
이 포스트는 널널한 개발자님의 강의를 듣고 작성한 글입니다.
CPU도 당신처럼 미리 예측하고 움직인다.
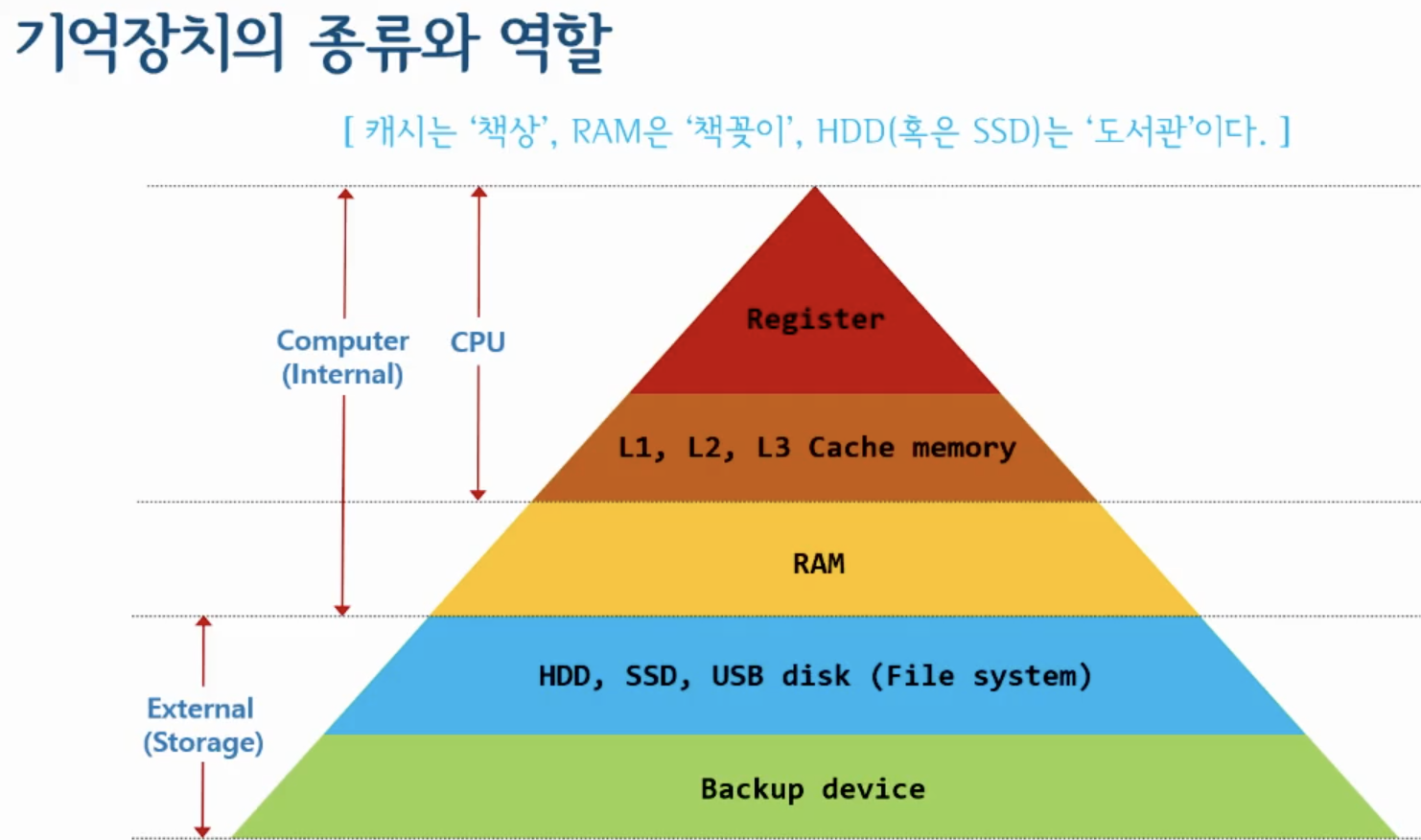
CPU는 연산장치다. 연산장치에서 중요한 것은 연산 속도인데 연산속도가 올라갈 수록 연산 양이 늘어나고 처리속도가 올라가 성능이 올라간다. 즉, 클럭속도를 올리는 방향으로 CPU가 개발되다가 어느 순간 한계를 맞아 코어 개수를 늘리는 방향으로 개발되어가고 있다.
여기서 코어는 CPU의 연산처리를 맡아서 한다. 연산을 처리할 데이터는 RAM에 존재한다. 그레서 RAM의 데이터를 CPU 영역까지 읽고 쓰는 것을 반복한다. 그런데 문제는 CPU 안에 레지스터와 RAM의 속도차이가 엄청 커서 그 중간에 완충역할을 하는 애가 있는데 바로 캐시 메모리이다.
캐시 메모리는 종류가 3가지로 나뉘는데 코어마다 붙어있는 L1,L2 캐시메모리가 존재하고 (제조사마다 다름.) CPU에 1개만 존재하는 L3 캐시메모리가 존재한다. 이렇게 캐시메모리를 나누어 놓은 이유는 데이터 양때문이다. L1은 명령과 데이터로 구분이 되고, L2는 이 2개가 섞여있다. L3는 각 코어마다 명령, 데이터가 섞여있어서 L3에서 각 코어별로 명령과 데이터를 올려보낸다.
즉, 캐시메모리는 레지스터와 RAM의 속도차이를 극복해주는 역할을 한다. 그런데 조금 더 재밌는것은 예측은 캐시메모리에서 하는데 이 연산을 캐시가 예측을 할 수 있다. 캐시메모리가 예측을 해서 데이터를 미리 캐시에 담는다. 그리고 코어가 데이터를 필요로 할때 RAM한테 바로 요청하지 않고 먼저 캐시메모리에게 요청을 한다. 해당 데이터가 캐시에 있으면 예측을 성공했다하고 전문용어로 캐시히트되었다고 한다. 이렇게 해서 성능을 높인다. 하지만 예측이 실패가 되면 캐시미스가 되었다고 하고 이럴 경우 RAM한테 정보를 요청한다. 이럴 경우 RAM한테 바로 요청하는거에 비해 속도가 느리지만 캐시미스가 날 확률은 10%밖에 안되므로 캐시메모리를 사용하는 것이 효율적이다.
정리하자면 RAM의 정보들을 미리 예측하여 CPU가 캐시 메모리에 저장을 해두어서 RAM에서 복사하는 과정을 최소화한다. 물론 CPU 예측이 틀려서 fault가 날 때는 RAM에서 정보를 복사해와야 하는 경우가 있다. 만약 RAM에도 찾는 정보가 없다고 하면 2차메모리에서 찾아야 하고 거기도 없으면 예외가 발생한다. 프로그래밍으로 치면 NullPointerException이 발생하는 것이다.
그럼 예를 들어 언제 캐시메모리가 사용하는지 알아보자. 우리가 코드로 반복문을 실행한다고 보자. 0~99까지 출력을 하는 로직의 코드를 작성한다고 했을 때 이 데이터를 캐시메모리가 미리 가져다 놓는다.
하지만 문제가 있는데, CPU는 너무 고성능이라 엄청 빠른데 RAM은 너무 느리다. 그래서 캐시 메모리가 나왔는데 이렇게 해서 성능을 극대화 해왔다. CPU는 연산하는 장치이고 RAM은 데이터와 명령을 담는 장치인데 이 명령과 데이터를 CPU로 가져와서 옮겨서 하는 구조인데 이 페러다임이 요즘 바뀌고 있다.
요즘은 CPU말고도 연산하는 장치가 있는데 바로 GPU다. GPU는 코어가 4000개정도 되는데 CPU에 비해 코어성능이 떨어진다. 하지만 병렬로 구성되어 있고 개수가 많기 때문에 CPU와 하는 역할 자체가 다르다. 예를 들어 인형 눈을 붙이는 작업은 이 작업을 하나도 안 해본 대학원생보다 이것을 많이 해본 장인이 더 적절할 것이다. 즉, GPU는 비트코인 채굴도 하지만 AI 인공지는 연산도 한다. 이로 인해 데이터처리가 많이 일어나는데 또 패러다임이 바뀌는게 PIM이 부상되어서 RAM에서 전처리 연산을 하는 구조로 바뀌고 있다.
예를 들어 요리사가 있고 그 밑에 조수들이 있다. 요리사는 조수들에게 내일 요리를 위해 감자를 깎아놓으라고 명령을 내린다. 그래서 조수들은 감자를 깎지만 PIM은 내일 요리가 어떤 메뉴인지 확인하고 그에 맞게 감자를 깎고 다져놓는 작업까지 하는것으로 비유를 할 수 있다.
