
Reactor 특징
-
Reactor는 리액티브 스트림즈(Reactive Streams)를 구현한 리액티브 라이브러리이다.
-
Non-Blocking은 리액티브 프로그래밍의 핵심적인 특징이며, Reactor 역시 완전한 Non-Blocking 통신을 지원한다.
-
Reactor는 Publisher 타입으로 Mono[0|1]와 Flux[N]이라는 두 가지 타입을 제공한다.
-
Mono[0|1]에서 0과 1의 의미는 0건 또는 1건의 데이터를 emit 할 수 있음을 의미한다.
-
Flux[N]에서 N의 의미는 여러 건의 데이터를 emit할 수 있음을 의미한다.
-
-
서비스들 간의 통신이 잦은 MSA(Microservice Architecture) 기반 애플리케이션에 Non-Blocking 통신을 완벽하게 지원하는 Reactor는 적합한 라이브러리이다.
-
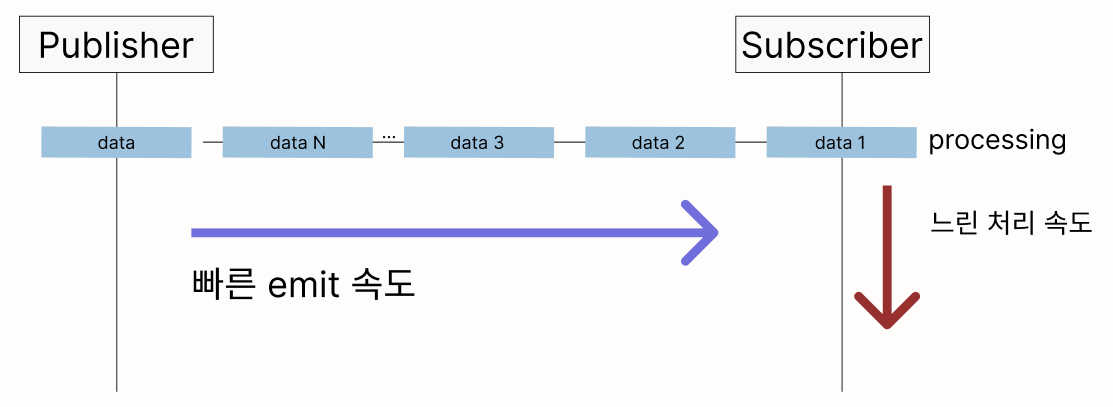
리액티브 프로그래밍에서는 끊임없이 들어오는 데이터를 적절하게 처리할 수 있어야 한다. 그림과 같이 Publisher에서 끊임없이 들어오는 데이터를 emit하는 것과 달리 Subscriber의 처리 속도가 느리면 데이터가 지속적으로 쌓여 오버플로우가 발생하게 되고 시스템이 다운될 수도 있다.
Backpressure란 그림에서 보다시피 Subscriber의 처리 속도가 Publisher의 emit 속도를 따라가지 못할 때 적절하게 제어하는 전략을 의미한다.
Reactor 구성 요소
import reactor.core.publisher.Flux;
import reactor.core.scheduler.Schedulers;
public class HelloReactorExample {
public static void main(String[] args) throws InterruptedException {
Flux // 1
.just("Hello", "Reactor") // 2
.map(message -> message.toUpperCase()) // 3
.publishOn(Schedulers.parallel()) // 4
.subscribe(System.out::println, // 5
error -> System.out.println(error.getMessage()), // 6
() -> System.out.println("# onComplete")); // 7
Thread.sleep(100L);
}
}-
Reactor Sequence의 시작점이다. (1)에서 Flux로 시작한다는 것은 Reactor Sequence가 여러 건의 데이터를 처리함을 의미한다.
-
just()Operator는 원본 데이터 소스로부터(Original Data Source) 데이터를 emit하는 Publisher의 역할을 한다. -
map()Operator는 Publisher로부터 전달 받은 데이터를 가공하는 Operator다. (3) 에서는just()Operator에서 emit된 영문 문자열을 대문자로 변환하고 있다.Reactor에서는
map()Operator처럼 데이터를 가공 처리할 수 있는 수많은 Operator를 지원한다.
-
publishOn()Operator는 Reactor Sequence에서 쓰레드 관리자 역할을 하는 Scheduler를 지정하는 Operator다.(4)와 같이
publishOn()Operator에 Scheduler를 지정하면 publishOn()을 기준으로 Downstream의 쓰레드가 Scheduler에서 지정한 유형의 쓰레드로 변경된다.즉, 코드에서는 Reactor Sequence 상에서 두 개의 쓰레드가 실행된다.
-
코드에서
subscribe()는 파라미터로 총 세 개의 람다 표현식을 가지는데 (5)의 첫 번째 파라미터는 Publisher가 emit한 데이터를 전달 받아서 처리하는 역할을 한다. -
두 번째 파라미터는 Reactor Sequence 상에서 에러가 발생할 경우, 해당 에러를 전달 받아서 처리하는 역할을 한다.
-
세 번째 파라미터는 Reactor Sequence가 종료된 후 어떤 후처리를 하는 역할을 한다. Reactor Sequence가 정상적으로 종료되면 동작을 수행한다.
Reactor Sequence에 Scheduler를 지정하면 main 쓰레드 이외에 별도의 쓰레드가 하나 더 생긴다.
Reactor에서 Scheduler로 지정한 쓰레드는 모두 데몬 쓰레드이기 때문에 주 쓰레드인 main 쓰레드가 종료되면 동시에 종료된다.
따라서 main 쓰레드를
Thread.sleep(100L)을 통해 0.1초 정도 동작을 지연시키면 그 0.1초 사이에 Scheduler로 지정한 데몬 쓰레드를 통해 Reactor Sequence가 정상 동작을 하게 된다.
-
코드의 흐름
메인 스레드와 데몬 스레드는 거의 동시에 실행이 된다.
.publishOn(Schedulers.parallel()) // 4
.subscribe(System.out::println, // 5
error -> System.out.println(error.getMessage()), // 6
() -> System.out.println("# onComplete")); // 7위 코드의 내용들이 데몬 스레드인데, 메인과 데몬 스레드가 동시에 실행되다가 메인 스레드의 실행이 종료되면, 데몬 스레드의 내용들이 출력되지 않는다. 메인 스레드가 종료되기 전에 Thread.sleep(100L); 의 코드를 추가하여 0.1초 간의 텀을 주어서 데몬 스레드의 값들이 정상 실행되도록 한다.
