🎯 To-do List
✅ 백준 1문제 풀기
☑️ c++ 공부
📝 배운 것들
🏷️ demand-zero memory
demand-zero memory라는 것은 말그대로 필요할 때(demand) 할당하고 0으로 초기화해주는(zero) 메모리를 말한다.
리눅스의 메모리 시스템은 매우, 최대한 게으른 방식(lazy)으로 작동하도록 되어있다.
게으르단 뜻은 어떤 자원을 요청하거나 동작을 요청했을 때, 그것이 정말 필요해질 때까지 실제 자원을 할당하거나 동작을 실행하지 않는 것을 의미한다.
즉, 우리(user program)가 kernel에게 메모리를 할당해달라고 요청하면(sbrk) kernel은 거의 아무것도 하지 않고(특정한 VM 영역이 할당되었다는 최소한의 표시만 해두고) 우리에게 할당이 끝났다고 알려준다.
즉, 특정 VM 영역이 할당되었다는 사실만 표시해두고, 실제 메모리는 할당되지 않은 상태로 남아있게 된다.
이렇게 되면 유저는 메모리가 할당된줄알고 해당 주소에 뭔가를 쓰거나 읽을텐데, 처음 읽거나 쓰려고 하는 순간 실제 메모리(페이지)가 할당되어있지 않기 때문에 page fault가 발생할 것이고, 그제서야 kernel은
사용하지 않는 메모리(페이지)를 할당하고
그 페이지를 0으로 채운뒤에
유저가 원래 하려고했던 명령어를 다시 실행하게 된다.
-> 오늘 이거 논쟁하느라 시간을 많이 잡아먹었다. 알아보니까 demand-zero memory라는 개념이 책에서만 언급되는 내용이고 (영어권 검색 결과에도 안 잡힘) gpt가 뭐라뭐라 말하는게 환각인지 의심돼서 중요하게 생각하면 안될 것 같음.
📦 Malloc
📌 시작
가장 간단히 상상할 수 있는 할당기는 힙을 하나의 커다란 바이트의 배열과 이 배열의 첫 번째 바이트를 가리키는 포인터 p로 구성할 수 있다. size 바이트를 할당하기 위해서 malloc은 현재 p 값을 스택에 저장하고, p를 size 크기만큼 증가시키고, p의 이전 값을 호출자에게 리턴한다. Free는 아무것도 하지 않고 단순히 호출자에게 리턴한다. 이 초보적인 할당기는 디자인 공간에서 극단점에 해당한다. 각 malloc과 free가 적은 수의 인스트럭션들을 실행하기 때문에 처리량은 매우 좋다. 그렇지만, 할당기는 블록들 을 하나도 재사용하지 않기 때문에 메모리 이용도는 매우 나쁠 것이다.
/*
* mm_malloc - Allocate a block by incrementing the brk pointer.
* Always allocate a block whose size is a multiple of the alignment.
*/
void *mm_malloc(size_t size)
{
int newsize = ALIGN(size + SIZE_T_SIZE);
void *p = mem_sbrk(newsize);
if (p == (void *)-1)
return NULL;
else
{
*(size_t *)p = size;
return (void *)((char *)p + SIZE_T_SIZE);
}
}
/*
* mm_free - Freeing a block does nothing.
*/
void mm_free(void *ptr)
{
}현재 mm.c에 구현돼있는 malloc 함수는 가장 기초적인 구현 방식을 채택하고 있다.
여유 블록 조직: 여유 블록을 어떻게 추적할 것인가?
배치: 새로 할당된 블록을 어떤 여유 블록에 배치할 것인가?
분할: 새로 할당된 블록을 여유 블록에 배치한 후 남은 여유 블록을 어떻게 처리할 것인가?
병합: 방금 해제된 블록을 어떻게 처리할 것인가?
이제부터 이 문제들을 고려하며 malloc을 개선시켜야 한다. 우선
📌 블록 헤더
할당기가 블록 경계를 구분하고 할당된 블록과 여유 블록을 구별할 때 필요한 데이터 구조를 만들어야 한다.
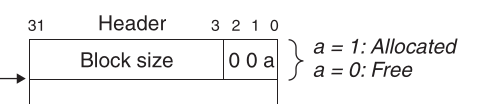
이 데이터 구조를 만들어보자.
한 블록을 1워드 헤더, 데이터, 추가적인 패딩으로 구성해야 한다.
헤더에는 블록 크기(헤더와 추가적 패딩 포함)와 블록이 할당되었는지를 기록한다.
패딩은 넣어도 되고(할당기 전략과 정렬 요구사항 때문) 안 넣어도 된다는데 일단 넣어보자.
근데 바로 문제가 발생함. 책에 이런 내용이 있었음.
만일 더블 워드 정렬 제한조건을 부과한다면 블록 크기는 항상 8의 배수이고, 블록 크기의 하위 3비트는 항상 0이다.
더블 워드 정렬
더블 워드 정렬(double word alignment)란 데이터가 메모리에 저장될 때 특정 크기(보통 4바이트나 8바이트)의 주소 경계에 맞춰 저장되는 것을 의미합니다. 이를 통해 메모리 접근 속도를 최적화할 수 있습니다.
8바이트 정렬
8바이트 정렬이란, 메모리 주소가 8의 배수로 되어 있다는 것을 의미합니다. 다시 말해, 주소의 마지막 3자리(3비트)가 0으로 끝난다는 뜻이에요. 예를 들어, 주소가 8의 배수인 경우를 생각해보세요:
0 (2진수: 0000) - 마지막 3자리: 000
8 (2진수: 1000) - 마지막 3자리: 000
16 (2진수: 10000) - 마지막 3자리: 000
24 (2진수: 11000) - 마지막 3자리: 000
위 예시에서 보듯이, 8의 배수로 끝나는 주소는 항상 마지막 3비트가 000입니다.
라고 gpt가 답변해주긴 햇는데, 그래서 이걸 어떻게 구현함?
...
네트워크 강의 듣고 팀 코어타임 진행하고 그밖에 여러가지를 한 후 다시 와서 봤는데,
이번 과제는 책을 보지 않으면 진행 자체가 불가능하다는 사실을 깨달음
그냥 내일 다시 책 보면서 해봐야될듯
⚔️ 백준
📌 15651 N과 M (3)
N, M = map(int, input().split())
def combi(l,arr):
global N, M
if l >= M:
for n in arr:
print(n,end=' ')
print()
return
for i in range(1,N+1):
combi(l+1,arr+[i])
combi(0,[])📌 15652 N과 M (4)
N, M = map(int, input().split())
def combi(l,arr):
global N, M
if l != 0 and l != 1 and arr[-2] > arr[-1]:
return
if l >= M:
for n in arr:
print(n,end=' ')
print()
return
for i in range(1,N+1):
combi(l+1,arr+[i])
combi(0,[])📌 15653 N과 M (5)
N, M = map(int, input().split())
input_arr = list(map(int,input().split()))
input_arr.sort()
def combi(l,arr,avail):
global N, M
if l == M:
for n in arr:
print(n,end=' ')
print()
return
for i in range(N-l):
combi(l+1,arr+[avail[i]],avail[:i]+avail[i+1:])
combi(0,[],input_arr)fault 1
for n in arr:
print(n,end=' ')
print()
return이런식으로 print()와 return에 탭을 넣어줘서
1
7
8
7
9 결과가 이렇게 나와버렸었음
