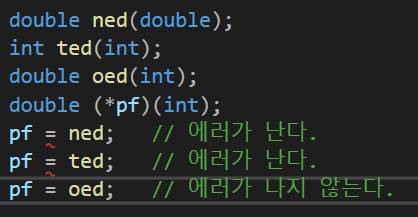
일반 변수와 마찬가지로 함수도 주소를 가지고 있다. 함수의 주소는 함수 선언에서 괄호를 빼면 된다.일반 변수는 포인터를 만드려면 그 가리키는 데이터가 어떤 데이터형인지 알았어야 했다. 함수도 마찬가지이다. 함수 포인터를 만들기 위해서는, 함수의 리턴 데이터형과 매개변수
30.7. 함수의 활용(1) - 인라인 함수
인라인 함수는 프로그램의 실행 속도를 높이기 위해 보강된 것이다. 인라인 함수를 이해하려면, 프로그램의 내부 구조를 깊이 있게 살펴볼 필요가 있다. 프로그램은 위에서 밑으로 순차적으로 실행이 된다. 각각의 명령들은 하나의 특정 메모리 주소를 가진다. 그러다가 일반 함수
31.7. 함수의 활용(2) - 참조 변수(lvalue, rvalue)
참조 변수는 일반 변수에 별명을 붙여주는 거와 다름없다. 왜 그런 행동을 할까? 참조의 주된 목적은 매개변수에 사용하는 것이다. 그러면 그 함수는 복사 데이터가 아니라, 원본 데이터를 가지고 작업을 한다. 참조는 &기호를 붙여서 사용한다.실행 결과.참조 변수를 바꾸면
32.7. 함수의 활용(3) - 디폴트 매개변수
디폴트 매개 변수는 함수의 매개변수를 입력하지 않아도 자동으로 대입해주는, 말 그대로 디폴트 매개변수이다. 다음과 같이 쓴다.디폴트 매개변수는 한 가지 규칙이 있는데, 오른쪽에서 왼쪽 방향으로 채워 나가야 한다.이렇게 하면 매개변수를 따로 입력 안 해도 된다.
33.7. 함수의 활용(4) - 함수 오버로딩
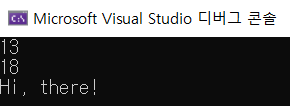
함수 오버로딩은 함수명은 같되 매개변수 자료형을 다르게 쓰는 것이다. 함수의 매개변수 리스트를 시그내쳐라 한다. 컴파일러는 매개변수 자료형에 따라 알맞은 함수를 찾아준다.실행 결과.매개변수에 따라서 각각 다른 함수가 실행되었다.const 연산자 또한 오버로딩이 된다.
34.7. 함수의 활용(5) - 함수 템플릿

지난번에 Swap() 함수를 이용하여 두 인자를 교환하는 코드를 만든 적이 있다. 이 인자가 int였는데, 만약 double형으로 바꾸고 싶다면 어떻게 할까? double형으로 오버로딩하는 방법이 있을 것이다. 하지만 단순히 그런 거 때문에 오버로딩 하는 것보다 더 좋
35.8. 메모리 모델과 이름 공간(1) - 분할 컴파일
C++에서는 메모리에 데이터를 여러 가지 방법으로 저장할 수 있다. 데이터를 메모리에 얼마나 오래 존속시킬 건지, 데이터 접근자에 대한 범위 설정이라던지 등을 선택할 수 있다. 일반적으로 C++는 프로그램을 구성하는 파일들을 분할하여 컴파일한 후에, 그걸 최종 실행 프
36.8. 메모리 모델과 이름 공간(2) - 기억 존속 시간, 사용 범위, 링크

프로그램 내에서 선언한 변수들은 메모리에 저장이 된다. 그리고 변수에 따라서 지속되는 시간이 다르다. 지역 변수먼저 지역변수이다. 지역 변수는 코드 블럭 내에서 선언된 변수를 말한다. 이 변수는 코드 블럭을 나가면 사라지게 된다.만약 변수 이름이 중복이 되면 어떻게 될
37.8. 메모리 모델과 이름 공간(3) - 이름 공간
프로젝트가 커짐에 따라서 변수나 함수 이름이 겹칠 가능성이 생겼다. 이 문제점을 해결할 수 있는 게 이름 공간이다. 이름 공간은 다음과 같이 사용한다.특징은 코드 블럭 외부에서 선언을 해야 한다. 접근은 어떻게 하는가? 범위 연산자를 통해서 하면 된다.각각 Jack 이
38.9. 객체와 클래스(1) - 절차식 프로그래밍 vs 객체 지향 프로그래밍
드디어 클래스다. 게임을 만들 때면 알겠지만, 클래스를 밥 먹을 때 수저 사용하듯 사용한다. 그만큼 중요해서 제대로 알 필요가 있다. (사실 모든 게 중요함.)객체 지향 프로그래밍의 가장 중요한 기능은 다음과 같다.1\. 추상화2\. 캡슐화와 데이터 은닉3\. 다형4\
39.9. 객체와 클래스(2) - 추상화와 클래스

클래스는 다음과 같이 이루어져 있다.생긴 거는 구조체와 비슷하다. 하지만 몇 가지 점에서 다르다. 일단 public과 private를 사용하는데, 클래스의 주요 기능 중 하나인 '데이터 은닉'을 위해서다. 예를 들어 스타크래프트의 마린 공격력이 갑자기 500으로 훌쩍
40.9. 객체와 클래스(3) - 클래스 생성자와 파괴자
클래스를 사용할 때는 일반적으로 '생성자'와 '파괴자'를 써야 한다. 왜? 클래스 안에는 변수들이 있다. 기본적으로 변수들은 초기화를 해주어야 한다. 근데 이 변수들은 private 안에 있기 때문에 멤버 함수를 통해서 초기화를 해주어야 한다. public에 변수를 만
41.9. 객체와 클래스(4) - const 멤버 함수
ㅇ
42.9. 객체와 클래스(5) - this 포인터
this 포인터는 간단하지만 살펴보자. 사실 이전 포스팅에 나왔었다. 예를 들어 한 클래스 내의 'height'라는 변수의 값을 바꾸고 싶다고 하자. 그걸 바꾸기 위한 메서드를 만들려고 한다.만약 매개 변수 이름과 클래스 내 변수 이름이 같다면, 위와 같은 문제가 생긴
43.9. 객체와 클래스(6) - 객체 배열
클래스 객체도 배열처럼 생성할 수 있다. 첫 번째 방법은 디폴트 생성자를 생성한다. 두 번째 방법은 일단 디폴트 생성자를 먼저 생성한 다음에 중괄호 안에 있는 생성자로 임시 객체를 만든 다음에 디폴트 생성자로 만든 객체로 복사를 한다. 그러니 어쨌든 디폴트 생성자가 필
44.10. 클래스의 활용(1) - 연산자 오버로딩
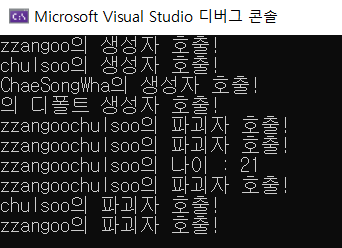
우리가 써왔던 연산자들도 사실은 오버로딩돼있었다. 여기선 클래스 간에 연산자 오버로딩 하는 방법을 알아보겠다. 오버로딩은 함수이므로 함수의 모형을 띄지만 약간 다르다. 가령 이런 식이다.operator은 연산자 오버로딩을 하겠다는 것이고, op 자리에 연산자가 들어오면
45.10. 클래스의 활용(2) - 프렌드 함수
클래스의 private에는 누가 접근이 가능한가? 오직 멤버 함수뿐이다. 하지만 이게 너무 엄격해서, 접근 범위를 넓히려고 한다. 그리고 그걸 '프렌드'라고 부르겠다. 프렌드에는 종류가 3개 있다.1) 프렌드 함수2) 프렌드 클래스3) 프렌드 멤버 함수여기서는 프렌드
46.10. 클래스의 활용(3) - 자동 변환과 클래스의 데이터형 변환

서로 다른 데이터형이 호환이 되면 그 데이터형에 맞춰서 변환된다고 했다. 예를 들어등이 있다. 호환되지 않는 데이터형은 자동으로 바뀌지 않는다.하지만 강제적으로 바꿀 수는 있다.이게 제대로 작동하는지는 또 다른 문제이다.근데 이걸 클래스에서도 가능하다. 가령 이런 클래
47.11. 클래스와 동적 메모리 대입(1) - class 내 static 변수, 복사 생성자, 대입 연산자
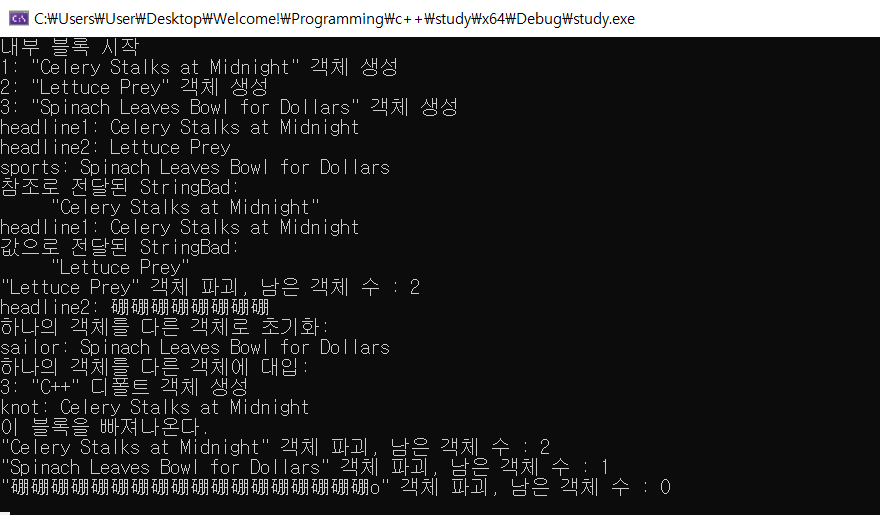
static
48.11. 클래스와 동적 메모리 대입(2) - Queue (Feat. 초기자 리스트, In-Class 초기화)
ㅇ
49.12. 클래스의 상속(1) - 기초 클래스로 연습(상속)
객체 지향 프로그래밍의 목적 중 하나는 재활용 할 수 있는 코드를 쓰는 것이다. 새로운 프로젝트를 개발할 때 입증이 된 이전에 쓰인 코드를 쓰면 버그도 줄일 수 있고, 개발 시간을 크게 절약할 수 있다. 또한 라이브러리에는 매우 많은 함수 혹은 클래스가 있다. 하지만
50.12. 클래스의 상속(2) - public 다형 상속(가상함수, override, final)
가상함수 이전 클래스에서는 기초 클래스의 메서드를 파생 클래스에서 재정의 하는 경우가 없었다. 하지만 실제로는 그런 경우도 생길 수 있다. 그럴 경우는 어떻게 하면 될까? 그리고 왜 그래야 할까? 예를 들어 다음과 같은 메서드가 기초 클래스, 파생 클래스에 모두 정의
51.12. 클래스의 상속(3) - 정적 결합 vs 동적 결합
함수 호출 예전에 객체 지향 프로그래밍을 사용하는 이유가 기억나는가? 크기가 100인 배열을 200개 미리 생성하는 것보다, 실행 도중에 크기에 맞는만큼만 알맞게 메모리를 배정하기 위해서 객체 지향 프로그래밍을 사용한다고 했다.
52.12. 클래스의 상속(4) - 접근 제어: protected
우리는 지금까지 접근 제어 public과 private를 썼다. 하지만 한 가지가 더 있다. 바로 protected다. 일반적으로 볼 때 protected는 private과 비슷하게 public 멤버 함수로만 접근할 수 있다. 한 가지 다른 점은, 파생 클래스에 한해서
53.12. 클래스의 상속(5) - 추상화 기초 클래스
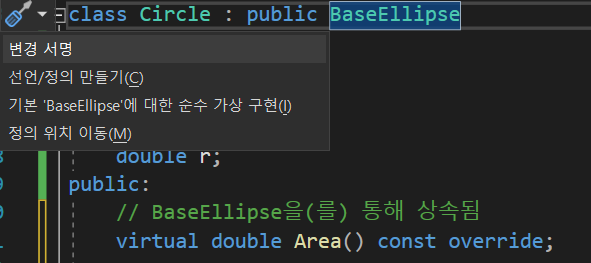
원과 타원의 클래스를 만들어보겠다. 우리가 배운 상속을 이용해서 만들어보자. 그럼 누가 기초 클래스가 되어야 하는가? 가만 보면 타원이 원을 포함한다. 타원에서 장경과 단경이 같으면 원이기 때문이다. 그러므로 타원을 기초 클래스로 해보겠다.자~ 이제 한번 기초 클래스를
54.12. 클래스의 상속(6) - 상속과 동적 메모리 대입
만약 기초 클래스에 동적 할당이 있고 복사 생성자, 대입 연산자가 있으면 파생 클래스에 어떤 영향을 미칠까? (프로그래머의 머리가 깨지는 영향?)case 1: 파생 클래스가 new를 사용하지 않음.위의 기초 클래스에는 동적 할당 변수, 복사 연산자, 대입 연산자가 있다
55.13. C++ 코드 재활용(1) - private 상속
C++가 추구하는 목표 중 하나가 코드의 재활용이었는데, 지금까지 우리는 이를 상속을 통해서 실현했다. 이번에는 다른 방법들을 알아보겠다. 첫 번째 방법은 클래스 객체 안에 클래스 객체를 쓰는 건데, 교재에선 valarray 클래스를 사용했다. 난 처음 보는데 뭔가
56.13. C++ 코드 재활용(2) - protected 상속
protected 상속도 비슷하게 사용한다.protected 상속에서는 기초 클래스의 public, protected멤버가 파생 클래스의 protected 멤버가 된다. private 상속과 마찬가지로, 기초 클래스의 인터페이스를 받을 수는 있지만, 바깥 세계에서 사용
57.13. C++ 코드 재활용(3) - 다중 상속(가상 기초 클래스)
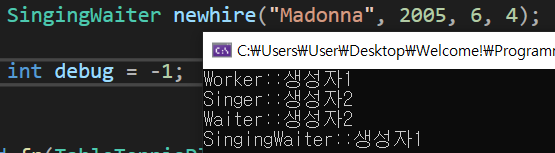
다중 상속은 두 개 이상의 기초 클래스로부터 상속 받는 것이다. 일일이 public같은 키워드를 적어주어야 한다. 그렇지 않으면 private으로 인식하기 때문이다. 다형 상속은 새로운 문제를 발생시킨다. 몇 가지 클래스를 만들어 보자. 저기서 Set 함수가 출력
58.13. C++ 코드 재활용(4) - 클래스 템플릿(스택)
코드를 재활용하는 다음 방법으로는 템플릿을 이용하는 방법이 있다. 예전에 Stack 클래스를 만들어본 적이 있다. 그 클래스는 데이터형으로 unsinged long을 가졌다. 데이터형을 double이나 string으로 바꿀 수도 있었을 것이다. 물론 그때 데이터형 이외
59.14. 프렌드, 예외, 기타사항(1) - 프렌드(프렌드 클래스, 프렌드 멤버 함수, 상호 프렌드, 공유 프렌드)
저번에 연산자 오버로딩 한 다음에 3가지의 프렌드 기능 중에 프렌드 함수만 배웠다. 이번엔 나머지를 알아보겠다. 클래스도 프렌드가 될 수 있는데, 이 경우에는 프랜드 클레스의 모든 메서드는 오리지널 클래스의 private 멤버와 protected 멤버에 접근할 수 있다
60.14. 프렌드, 예외, 기타사항(2) - 내포 클래스
클래스 선언을 클래스 안에서 하면 그걸 '내포 클래스'라고 부른다. 멤버 변수들이 많을 때나, 같은 이름의 다른 클래스가 있을 때, 내포 클래스를 활용하면 이름이 난잡해지는 것을 방지할 수 있다. 이와 비슷하지만 다른, 클래스 안에 클래스 객체를 생성하는 컨테인먼트도
61.14. 프렌드, 예외, 기타사항(3) - abort
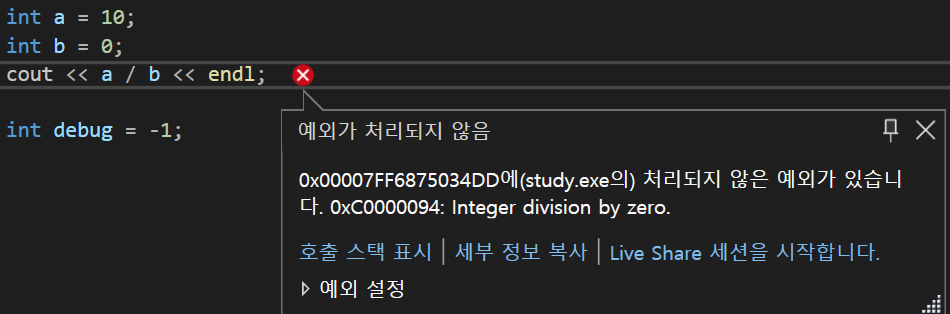
프로그램을 실행하다 보면, 예상치 못한 일들을 많이 만난다. 이런 재난들을 기다리는 것보다는, 미리 예방하는 게 좋을 것이다. 몇 가지 예시를 알아보자.이런 구문을 실행하면 어떻게 되는가?실행 결과.실행하고 나서야 어쩌구 저쩌구 나온다. 우리의 목적은 미리 예방하는 것
62.14. 프렌드, 예외, 기타사항(4) - try-catch
이번엔 try-catch를 알아보겠다. 일단 예제를 보자.실행 결과.예외가 일어날만한 구문을 try 코드 블럭 안에 쓴다. 그리고 throw에는 예외가 발생하면 던져줄(?) 코드를 작성한다. Hmean 함수가 실행 되고 예외가 발생하면 if 문에 들어가서 throw를
63.14. 프렌드, 예외, 기타사항(5) - RTTI(dynamic_cast)
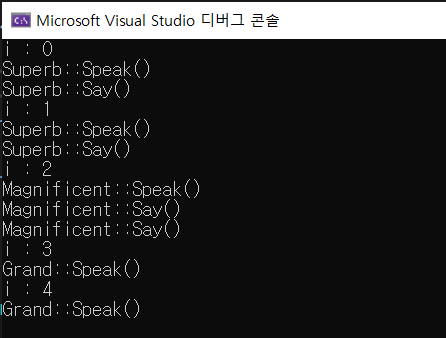
RTTI는 'runtime type identification의 약자로, 실행 시간 데이터형 정보라는 뜻이다. 실행 도중에 데이터형을 결정하는 표준 방법을 제공한다는데, 그 종류 하나하나 배워보면 뭔 말인지 알 것이다.기초 클래스와 파생 클래스 간에 형 변환인 업캐스팅
64.14. 프렌드, 예외, 기타사항(6) - 데이터형 변환 연산자(const_cast, static_cast, reinterpret_cast)
일반적으로 데이터형 변환은 변환하고 싶은 변수 앞에 '(데이터형)변수' 뭐 이런 식으로 쓴다. 근데 이게 좀... 불안정하다고 한다. 그래서 이걸 강화하고자 4개의 데이터형 변환을 만들었다. dynamiccast는 저번에 배웠고, constcast부터 알아보자. co
65.15. string 클래스와 표준 템플릿 라이브러리(1) - string 클래스

흔히 쓰이는 string 클래스에 대해 알아보자. string 클래스는 string 헤더 파일에 있다.string::npos는 일반적으로 가장 큰 unsigned int이다. static 멤버라서 범위 연산자를 통해 쓸 수 있다.이와 비슷하게 rfind(), find_
66.15. string 클래스와 표준 템플릿 라이브러리(2) - 스마트 포인터
동적 할당은 유용하다. 근데 좀 귀찮은 게 있다. 바로 delete이다. 귀찮지만 안 적으면 매우 위험하다. 그래서 우리가 해야 할 건 "주의하기". 하지만 가끔씩 까먹을 때가 있다. 그럴 때를 위해 '스마트 포인터'를 만들었다.스마트 포인터는 3개(auto_ptr,
67.15. string 클래스와 표준 템플릿 라이브러리(3) - 표준 템플릿 라이브러리(vector, emplace_back)
표준 템플릿 라이브러리(STL : Standard Template Library)는 컨테이너, 이터레이터, 함수 객체, 알고리즘을 나타내는 템플릿들의 집합을 제공한다. 이를 통해 검색, 정렬, 무작위화 등등 더 다양한 코드를 짤 수 있게 도와주는 그런 도구라고 생각하면
68.15. string 클래스와 표준 템플릿 라이브러리(4) - 함수 객체(Functor)
많은 STL 알고리즘들이 펑크터(Functor)라고 부르는 함수 객체를 사용한다. 펑크터는 함수처럼 ()와 함께 쓸 수 있는 객체다. 일반 함수의 이름, 함수를 지시하는 포인터, () 연산자 오버로딩된 클래스 객체(operator()), 즉 ()가 붙은 해괴망측한 것들
69.15. string 클래스와 표준 템플릿 라이브러리(5) - 알고리즘
알고리즘은 배열을 소트하거나 리스트에서 특정한 값을 검색하는 것과 같은 특별한 작업들을 수행하기 위해 사용하는 방법이다. 교재에서는 분류하고 뭐 하고 그러던데, 개념적인 거 보다는 함수 하나하나 나올 때마다 기록하는 게 좋은듯.
70.16. 입력, 출력, 파일(1) - C++ 입출력의 개요(스트림, 버퍼)
이번엔 지금까지 써왔던 입출력에 대해서 알아보자.C++은 입력과 출력을 바이트들의 흐름(스트림)이라 간주한다. 입력 시 프로그램은 입력 스트림으로부터 바이트들을 추출하고, 출력 시에는 출력 스트림에 바이트를 삽입한다. 이 바이트들은 수치 데이터나 문자의 2진 표현을 나
71.16. 입력, 출력, 파일(2) - cout을 이용한 출력
우리는 지금까지이런 구문들을 많이 이용해왔다. 이것은 사실 ostream에 오버로딩돼있던 '삽입 연산자'이다. 삽입 연산자는 int나 double같은 C++의 모든 기본 데이터형들을 인식할 수 있도록 오버로딩돼있다. 아마 원형은 이런 꼴일 것이다.리턴형이 참조이기 때문
72.16. 입력, 출력, 파일(3) - cin을 이용한 입력
이번엔 cin이다. 일반적으로 cin은 다음과 같이 사용한다.여기서 value_holder은 입력을 저장할 메모리 위치이다. 여기도 여러 가지 메서드가 나오는데 뭔가 필요하다고 느껴지지가 않네 ㄷㄷ.
73.16. 입력, 출력, 파일(4) - 파일 입력과 출력

게임 데이터들은 굉장히 많다. 유닛의 공격력, 방어력, 체력에서 시작하여 밸런스를 조정하는 숫자들... 그런 걸 프로그램에서 일일이 다루기보다는 엑셀같은 파일로 딱 보는 게 편할 것이다. 그래서 우리는 프로그램과 파일을 연결시키는 방법, 프로그램이 파일의 내용을 읽는
74.16. 새로운 C++(1) - Move Semantics과 Rvalue 참조(이동 대입)

예전에 했던 StringBad.cpp를 보자.덧붙여 이런 코드를 적으면 어떨까?실행 결과.여기서 StringBad c(a.Rvalue(b));를 잘 보자. Rvalue() 메서드는 다음과 같았다.객체 c의 매개변수로 만든 임시 객체를 만들어주었는데, 이것을 삭제하고 다
75.16. 새로운 C++(2) - 새로운 클래스 형태(default, delete)
지금까지 클래스의 다양한 생성자와 연산자에 대해서 배웠다. 이들은 따로 정의하지 않으면 각각 디폴트 함수들이 호출된다. 이를 명시적으로 표현하는 방법이 있다. default와 delete를 이용하면 된다. default는 컴파일러가 제공하는 생성자를 이용하겠다는 뜻이고
76.16. 새로운 C++(3) - 람다 함수

람다를 알아보기 위해서 아주 알찬 프로그램을 만들어보자. 랜덤 정수 리스트를 작성하고 3, 13으로 나뉘는 게 각각 몇 개 있는지 살펴보자. vector와 STL generate() 알고리즘을 이용해보자.실행 결과.gernerate()의 제1 매개변수, 제2 매개변수는
77.16. 새로운 C++(4) - 래퍼(Wrapper)
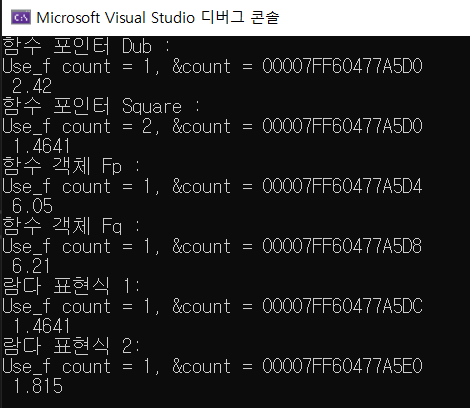
다음 코드를 보자.이 코드에서 Use_f 템플릿 함수는 6번 호출된다. 그럼 static 멤버 변수도 6이 될까?실행 결과.실행해보니 그렇지 않다. 멤버 변수의 주소를 통해 1,2번째를 제외한 나머지 static 멤버 변수의 주소가 다 다르다는 걸 알 수 있다. 왜 이
78.16. 새로운 C++(5) - 가변인자 템플릿
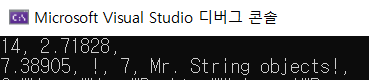
만약 2개 이상의 매개변수를 받는 템플릿을 작성할 건데, 그 매개변수 개수가 몇 개가 될지 모른다면 어떻게 할 것인가? 그럴 때 가변인자 템플릿을 쓴다. 다음과 같이 쓴다.저 '...'은 뒤에 생략이 돼있다는 뜻이 아니라, 진짜 쩜쩜쩜을 적은 것이다. 물론 의미는 여러
79.17. 비트 연산자
비트 연산자들은 정수값을 구성하는 비트들에 적용된다. 비트 연산자의 종류는 다음과 같다.왼쪽 시프트 연산자는 다음과 같이 쓴다.여기서 value는 정수값이고, shift는 시프트 비트 수이다. <<는 시프트 연산자다. 이는 value의 모든 비트들을 왼쪽에
80.18. 멤버 내용 참조 연산자
C++에서는 클래스의 멤버들을 지시하는 포인터를 정의할 수 있다. 간단한 예제를 보자.여기서 Example안에 있는 멤버 변수를 대상으로 포인터를 만들어보자.이렇게 하면 된다. 하지만 일반 포인터랑은 약간 다르다. 일반 포인터는, 변수의 주소를 가리켰다. 그러나 멤버
81.static 클래스 변수 동적 할당
성장 신호가 생겼다. 클래스 A 안에 클래스 B 변수를 만들어서, 이를 모든 클래스 A가 공유하는 변수로 만들어주고 싶었다.당연히 static이 들어가야 할 것이고,초기화는 이런 식으로 했다.이렇게 하면 어떤 상황이 펼쳐지나? 기껏 공유하려고 만들었던 변수 b인데, 생