🎯 To-do List
✅ solved.ac 랜덤 마라톤 (c언어) | 2558, 14645, 15962, 15727, 27924, 30328, 25628, 11586
✅ 알고리즘 스터디 | 2468 안전영역
☑️ c++ 공부하기
☑️ (다 끝내고) 복습을 위해 이거 보기
📚 Journal
-
밥 먹거나 이동할 때 백준 문제 푸는 건 아무리 브론즈여도 타이핑이 느려서 효율이 안 좋은듯. 차라리 텍스트를 읽는게 낫다.
-
1주차 때 못 풀었던 안전 영역을 손대봤는데,
생각보다 빠르고 쉽게 풀렸다.
40일 동안 그래도 성장하긴 한 모양이다.
📝 배운 것들
🏷️ c언어 동적 배열 초기화
char arr[100][100] = {};
이건 되고
char arr[a][a]={};
이건 안되는 이유가 뭐임?
C 언어에서는 배열을 선언할 때 배열의 크기가 고정되어 있어야 합니다. 즉, 배열의 크기는 컴파일 타임에 알 수 있어야 합니다. 이를 "정적 배열"이라고 합니다. 하지만 a와 같은 변수를 사용하여 배열의 크기를 지정하는 경우, 배열의 크기는 런타임에 결정됩니다. 이를 "가변 길이 배열" 또는 VLA(Variable Length Array)라고 합니다.
정적 배열 초기화
정적 배열을 선언하고 초기화할 때는 다음과 같이 할 수 있습니다:
char arr[100][100] = {};이 경우, 배열의 크기가 컴파일 타임에 고정되어 있으므로, 컴파일러는 배열의 초기값을 0으로 설정할 수 있습니다.
가변 길이 배열 (VLA)
반면에, a와 같은 변수를 사용하여 배열의 크기를 지정하는 경우:
int a;
scanf("%d", &a);
char arr[a][a] = {};이 경우, arr 배열의 크기는 런타임에 결정됩니다. C99 표준부터 지원되는 VLA는 초기화 리스트 {}를 사용할 수 없습니다. VLA는 배열의 크기가 런타임에 결정되므로, 초기화 값을 컴파일 타임에 알 수 없습니다.
해결 방법
가변 길이 배열을 초기화하려면, 초기화 루프를 사용해야 합니다. 다음은 예제입니다:
#include <stdio.h>
#include <string.h> // memset 사용을 위해 추가
int main() {
int a;
scanf("%d", &a);
char arr[a][a];
// 배열 초기화
memset(arr, 0, sizeof(arr));
// 문자열 입력
for (int i = 0; i < a; i++) {
scanf("%s", arr[i]);
}
// 입력된 문자열 출력
for (int i = 0; i < a; i++) {
printf("%s\n", arr[i]);
}
return 0;
}설명
memset를 사용하여 배열을 0으로 초기화합니다. memset 함수는 메모리의 특정 영역을 지정된 값으로 설정하는 함수입니다.
memset(arr, 0, sizeof(arr));📦 Malloc : 기본 상수 및 매크로 정의
상수
#define WSIZE 4 // 워드, 헤더, 푸터 사이즈 (바이트)
#define DSIZE 8 // 더블 워드 사이즈 (바이트)
#define CHUNKSIZE (1 << 12) // 힙을 이만큼 늘려야 함 (바이트)워드 하나가 4바이트라고???
CHUNKSIZE는 또 뭔 소리임? 비트 연산을 왜 하는거임?
워드(Word)의 크기
워드는 컴퓨터 시스템에서 데이터를 처리하는 기본 단위입니다.
#define WSIZE 4는 워드, 헤더, 푸터의 크기가 4바이트임을 의미합니다. 이 크기는 32비트 시스템에서 일반적인 워드 크기입니다.
더블 워드(Double Word)
더블 워드는 워드의 두 배 크기를 의미합니다.
#define DSIZE 8는 더블 워드의 크기가 8바이트임을 의미합니다. 64비트 시스템에서 더블 워드는 64비트(8바이트)입니다.
CHUNKSIZE
CHUNKSIZE는 힙 메모리를 한 번에 얼마나 늘릴지를 정의하는 매크로입니다. 여기서 비트 시프트 연산이 사용됩니다.
#define CHUNKSIZE (1 << 12)는 CHUNKSIZE가 2의 12승, 즉 4096바이트임을 의미합니다. 비트 시프트 연산은 왼쪽으로 12비트를 이동시켜 2^12을 빠르게 계산하는 방법입니다. 이는 4096바이트와 동일합니다.
비트 시프트 연산
비트 시프트 연산은 비트를 좌우로 이동시켜서 곱셈이나 나눗셈을 빠르게 수행할 수 있는 방법입니다.
(1 << 12)는 1을 12비트 왼쪽으로 이동시켜 4096을 나타냅니다. 즉, 1에 2의 12승을 곱하는 것과 같은 효과를 가집니다.
매크로 정의의 의미
이제 각 매크로의 의미를 정리해보겠습니다.
-
#define WSIZE 4- 워드의 크기가 4바이트입니다. 이는 메모리에서 기본적인 단위로 사용됩니다.
-
#define DSIZE 8- 더블 워드의 크기가 8바이트입니다. 이는 두 개의 워드 크기와 동일합니다.
-
#define CHUNKSIZE (1 << 12)- 힙 메모리를 한 번에 늘릴 크기인 4096바이트를 정의합니다. 이는 메모리 할당 시 효율성을 높이기 위해 사용됩니다.
그럼 나는 64비트 운영체제니까 WSIZE 대신 DSIZE를 써야되는거임?
64비트 운영체제에서 64비트 워드 크기를 사용할지 여부는 사용하려는 메모리 관리 시스템의 요구 사항에 따라 다릅니다. 메모리 관리 시스템을 설계할 때, 워드 크기와 더블 워드 크기를 어떻게 사용할지 결정해야 합니다.
WSIZE와 DSIZE의 사용
-
WSIZE (워드 사이즈):
- 32비트 시스템에서 일반적으로 4바이트입니다.
- 64비트 시스템에서도 메모리 관리와 같은 경우, 특정 구조체의 헤더나 푸터를 4바이트로 정의하는 경우가 있습니다.
-
DSIZE (더블 워드 사이즈):
- 64비트 시스템에서 일반적으로 8바이트입니다.
- 메모리 블록의 정렬을 맞추기 위해 더블 워드를 사용할 수도 있습니다.
64비트 운영체제에서의 사용
64비트 운영체제에서 64비트 포인터와 데이터가 기본적으로 사용되기 때문에 더블 워드를 사용하는 것이 더 적합할 수 있습니다. 그러나 이는 전체 시스템 설계에 따라 다릅니다. 예를 들어, 메모리 관리 시스템에서 메모리 블록의 크기와 헤더 정보를 저장할 때 워드를 사용하거나 더블 워드를 사용할 수 있습니다.
요약
64비트 운영체제에서 반드시 WSIZE 대신 DSIZE를 사용해야 하는 것은 아닙니다. 메모리 관리 시스템의 요구 사항에 따라 워드 크기와 더블 워드 크기를 적절히 선택하면 됩니다. 더블 워드를 사용하면 64비트 포인터와 데이터를 보다 효율적으로 처리할 수 있습니다. 각 매크로와 자료형을 시스템의 설계에 맞게 조정하면 됩니다.
PACK
pack a size and allocated bit into a word 무슨 뜻인지 해석좀
하나의 워드에 메모리 블록의 크기와 할당 상태를 함께 저장하여, 메모리 블록의 정보를 효율적으로 관리하고자 하는 것입니다. 이는 메모리 관리 시스템에서 블록의 상태를 추적하고, 할당 및 해제 작업을 수행할 때 유용합니다.
#define PACK(size, alloc) ((size) | (alloc))
이걸로 어떻게 하나의 워드에 저장시킨다는거임? 애초에 워드는 나와있지도 않는데? | 이건 뭐임?
좋은 질문입니다! #define PACK(size, alloc) ((size) | (alloc))는 실제로 메모리 관리에서 크기와 할당 상태를 하나의 정수 값으로 결합하는 방법을 설명하는 코드입니다. 이 코드의 의미와 동작을 이해하기 위해, 각 부분을 살펴보겠습니다.
비트 연산과 워드
- 워드(word): 컴퓨터에서 데이터 처리 단위로, 32비트(4바이트) 또는 64비트(8바이트)를 의미합니다.
- 비트 연산: 여기서
|(비트 OR 연산자)는 두 값의 각 비트를 비교하여 하나라도 1이면 1을 반환하는 연산자입니다.
정의된 매크로 설명
#define PACK(size, alloc) ((size) | (alloc))- size: 메모리 블록의 크기를 나타내는 값입니다.
- alloc: 메모리 블록의 할당 상태를 나타내는 비트입니다. 예를 들어,
alloc이 1이면 할당된 상태를, 0이면 할당되지 않은 상태를 나타낼 수 있습니다.
어떻게 하나의 워드에 저장하나요?
- 비트 조합:
size와alloc은 각각 정수 값입니다.alloc은 보통 1비트(예: 0 또는 1)로 사용되며,size는 나머지 비트를 사용합니다. - 비트 OR 연산:
|연산자는 비트 OR 연산을 수행합니다. 예를 들어:size가 100(2진수로 01100100)이고alloc이 1(2진수로 00000001)이라면- 결과는 01100101이 됩니다.
이렇게 하면, 하나의 워드에 크기와 할당 상태를 함께 저장할 수 있습니다.
구체적인 예시
#define SIZE 100
#define ALLOC 1
#define PACKED_WORD (PACK(SIZE, ALLOC))SIZE는 100입니다 (이진수: 01100100).ALLOC은 1입니다 (이진수: 00000001).PACK(SIZE, ALLOC)는 01100100 | 00000001 = 01100101이 됩니다.- 따라서,
PACKED_WORD는 01100101 (십진수로 101)입니다.
이와 같은 방식으로 size와 alloc을 하나의 워드로 결합하여 저장할 수 있습니다. size는 주로 블록의 크기를 나타내는 큰 비트를 차지하고, alloc은 가장 낮은 비트를 사용하여 블록이 할당되었는지를 나타냅니다.
이 방법은 메모리 관리에서 매우 유용하며, 효율적으로 블록의 크기와 상태를 하나의 변수로 관리할 수 있게 해줍니다.
size가 할당 여부 비트를 사용할 가능성은 없음?
좋은 질문입니다. size가 할당 여부 비트를 사용할 가능성을 없애기 위해서, 할당 여부 비트(allocated bit)는 보통 가장 낮은 비트(least significant bit, LSB)를 사용하고, size는 그 나머지 비트를 사용합니다. 이렇게 하면 size와 allocated bit가 겹치지 않도록 설계할 수 있습니다.
구체적으로 설명하자면, 크기 정보는 보통 2의 배수로 저장되기 때문에, 가장 낮은 비트는 항상 0입니다. 따라서 이 비트를 할당 여부를 나타내는 비트로 사용할 수 있습니다. 예를 들어, 4바이트 단위의 크기 정보를 가진다면 크기는 4, 8, 12, 16, ... 이런 식으로 됩니다. 이러한 경우 이진수로 보면 항상 마지막 비트는 0이 됩니다. 이 점을 이용해 할당 여부를 나타내는 비트로 사용할 수 있습니다.
구체적인 예
size는 블록의 크기를 나타내며, 예를 들어 32바이트라면 이진수로 100000이 됩니다.alloc은 1비트로, 0 또는 1의 값을 가집니다.
예시를 통해 설명
-
크기가 32바이트이고 할당된 경우:
size= 32 (이진수: 100000)alloc= 1 (이진수: 000001)PACK(size, alloc)= 100000 | 000001 = 100001 (십진수로 33)
-
크기가 32바이트이고 할당되지 않은 경우:
size= 32 (이진수: 100000)alloc= 0 (이진수: 000000)PACK(size, alloc)= 100000 | 000000 = 100000 (십진수로 32)
이렇게 하면 size와 alloc이 겹치지 않으면서, 하나의 워드에 저장될 수 있습니다.
워드에서 정보 추출하기
이렇게 저장된 정보를 다시 추출할 때는 비트 연산을 사용합니다.
-
크기를 추출할 때:
#define GET_SIZE(packed_word) ((packed_word) & ~0x1)이 매크로는 할당 비트를 제외한 나머지 비트를 가져옵니다.
-
할당 여부를 추출할 때:
#define GET_ALLOC(packed_word) ((packed_word) & 0x1)이 매크로는 가장 낮은 비트만 추출하여 할당 여부를 확인합니다.
GET
#define MAX(x, y) ((x) > (y) ? (x) : (y))
이거는 자료형이 없는데
#define GET(p) ((unsigned int )(p))
이거는 자료형이 있는 이유가 뭐임?
사실 없어도 되는건데 오류 안 생기게 하려고 자료형 넣는거지?
네, 맞습니다. #define 매크로에서 자료형을 명시하는 이유는 코드의 안정성과 가독성을 높이기 위해서입니다. 구체적으로 각 매크로의 차이점을 설명하면 다음과 같습니다.
#define MAX(x, y) ((x) > (y) ? (x) : (y))
이 매크로는 두 값 중 더 큰 값을 반환하는 단순한 비교 연산을 수행합니다. 이 매크로는 두 값을 비교하여 큰 값을 선택하므로, 기본적으로 자료형에 대한 정보가 필요하지 않습니다. 주어진 두 값의 자료형이 무엇이든 비교 연산과 삼항 연산자는 적절하게 동작합니다.
#define GET(p) (*(unsigned int *)(p))
이 매크로는 포인터를 역참조하여 값을 가져오는 역할을 합니다. 이 경우 자료형을 명시하는 이유는 다음과 같습니다:
- 포인터 역참조: 포인터를 역참조할 때, 포인터가 가리키는 데이터의 자료형을 명확히 지정해야 합니다. 그렇지 않으면 컴파일러가 해당 메모리 주소에서 얼마나 많은 바이트를 읽어야 할지 알 수 없습니다.
- 자료형 변환:
(unsigned int *)(p)와 같은 형 변환을 통해 포인터p를unsigned int형 포인터로 변환합니다. 그런 다음, 역참조 연산자*를 사용하여unsigned int형 데이터를 가져옵니다. 이 과정에서 자료형을 명시하지 않으면 컴파일러는 메모리에 접근하는 방법을 알 수 없어 오류가 발생할 수 있습니다.
따라서, 포인터를 통해 메모리 접근을 할 때는 자료형을 명확히 지정하는 것이 중요합니다. 이는 코드가 예상대로 동작하도록 하고, 컴파일러가 올바른 메모리 접근을 보장하도록 합니다.
결론
#define GET(p) 매크로에서 자료형을 명시하는 이유는 포인터를 역참조할 때 정확한 자료형을 지정하여 컴파일러가 올바르게 메모리 접근을 할 수 있도록 보장하기 위해서입니다. 반면, #define MAX(x, y) 매크로는 단순히 두 값을 비교하여 더 큰 값을 반환하는 연산이므로, 자료형을 명시할 필요가 없습니다. 이렇게 함으로써 코드의 안정성과 가독성을 높일 수 있습니다.
GET_SIZE, GET_ALLOC
/ 주소 p에 있는 워드에서 메모리 블록의 크기와 할당 상태 읽기 /
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLOC(p) (GET(p) & 0x1)이건 또 뭐임? 7자리까지 읽고 1자리만 읽고 뭐 대충 그런 건 알겠는데 정확히 어떻게 동작하는지 모르겠음.
비트 연산
~0x7는0x7의 비트 반전입니다.0x7은 이진수로0000 0111입니다. 이를 비트 반전하면1111 1000이 됩니다.&연산자는 비트 AND 연산자입니다. 두 비트가 모두 1일 때만 1을 반환합니다.
GET_SIZE(p)
#define GET_SIZE(p) (GET(p) & ~0x7)GET(p): 주소p에서unsigned int값을 읽어옵니다.~0x7:0x7의 비트 반전으로1111 1000이 됩니다.GET(p) & ~0x7: 주소p에서 읽어온 값과1111 1000을 비트 AND 연산하여, 하위 3비트(할당 상태 비트와 크기 비트의 일부)를 제외한 상위 비트를 반환합니다.
이렇게 하면, 메모리 블록의 크기를 나타내는 비트들만 남게 됩니다.
GET_ALLOC(p)
#define GET_ALLOC(p) (GET(p) & 0x1)GET(p): 주소p에서unsigned int값을 읽어옵니다.0x1: 이진수로0000 0001입니다.GET(p) & 0x1: 주소p에서 읽어온 값과0000 0001을 비트 AND 연산하여, 가장 하위 비트만 남기고 나머지는 0으로 만듭니다.
이렇게 하면, 메모리 블록의 할당 상태를 나타내는 비트(가장 하위 비트)만 남게 됩니다.
HDRP, FTRP
/ 주어진 블록 포인터 bp에 대해서, 헤더와 푸터의 주소를 구한다 /
#define HDRP(bp) ((char)(bp) - WSIZE)
#define FTRP(bp) ((char)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)이거 왜 헤더는 WSIZE만큼만 앞으로 가는데
푸터는 DSIZE만큼 앞으로 감? 헤더랑 푸터랑 크기 똑같지 않음?
메모리 블록이 다음과 같은 구조를 갖는다고 가정합시다:
| 헤더 (4바이트) | 사용자 데이터 영역 (사용자 크기) | 푸터 (4바이트) |헤더와 푸터의 크기는 각각 WSIZE입니다.
bp는 사용자 데이터 영역의 시작 주소입니다.
-> 사용자 데이터 영역에서 데이터 블록 크기 더하면 해당 데이터 블록보다 WSIZE만큼 뒤로 가버리니까 푸터 시작 위치로 가려면 DSIZE를 빼야 하는듯
16진수
생각해보니까 int 뭐 이런 자료형 선언할 필요도 없이 ~0x7 이래버리면 0x만 보고 16진수인거 알아버리는 건가? 컴파일러가?
네, 맞습니다. ~0x7와 같은 표현을 사용하면 컴파일러는 이를 16진수 상수로 인식하고, 비트 연산을 수행합니다. 0x 접두사를 사용하면 컴파일러는 이를 16진수로 해석합니다.
매크로 안에서 말고도 그냥 함수 내에서 쓸 때도 저래도 되는거임?
네, 매크로뿐만 아니라 일반 함수 내에서도 0x7와 같은 16진수 리터럴과 비트 연산을 사용할 수 있습니다. 컴파일러는 이러한 표현을 동일하게 처리합니다. 함수 내에서도 16진수 상수를 사용하여 비트 연산을 수행할 수 있습니다.
📦 Malloc : mm_init
초기화와 동시에 조건 확인
void heap_listp;
if ((heap_listp = mem_sbrk(4 WSIZE)) == (void *)-1)이렇게 하면 초기화와 동시에 조건을 확인하는건가?
네, 맞습니다. 이 코드는 heap_listp 변수를 초기화하고, 초기화가 성공했는지를 동시에 확인합니다.
(void *)-1
if ((heap_listp = mem_sbrk(4 WSIZE)) == (void )-1)
여기서 (void *)-1 이게 무슨 뜻인지 모르겠음. 포인터에 -1이라는게 있나? 이걸 왜 검사함?
(void *)-1은 메모리 할당 함수에서 실패를 나타내기 위해 사용되는 특별한 값입니다. 포인터에 -1을 직접 저장하는 것은 일반적으로 유효하지 않지만, 이 경우는 특정한 실패 조건을 나타내기 위해 사용됩니다.
상세 설명
-
(void *)-1의 의미:(void *)-1은-1을void포인터 타입으로 캐스팅한 것입니다.- 이 값은 메모리 할당 함수에서 실패를 나타내기 위해 사용됩니다.
- 많은 메모리 할당 함수, 특히 시스템 호출과 비슷한 함수들은 실패 시 이 특별한 값을 반환합니다.
-
mem_sbrk함수:mem_sbrk함수는 힙 메모리를 확장하기 위해 사용됩니다.- 이 함수가 메모리 확장에 실패하면
(void *)-1을 반환합니다.
-
왜 검사하는가:
if ((heap_listp = mem_sbrk(4 * WSIZE)) == (void *)-1)는mem_sbrk함수가 실패했는지를 검사합니다.heap_listp가(void *)-1이면, 메모리 할당이 실패한 것입니다.- 실패 시 적절한 에러 처리를 하기 위해 이 값을 검사합니다.
왜 -1을 사용하는가
-1은 모든 비트를 1로 설정한 값입니다. 32비트 시스템에서는0xFFFFFFFF, 64비트 시스템에서는0xFFFFFFFFFFFFFFFF입니다.- 이 값은 일반적으로 유효한 메모리 주소와 충돌할 가능성이 적습니다. 따라서 메모리 할당 실패를 나타내는 데 사용하기 적합합니다.
-> 생각해보니 memlib.c에 있는 mem_sbrk 함수에서 오류 나면 -1 리턴했었음.
패딩, 프롤로그, 에필로그 블록
PUT(heap_listp, 0); // 정렬 패딩
PUT(heap_listp + (1 WSIZE), PACK(DSIZE, 1)); // 프롤로그 헤더
PUT(heap_listp + (2 WSIZE), PACK(DSIZE, 1)); // 프롤로그 푸터
PUT(heap_listp + (3 WSIZE), PACK(0, 1)); // 에필로그 헤더
heap_listp += (2 WSIZE);정렬 패딩은 뭔데 0을 넣어주는거고,
프롤로그 헤더랑 푸터는 뭐고,
애초에 에필로그 헤더는 뭔지도 모르겠음.책에선 mm_init 함수는 메모리 시스템에서 4워드를 가져와서 빈 가용 리스트를 만들 수 있도록 이들을 초기화한다. 라는데 빈 가용 리스트는 왜 만드는거임?
-> 답변 받긴 했는데 이런걸 왜 설명 안 하는건지 뭔가 이상해서 책 주고 gpt한테 어디에 나오는지 찾아달라고 했더니 책 823 페이지 맨 아래에 설명이 있었음.
"첫 번째 워드는 더블 워드 경계로 정렬된 미사용 패딩 워드이다. 패딩 다음에는 특별한 프롤로그 블록이 오며, 이것은 헤더와 풋터로만 구성된 8바이트 할당 블록이다. 프롤로그 블록은 초기화 과정에서 생성되며 절대 반환하지 않는다. 프롤로그 블록 다음에는 malloc 또는 free를 호출해서 생성된 0 또는 1개 이상의 일반 블록들이 온다.
힙은 항상 특별한 에필로그 블록으로 끝나며, 이것은 헤더만으로 구성된 크기가 0으로 할당된 블록이다. 프롤로그와 에필로그 블록들은 연결과정 동안에 가장자리 조건을 없애주기 위한 속임수다. 할당기는 한 개의 정적(static) 전역변수를 사용하며, 이것은 항상 프롤로그 블록을 가리킨다.(작은 최적화로 프롤로그 블록 대신에 다음 블록을 가리키게 할 수 있다)."
정렬 패딩을 추가하면 왜 첫 번째 실제 데이터 블록이 올바르게 정렬된 주소에서 시작하도록 보장되는건지 자세하게 설명해줘. 그냥 추가하면 이렇게 됨~ 이게 아니라 근본적인 원인이나 과정을 설명해달라고.
메모리 정렬과 그 필요성
메모리 정렬은 데이터가 메모리 내에서 특정한 경계(바이트 경계)에 위치하도록 하는 것입니다. 이는 CPU가 메모리에 접근할 때 성능을 최적화하고, 데이터 접근의 효율성을 높이기 위해 필요합니다. 예를 들어, 8바이트 정렬이 필요한 경우 데이터는 8의 배수인 주소에서 시작해야 합니다.
메모리 할당 초기화
mem_sbrk 함수는 요청된 크기만큼 힙을 확장하고, 새로운 힙 영역의 시작 주소를 반환합니다. 이 주소는 반드시 정렬된 상태일 필요는 없습니다.
초기 힙 설정 과정
초기 힙 설정 과정에서 프롤로그 블록과 에필로그 블록을 추가합니다. 이 과정에서 정렬 패딩을 추가하는 이유는 다음과 같습니다:
-
힙 확장:
void *heap_listp; if ((heap_listp = mem_sbrk(4 * WSIZE)) == (void *)-1) return -1;mem_sbrk는 4 * WSIZE(16바이트)를 힙에 추가하고, 그 시작 주소를 반환합니다.- 이 시작 주소는 반드시 8바이트 경계로 정렬되지 않을 수 있습니다.
-
정렬 패딩 추가:
PUT(heap_listp, 0); // 정렬 패딩- 정렬 패딩으로 4바이트를 사용하여 첫 번째 워드를 채웁니다.
- 이는 이후에 올바른 정렬을 보장하기 위해 추가하는 것입니다.
-
프롤로그 블록 추가:
PUT(heap_listp + (1 * WSIZE), PACK(DSIZE, 1)); // 프롤로그 헤더 PUT(heap_listp + (2 * WSIZE), PACK(DSIZE, 1)); // 프롤로그 푸터- 프롤로그 블록은 항상 존재하는 최소 크기의 할당된 블록입니다.
- 이는 메모리 할당 및 해제 알고리즘을 단순화합니다.
-
에필로그 블록 추가:
PUT(heap_listp + (3 * WSIZE), PACK(0, 1)); // 에필로그 헤더- 에필로그 블록은 힙의 끝을 표시하는 크기 0의 블록입니다.
-
힙 포인터 조정:
heap_listp += (2 * WSIZE);heap_listp를 프롤로그 블록의 끝으로 이동시킵니다.
정렬의 보장 과정
정렬 패딩을 추가하는 과정과 그 이유를 상세히 설명하겠습니다.
-
초기 주소가 8바이트 경계에 정렬되지 않은 경우:
- 예를 들어,
heap_listp의 초기 주소가 0x1004라고 가정합시다. 이는 4바이트 경계에는 정렬되어 있지만 8바이트 경계에는 정렬되지 않았습니다.
- 예를 들어,
-
정렬 패딩 추가:
PUT(heap_listp, 0);로 첫 번째 워드에 0을 넣어 4바이트를 채웁니다.- 이제
heap_listp는 0x1008가 됩니다. 이는 8바이트 경계에 정렬된 주소입니다.
-
프롤로그 블록 추가:
PUT(heap_listp + (1 * WSIZE), PACK(DSIZE, 1));로 프롤로그 헤더를 추가합니다.PUT(heap_listp + (2 * WSIZE), PACK(DSIZE, 1));로 프롤로그 푸터를 추가합니다.- 이로써 프롤로그 블록이 8바이트 경계에 정렬된 상태에서 추가됩니다.
-
에필로그 블록 추가:
PUT(heap_listp + (3 * WSIZE), PACK(0, 1));로 에필로그 블록을 추가합니다.- 이는 계속해서 8바이트 경계를 유지합니다.
시각적 설명
힙의 초기 레이아웃을 시각적으로 표현해보겠습니다:
[0x1000] 0 (정렬 패딩)
[0x1004] 프롤로그 헤더 (4바이트)
[0x1008] 프롤로그 푸터 (4바이트)
[0x100C] 에필로그 헤더 (4바이트)정렬 패딩을 추가하지 않으면 첫 번째 프롤로그 헤더가 4바이트 경계에 있지만, 프롤로그 푸터는 8바이트 경계에 있지 않습니다. 정렬 패딩을 추가함으로써 첫 번째 실제 데이터 블록이 올바르게 정렬된 주소(8바이트 경계)에서 시작할 수 있도록 보장합니다.
이건 그냥 네가 가정한거잖아 뭔 소리야 그럼 0x1000이었으면 어쩔건데
네, 맞습니다. 정렬 패딩을 추가하는 이유는 초기 힙 주소가 항상 정렬되지 않은 경우를 대비하기 위함입니다. 그러나 초기 주소가 이미 정렬된 상태라면 정렬 패딩이 필요하지 않을 수도 있습니다.
-> ㅇㅋ 구글링으로도 찾아보니까 이에 대한 명쾌한 해답 못 얻음 중요한 거 아니니 시간 낭비하지 말고 skip
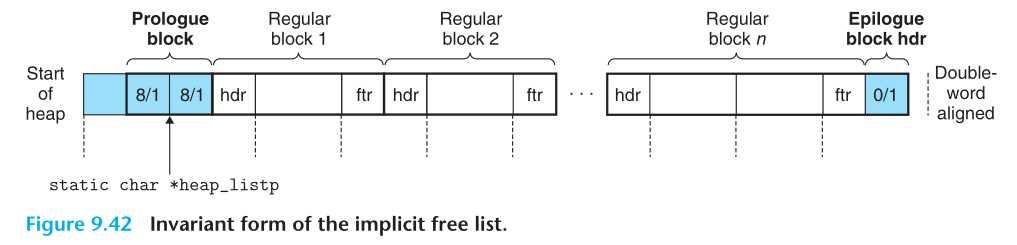
그냥 이것만 머릿속에 가져가자
-> 후에 동기에게 알게된 사실 : 페이로드의 시작점을 8바이트로 맞춰주기 위함이라고 함.
📦 Malloc : extend_heap
짝수 크기 워드 정렬
size = (words % 2) ? (words + 1) WSIZE : words WSIZE;
는 힙이 짝수 크기의 워드로 정렬되도록 보장합니다.라는게 8바이트 크기로 정렬되도록 보장한다라는 말이랑 똑같은거지?
네, 맞습니다. 짝수 크기의 워드로 할당함으로써 8바이트 크기로 정렬되도록 보장합니다. 이는 메모리 블록이 항상 8바이트 경계에서 시작되도록 하여, 8바이트 정렬 요구 사항을 충족시키는 것입니다.
📦 Malloc : mm_malloc
바이트 정렬을 위한 반올림
DSIZE *2 하면 되는거 아님? 왜 (DSIZE) + (DSIZE - 1) 임?
좋은 질문입니다. (DSIZE) + (DSIZE - 1)가 사용하는 이유는 8바이트(DSIZE)로 정렬된 크기를 얻기 위해 반올림을 수행하기 위함입니다. 아래에서 그 이유를 자세히 설명하겠습니다.
DSIZE * 2
DSIZE * 2는 8바이트 크기 두 배를 직접 계산하는 것입니다.- 이는 특정한 경우에는 작동하지만, 항상 8바이트로 정렬된 크기를 보장하지는 않습니다.
(DSIZE) + (DSIZE - 1)
(DSIZE) + (DSIZE - 1)는 반올림을 위한 수식입니다.- 이 방법을 사용하면 항상 8바이트 정렬된 크기를 보장할 수 있습니다.
반올림의 이유
반올림을 통해 메모리 블록이 8바이트 경계로 정렬되도록 하는 것이 목적입니다. 예를 들어, 20바이트 요청을 처리하는 과정을 설명해 보겠습니다.
계산 과정
-
요청된 크기(size)에 헤더(DSIZE) 추가:
- 예: 요청된 크기 20바이트 + 헤더 8바이트 = 28바이트
-
반올림을 위한 (DSIZE - 1) 추가:
- 예: 28바이트 + (8바이트 - 1) = 28 + 7 = 35바이트
DSIZE - 1을 추가하면 다음 8바이트 배수로 올림됩니다.
-
DSIZE로 나누기:
- 예: 35바이트 / 8바이트 = 4.375 → 정수 나눗셈이므로 4
-
DSIZE로 곱하기:
- 예: 4 * 8바이트 = 32바이트
반올림을 위한 (DSIZE - 1) 추가:
나 이게 무슨 의민지 하나도 모르겠는데? 더 쉽게 설명해줘
-> 답변 하긴 했는데 왜인지 또 이유를 안 알려줌. 귀류법으로 직접 생각해봄.
size에 DSIZE *2를 더하고 DSIZE를 나눈 뒤 DSIZE를 곱한다면?
-> ㅇㅋ 뭔지 모르겠음 패스. 아무튼 이렇게 하면 8바이트 정렬이 된다까지만 알고 다음으로 넘어감.
⚔️ 백준
📌 2468 안전영역
import sys
sys.setrecursionlimit(10**5)
N = int(input())
height = []
for i in range(N):
height.append(list(map(int,input().split())))
paper = [[0 for _ in range(N)] for _ in range(N)]
# 안전 영역 찾으면 일단 cnt +1
# 그 후 죄다 내린 비에 해당하는 숫자로 칠해버림
def bfs(i,j,x):
global N
if 0<=i<N and 0<=j<N:
if(height[i][j]>x and paper[i][j]!=x):
paper[i][j]=x
bfs(i-1,j,x)
bfs(i+1,j,x)
bfs(i,j-1,x)
bfs(i,j+1,x)
last = 0
for i in range(N):
for j in range(N):
last = max(last,height[i][j])
result=0
for x in range(last+1):
cnt=0
for i in range(N):
for j in range(N):
if(height[i][j]>x and paper[i][j]!=x):
cnt+=1
bfs(i,j,x)
result=max(cnt,result)
if result==0:
result=1
print(result)if result==0:
result=1
이 부분 예외처리를 안 해서
추가했었는데
if result==0:
result==1
맨 처음에 이딴식으로 추가함
=과 ==을 헷갈리는 실수 종종했던거 같은데 조심하자
