📚 Journal
https://stay-present.tistory.com/98
내일 말짱한 정신으로 다시 읽어볼 것
공부 방향성
[Week03] Pintos Project2-1 Background 이것만 빠르게 정리한 다음에
바로 구현 시작했어야 했을텐데
강의 듣다가 시간이 금새 지나가버렸다. (순서를 거꾸로 봄)
앞으로 할 때 도움이야 되겠지만,
공부 방향성 잡기 실패한듯.
내일부턴 ㄹㅇ로 구현 위주로 들어가보자.
구현 어디서부터 시작할지
process_exec에 있는
load 함수 수정해서
명령줄 파싱
프로세스 실행시킬 수 있어야 테스트
그전엔 명령줄에 입력해서 잘 되는지
📝 배운 것들
🏷️ Process Environment Block (PEB)
Windows 운영체제에서 유저 모드 프로세스에 대한 정보를 저장하는 구조체.
- 프로세스가 시작될 때 커널이 만든다.
- PEB는 각 프로세스마다 고유하다.
- 프로세스의 모듈 목록, 환경 변수, 시작 매개 변수 등의 정보가 저장된다.
- 커널 모드에서 관리되지 않고 유저 모드에서 접근 가능하므로
응용 프로그램이 자체적으로 메모리와 리소스를 관리하는 데 도움을 준다. - WinDbg같은 디버깅 툴 쓰면 PEB 확인할 수 있다.
리눅스나 맥은?
비슷한 거 있는데 PEB같이 구체적으로 만들어지진 않았음.
리눅스에선 프로세스의 메모리 정보나 환경 변수를 /proc 파일 시스템을 통해 접근할 수 있음.
프로세스의 메모리 할당, 파일 핸들, 실행 중인 모듈 같은 정보는 리눅스 커널이 관리함.
PEB는 아니고 그냥 파일 형식
리눅스는 ELF(Executable and Linkable Format) 파일 형식으로 프로그램과 라이브러리가 로드됨.
맥 OS 파일 형식은 Mach-O(Mach Object)
🏷️ Process Identifier (PID)
PID는 운영체제가 실행 중인 프로세스를 식별하려고 부여하는 숫자임.
프로세스 간의 상호작용, 신호 전송, 종료 등의 작업할 때 쓰임
- 프로세스 간 통신
- kill 명령어로 특정 프로세스 종료
- fork()로 새 프로세스 생성될 때 PID가 할당됨
- getpid()로 현재 프로세스의 PID 가져올 수 있음
- getppid()로 부모 프로세스의 PID 확인할 수 있음
- 쉘에선 $$ 변수로 현재 쉘의 PID 확인할 수 있음
🏷️ x86-64 Calling Convention
함수 호출 시 인자 전달 방식, 리턴 값 처리, 메모리와 레지스터 사용 규칙을 정의한 것
1. 인자 전달 방식
- 첫 번째에서 여섯 번째 정수/포인터 인자는 레지스터를 통해 전달됨. 이때 사용하는 레지스터는 RDI, RSI, RDX, RCX, R8, R9임.
- 부동 소수점 인자는 XMM0 ~ XMM7 레지스터에 전달됨
- 여섯 개 이상의 정수 인자 또는 여덟 개 이상의 부동 소수점 인자가 있을 경우, 나머지 인자는 스택을 통해 전달됨.
2. 스택 정렬
- 함수 호출 전에 스택이 16바이트로 정렬되어야 함.
- 메모리 접근이 올바르게 정렬되어야 하는 SIMD 연산을 지원하기 위해 필수적
3. 리턴 값 처리
- 함수의 리턴 값은 정수형이나 포인터형 값일 경우 RAX 레지스터에 저장됨
- 부동 소수점 리턴 값은 XMM0 레지스터에 저장됨
- 리턴 값이 큰 구조체일 경우, 해당 구조체를 저장할 메모리 주소가 인자로 전달되며, 그 주소를 통해 리턴 값이 저장됨.
🏷️ Argument vector (argv)
argument vector는 명령줄에 전달된 인자들을 배열로 저장한 구조
argc: 명령줄 인자의 개수
argv: 각 인자에 대한 문자열 포인터들을 담은 배열. argv[0]은 항상 프로그램 이름을 가리킴.
argc 확인해서 유효한 인자 개수 체크한 뒤 argv 배열 요소 접근해야 함.
명령줄 인자는 기본적으로 문자열
🏷️ ELF (Executable and Linkable Format)
ELF는 유닉스 계열 운영체제에서 사용되는 표준 바이너리 파일 형식.
실행 가능한 프로그램, 공유 라이브러리, 코어 덤프를 저장할 때 사용됨.
운영체제가 실행 파일을 메모리에 로드하고 실행하는 과정을 지원함.
ELF 파일 구조
- ELF 헤더: 파일의 타입과 크기, CPU 아키텍처, 엔트리 포인트 주소 등의 기본 정보 포함. 운영체제의 로더가 파일을 메모리에 어떻게 로드해야할지 알려줌.
- 프로그램 헤더: 실행 시 필요한 메모리 매핑 정보를 포함. 운영체제는 이 정보를 참조하여 프로그램의 코드를 메모리에 적재하고 실행함.
- 섹션 헤더: 코드, 데이터, 심볼 테이블, 디버깅 정보 등 파일의 각 부분에 대한 정보 포함. 컴파일러와 링커가 이 정보를 사용하여 실행 파일을 생성하거나 수정.
ELF 파일 구성 요소
- .text 섹션: 실행 가능한 기계어 코드가 포함된 영역. 읽기/실행 가능.
- .data 섹션: 초기화된 전역 변수와 정적 변수가 포함됨. 읽기/쓰기 가능.
- .bss 섹션: 초기화되지 않은 데이터가 포함된 공간. 프로그램 실행 중 메모리가 할당되며, 읽기/쓰기 가능.
로딩 및 실행 과정
ELF 파일이 운영체제에 의해 실행될 때, 로더(loader)가 ELF 파일을 읽고 메모리에 적재한 후 실행함.
이때 로더는 프로그램 헤더의 정보로 프로그램을 적절한 메모리 주소에 매핑하고, 필요한 라이브러리를 로드함.
정적 링크, 동적 링크 두 가지 방식으로 실행 가능.
정적 링크: 모든 라이브러리가 실행 파일에 포함됨
동적 링크: 외부 공유 라이브러리 필요함. 실행할 때 해당 라이브러리를 메모리에 로드해서 사용함.
🏷️ 주요 시스템 콜 (파일 시스템, 프로세스)
파일 시스템 시스템 콜
open(): 파일 열거나 새로운 파일 생성. pathname(파일 경로)과 flags(access mode)를 인자로 받음.
// Opening an existing file for reading
int fd = open("/home/user/file.txt", O_RDONLY);flags 종류
O_RDONLY – Open file for reading only
O_WRONLY – Open file for writing only
O_RDWR – Open file for reading and writing
O_CREAT – Create file if it does not exist
O_TRUNC – Truncate file to zero length
O_APPEND – Seek to end of file before each write
O_EXCL – Fail if file already exists when creating file
에러 핸들링 예시
int fd = open("file.txt", flags);
if (fd == -1) {
switch(errno) {
case ENOENT:
printf("File does not exist\n");
break;
case EACCES:
printf("Permission denied\n");
break;
// similarly check other errors
}
}-
close(): 파일 디스크럽터를 닫고 시스템 리소스를 해제. 자동으로 닫히지만 수동으로 닫으면 리소스 절약. -
read(): 파일 디스크립터에서 데이터를 읽어 버퍼에 저장 -
write(): 데이터를 파일 디스크립터에 씀 -
seek(): 파일의 읽기/쓰기 위치를 조정. 파일의 특정 위치로 이동함. -
tell(): 파일의 읽기/쓰기 포인터 위치 반환. 파일 작업 중 어디까지 진행되었는지 알기 위해 사용됨.
프로세스 시스템 콜
-
fork(): 새로운 자식 프로세스를 생성. 부모와 자식 프로세스는 동일한 코드를 실행. 둘 중 하나가 데이터를 변경하려고 할 때 자식 프로세스가 부모 프로세스의 주소 공간을 복사받음. (똑같은 메모리 공간을 쓴다는게 아니라 데이터를 복사해온다는 뜻) -
wait(): 자식 프로세스가 종료될 때까지 부모 프로세스가 기다리게 함. 이거 쓰면 좀비 프로세스(종료된 프로세스가 자원을 해제하지 않은 상태) 방지 가능. -
exec(): 기존 프로세스의 주소 공간을 새 프로그램으로 대체함. PID도 물려받음.
exec 종류
https://jwprogramming.tistory.com/55
구분 1 : l계열(execl, execlp), v계열(execv, execvp)
l계열 : 인자를 열거하는 방식이 나열형
v계열 : 인자를 열거하는 방식이 배열형
구분 2 : p가 붙은 계열(execlp, execvp), 안붙은 계열(execl, execv)
p가 안붙은 계열 : 경로를 지정해주면 ,현재/절대경로를 기준으로 찾게 됩니다.(경로로 실행파일을 지정)
p가 붙은 계열(path) : path에 잡혀있으면 실행됩니다.(실행파일의 이름만 지정)
exit(): 프로세스 종료. 자원 해제와 함께 종료 상태 코드 반환.
🖥️ PintOS
🔷 User Program
1. 기초 공부
EE415: Introduction to Operating System, KAIST
📌 [Week03] Pintos Project2-1 Background
https://www.youtube.com/watch?v=RbsE0EQ9_dY
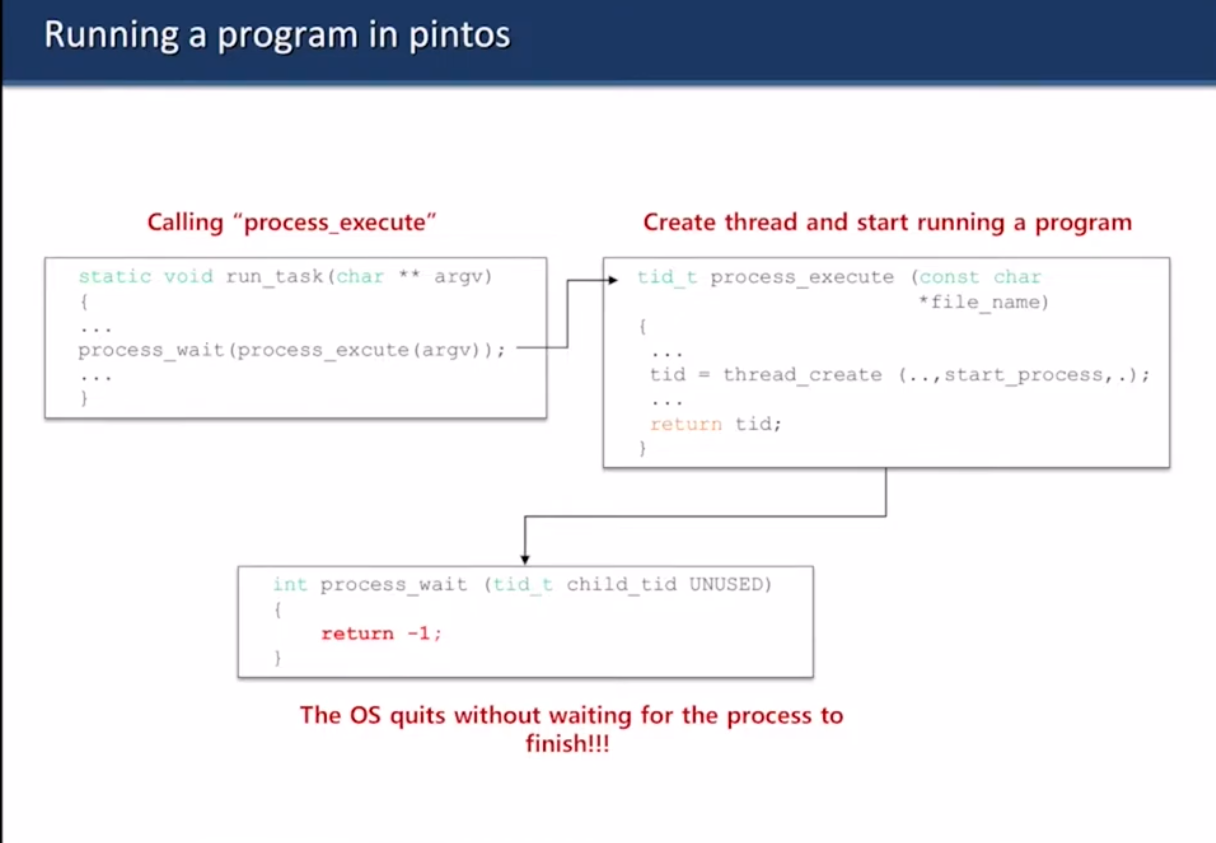
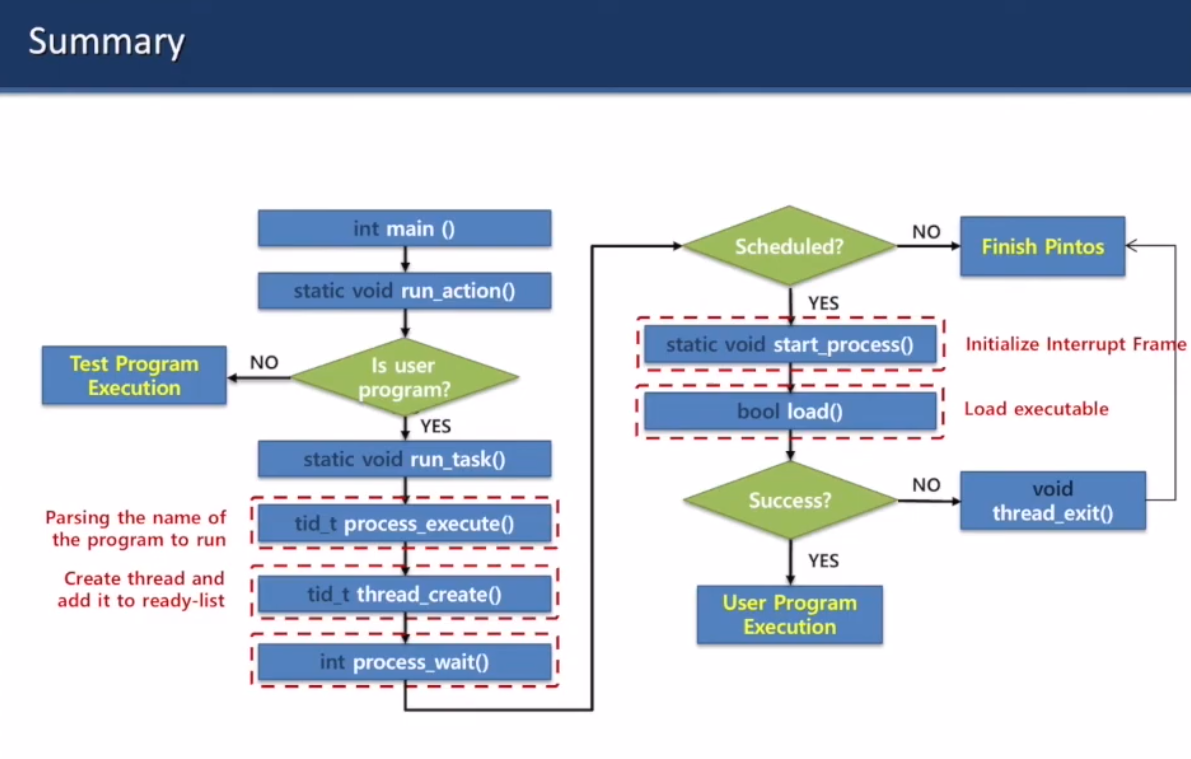
- process_execute 호출
- 쓰레드를 만들고 프로그램 돌리기 시작
- 지금은 wait가 -1만 반환하고 암것도 안함
Final Goal
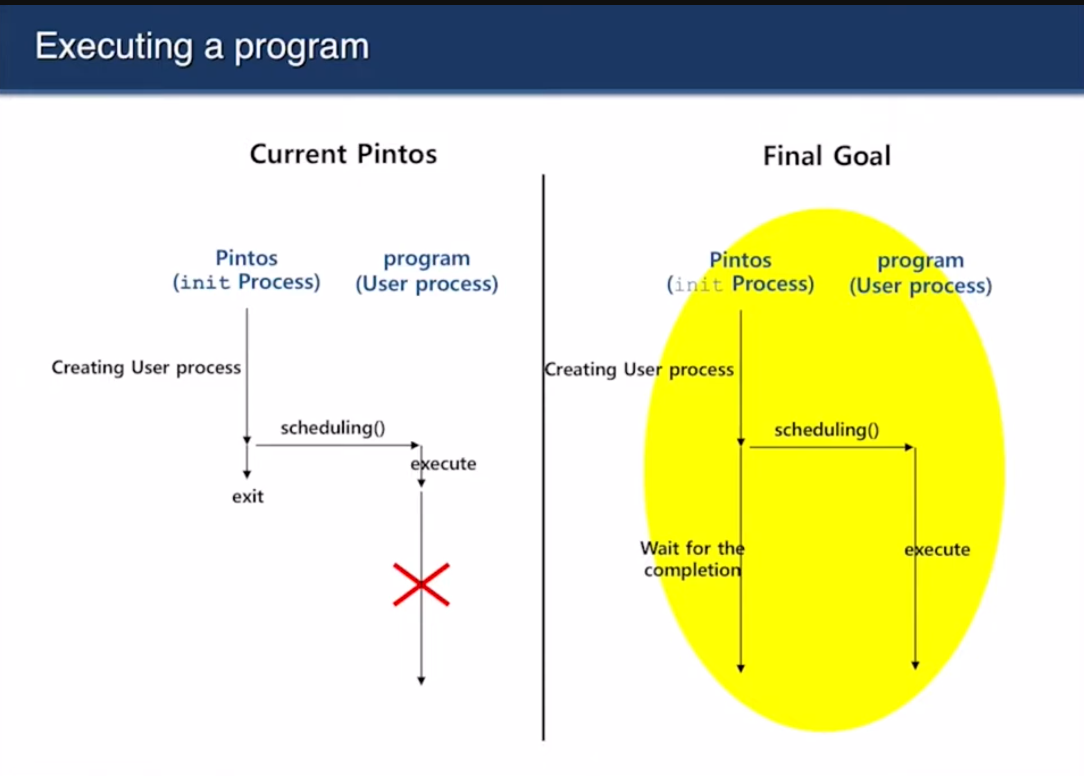
왼쪽이 현재. 오른쪽이 만들어야 될 거.
모든 것은 init process로부터 시작함
지금은 scheduling한 다음에 바로 exit해서 execute를 못해유
완료될 때까지 기다렸다가 마저 진행시켜야 된다
Overall execution
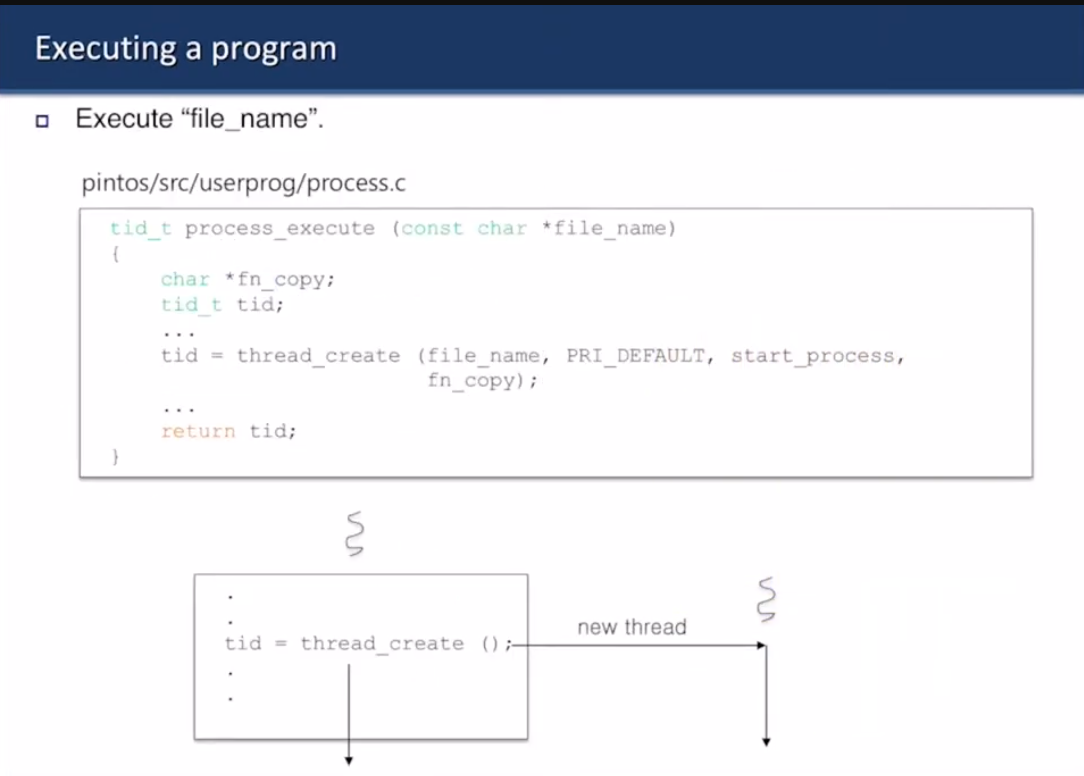
file_name을 실행시키기 위해
process.c에 있는 process_execute에 있는 thread_create가 쓰레드 만듦
쓰레드 만들기

thread_create()가 하는 일
- 쓰레드 구조체를 만들고 초기화
- 커널 스택 할당
- start_process 함수를 register함 (instruction pointer 또는 instruction counter의 값을 entery point of the process 라는데 뭔 말인지 모르겠)
- ready list에 추가함
thread_create()는 새로운 쓰레드를 생성하는 함수로, 여러 단계에 걸쳐 쓰레드를 시스템에 등록하고 실행할 준비를 합니다. 언급한 부분 중 "start_process 함수를 register함"이라는 내용은 쓰레드가 실행될 시작점(entry point)를 설정하는 과정입니다. 여기에 사용되는 개념들이 조금 어려울 수 있는데, 이를 자세히 설명하겠습니다.
-
Instruction Pointer 또는 Program Counter (IP/PC)
Instruction Pointer (IP)는 현재 CPU가 실행 중인 명령어의 주소를 가리키는 레지스터입니다. 이를 Program Counter (PC)라고도 부릅니다.
CPU는 이 레지스터의 값(명령어의 주소)을 읽고 해당 명령어를 실행합니다. 명령어가 실행된 후에는 다음 명령어의 주소로 값이 자동으로 갱신됩니다.
프로세스 또는 쓰레드가 시작되면, CPU는 프로세스의 엔트리 포인트(entry point)에 위치한 첫 번째 명령어를 실행합니다. 이 첫 명령어의 위치가 IP/PC 레지스터에 기록됩니다. -
start_process 함수 등록과 엔트리 포인트
start_process 함수는 새로 생성된 쓰레드가 실행될 때, 첫 번째로 실행되는 함수입니다. 즉, 이 함수는 쓰레드의 시작점입니다.
thread_create()가 실행되면, 이 쓰레드가 실행되었을 때 처음으로 실행할 코드를 가리키는 주소(엔트리 포인트)를 IP/PC 레지스터에 저장합니다.
엔트리 포인트는 새 쓰레드가 시작될 때 첫 번째로 실행할 코드의 위치입니다. start_process는 그 코드의 시작 주소를 의미하며, CPU는 이 주소부터 명령어를 실행하기 시작합니다. -
프로세스의 시작과 엔트리 포인트의 역할
프로세스나 쓰레드의 실행은 메모리에 저장된 코드를 하나씩 실행하는 과정입니다. 이때 IP/PC 레지스터는 "어디서부터 명령어를 실행할지"를 알려주는 역할을 합니다.
새로운 쓰레드를 만들면, thread_create()는 쓰레드가 실행되었을 때 start_process라는 함수를 처음 실행하도록 IP/PC에 등록하는 것입니다.
간단히 말해, 쓰레드가 시작될 때 CPU는 IP/PC 레지스터를 보고 첫 명령어의 위치를 알아내어 실행을 시작하는데, start_process는 그 첫 명령어의 위치를 지정하는 함수입니다.
프로세스 시작하기

load 함수는 disk에 있는 binary file을 memory에 load한다
실행하고자 하는 instruction의 위치를 특정하고 (&if_.eip)
user stack의 stack top pointer을 acquire한다 (&if.esp)
load 함수는 디스크에 저장된 실행 파일(바이너리 파일)을 메모리에 로드하여 프로세스를 실행할 준비를 하는 중요한 함수입니다. 이 함수는 프로그램이 실행되기 위한 기본적인 메모리 설정을 하고, 실행할 명령어와 데이터가 적절하게 배치되도록 합니다. 여기서 두 가지 핵심 작업을 설명해보겠습니다.
- 실행하고자 하는 명령어의 위치를 특정 (&if_.eip)
-
명령어의 위치를 특정한다는 것은, 실행 파일에서 실행할 첫 번째 명령어(즉, 프로그램이 시작될 때 처음으로 실행되는 명령어)의 위치를 결정하는 것을 의미합니다.
- eip(Instruction Pointer) 또는 프로그램 카운터(PC)는 CPU가 현재 실행할 명령어의 메모리 주소를 가리키는 레지스터입니다.
- if_.eip는 Instruction Pointer로, CPU가 프로세스를 실행할 때 이 레지스터가 가리키는 주소에서 첫 번째 명령어를 실행하게 됩니다.
- load 함수는 실행 파일을 메모리에 로드한 후, 실행할 첫 번째 명령어의 주소를 찾아서 if_.eip에 저장합니다. 이 위치는 프로그램의 엔트리 포인트(entry point)라고도 하며, 주로 프로그램의 실행이 시작되는 지점입니다.
- 스택 탑 포인터를 설정한다 (&if_.esp)
-
스택 탑 포인터(stack top pointer)는 사용자 스택의 최상단을 가리키는 포인터로, esp(Stack Pointer) 레지스터에 저장됩니다.
- 스택은 함수 호출 시 사용되는 임시 데이터를 저장하는 메모리 구조로, 지역 변수나 함수 호출 기록 등이 저장됩니다.
- 프로그램이 실행되기 위해서는 사용자 스택이 준비되어 있어야 하고, 그 스택의 최상단 주소를 알려주는 것이 esp입니다.
- load 함수는 프로그램을 메모리에 로드하는 과정에서 사용자 스택을 초기화하고, 스택의 최상단을 가리키는 포인터를 if_.esp에 설정합니다. 이를 통해 프로그램은 스택에 데이터를 쌓고, 필요한 변수를 저장할 수 있습니다.
실행 과정 요약
- 디스크에서 바이너리 파일을 메모리로 로드: 바이너리 파일을 메모리에 적재하고, 실행할 코드와 데이터를 메모리의 적절한 위치에 배치합니다.
- 프로그램의 엔트리 포인트(첫 명령어 위치)를 결정: 프로그램이 실행될 첫 명령어의 메모리 주소를 찾아서 eip 레지스터에 설정합니다. 이 주소는 실행 파일의 시작점이 됩니다.
- 사용자 스택의 초기화: 사용자 스택을 설정하고, 그 스택의 최상단 주소를 esp 레지스터에 저장합니다. 이는 프로그램 실행 중 함수 호출과 변수 저장 등에 사용됩니다.
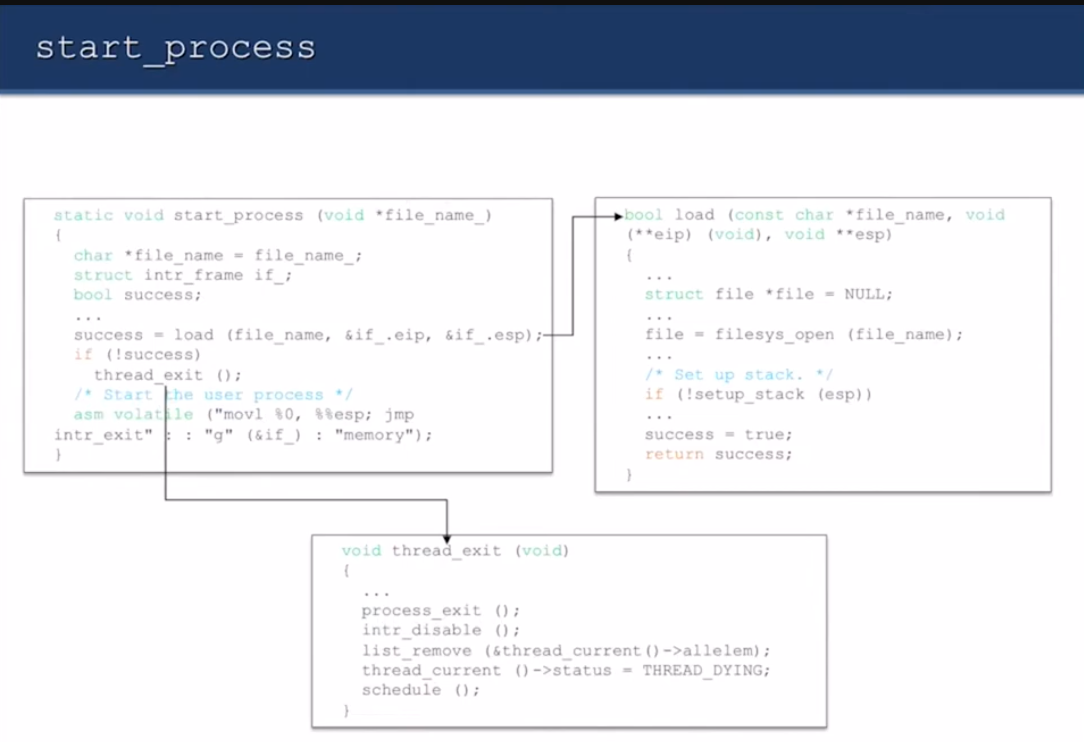
start_process가 호출되면
load함
load 실패하면 exit함. allocate된 memory chunks들 다 해제해줘야 됨.
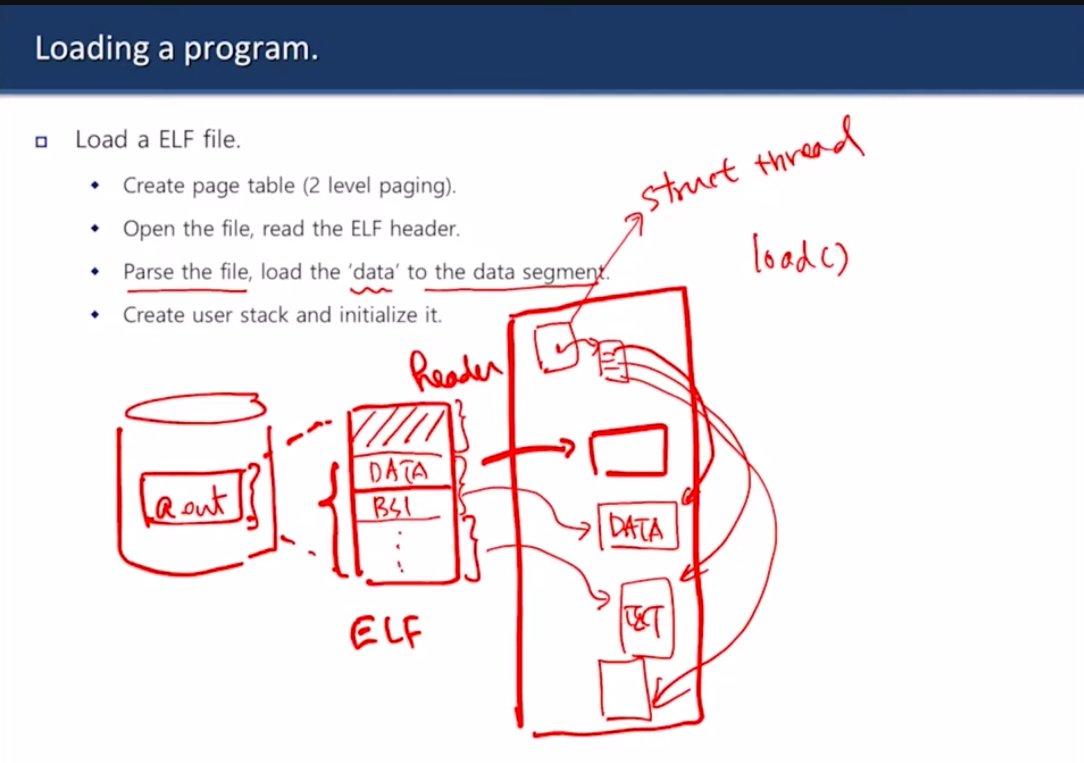
ELF 파일 load하기
- page table을 만든다
- 파일을 열고, ELF 헤더를 읽는다
- 파일을 parse하고, 'data' 를 data segment에 load한다
- 유저 스택을 만들고 초기화한다
ELF 헤더에는 파일이 어떻게 구성되어있는지에 대한 정보가 있음
그거 보고 메모리에 파일 load함
쓰레드 구조체에는 page table을 담고 있음 (field 이름은 page dir)
load만 하는게 아니라 초기화도 해유
(!!! 핵심 !!!) 인자 넘기고 쓰레드 만들기

"echo x y z" 이렇게 주면
- 쓰레드 이름 특정 : echo
- echo라는 이름 가진 프로그램 찾기
- user stack에 인자 넣기
userprog/process.* 수정해서 이렇게 되게 해라
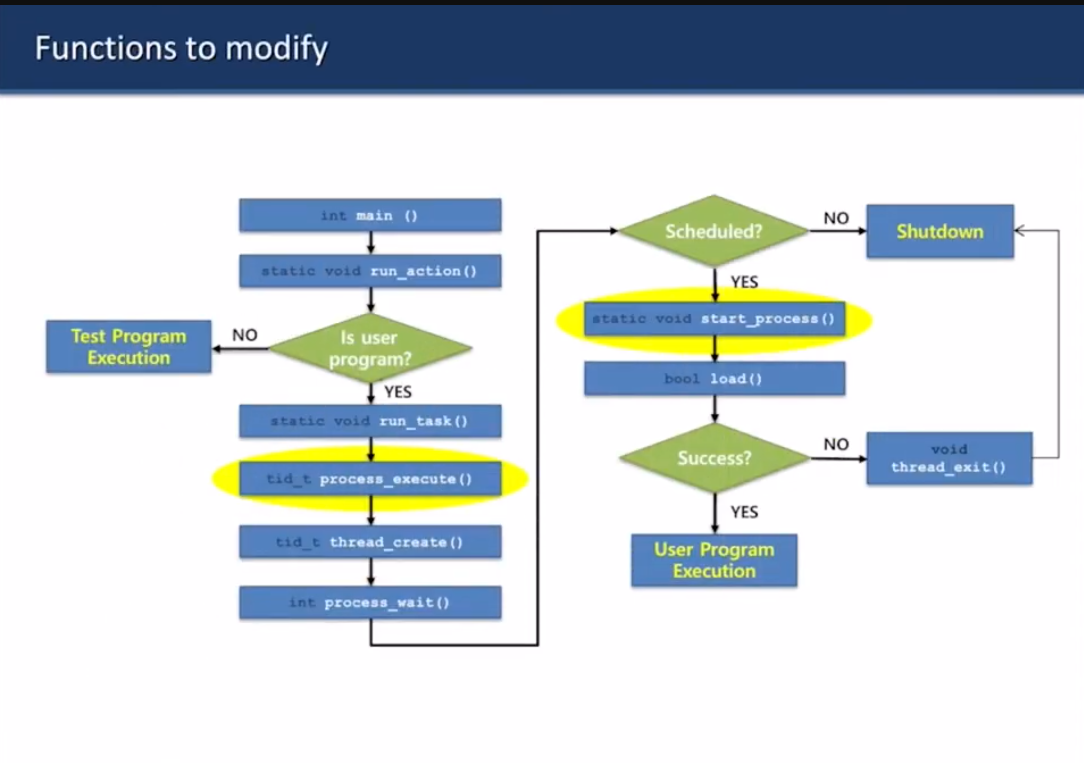
이거 두 개 수정하세요

process_execute()
- file_name에 있는 문자열을 parse하셈
- 첫번째 토큰을 thread_create()에 새로운 프로세스의 이름으로 전달하셈
start_process()
- file_name을 parse하셈 (토큰으로 쪼개셈)
- 새 프로세스의 유저 스택에 토큰들을 저장하셈

이거 써서 문자열을 tokenize하셈
string.c에 있는듯

process_execute 고쳐서 thread_create에 명령줄의 첫 번째 토큰만 전달되도록 바꾸셈
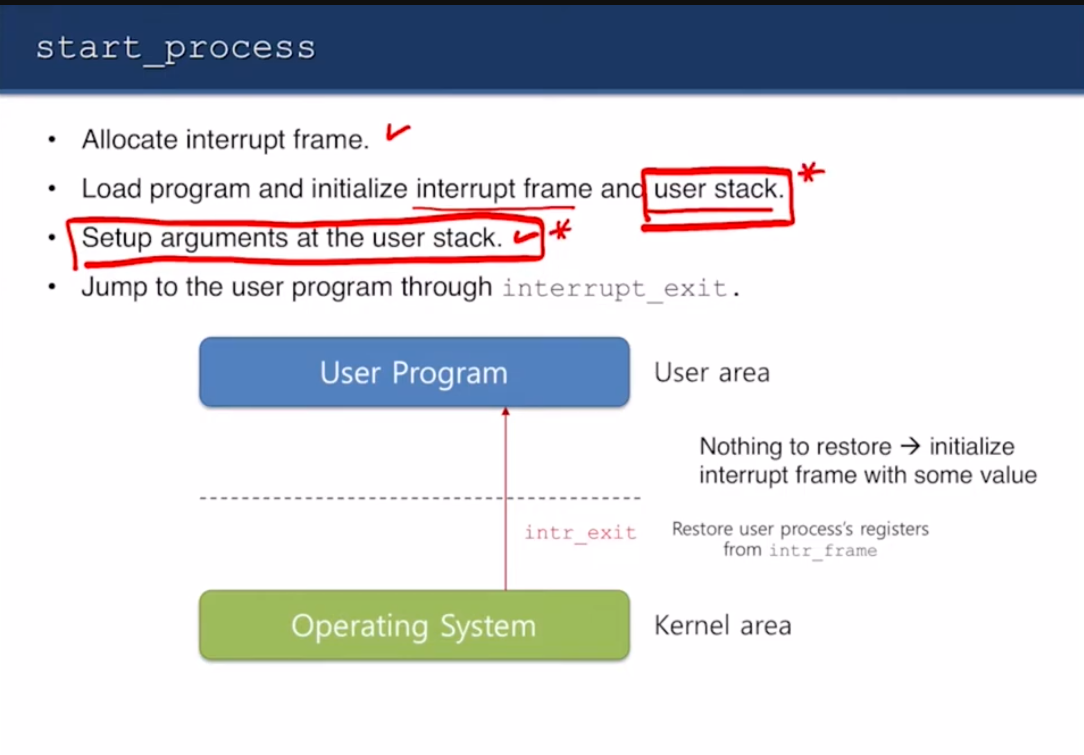
- 인터럽트 프레임 할당하기
- 프로그램을 load하고 인터럽트 프레임과 유저 스택을 초기화하기
- 유저 스택에 있는 인자들을 setup하기
- interrupt_exit로 유저 프로그램으로 jump
유저 스택에 인자 전달하는거 구현해야 하는거임
- 인터럽트 프레임 할당
- 인터럽트 프레임(Interrupt Frame)은 CPU가 인터럽트가 발생했을 때 또는 인터럽트 처리 후 복귀할 때 사용되는 구조체입니다.
- 이 프레임은 프로세서가 현재 실행 중인 상태(레지스터 값 등)를 저장하는 데 사용됩니다. 또한, 프로세스가 커널 모드에서 사용자 모드로 전환될 때, 또는 그 반대로 전환될 때도 사용됩니다.
- 여기서는 새로 시작하는 유저 프로그램의 실행 상태를 설정하는 데 사용됩니다. 즉, 유저 프로그램이 실행될 준비를 마쳤을 때, 인터럽트 프레임을 통해 프로그램 상태를 복원하고 실행을 시작합니다.
- 프로그램 로드 및 인터럽트 프레임/유저 스택 초기화
- 프로그램 로드: 이는 디스크에 저장된 바이너리 파일을 메모리로 로드하는 과정입니다. 실행 파일이 메모리로 로드되면 프로그램의 명령어와 데이터가 메모리의 적절한 위치에 배치됩니다.
- 인터럽트 프레임 초기화: 이 단계에서, 방금 할당된 인터럽트 프레임에 초기 값이 설정됩니다. 이 값들은 CPU가 유저 프로그램으로 전환될 때 사용할 상태 정보입니다.
- 유저 스택 초기화: 유저 스택은 함수 호출 시 사용할 지역 변수, 함수 인자, 리턴 주소 등을 저장하는 공간입니다. 프로그램이 실행되기 위해서는 유저 스택의 최상단을 정확히 설정해야 하며, 이를 초기화하는 것이 이 단계의 작업입니다.
- 유저 스택에 있는 인자들을 설정
- 유저 프로그램을 실행할 때, 프로그램의 인자들(arguments) (예:
argc,argv)가 유저 스택에 저장됩니다. 이 단계에서는 스택에 프로그램의 인자들을 설정(setup)하는 작업을 합니다. - 예를 들어, 유저 프로그램이
./program arg1 arg2와 같은 명령으로 실행될 경우,arg1과arg2같은 인자들이 유저 스택에 적절히 배치됩니다. 이를 통해 프로그램이 시작될 때 이 인자들을 사용할 수 있게 됩니다.
interrupt_exit를 통해 유저 프로그램으로 점프
- 이제 유저 프로그램이 실행될 준비가 끝났으므로, 커널은
interrupt_exit함수를 사용하여 유저 모드로 전환합니다. interrupt_exit은 인터럽트가 처리된 후 다시 유저 모드로 돌아갈 때 사용하는 함수로, 앞서 설정한 인터럽트 프레임에서 CPU 레지스터 값을 복원한 후, 해당 위치에서 실행을 계속합니다.- 이 과정을 통해 커널은 유저 프로그램으로 점프하여, 유저 프로그램의 첫 번째 명령어부터 실행을 시작하게 됩니다.
요약
- 인터럽트 프레임을 할당하여 CPU 상태를 저장하고 복원할 준비를 합니다.
- 프로그램을 메모리에 로드하고, 유저 프로그램의 스택과 인터럽트 프레임을 초기화하여 실행할 준비를 합니다.
- 유저 스택에 프로그램 인자를 설정하여 프로그램이 시작될 때 인자를 사용할 수 있도록 합니다.
interrupt_exit을 사용해 커널에서 유저 프로그램으로 전환하고 프로그램 실행을 시작합니다.
커널 들락날락하기
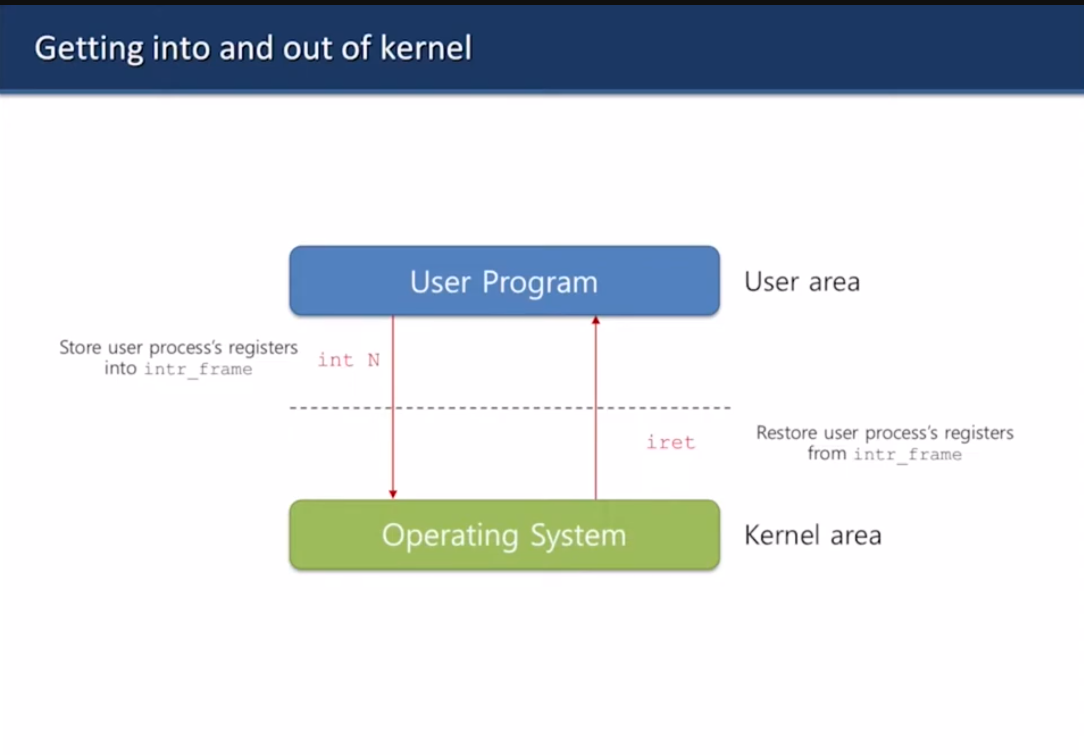
커널로 들어가려면 int라는 instruction을 호출해야 함
커널에서 다시 나오려면 iret 호출해야 함
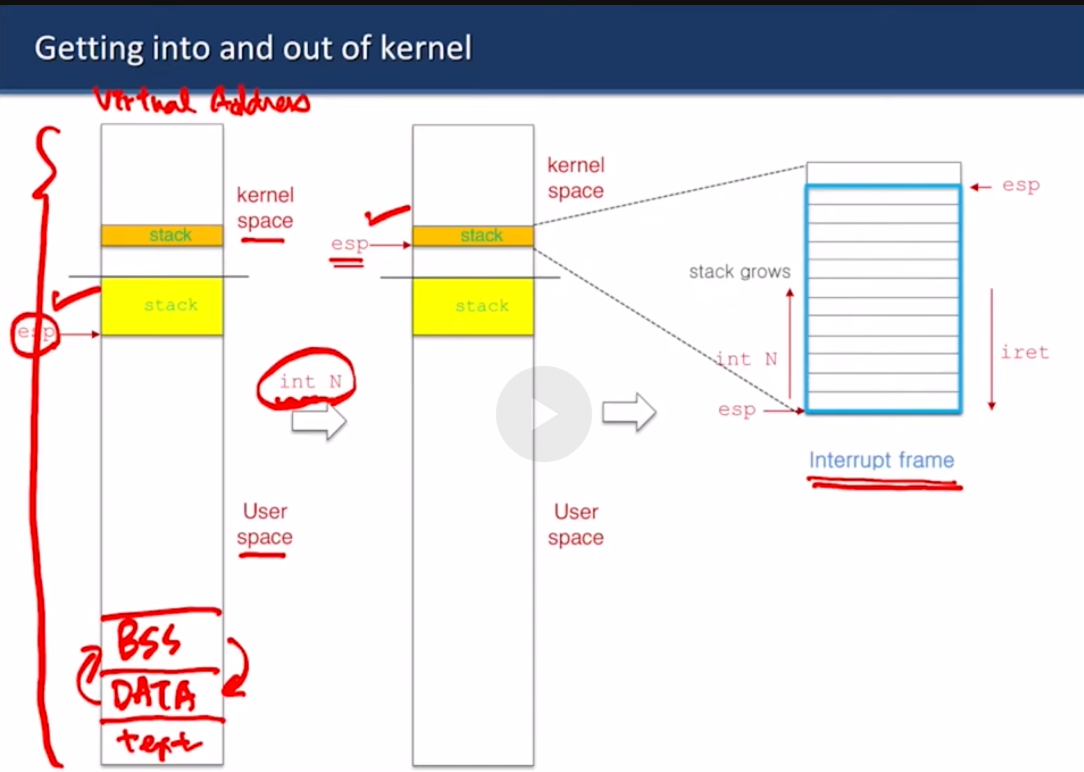
운영체제에 따라서 bss랑 data segment 위치는 바뀔 수 있다
exp가 보통은 유저 스택의 시작 부분에 있음.
int 호출하면 esp가 커널 스택 시작점으로 감.
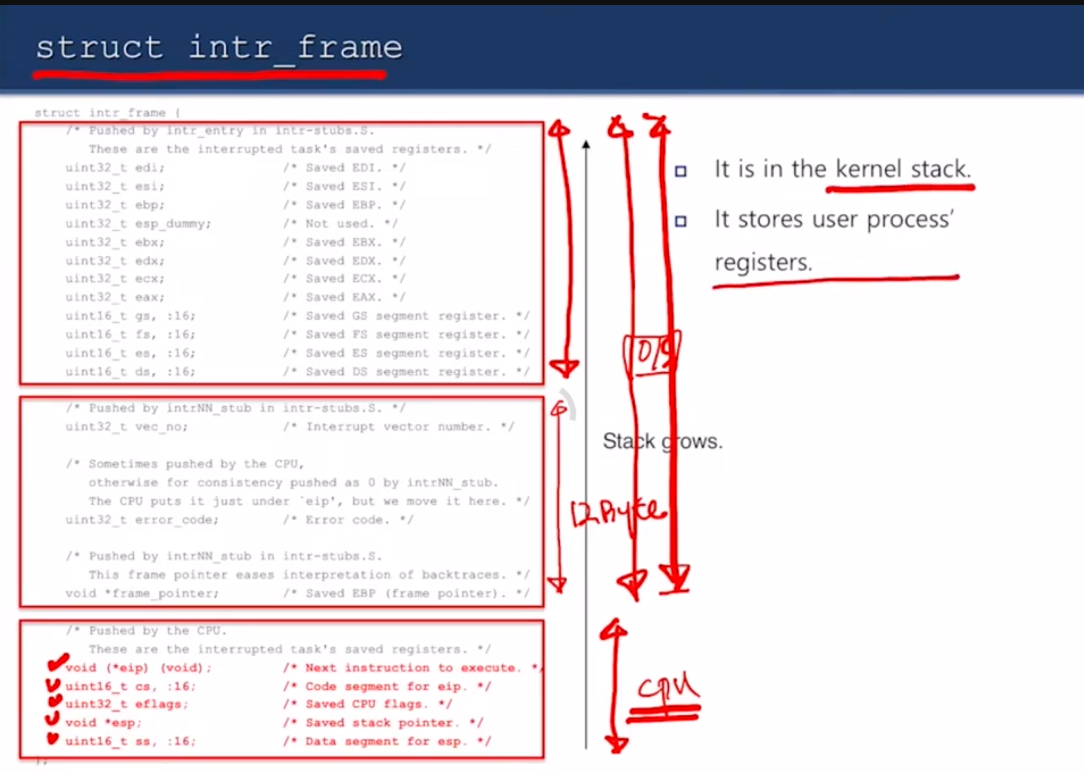
위쪽 두 칸은 운영체제가 결정하고
맨 아래 다섯개는 CPU가 결정함
인터럽트 프레임은 커널 스택에 있고
커널 스택은 유저 프로세스 레지스터들을 저장한 다음에 들어감
그래서 커널에 들어가는 건 비쌈
유저 프로세스 레지스터가 뭔데?
유저 프로세스 레지스터(User Process Registers)는 프로세스가 실행 중일 때 CPU에서 사용하는 레지스터 집합을 의미합니다. 레지스터는 CPU 내부에 있는 매우 빠른 메모리 공간으로, 현재 실행 중인 프로세스의 상태를 저장하고, 연산을 수행하거나 명령어를 처리할 때 필요한 데이터를 담습니다.
유저 프로세스 레지스터가 중요한 이유
유저 프로세스가 실행될 때, CPU는 이 레지스터들에 데이터를 저장하고, 명령어를 처리하며, 함수 호출을 관리합니다. 즉, 프로세스가 정상적으로 실행되기 위해선 레지스터에 저장된 정보가 매우 중요합니다.
하지만 프로세스는 CPU를 독점적으로 사용하지 않으며, 컨텍스트 스위칭(Context Switching) 과정에서 CPU는 다른 프로세스로 전환됩니다. 이때 현재 실행 중인 유저 프로세스의 상태를 나중에 다시 실행하기 위해 저장할 필요가 있습니다. 인터럽트 프레임은 이러한 유저 프로세스 레지스터의 상태를 저장하는 구조체로, 커널 스택에 위치하며, CPU가 유저 모드에서 커널 모드로 전환될 때, 유저 프로세스의 모든 레지스터 값을 임시로 저장해 둡니다.
인터럽트 프레임의 역할
- 유저 프로세스가 실행 중일 때, 인터럽트가 발생하거나 시스템 콜이 호출되면 커널은 유저 프로세스의 레지스터 값(현재 상태)을 인터럽트 프레임에 저장하고, 커널 모드로 전환합니다.
- 유저 모드에서 작업이 끝나고 다시 유저 프로세스로 복귀할 때는, 인터럽트 프레임에 저장된 레지스터 값을 복원하여 유저 프로그램이 원래 상태로 돌아가서 실행될 수 있게 합니다.
따라서 유저 프로세스 레지스터는 유저 프로세스가 CPU에서 실행되는 동안 사용되는 모든 상태 정보를 의미하며, 이를 안전하게 관리하고 보호하기 위해 커널 스택에 인터럽트 프레임을 사용하여 레지스터 상태를 저장하고 복원하는 것입니다.

- load에 프로그램 이름을 전달한다
- 파일 이름으로 load()가 실행 가능한 파일을 찾아서 메모리에 load한다
- pintos에선 load()가 eip랑 esp 초기화 해줘야 됨
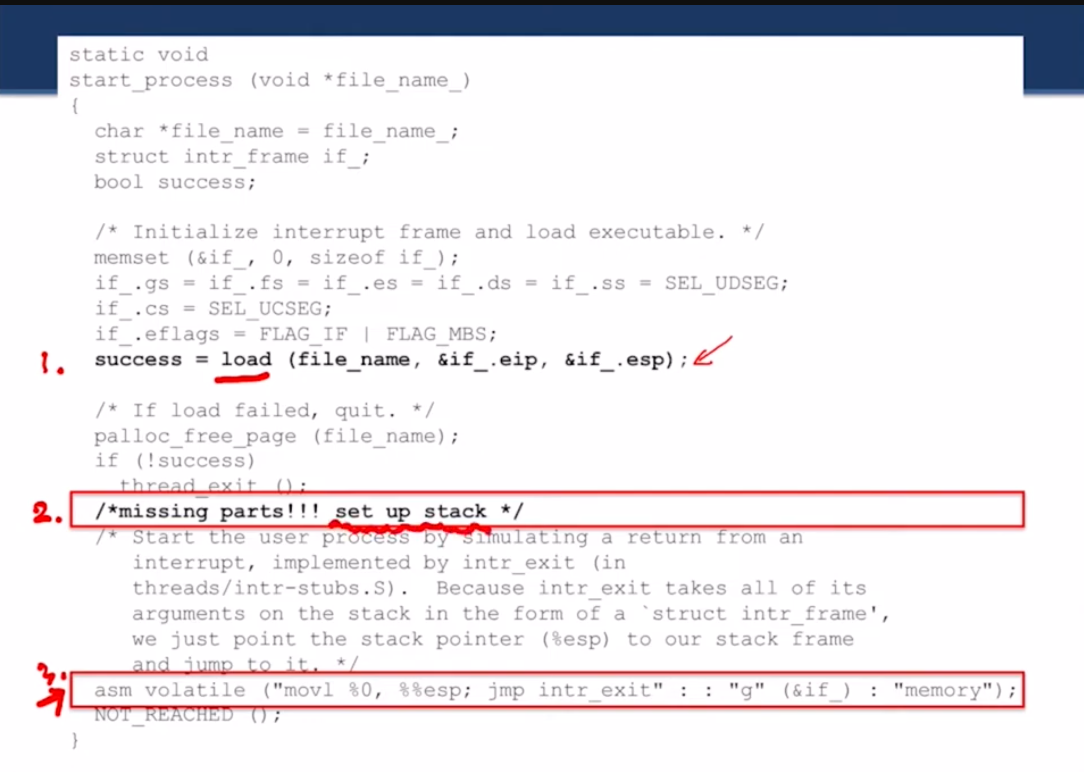
start_process에서 2번이라고 해놓은 부분 님이 마저 작성하셈 (유저 스택 채우는거)
근데 이거 작성하려면 1번이랑 3번도 이해해야 될거임
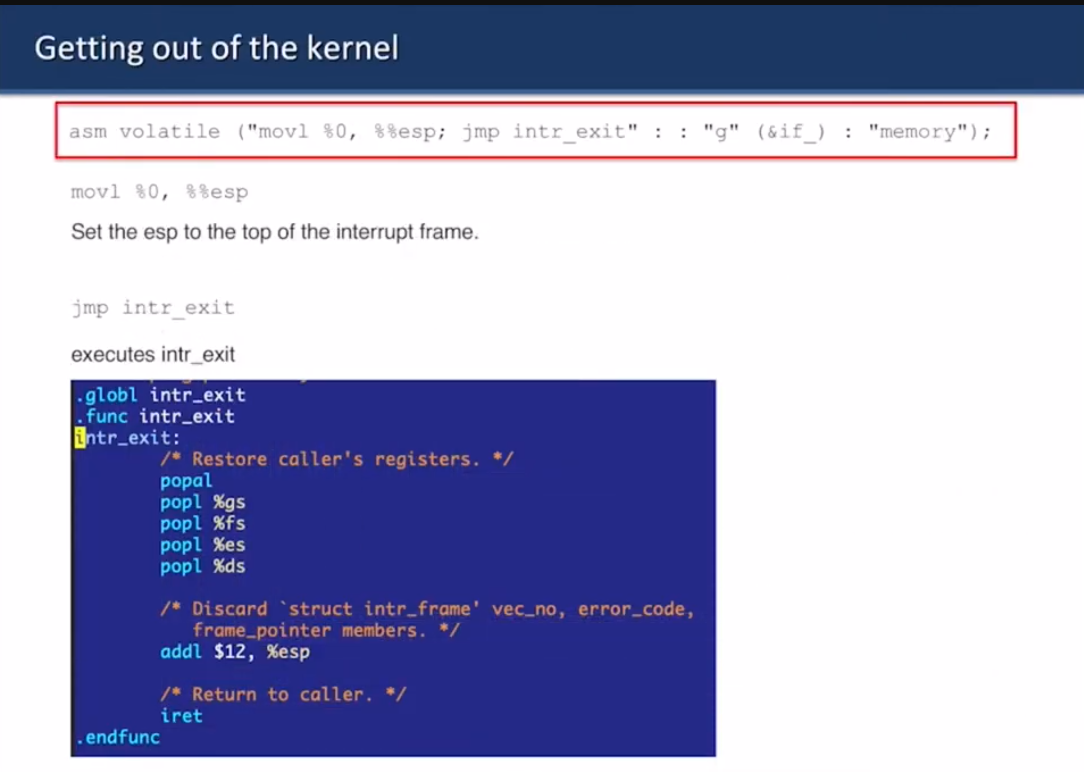
asm volatile은 c고 안에 들어있는 거 movl이랑 jmp는 어셈블리어임
esp를 인터럽트 프레임의 top으로 설정하고
intr_exit를 실행하는거임
이러면 커널에서 나올 수 있음

int로 커널에 들어갈 때 인터럽트 프레임에 값을 저장하고
iret로 커널에서 나올 때 인터럽트 프레임에 값을 빼내는게 원래인데
쓰레드 처음 만들 땐 그런 거 없으니까 임의의 값으로 초기화한다고 함

유저 스택에 인자 집어넣을 때 규칙
오른쪽에서 왼쪽 (ppt가 오타라고 함) 으로 문자열들을 집어넣음
(각각은 아니고 전부) 문자열 넣으면 4바이트로 정렬돼야함 (이것도 if necessary라고 적혀있는데 has to be라고 말함)
문자열들의 시작 주소를 집어넣음
argv랑 argc 집어넣음
다음 instruction의 주소 집어넣음 (return address)
새롭게 만들어지는 프로세스 만들 땐 fake address로 0 넣으면 됨
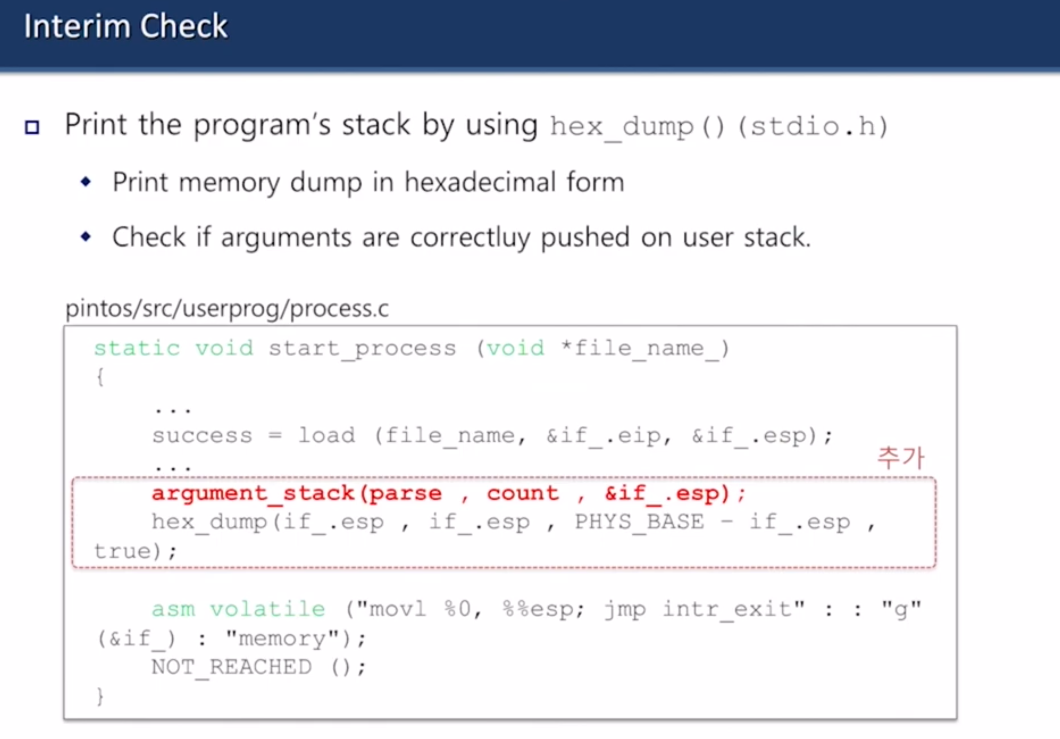
유저 스택이 제대로 만들어졌는지 확인하려면 hex_dump() 호출하면 됨
📌 [Week04] Pintos Project2 systemcall
https://www.youtube.com/watch?v=sBFJwVeAwEk&list=PLmQBKYly8OsUPN4zqn3nedxSB0DMoVnX5

목표 : 핀토스에서 유저 프로그램 돌아가게 만들자
1.system call 구현
2. 새 프로세스 시작시키기
3. 실행 파일 write 못하게 하기

지금 시스템 콜 핸들러 테이블이 비어있는데
유저가 쓸 수 있게 시스템 콜 만들어라
- process related: halt, exit, exec, wait
- file related: create, remove, open, read, write, seek, tell, close
수정할 거
- pintos/src/threads/thread.*
- pintos/src/userprog/syscall.*
- pintos/src/userprog/process.*
시스템 콜 호출 절차
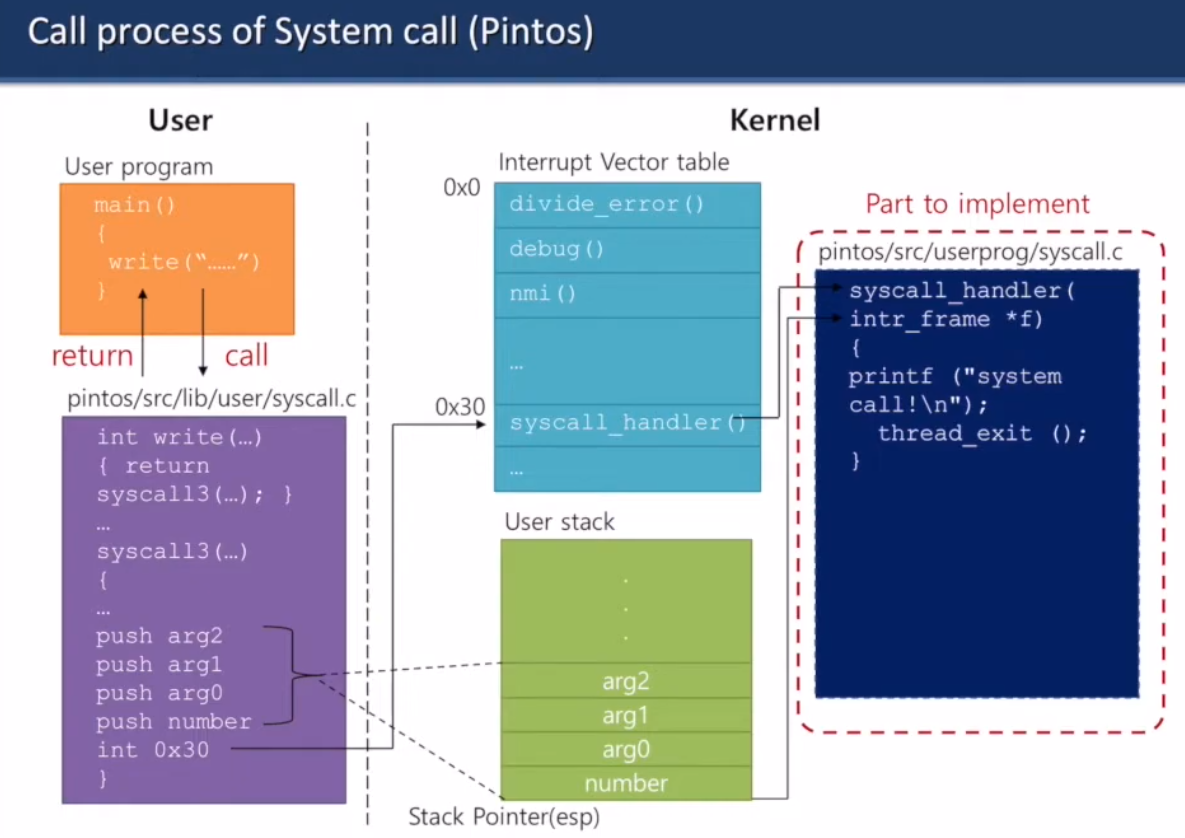
시스템 콜 하면 syscall.c로 감.
인자 3개면 syscall3 호출.
입력했던 인자들은 유저스택으로 감.
0x30로 가면 interrupt vector table 안의 syscall_handler() 호출.
지금은 비어있음. 너 이거 구현해야 됨.
시스템 콜 핸들러

시스템 콜들에 숫자 지정돼있으니까 switch문 쓰셈
시스템 콜 구현하기

- 시스템 콜 숫자로 '시스템 콜 핸들러'가 '시스템 콜'을 호출할 수 있게 해라
- 인자 리스트에 있는 포인터들이 유효한지 확인해라
- 포인터들은 유저 영역에 있어야 함. 커널 영역 안됨.
- 포인터들이 유효하지 않은 주소 가리키면 page fault
- 유저 스택에 있는 인자들을 커널로 복사해라
- 시스템 콜의 반환값을 eax 레지스터에 저장해라
커널은 유저 스택에 접근하는게 아니라 유저 스택에 있는 데이터를 커널 스택으로 옮긴 다음 사용

사용자는 시스템 콜에 잘못된 포인터를 넣을 수 있다
- 널 포인터 / 가상 주소에 할당 안된 포인터
- 커널 가상 주소 공간 포인터 (PHYS_BASE 위에)
커널은 포인터가 유효한지 확인하고 커널이나 다른 프로세스들 고장 안 내게 프로세스 죽여야 됨
어떻게 detect? (깃북에도 있었음)
-
방법 1: 유저가 넣은 포인터가 맞는지 확인
- 유저 메모리 접근을 다루는 가장 간단한 방법
userprog/pagedir.c와threads/vaddr.h에 있는 함수들 써라
-
방법 2: 포인터가 PHYS_BASE 아래에 있는지만 확인한다
- 유효하지 않은 포인터는 page_fault 일으킬 거임. page_fault() 코드 건드리면 됨.
- MMU를 사용하기 때문에 방법 1보다 빠름
- 진짜 커널은 이렇게 함
ㅇㅋ 나는 간단한 방법으로 할거임

메모리 누수시키지 마셈
lock이나 malloc 했었는데 프로세스 그냥 죽여버리면 메모리 누수됨.
- 1번째 방법으론 해결 쉬움
- 포인터 유효성 확인한 뒤에만 lock 걸거나 allocate 하셈
- 2번째 방법은 좀 어려움
- 메모리 접근할 때 에러 코드 반환할 수가 없음
- 이때는 제공한 함수를 쓰셈 (get_user나 put_user 쓰거나 page_fault()에서 eax를 0xffffffff로 설정하고 eip에서 이전 값을 복사해온다)

pintos는 halt로만 꺼져야 한다
unix에서의 exec랑 다르다
pintos에서의 exec은 fork랑 exec 섞은거
Process Hierarchy
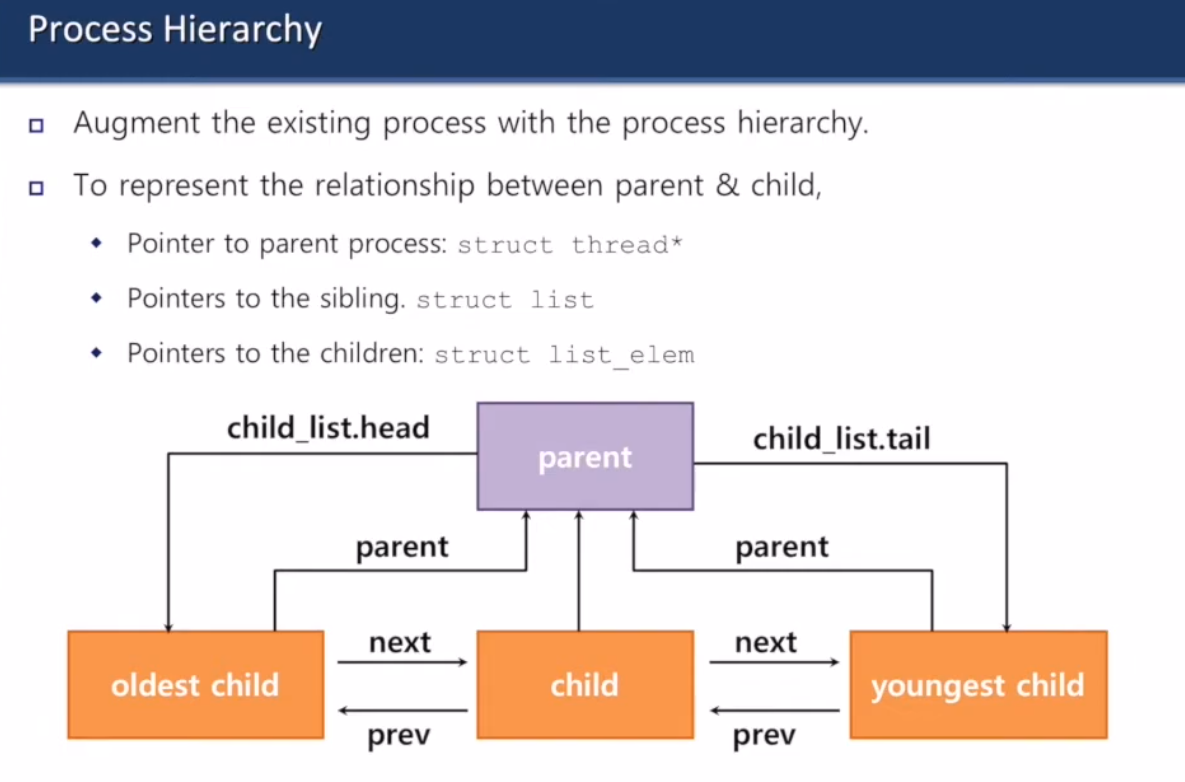
자식 프로세스들을 리스트로 갖는듯?
child끼리는 연결되는데 parent에는 head랑 tail 정보만 갖고 있으면 된다고 함
wait()

- 자식 프로세스 pid가 끝날 때까지 기다리고 자식의 exit status를 반환
- pid가 살아있으면, 종료될 때까지 기다린다.
- pid가 exit를 호출하지 않았는데 커널에 의해 꺼졌으면 -1 반환
- 부모가 이미 죽은 자식 wait 걸 수 있는데 이러면 종료된 자식 프로세스의 exit status 반환
- child가 종료된 후에 부모는 프로세스 디스크립터 할당 해제해야됨
- wait가 fail하면 -1 반환
- pid가 호출한 프로세스의 직계 자식이 아님
- 이미 기다리고 있는 프로세스를 또 기다리려고 함
process_wait() 수정해야 될건데, 어려우니까 지금은 infinite loop로 만들어놔라.

process_wait()
- child_tid인 child process의 디스크립터를 찾는다
- 호출자는 child process가 끝날 때까지 블락된다
- child process가 끝나면, child process의 디스크립터를 할당 해제하고 exit status를 반환한다
Semaphore
- 쓰레드 구조체에 0인 세마포어 만들고 쓰레드 대기타게 한 다음에 자식 쓰레드 끝나면 sema_up
Exit status
- 쓰레드 구조체에 exit status를 추가한다
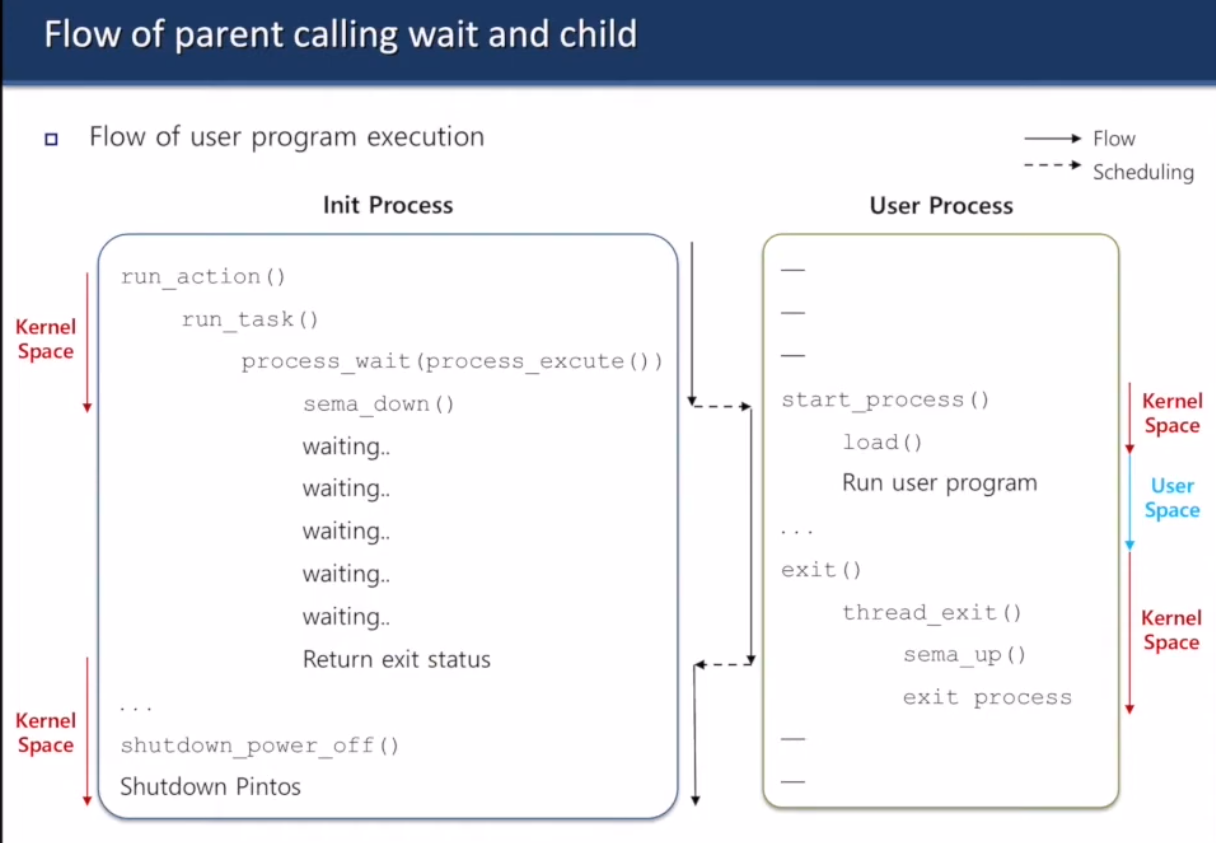
자식 프로세스 exit할 때 sema_up 해라
exec()

- cmd_line을 받아서 프로그램 실행
- 쓰레드 만들고 실행. pintos의 exec()은 unix에서의 fork()랑 exec() 합친 거랑 같다.
- 실행될 프로그램의 인자를 넘긴다
- 새 자식 프로세스의 pid를 반환한다
- 프로그램 로드하거나 만드는데 실패하면 -1 반환
- exec를 호출하는 부모 프로세스는 자식 프로세스가 생성되어 완벽하게 load될 때까지 기다려야 한다

이거 기다릴 때도 semaphore 사용
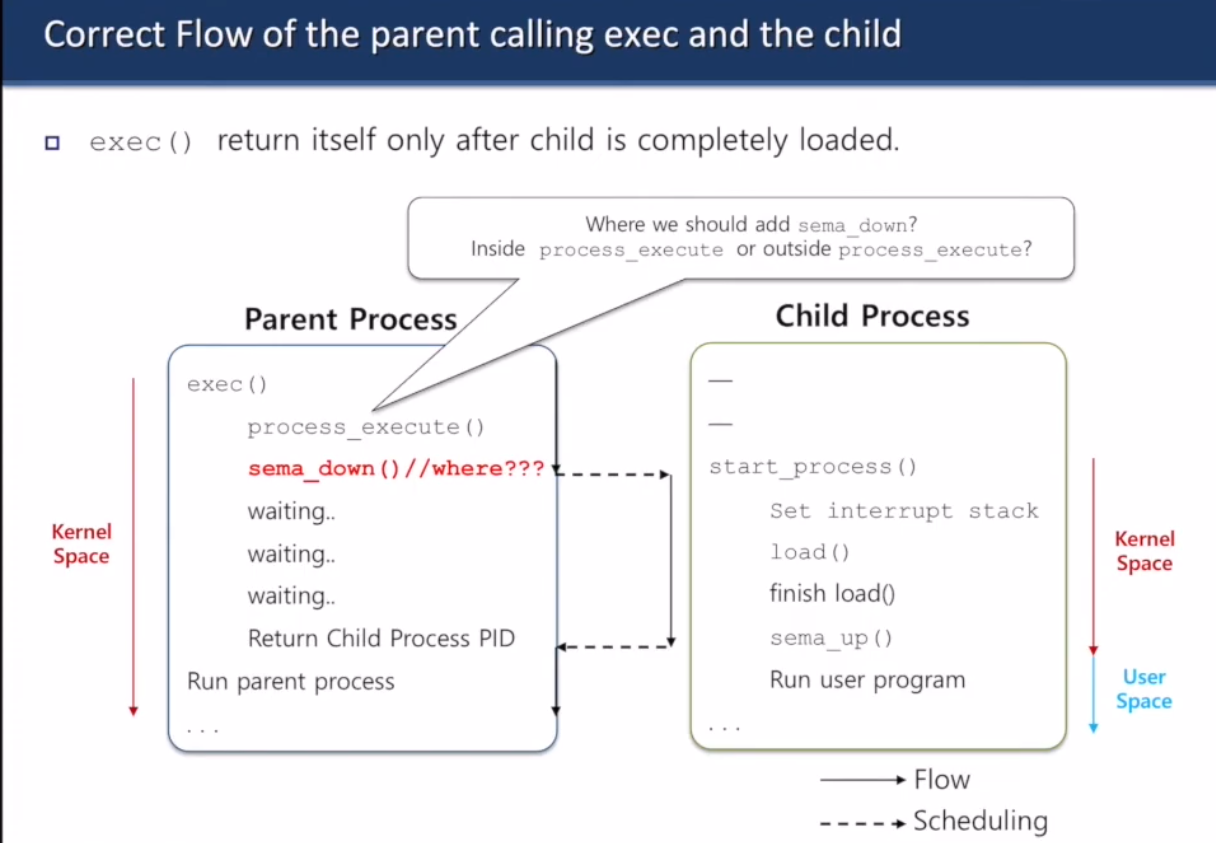
sema_down을 어디에 놓을까요? 키히힛
이러고 답은 안 알려줌
📌 [Week04] Pintos Project2 file manipulation
https://www.youtube.com/watch?v=SqMD8rbmEjY
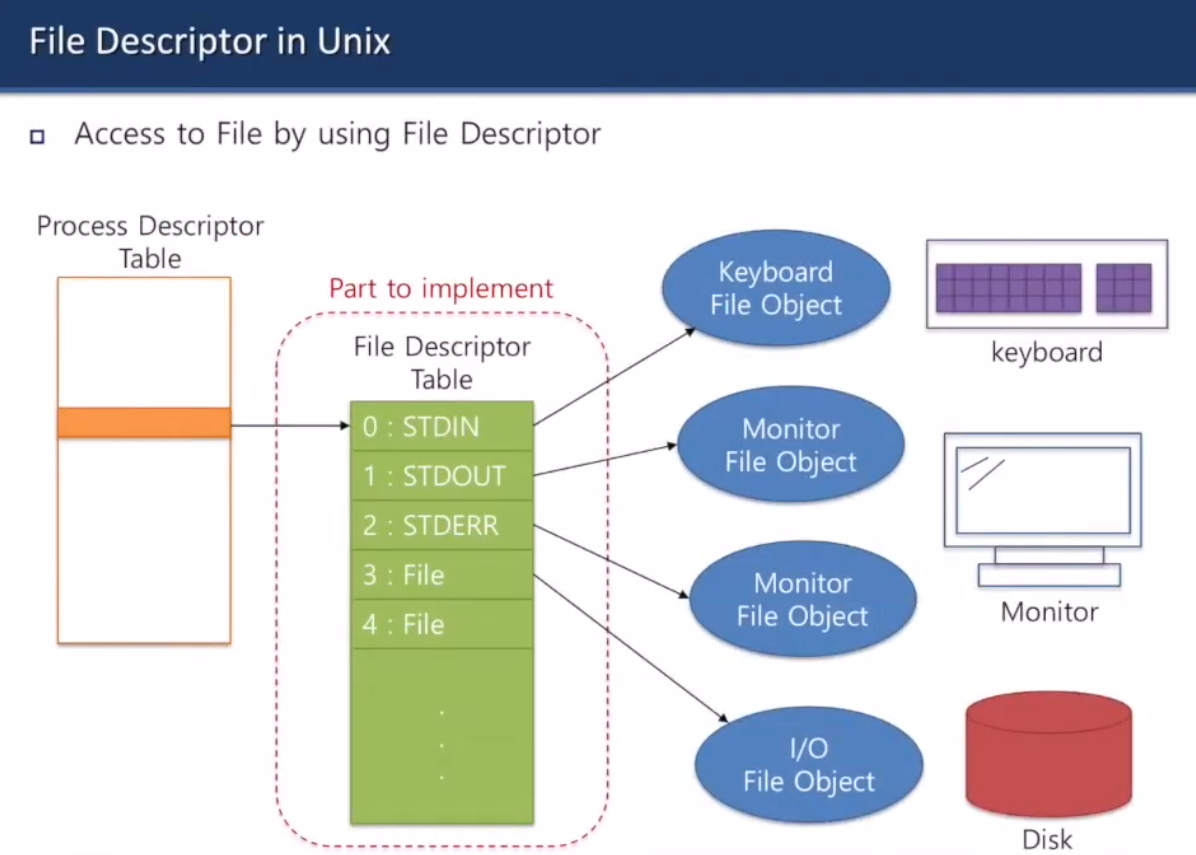
핀토스에는 file descriptor table이 없어서 너네가 만들어야 됨

- 각각의 프로세스는 고유한 파일 디스크립터 테이블이 있음 (최대 크기: 64 엔트리)
- 파일 디스크립터 테이블은 파일을 가리키는 포인터의 배열임
- FD는 파일 디스크립터 테이블의 인덱스임. 연속적으로 할당됨.
- open() 하면 fd 반환함
- close() 하면 index fd에 있는 파일 디스크립터 엔트리를 0으로 리셋함
파일 디스크립터 테이블
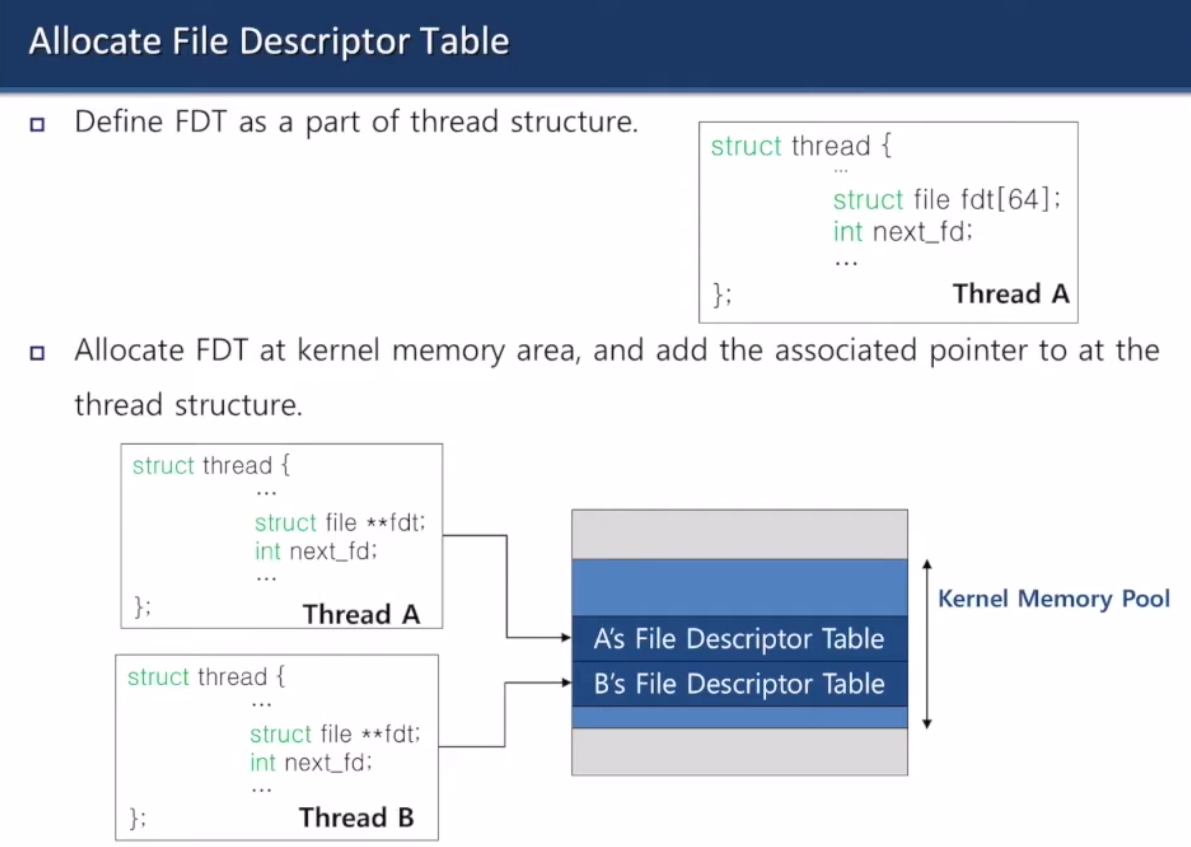
이런 느낌으로 만드쇼

thread가 만들어지면
- 파일 디스크립터 테이블 할당하기
- 파일 디스크립터 테이블 가리키는 포인터 초기화
- fd0과 fd1을 표준 입력과 표준 출력으로 지정
thread가 종료되면
- 모든 파일을 닫기
- 파일 디스크립터 테이블 할당 해제
파일에 대한 경쟁조건 없애기 위해 global lock 사용
- syscall.h에 global lock 정의
- syscall_init()에서 lock_init()으로 lock을 초기화하기
- global lock으로 파일 시스템과 관련된 코드를 보호하기
페이지 폴트와 시스템 콜 수정할 것들
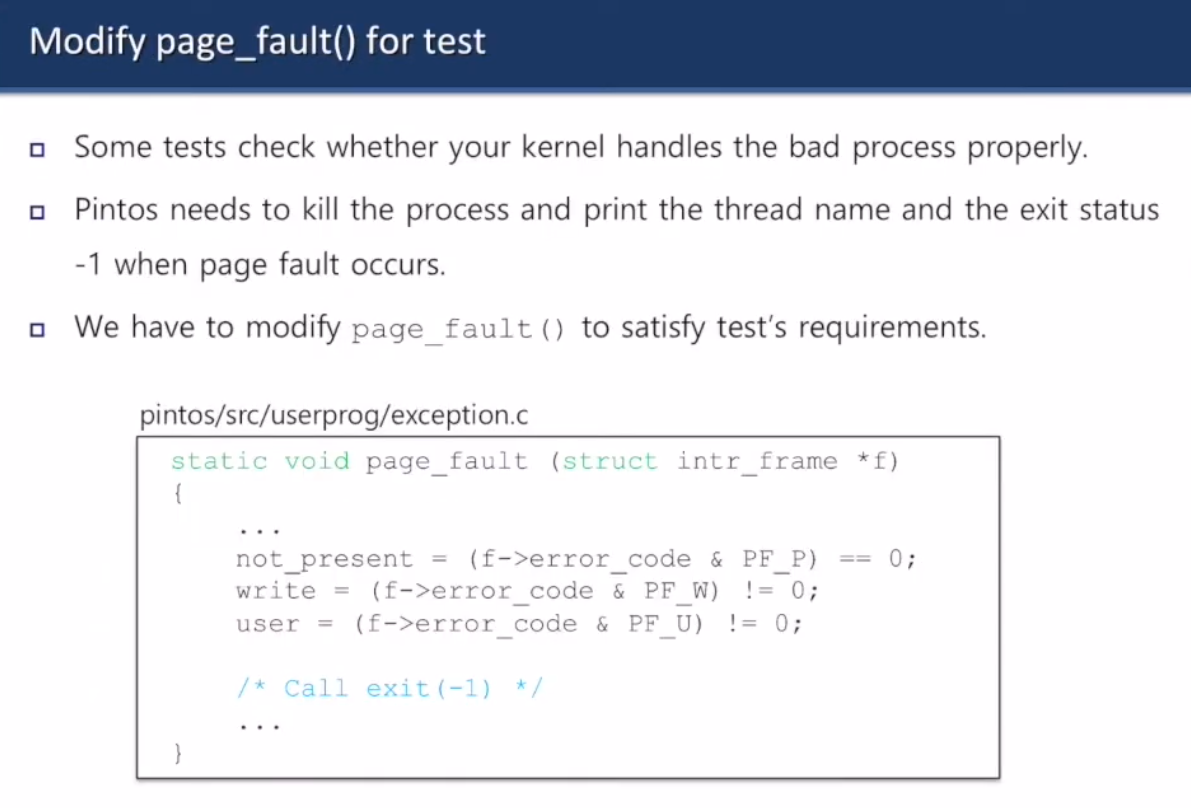
- 어떤 테스트는 커널이 이상한 프로세스 잘 처리하나 확인함
- 페이지 폴트 발생하면 프로세스 죽인 다음 죽인 놈 이름하고 exit status 상태 -1을 출력
- page_fault() 수정하셈

ㅋㅋ 이것도 만드셈
create()
- initial_size를 size로 갖는 파일을 만들기
- filesys_create() 쓰셈
- 성공하면 true, 실패하면 false 반환
remove()
- 파일 이름이 file인 거 지우기
- filesys_remove() 쓰셈
- 성공하면 true, 실패하면 false 반환
- 열려있건 닫혀있건 삭제시킬것
open()
- 인자로 받은 경로에 있는 파일을 연다
- 해당 파일의 fd 반환
- filesys_open() 쓰셈

ㅋㅋ 이것도임
filesize()
- fd로 열린 파일의 바이트 단위 크기 반환
- file_length() 쓰셈
read()
- fd로 열린 파일의 size 바이트만큼을 읽어서 버퍼에 넣어라
- 실제로 읽은 바이트 크기 반환. 실패하면 -1 반환.
- fd가 0이면 input_getc()을 사용해서 키보드에서 읽음. 아니면 file_read()로 파일을 읽음.

...이것도임
write()
- 버퍼에서 size 바이트만큼 열려있는 파일
fd에 write해라 - 실제로 써진 바이트 크기 반환
- fd가 1이면 putbuf()를 사용해서 console에 write한다. 아니면 파일에 file_write()로 write한다.
seek()
- 열려있는 파일
fd에서 다음에 읽거나 쓸 바이트를position으로 바꾼다 - file_seek() 써라

tell()
- 열려있는 파일
fd에서 다음에 읽을 바이트의 위치를 반환 - file_tell() 써라
close()
- fd 닫기
- file_close() 써라

실행 중이면 쓰기 못하게 해라
뭘 해야되는 건지 요약
📌 [Week04] 16 segmentation
https://www.youtube.com/watch?v=k-CA2WxCknE
segment는 특정한 길이의 연속적인 주소 공간.
논리적으로 다른 segment: code, stack, heap
물리 주소는 offset과 base로 이루어짐
base: 메모리 블록의 시작 위치
offset: 기준 주소로부터 얼마나 떨어져 있는지 나타내는 값
맞습니다. 가상 주소에서도 오프셋(offset) 개념이 사용됩니다. 이전 설명에서 물리 주소에 대한 베이스(base)와 오프셋(offset) 개념을 설명했지만, 가상 주소 체계에서도 이와 유사한 개념이 적용됩니다. 이를 보다 명확히 이해하기 위해 가상 주소와 물리 주소 간의 관계 및 메모리 관리 기법인 페이지 테이블(Page Table) 에서의 오프셋 사용에 대해 자세히 설명드리겠습니다.
현대의 운영체제는 가상 메모리 시스템을 사용하여 가상 주소를 물리 주소로 변환합니다. 이 과정에서 페이지 테이블(Page Table) 이 중요한 역할을 합니다.
- 페이지(Page):
- 가상 메모리와 물리 메모리를 일정한 크기의 블록으로 나눈 단위입니다. 일반적으로 4KB 크기를 사용합니다.
- 페이지 테이블(Page Table):
- 각 프로세스마다 존재하며, 가상 페이지 번호(Virtual Page Number)를 물리 페이지 번호(Physical Page Number)로 매핑하는 표입니다.
- 페이지 테이블을 통해 가상 주소의 상위 비트(페이지 번호 부분)를 물리 주소의 페이지 프레임으로 변환하고, 하위 비트(오프셋)는 그대로 사용하여 최종 물리 주소를 생성합니다.
가상 주소의 구조: 페이지 번호와 오프셋
가상 주소는 페이지 번호와 오프셋으로 구성됩니다.
- 페이지 번호(Page Number):
- 가상 주소의 상위 비트로, 페이지 테이블에서 해당 페이지가 매핑되는 물리 페이지 프레임을 찾는 데 사용됩니다.
- 오프셋(Offset):
- 가상 주소의 하위 비트로, 페이지 내에서의 특정 위치를 나타냅니다.
- 페이지 내에서 데이터가 어디에 위치하는지를 지정하는 값입니다.
물리 주소의 구조: 프레임 번호와 오프셋
물리 주소도 유사하게 프레임 번호(Frame Number) 와 오프셋(Offset) 으로 구성됩니다.
- 프레임 번호(Frame Number):
- 물리 메모리의 페이지 프레임을 식별하는 번호입니다.
- 페이지 테이블에서 가상 페이지 번호에 해당하는 물리 페이지 프레임 번호를 찾는 데 사용됩니다.
- 오프셋(Offset):
- 페이지 내에서의 특정 위치를 나타내며, 가상 주소의 오프셋과 동일합니다.
주소 변환 과정
- 가상 주소 분리:
- 가상 주소를 페이지 번호와 오프셋으로 분리합니다.
- 페이지 테이블 조회:
- 페이지 번호를 사용하여 페이지 테이블에서 해당하는 물리 페이지 프레임 번호를 찾습니다.
- 물리 주소 구성:
- 물리 페이지 프레임 번호와 가상 주소의 오프셋을 결합하여 최종 물리 주소를 생성합니다.
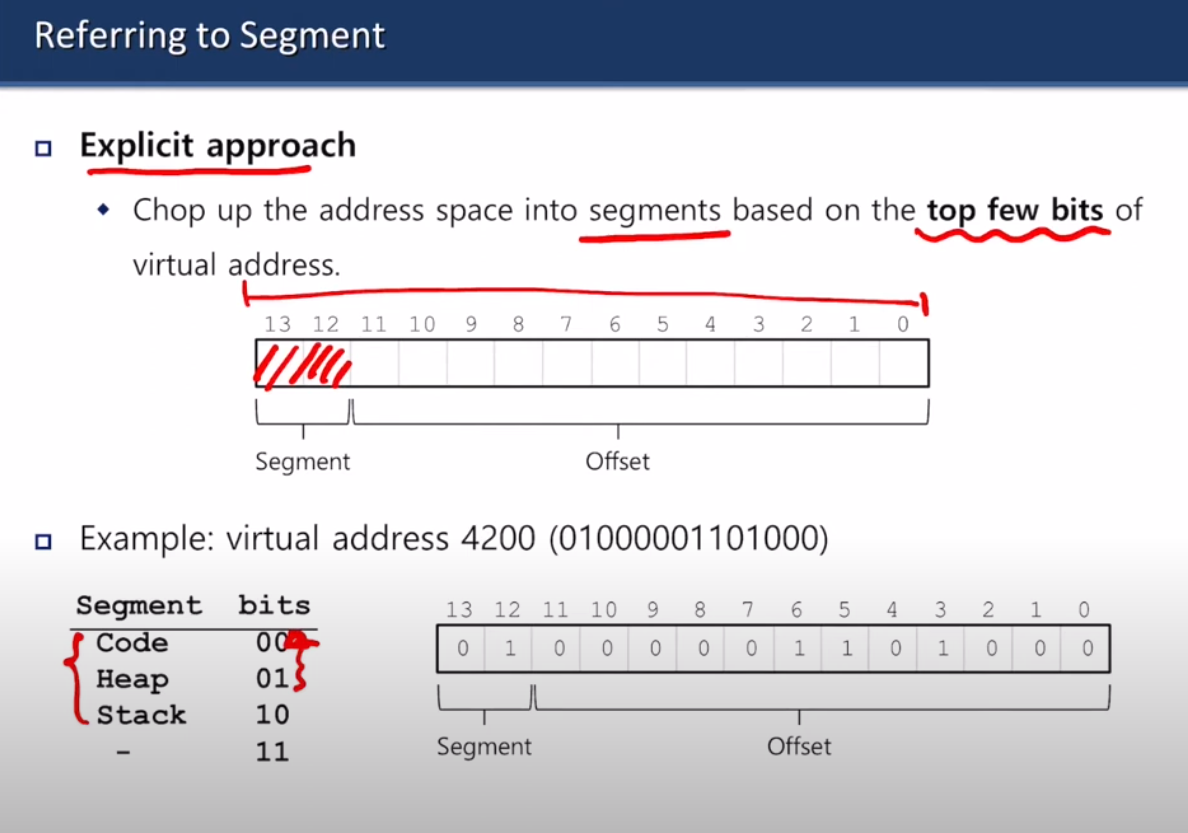
주소 공간 맨 앞 두 비트는 segment로 할당. code는 00, heap은 01, stack은 10

코드 공간 공유 가능. 보호해야됨.

https://wooono.tistory.com/330
Coarse-Grained
하나의 작업을 큰 단위의 프로세스로 나눈 뒤,
"Single Call" 을 통해, 작업 결과를 생성해내는 방식
예를 들어, Do() 라는 함수가 있다면
단순히, Do() 를 호출해 작업 결과를 생성해내는 방식
Fine-Grained
하나의 작업을 작은 단위의 프로세스로 나눈 뒤,
다수의 호출을 통해, 작업 결과를 생성해내는 방식
예를 들어, Do() 라는 함수가 있다면
해당 함수를 First_Do(), Second_Do() 로 나누어 작업 결과를 생성해내는 방식

외부 단편화 : 공간이 쪼개지면 못 담아
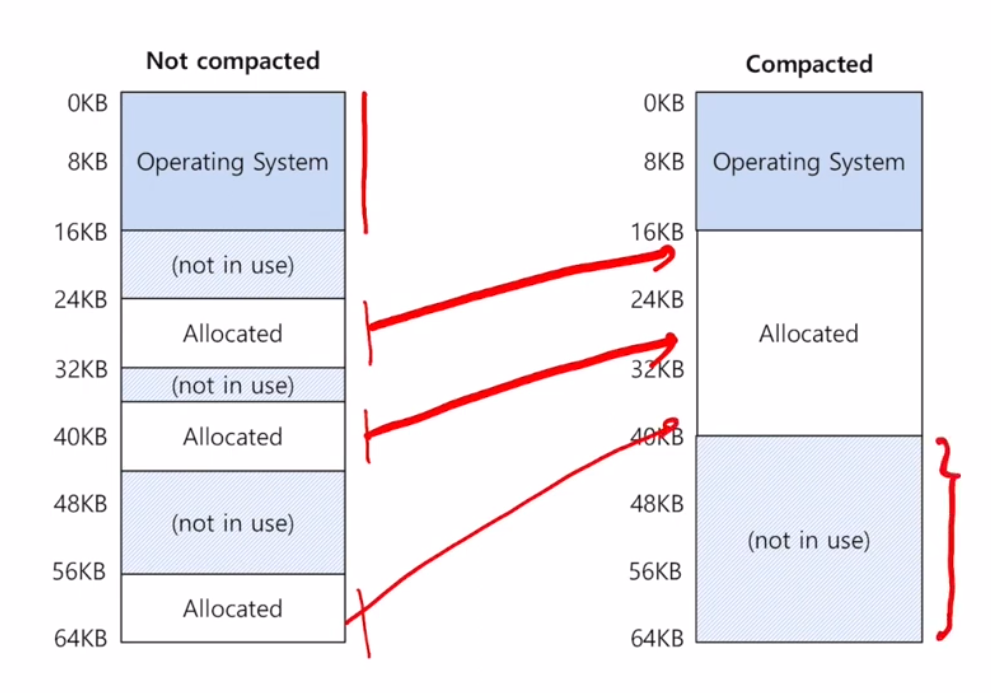
그래서 compaction(디스크 조각모음) 해야돼
원래는 segmentation 썼는데 x86-64부터는 안 씀
