함수 오버로딩은 함수명은 같되 매개변수 자료형을 다르게 쓰는 것이다. 함수의 매개변수 리스트를 시그내쳐라 한다. 컴파일러는 매개변수 자료형에 따라 알맞은 함수를 찾아준다.
int Add(int value1, int value2);
double Add(double value1, double value2);
string Add(string str1, string str2);
int main()
{
int integer = Add(5, 8);
double doubling = Add(5.0, 8.0);
string str = Add("Hi,", " there!");
cout << integer << endl;
cout << doubling << endl;
cout << str << endl;
}
int Add(int value1, int value2)
{
return value1 + value2;
}
double Add(double value1, double value2)
{
return value1 * 2 + value2;
}
string Add(string str1, string str2)
{
return str1 + str2;
}실행 결과.
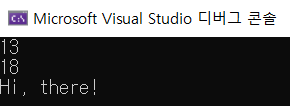
매개변수에 따라서 각각 다른 함수가 실행되었다.
const 연산자 또한 오버로딩이 된다.
void dribble(char* bits);
void dribble(const char* cbits);
void dabble(char* bits);
void drivel(const char* bits);
const char p1[20] = "Hi, there!";
char p2[20] = "This is for you!";
dribble(p1); // dribble(const char*)
dribble(p2); // dribble(char*)
dabble(p1); // 대응하는 함수가 없다.
dabble(p2); // dabble(char*)
drivel(p1); // drivel(char*)
drivel(p2); // drivel(char*)dabble과 drivel를 보면, char*은 const char*를 받을 수 없지만, const char*은 char*과 const char* 둘 다 받을 수 있다는 것을 알 수 있다.
반면 참조 변수는 오버로딩이 안된다. 컴파일러 입장에서 어떤 함수를 사용해야 할지 모르기 때문이다.
double cube(double x);
double cube(double& x); // 어느 것을 사용해야 할까?오버로딩은 과용하지 말고 되도록 같은 임무를 수행하도록 만드는 것이 헷갈리지 않고 좋다.

Question, Think, Select