목표 : BBB 막투과성 O,X 분류
0. 라이브러리 설치
!pip install rdkit-pypi1. 데이터 준비하기
!wget https://s3-us-west-1.amazonaws.com/deepchem.io/datasets/molnet_publish/bbbp.zip
!ls
!unzip bbbp.zip
import pandas as pd
data = pd.read_csv("BBBP.csv")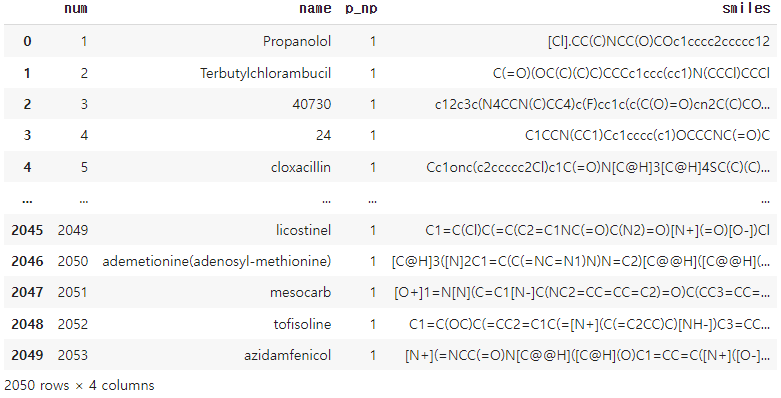
1-1 SMILES --> Finger Print
from rdkit import Chem, DataStructs
from rdkit.Chem import AllChem
import numpy as np
# 데이터 중 'NONE'값 제거
idxs=[]
for i, smiles in enumerate(data["smiles"]):
mol = Chem.MolFromSmiles(smiles)
if (mol == None) :
print(i,mol)
idxs.append(i)
data = data.drop(idxs, axis= 0)
# Fingerprint
fps = []
for i, smiles in enumerate(data["smiles"]):
mol = Chem.MolFromSmiles(smiles)
arr = np.zeros((1,))
fp = AllChem.GetMorganFingerprintAsBitVect(mol, 2048)
DataStructs.ConvertToNumpyArray(fp, arr)
fps.append(fp)
data['fp'] = fps2. train_test_split
from sklearn.model_selection import train_test_split
train_val, test = train_test_split(data, test_size=0.1, random_state=42)
train, val = train_test_split(train_val, test_size=0.1/0.9, random_state=42)
datasets = {
"train" : train,
"val" : val,
"test" : test
}3. Dataset Customization [bbbpDataset]
import torch
from torch.utils.data import Dataset
class bbbpDataset(Dataset):
def __init__(self, df):
self.x = list(df["fp"])
self.y = list(df["p_np"].values)
def __len__(self):
return len(self.x)
def __getitem__(self, index):
return torch.tensor(self.x[index]).float(), torch.tensor(self.y[index]).float()
bbbpdata = {
"train": bbbpDataset(datasets["train"]),
"val": bbbpDataset(datasets["val"]),
"test": bbbpDataset(datasets["test"])
}
from torch.utils.data import DataLoader
bbbp_dataloaders = {
"train" : DataLoader(bbbpdata["train"], batch_size=32, shuffle = True),
"val" : DataLoader(bbbpdata["val"], batch_size=32, shuffle = False),
"test" : DataLoader(bbbpdata["test"], batch_size=32, shuffle = False)
}4. 모델 만들기
import torch
from torch import nn
device = "cuda" if torch.cuda.is_available() else "cpu"
device
class bbbp_MLP(nn.Module):
def __init__(self):
super(bbbp_MLP, self).__init__()
self.linear1 = nn.Linear(2048,1024)
self.linear2 = nn.Linear(1024, 256)
self.output = nn.Linear(256,1)
self.dropout1 = nn.Dropout(0.5
self.relu = nn.ReLU()
def forward(self,x) :
out = self.linear1(x)
out = self.dropout1(out)
out = self.relu(out)
out = self.linear2(out)
out = self.dropout1(out)
out = self.relu(out)
out = self.output(out)
return out
model = bbbp_MLP()
model.to(device) 5. 손실 및 최적화 함수 설정
import torch.optim as optim
loss_fn = nn.BCEWithLogitsLoss()
optimizer = torch.optim.SGD(params = model.parameters(), lr = 0.1)
def acc_fn(y_true, y_pred):
correct = torch.eq(y_true, y_pred).sum().item()
acc = (correct / len(y_pred)) * 100
return acc6. 모델학습하기
torch.manual_seed(42)
epochs = 101
train_losses = []
val_losses = []
train_accs = []
val_accs = []
for epoch in range(epochs):
model.train()
epoch_train_loss = 0.0
for i, data in enumerate(bbbp_dataloaders["train"]):
x,y = data[0], data[1]
optimizer.zero_grad()
outputs = model(x)
train_loss = loss_fn(outputs, y.view(-1,1))
train_acc = acc_fn(torch.round(torch.sigmoid(outputs)), y.view(-1,1))
train_loss.backward()
optimizer.step()
epoch_train_loss += train_loss.item()
model.eval()
epoch_val_loss = 0.0
with torch.inference_mode():
for i, data in enumerate(bbbp_dataloaders["val"]):
x,y = data[0].to(device), data[1].to(device)
outputs = model(x)
val_loss = loss_fn(outputs, y.view(-1,1))
val_acc= acc_fn(torch.round(torch.sigmoid(outputs)), y.view(-1,1))
epoch_val_loss += val_loss.item()
epoch_train_loss /= len(bbbp_dataloaders['train'])
epoch_val_loss /= len(bbbp_dataloaders['val'])
train_losses.append(epoch_train_loss)
val_losses.append(epoch_val_loss)
train_accs.append(train_acc)
val_accs.append(val_acc)
if epoch % 10 == 0:
print("[Epoch %d] Train Loss: %.3f Train acc: %.3f Validation Loss: %.3f Validation acc : %.3f" %
(epoch, epoch_train_loss, train_acc, epoch_val_loss, val_acc))
7. 결과 리포팅하기
import matplotlib.pyplot as plt
epoch_count = range(epochs)
plt.plot(epoch_count, train_losses, label = "Train loss")
plt.plot(epoch_count, val_losses, label="Val loss")
plt.title("Training and val loss curves")
plt.ylabel("Loss")
plt.xlabel("Epochs")
plt.legend()
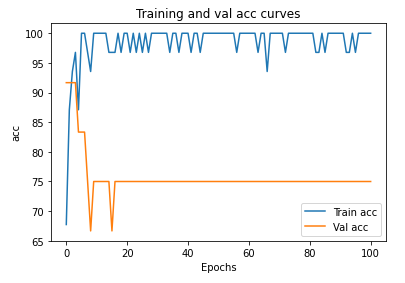
epoch_count = range(epochs)
plt.plot(epoch_count, train_accs, label="Train acc")
plt.plot(epoch_count, val_accs, label="Val acc")
plt.title("Training and val acc curves")
plt.ylabel("acc")
plt.xlabel("Epochs")
plt.legend()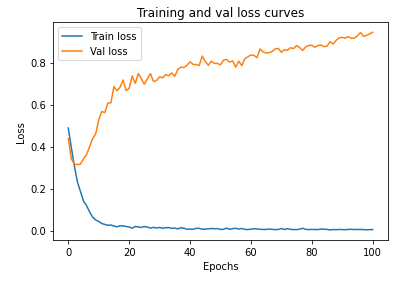

AI driven Drug Discovery