클래스를 사용할 때는 일반적으로 '생성자'와 '파괴자'를 써야 한다. 왜? 클래스 안에는 변수들이 있다. 기본적으로 변수들은 초기화를 해주어야 한다. 근데 이 변수들은 private 안에 있기 때문에 멤버 함수를 통해서 초기화를 해주어야 한다. public에 변수를 만든다면 멤버 함수를 안 써도 되겠지만 그건 데이터 은닉을 위반하는 방법이다. 그 맨 처음에 초기화를 담당하는 멤버 함수를 '생성자'라고 한다. 일반적으로 모든 객체는 생성될 때 초기화 시키는 게 좋다.
- 생성자 특징
생성자의 이름은 클래스의 이름과 같다. 또한 리턴값이 없는데도 불구하고 void형으로 쓰지 않는다. 생성자는 객체가 생성될 때 동시에 호출이 된다.
다음은 클래스 생성자 예이다.
class Student
{
public:
Student(int age, float height); // 생성자.
~Student(); // 파괴자.
private:
int age;
float height;
};
int main()
{
Student chulsoo(10, 165.5f); // 객체 생성과 동시에 생성자 호출. 일반적으로 이렇게 사용.
Student yuri = Student(9, 152.3f); // 이런 방법도 가능.
Student *Mangoo = new Student(11, 172.2f); // 동적 할당도 가능.
}
Student::Student(int age, float height) // 리턴형이 없는 함수 머리.
{
this->age = age; // this는 나중에 배운다. private의 변수를 가리켜 매개변수와 구분 시켜준다.
this->height = height; // 일반적으로 멤버 변수 초기화.
}- 디폴트 생성자
디폴트 생성자는 딱히 초기화 할 게 없을 때 쓰이는 생성자다. 생성자를 안 만들고 객체를 생성하면 자동으로 실행된다. 실행만 되지 딱히 하는 일은 없다. 아마 구문으로 만들면 다음과 같을 것이다.
Student::Student() { }이것은 마치 초기화를 안 한 변수랑 같다.
int x;만약 개발자가 일반적인 생성자를 만들었다? 그러면 디폴트 생성자를 따로 만들어야지 디폴트 생성자 사용이 가능하다. 왜? 디폴트 생성을 개발자가 원하지 않을 수도 있기 때문이다. 디폴트 생성자는 두 가지 방법으로 만들 수 있다.
Student::Student(); // 아무 것도 안 적는 첫 번째 방법.
Student::Student(int age = 10, float height = 160.0f); // 모든 매개 변수에 디폴트 값을 넣는 두 번째 방법.하나의 디폴트 생성자만 가질 수 있기 때문에 둘 다 사용하는 건 안된다. 하지만 일반적으로 객체의 변수들은 초기화 되어야 하기 때문에 이런 식으로 쓴다.
Student::Student() // 디폴트 생성자.
{
age = 20;
height = 185.2f;
}- 파괴자
객체를 생성하면 생성자가 나오듯이, 객체의 사용이 끝나면 파괴자가 나온다. 사용이 끝난 걸 어떻게 아는가? new를 사용해 동적 할당을 하고 사용을 마칠 때의 delete가 그 예시이다. (메모리 절약에 힘 써주는 것 같아서 아주 마음에 든다.) new가 없으면? 코드 블럭 안에서 생성했으면 그 코드 블럭이 끝날 때, 이외에는 프로그램이 종료될 때 파괴자가 실행 된다.
파괴자는 어떻게 만드는가? 위에도 눈치채지 못하게 저었지만 클래스명 앞에 물결표(~)를 붙이면 된다.
~Student();파괴자는 파괴하는 것 이외에는 딱히 할 일이 없으니 다음과 같이 코딩할 수 있다.
Student::~Student()
{
}언제 호출되는지 궁금하면 간단한 문구를 넣을 수 있다.
Student::~Student()
{
cout << "Student의 파파괴괴자." << endl;
}- 클래스 코딩
헤더 파일과 cpp 파일을 구분해서 클래스의 예시를 하나 만들어보겠다.
Student.h
#pragma once
#include <iostream>
#include <string>
using namespace std;
class Student
{
public:
Student(string name, int age, float height);
~Student();
void SetHeight(float height);
float GetHeight();
int GetAge();
private:
string name;
int age;
float height;
};
Student.cpp
#include "Student.h"
Student::Student(string name, int age, float height)
{
cout << name << "의 생성자 호출!" << endl;
this->name = name;
this->age = age;
this->height = height;
}
Student::~Student()
{
cout << this->name << "의 파괴자 호출!" << endl;
}
void Student::SetHeight(float height)
{
cout << "키가 " << height << "으로 컸네?" << endl;
this->height = height;
}
float Student::GetHeight()
{
return this->height;
}
int Student::GetAge()
{
return this->age;
}
main.cpp
#include "Student.h"
int main()
{
Student yuri("yuri", 12, 163.5f);
cout << "유리의 나이 : " << yuri.GetAge() << endl;
{
Student* mangoo = new Student("mangoo", 11, 172.5f); // 동적 할당이라 delete를 써주지 않으면 파괴자 호출이 안 된다.
Student zzangoo("zzangoo", 12, 163.5f); // 동적 할당이 아닌 객체 생성은 코드 블럭이 끝나면 파괴자가 호출 된다.
}
Student *chulsoo = new Student("chulsoo", 13, 158.8f);
cout << "철수의 키 : " << chulsoo->GetHeight() << endl;
chulsoo->SetHeight(162.0f);
cout << "철수의 키 : " << chulsoo->GetHeight() << endl;
delete chulsoo;
}실행 결과.
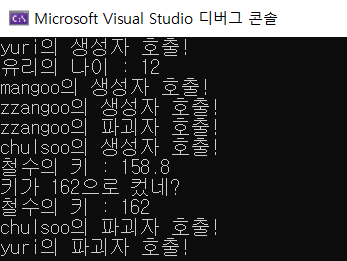
클래스의 선언은 Student.h 헤더 파일에, 메서드의 정의는 Student.cpp cpp파일에 적었다. main.cpp에서 Student 객체를 만들어서 메서드를 이용할 때, 사용자가 그 메서드의 코드 내용을 다 알 필요가 있을까? 쓰는 사람 입장에서는 그 기능만 제대로 알면 되지 복잡한 코드 내용을 알 필요는 없다. 이렇게 나누어 쓰는 것을 '캡슐화'라고 한다. 흔히 약국에서 먹는 캡슐 안에는 한 가지 혹은 여러 가지의 약 가루가 들어있을 것이다. 약사가 아니고서는 웬만하면 이 가루에 궁금증을 가지지는 않을 것이다. 메서드도 마찬가지다. 덕분에 우리도 std::cout이나 std::string같은 복잡한 메서드를 편하게 쓰고 있지 않는가?
위의 코드에서 yuri, chulsoo 생성자와 파괴자 문구를 비교해 보면, 언제 생성되고 언제 파괴되는지 구분할 수 있을 것이다. 또한 동적 할당을 사용해서 생성한 객체는 delete를 쓰지 않으면 파괴자가 호출 안 된다는 사실을 반드시!!!! 알아야 한다.
