🎯 To-do List
⏳ Routine
✅ 알고리즘 스터디 | '2468 안전영역' 최적화
✅ 기술 면접 준비 | 프로세스와 쓰레드의 차이
🍪 Plan
☑️ c++ 공부하기
☑️ 기술 면접 준비 | (0812) 경쟁 조건, 데드락, (0813) 뮤텍스, 세마포어, 조건 변수, (?) 멀티프로세스와 멀티쓰레드의 차이
☑️ malloc 구현 후 | CS:APP 6장 읽기, 복습을 위해 이거 보기
🎤 기술 면접 준비
프로세스와 쓰레드의 차이
프로세스는 실행 중인 프로그램의 인스턴스를 의미합니다. 각 프로세스는 고유한 메모리 공간을 할당 받습니다. 한 프로세스는 다른 프로세스의 메모리에 직접 접근할 수 없기 때문에, 한 프로세스가 오류를 일으켜도 다른 프로세스는 안전하게 돌아갈 수 있습니다. 프로세스가 할당받는 메모리 공간에는 스택 영역, 힙 영역, 데이터 영역, 코드 영역이 있습니다.
쓰레드는 프로세스 내에서 실행되는 여러 흐름 중 하나입니다. 같은 프로세스에 있는 쓰레드들은 프로세스의 힙 영역, 데이터 영역, 코드 영역을 공유합니다. 이로 인해 쓰레드 간 컨텍스트 스위칭을 할 때 CPU 레지스터와 스택 포인터만 교체해주면 되므로 비용이 적게 듭니다. 또한 전역 변수나 힙 메모리를 통해 쓰레드 간의 데이터를 쉽게 공유할 수 있습니다. 하지만 동일한 메모리 공간을 공유하므로 경쟁 조건, 데드락 등 동기화 문제가 발생할 수 있습니다. 이를 방지하기 위해 뮤텍스, 세마포어, 조건 변수 등의 동기화 메커니즘을 사용합니다.
📝 배운 것들
🏷️ python 배열 pop
stack=[[1,2]]
i,j = stack.pop()이렇게 하면 i,j에 각각 1,2가 담긴다
🏷️ 2차원 리스트 최대값 구하기
max(map(max,height))last = max(map(max, height))는 파이썬의 내장 함수들을 조합하여 2차원 리스트 height에서 최대값을 구하는 코드입니다. 이 코드는 여러 단계를 통해 동작하며, 각 단계는 다음과 같습니다:
단계별 설명
-
map(max, height):map함수는 첫 번째 인자로 주어진 함수를 두 번째 인자로 주어진 시퀀스(여기서는 리스트height)의 각 요소에 적용합니다.max함수는 각 리스트에서 최대값을 찾습니다.- 따라서
map(max, height)는height리스트의 각 하위 리스트에서 최대값을 찾아 이를 새로운 시퀀스로 반환합니다.
예를 들어,
height가 다음과 같다고 가정합시다:height = [ [1, 2, 3], [4, 5, 6], [7, 8, 9] ]이 경우,
map(max, height)는 각 하위 리스트의 최대값을 반환하여[3, 6, 9]라는 리스트를 생성합니다. -
max([...]):- 앞 단계에서 생성된 시퀀스
[3, 6, 9]에 대해max함수를 호출합니다. - 이 함수는 리스트에서 가장 큰 값을 반환합니다.
- 결과적으로,
max([3, 6, 9])는9를 반환합니다.
- 앞 단계에서 생성된 시퀀스
📦 Malloc
step 1: place 함수

ㅋㅋ 딱 알았다 이건 무조건 된다 하면서 코드 짰는데
static void place(void *bp, size_t asize)
{
if (GET_SIZE(HDRP(bp)) - asize >= DSIZE)
{
PUT(bp + asize - DSIZE, PACK(asize, 1)); // 새 푸터에 정보 넣기
PUT(bp + asize - WSIZE, PACK(GET_SIZE(HDRP(bp)) - asize, 1)); // 새 헤더에 정보 넣기
PUT(FTRP(bp), PACK(GET_SIZE(HDRP(bp)) - asize, 1)); // 원래 푸터의 정보 갱신
PUT(HDRP(bp), PACK(asize, 1)); // 원래 헤더의 정보 갱신
}
else
{
PUT(HDRP(bp), PACK(GET_SIZE(HDRP(bp)), 1));
PUT(FTRP(bp), PACK(GET_SIZE(HDRP(bp)), 1));
}
}실행하자마자 바로 무한 반복(디버거 찍어보니 while문에서 막힘)이 일어났다.
이만큼 했으면 됐다 싶어서 답지 봄.
근데 인터넷에 있는 답지들 보니까
로직도 코드도 좀 더 깔끔하게 쓰여있긴 했는데 나랑 로직이 똑같음.
뭐지? 하고 이것저것 바꿔보다가 find_fit 바꿔보니까
➜ malloc-lab git:(main) ✗ ./mdriver
Team Name:ateam
Member 1 :Harry Bovik:bovik@cs.cmu.edu
Using default tracefiles in ./traces/
ERROR: mem_sbrk failed. Ran out of memory...
ERROR [trace 7, line 7124]: mm_malloc failed.
ERROR: mem_sbrk failed. Ran out of memory...
ERROR [trace 8, line 5124]: mm_malloc failed.
ERROR [trace 9, line 7]: mm_realloc did not preserve the data from old block
ERROR [trace 10, line 7]: mm_realloc did not preserve the data from old block
Terminated with 4 errors드디어 무한 반복이 끝나고 뭔가가 나옴.
내가 원래 작성했던 find_fit이
static void *find_fit(size_t asize)
{
void *bp = heap_listp;
// 힙의 데이터가 시작되는 영역부터 시작해서 에필로그 블록까지 탐색
while (GET_SIZE(FTRP(bp)) > 0)
{
// 헤더를 봤더니 할당되어 있지 않고, 충분히 크다면
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp))))
return bp; // 할당
bp = NEXT_BLKP(bp);
}
return NULL; // 맞는 블록이 없으면 NU**원래 코드에서 틀렸었던 부분**LL 반환
}이거고
인터넷에서 봤던, 제대로 돌아가는 코드는
static void *find_fit(size_t asize)
{
// 적절한 가용 블록을 검색한다.
// first fit 검색을 수행한다. -> 리스트 처음부터 탐색하여 가용블록 찾기
void *bp;
// 헤더의 사이즈가 0보다 크다. -> 에필로그까지 탐색한다.
for (bp = heap_listp; GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp))
{
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp))))
{
return bp;
}
}
return NULL;
}**원래 코드에서 틀렸었던 부분**이건데
눈을 씻고 들여다봐도 다른 점이 보이질 않음.
똑같은 걸 while문으로 구현한 거랑 for문으로 구현한 차이 아닌가?
라고 gpt한테 물어봤더니 답을 알려줌.
여기서 중요한 차이가 발생합니다. 에필로그 블록은 크기가 0인 특수한 블록이므로, HDRP를 사용하여 검사하는 것이 일반적입니다. FTRP(bp)는 블록의 끝 부분을 참조하기 때문에, 블록의 크기가 잘못 설정된 경우 무한 루프가 발생할 수 있습니다. HDRP(bp)를 사용하면 이러한 오류를 방지할 수 있습니다.
내 원래 코드도 HDRP(bp)로 바꿨더니 제대로 돌아감.
어처구니가 없긴 한데 책 보니까
힙은 항상 특별한 에필로그 블록으로 끝나며, 이것은 헤더만으로 구성된 크기가 0으로 할당된 블록이다.
라는 내용이 있긴 했음.
대충대충 읽으니까 이런 일이 생기는 것.
한 글자 한 글자 꼭꼭 씹어먹어야 한다.
그러고도
ERROR [trace 7, line 7124]: mm_malloc failed.
ERROR: mem_sbrk failed. Ran out of memory...
ERROR [trace 8, line 5124]: mm_malloc failed.이 부분이 있던게 거슬려서 다른 답지 코드를 넣어봤는데
static void place(void *bp, size_t asize)
{ // 들어갈 위치를 포인터로 받는다.(find fit에서 찾는 bp) 크기는 asize로 받음.
// 요청한 블록을 가용 블록의 시작 부분에 배치, 나머지 부분의 크기가 최소 블록크기와 같거나 큰 경우에만 분할하는 함수.
size_t csize = GET_SIZE(HDRP(bp)); // 현재 있는 블록의 사이즈.
if ((csize - asize) >= (2 * DSIZE))
{ // 현재 블록 사이즈안에서 asize를 넣어도 2*DSIZE(헤더와 푸터를 감안한 최소 사이즈)만큼 남냐? 남으면 다른 data를 넣을 수 있으니까.
PUT(HDRP(bp), PACK(asize, 1)); // 헤더위치에 asize만큼 넣고 1(alloc)로 상태변환. 원래 헤더 사이즈에서 지금 넣으려고 하는 사이즈(asize)로 갱신.(자르는 효과)
PUT(FTRP(bp), PACK(asize, 1)); // 푸터 위치도 변경.
bp = NEXT_BLKP(bp); // regular block만큼 하나 이동해서 bp 위치 갱신.
PUT(HDRP(bp), PACK(csize - asize, 0)); // 나머지 블록은(csize-asize) 다 가용하다(0)하다라는걸 다음 헤더에 표시.
PUT(FTRP(bp), PACK(csize - asize, 0)); // 푸터에도 표시.
}
else
{
PUT(HDRP(bp), PACK(csize, 1)); // 위의 조건이 아니면 asize만 csize에 들어갈 수 있으니까 내가 다 먹는다.
PUT(FTRP(bp), PACK(csize, 1));
}
}Team Name:ateam
Member 1 :Harry Bovik:bovik@cs.cmu.edu
Using default tracefiles in ./traces/
ERROR [trace 9, line 7]: mm_realloc did not preserve the data from old block
ERROR [trace 10, line 7]: mm_realloc did not preserve the data from old block
Terminated with 2 errors오류가 사라짐.
답지의 코드와 로직이 깔끔하다고 생각했던 부분
1. 원래 블록 사이즈를 csize로 묶어놓음. (난 size_t를 못 떠올려내서 사이즈를 어떻게 선언하지? 이러고 선언을 안 해버림)
2. 앞쪽 블록의 헤더 갱신 -> 푸터 갱신 -> 뒤쪽 블록 넘어감 -> 헤더 갱신 -> 푸터 갱신 이렇게 직관적으로 코드를 짬.
static void place(void *bp, size_t asize)
{
if (GET_SIZE(HDRP(bp)) - asize >= (2 * DSIZE))
{
PUT(bp + asize - DSIZE, PACK(asize, 1)); // 새 푸터에 정보 넣기
PUT(bp + asize - WSIZE, PACK(GET_SIZE(HDRP(bp)) - asize, 1)); // 새 헤더에 정보 넣기
PUT(FTRP(bp), PACK(GET_SIZE(HDRP(bp)) - asize, 1)); // 원래 푸터의 정보 갱신
PUT(HDRP(bp), PACK(asize, 1)); // 원래 헤더의 정보 갱신
}
else
{
PUT(HDRP(bp), PACK(GET_SIZE(HDRP(bp)), 1));
PUT(FTRP(bp), PACK(GET_SIZE(HDRP(bp)), 1));
}
}틀렸었던 부분
새 헤더랑 원래 푸터에는 0을 넣어야 됐음. 가용 블록이니까.
그냥 그거였음...
step 2: realloc 함수
ERROR [trace 9, line 7]: mm_realloc did not preserve the data from old block
ERROR [trace 10, line 7]: mm_realloc did not preserve the data from old block
Terminated with 2 errorsrealloc이 안되는데 내 코드 문제일 것으로 추측함.
검증을 위해 답지 코드를 써봄.
void *mm_realloc(void *ptr, size_t size)
{
void *oldptr = ptr; // 이전 포인터
void *newptr; // 새로 메모리 할당할포인터
size_t originsize = GET_SIZE(HDRP(oldptr)); // 원본 사이즈
size_t newsize = size + DSIZE; // 새 사이즈
// size 가 더 작은 경우
if (newsize <= originsize) {
return oldptr;
} else {
size_t addSize = originsize + GET_SIZE(HDRP(NEXT_BLKP(oldptr))); // 추가 사이즈 -> 헤더 포함 사이즈
if (!GET_ALLOC(HDRP(NEXT_BLKP(oldptr))) && (newsize <= addSize)){ // 가용 블록이고 사이즈 충분
PUT(HDRP(oldptr), PACK(addSize, 1)); // 새로운 헤더
PUT(FTRP(oldptr), PACK(addSize, 1)); // 새로운 푸터
return oldptr;
} else {
newptr = mm_malloc(newsize);
if (newptr == NULL)
return NULL;
memmove(newptr, oldptr, newsize); // memcpy 사용 시, memcpy-param-overlap 발생
mm_free(oldptr);
return newptr;
}
}
}Using default tracefiles in ./traces/
Perf index = 48 (util) + 7 (thru) = 55/100근데 되면 안되는데 됨. 그럼 도대체 뭐가 문제인거지?
realloc은 원래 작성되어있던 함수인데?
void *mm_realloc(void *bp, size_t size){
if(size <= 0){
mm_free(bp);
return 0;
}
if(bp == NULL){
return mm_malloc(size);
}
void *newp = mm_malloc(size);
if(newp == NULL){
return 0;
}
size_t oldsize = GET_SIZE(HDRP(bp));
if(size < oldsize){
oldsize = size;
}
memcpy(newp, bp, oldsize);
mm_free(bp);
return newp;
}Perf index = 44 (util) + 6 (thru) = 51/100오 이건 또 다른 코드인데 이것도 되긴 함
근데 내가 지금 뭐 하고 있는지 모르겠음
답지 소믈리에 하지 말고 원인을 파악해보자.
- 원시적으로 구현돼있던 할당기를 묵시적 가용 리스트를 이용한 할당기로 바꿔주기 위해
find_fit함수와place함수를 구현했다. - realloc 함수를 바꿔보니 realloc 오류가 없어진 것으로 보아, 기존의 realloc 함수는 원시적 할당기에 적합한 realloc일 것임.
- 이에 대한 근거가 필요함. 또한, realloc을 직접 구현해볼 수 있어야 함.
따라서 원시적 할당기를 위한 realloc은 어째서 mm_realloc did not preserve the data from old block라는 오류를 출력하는지 논증해야함.
- 복사를 제대로 못했다는거 같은데 새로운 malloc 함수와 함께라면 그럴 가능성이 생기는지 확인을 해봐야 함.
- 원시적 malloc 함수는 기본적으로 할당을 못하는 상황이 생길 수가 없음. 필요할 때마다 그만큼 힙을 늘려버리기 때문임.
- 따라서 새로운 malloc 함수가 할당을 하지 못하는 상황이 생겼다는 말일 수 있음. 하지만 다른 realloc 함수와 함께할 때는 정상적으로 할당을 했던 것으로 보아, 기존 realloc이 다소 naive하게 작성되었던 부분이 있을 것으로 추정됨.
- 근데 원본 파일을 다시 확인해보니 점수가 뜨는게 아니라 오류가 뜸. 그럼 점수가 떴던 기억은 뭐지? 분명 원시적 malloc으로도 뭐가 되긴 했었던 것 같은데?
make 후 ./mdriver 를 실행하면 out of memory 에러 발생
책에 있는 implicit list 방식대로 malloc을 구현해서 해당 에러를 없애기
- 컴퍼스에 이렇게 적혀있었던 것을 보니 기억조작이었는듯? 결국 그냥 realloc 자체가 견본품이었는듯. 그런데 어째서? 어디가 틀렸길래?
- 그리고 이전 정글 기수들은 도대체 어디서 realloc을 보고 이런걸 만들어낸거임?
일단 여기까지 해두고 내일 다시 해야될듯.
⚔️ 백준
📌 2468 안전영역
last = 0
# for i in range(N):
# for j in range(N):
# last = max(last,height[i][j])
start = min(map(min, height))
last = max(map(max,height))높이의 min과 max를 확인하고 내릴 비 양의 범위의 시작을 min, 끝을 max로 했다.
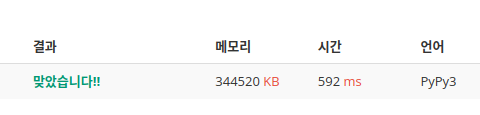
더 느려졌다.
height_set = set()
for i in range(N):
for j in range(N):
height_set.add(height[i][j])내릴 비 양의 범위를 전부 순회하는게 아니라 height에 들어있는 숫자들만 테스트해보는 것으로 바꾸었다.
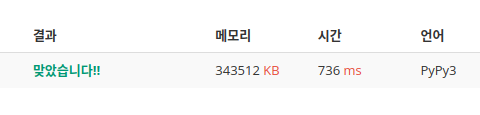
더 느려졌다.
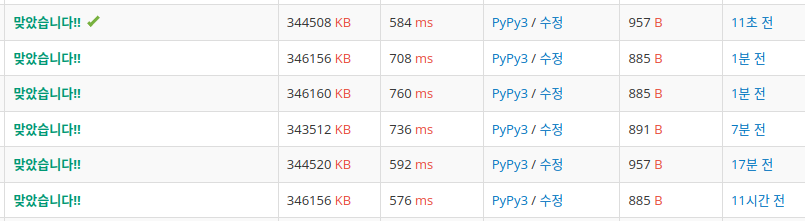
뭔가 이상해서 어제 코드도 다시 돌려봤더니 그냥 백준 서버가 느려진 탓이었다.
set 쓰는건 느린게 맞는데 min을 추가로 확인하고 순회할 거 줄이면 빨라지긴 하는듯.
그래도 stack 써서 while문 돌리는 것보단 3배 정도 느렸다. 재귀가 원래 좀 느린건가?
def bfs(i,j,x):
global N
stack=[[i,j]]
while stack:
i,j = stack.pop()
if 0<=i<N and 0<=j<N:
if(height[i][j]>x and paper[i][j]!=x):
paper[i][j]=x
stack.append([i-1,j])
stack.append([i+1,j])
stack.append([i,j-1])
stack.append([i,j+1])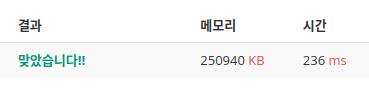
재귀 대신 반복문 썼더니 빨라지긴 했는데 다른 사람들 거에 비해서 메모리를 2배 더 사용하고 있었음.
setrecursionlimit(10**5)를 주석처리했더니
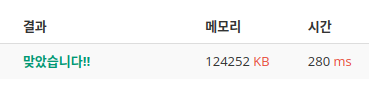
메모리가 줄어들음.
visited = [[False]*N for _ in range(N)]
if(height[i][j]>x and visited[i][j]==False):매번 visited 배열을 새로 선언하면 좀 느릴 것 같아서 paper 배열을 재활용했던 거였는데
visited를 사용하는 다른 사람들 코드가 살짝 더 빨라서 적용해봤더니
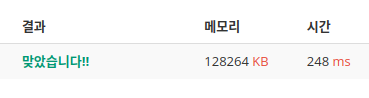
약간 더 빨라짐 (백준 서버 때문에 생긴 오차일수도?)
