
이 포스트는 널널한 개발자님의 강의를 듣고 작성한 글입니다.
DMA와 고성능 소켓
DMA를 알면 고성능 소켓이 보인다.
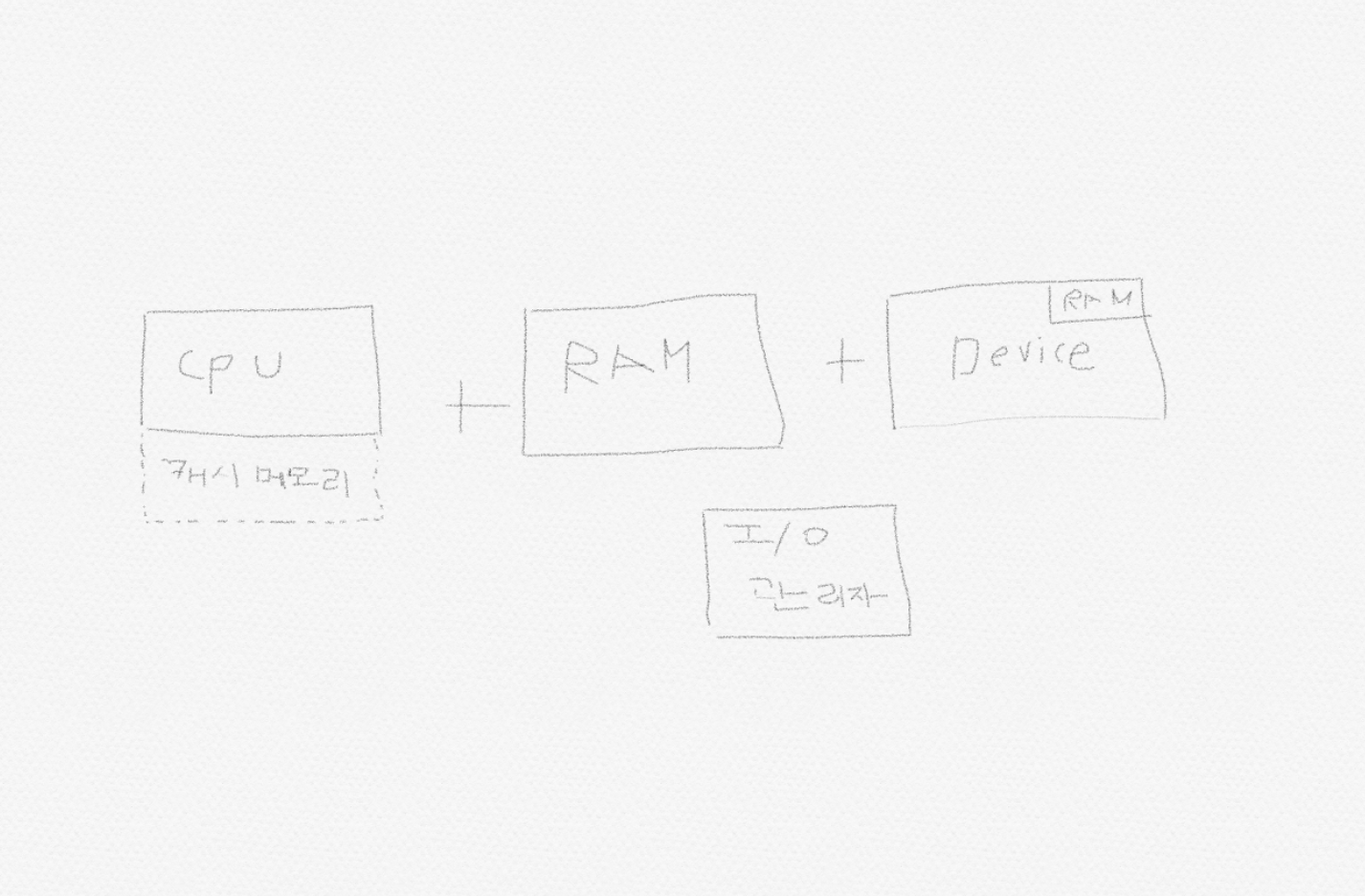
위 그림은 저번 포스팅에서 이야기 했던 과정이다. 여기서 I/O 관리자는 CPU가 어떤 장치한테 뭔가를 직접 가져오면 장치가 반응이 늦을 것을 대비하여 I/O관리자가 도와준다. 또한 RAM의 일부를 Device를 위해 예약을 걸수도 있는데 이 과정에서 I/O관리자한테 알려준다.
CPU가 어떤 장치한테 정보를 보내는 방법
- CPU가 RAM의 예약된 메모리에 정보를 보낸다. (복사)
- 어떤 경우는 데이터가 RAM의 내부에서 또 일어난다. (복사)
- 복사된 데이터를 장치의 RAM에 또 복사한다.
이 모든 과정에서 I/O 매니저는 역할을 수행한다. 근데 의문점이 이렇게 복사하는게 아니라 한번에 CPU에서 Device로 보낼 수 있는 방법은 없을까?
CPU에서 Device로 한번에 보내거나 또는 CPU가 RAM의 일부를 복사할텐데 Device가 그 부분을 Direct로 Write한다. (I/O 매니저 없이) 바로 이 방법이 DMA이다. 이 이야기가 NIC(Network Interface Card)에서 많이 나온다.
DMA
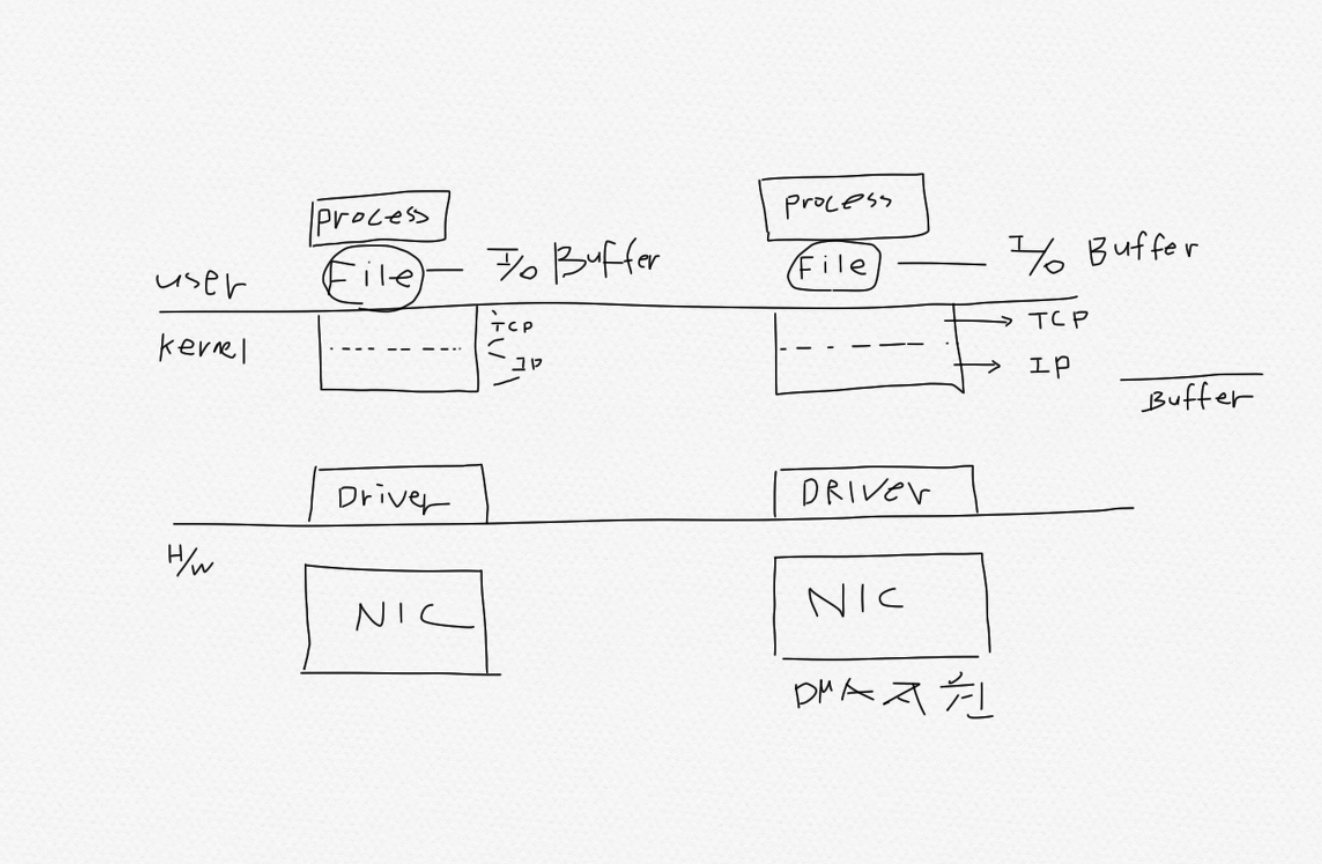
DMA란 연산을 처리하는 과정에서 데이터를 계속 복사를 안하고 그냥 데이터를 쓱 주변기기에 직접 전달하는 것을 말한다.
File에는 어떤 장치를 추상화한것이고 File에는 I/O 버퍼가 딸려있다. 여기서 데이터를 N/W를 통해 수신하는 경우 Kernel의 System call 부분이 TCP, IP로 나뉘고 이때 File을 Socket이라고 불린다.
H/W Device가 NIC라고 하면,
- Process내의 네트워크로 송신할 데이터를 적재한다.
- Process가 I/O 버퍼에 Write를 한다. 정확히는 Socket에다가 Send를 한다.
- 그러면 네트워크 데이터가 I/O 버퍼에 적재된다.
- Kernel 영역으로 내려오면서 Segmanation이 일어난다.
- I/O 버퍼 데이터가 쪼개져서 Kernel 영역의 Buffer에 복사를 한다.
- 커널 영역의 Buffer의 데이터를 NIC에 보내고 그걸 네트워크에 보낸다.
그런데 보면 이 Process 메모리, I/O Buffer, Kernel Buffer도 다 RAM 메모리이다. 즉, NIC가 DMA를 지원하면 수 많은 메모리를 안 거치고 바로 process 메모리로 간다. 예를 들어 C언어의 malloc 함수를 사용하여 할당을 받았다고 해보자. 할당받은 영역은 heap영역 어딘가일테고 이 메모리는 user mode application 메모리이다. 그런데 IOCP를 이용하면 heap 영역을 kernel에서 쓸꺼라고 OS가 Lock을 건다, 한마디로 찜이다. 즉, 과정이 단계를 안 거치고 바로 복사된다. 그 이유는 다 똑같은 RAM 메모리이기 때문이다.
더 대박인 경우는 가상화 클라우드 환경일때이다. A 클라우드에서 B 클라우드로 데이터를 송수신할때 가상화환경이고 NIC가 DMA를 지원하면 일종의 복사처럼 엄청 빨리 일어난다. 그 이유는 A클라우드, B클라우드 둘다 똑같은 RAM 메모리를 참조하기 때문이다.
