[Deeplearning Andrew Ng강의_2] : Improving Deep Neural Networks: Hyperparameter Tuning, Regularization and Optimization #2
DeepLearning Study
Optimization Algorithms -> Faster!!
1. Mini-Batch gradient descent
5,000,000개의 데이터를 학습시킨다 가정했을 때
데이터를 한번에 학습하는 'Batch'(BGD) 또는 데이터를 하나하나 학습하는 'Stochastic'(SGD)의 경우 시간이 너무 오래걸리고 local minima에 빠지기 쉽다.
하지만 이를 해결하기 위한 방법인 Mini-Batch의 경우 1000개의 데이터를 5000개의 묶음으로 학습함으로써 위 문제를 해결할 수 있다.
Choosing your mini-batch size
If small Train-set(m<2000) : Use 'Batch'(BGD)
Typical mini-batch size : 64,128,256,512 처럼 2의 n승 꼴이 컴퓨터가 인식하기 좋음!
※ Exp.weighted average - 지수가중평균
v[t] = βv[t-1] + (1-β)θ[t]
β = 0.9 : 10일간 {1/(1-0.9) = 10}
β = 0.98 : 50일간 {1/(1-0.98) = 50}
β = 0.99 : 100일간 {1/(1-0.99) = 100}
2. GD with Momentum
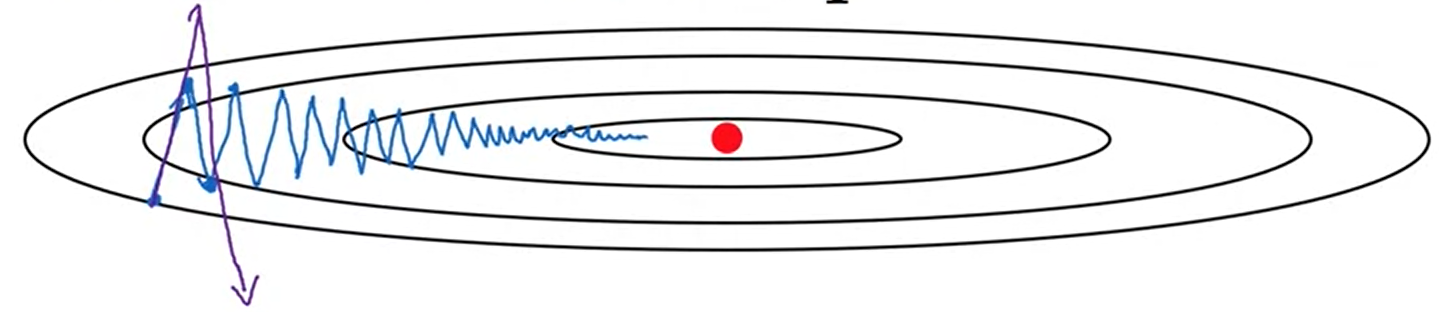
Vertical로 움직이는 것은 'learning rate'와 관련 (Slower learning) α
Horizontal로 움직이는 것은 'momentum'과 관련 (Faster learning) v(지수가중평균)
w:= w - α vdw
b:= b - α vdb 이걸 통해

빨간색 더 빨리 minimum에 도달할 수 있다.
3. RMSprop(Root Mean Square) - faster!
Momentum을 더 효과적으로 이용하기 위해
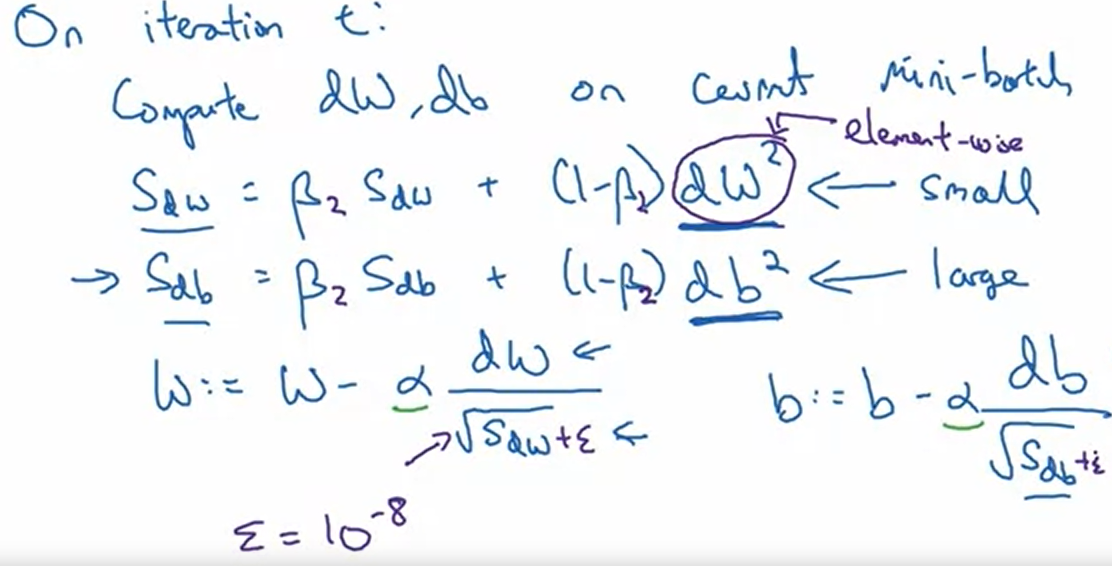
4. Adam optimization - 매우 중요!!
Momentum + RMSprop = Adam!!

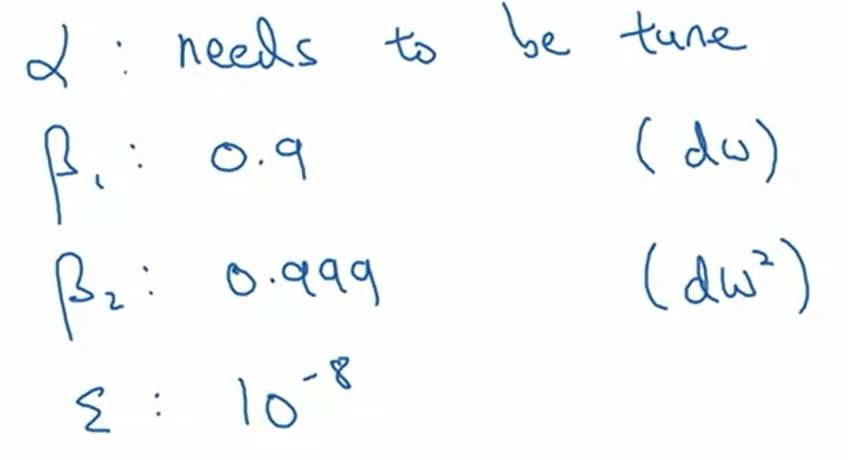
α : learning rate
β1 : momentum
β2 : RMSprop
ε : 추천 - 중요하지는 않다
--> Adam (Adaptive Moment Estimation) !!
5. Learning rate decay
--> Slowly reduce learning rate overtime
if train-set [mini-batch]
X{1}|X{2}|X{3} ...
------------------>epoch1
------------------>epoch2
...
learning rate : α = 1 /{1 + decay-rate epoch_num} α[0]
α[0] = 0.2 / decay-rate = 1
( Epoch, α ) : (1, 0.1) | (2, 0.067) | (3, 0.05) | (4,0.04)
--> α를 구하는 다른 방법들도 존재한다.
