📚 Journal
gpt를 어디까지 써야될지 모르겠음.
일단 최대한 내가 할 수 있는데까지 해보려고 하는데,
계산기 나왔는데 주판 배우려고 하는게 아닐지 모르겠음.
언덕 올라오는데 코치님 마주침.
하루종일 걸려도 답이 안 보이길래
gpt한테 물어보게된다고 했더니
책이나 인터넷 같은 다른 곳에서 교차 검증하는 방법을 이야기하심.
그 말 듣고 OSTEP 찾아보니까 60p에 관련 내용이 있긴 했음.
알고 찾아서 빨리 찾은거지 아니었으면 그냥 지나쳤을 것 같긴 함.
책에서 헤매는 과정에서 배우게 되는 것들이 있어서 그런건가?

슬랙에 추가적으로 답변도 해주셨다.
- 답이 맞는지 교차검증
- 교차검증하면서 답을 찾아가는 과정을 배우기
이 정도로 요약하면 될듯
🖥️ PintOS
🔷 Priority Scheduling
디버깅 관련 메모
cd /root/pintos-kaist
source ./activate
cd /root/pintos-kaist/threads
make clean
make
cd /root/pintos-kaist/threads/build
pintos --gdb -- -q run priority-change
(이 줄 전까지 복사해야 마지막 엔터까지 쳐짐)
pintos run priority-change
timeout 10 pintos --gdb -- -q run alarm-multiple
timeout 10 pintos -- run priority-preempt
전부 테스트 (threads 들어가서)
make check
priority-change
priority-preempt
1. 간단한 선점 스케줄링 구현
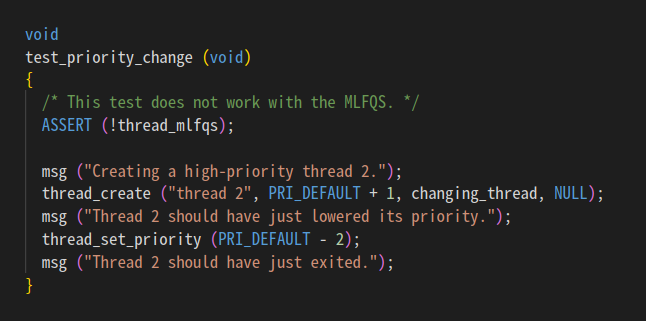
쓰레드 만든 다음에 우선순위 바꾸면 다른 쓰레드가 선점해야되는 것 같음
어제 깃북에서 타임 인터럽트 핸들러에서 선점을 처리한다는 내용을 봐서
일단 여기에서 드르렁 리스트랑 똑같은 로직으로 간단한 선점을 해보려고 했는데
in thread_yield(): assertion `!intr_context()' failed.라는 이상한 오류가 생김.
/* Returns true during processing of an external interrupt
and false at all other times. */
bool
intr_context (void) {
return in_external_intr;
}이것 때문에 일어났다고 하는데... gpt를 써야될지 안 써야될지 진짜 모르겠음.
당연히 이거 관련해서 물어보면 답이야 알려주겠지만
그렇게 하면 이 과정의 의미가 있나? 싶음.
그렇다고 이런걸로 시간 잡아먹고 있는것도 이상하고...
일단 이건 물어보자. 힌트가 너무 없다.

바로 정답을 주긴 했다.
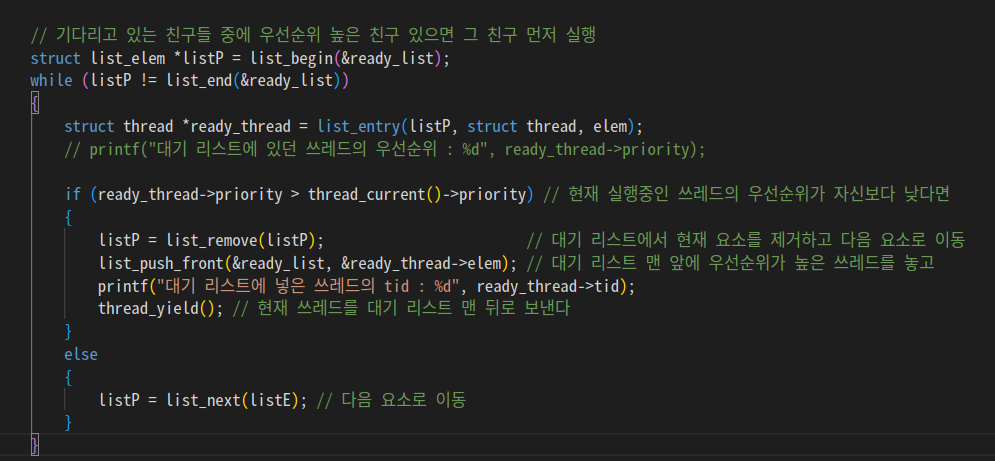
/* Timer interrupt handler. */
static void
timer_interrupt(struct intr_frame *args UNUSED)
{
ticks++;
thread_tick();
// 드르렁 중인 친구들 수면 시간 체크하고 깨어날 시간이면 깨운다
struct list_elem *listE = list_begin(&sleeping_list);
while (listE != list_end(&sleeping_list))
{
struct thread *sleeping_thread = list_entry(listE, struct thread, elem);
// printf("Current timer_ticks: %lld\n", timer_ticks());
if (sleeping_thread->sleep_ticks <= timer_ticks()) // 깨어날 시간이 되었을 때
{
listE = list_remove(listE); // 현재 요소를 제거하고 다음 요소로 이동
thread_unblock(sleeping_thread); // 프로세스 깨운다
}
else
{
listE = list_next(listE); // 다음 요소로 이동
}
}
// 기다리고 있는 친구들 중에 우선순위 높은 친구 있으면 그 친구 먼저 실행
struct list_elem *listP = list_begin(&ready_list);
while (listP != list_end(&ready_list))
{
struct thread *ready_thread = list_entry(listP, struct thread, elem);
// printf("대기 리스트에 있던 쓰레드의 우선순위 : %d", ready_thread->priority);
if (ready_thread->priority > thread_current()->priority) // 현재 실행중인 쓰레드의 우선순위가 자신보다 낮다면
{
listP = list_remove(listP); // 대기 리스트에서 현재 요소를 제거하고 다음 요소로 이동
list_push_front(&ready_list, &ready_thread->elem); // 대기 리스트 맨 앞에 우선순위가 높은 쓰레드를 놓고
// printf("대기 리스트에 넣은 쓰레드의 tid : %d", ready_thread->tid);
intr_yield_on_return(); // 현재 쓰레드를 대기 리스트 맨 뒤로 보낸다
}
else
{
listP = list_next(listE); // 다음 요소로 이동
}
}
}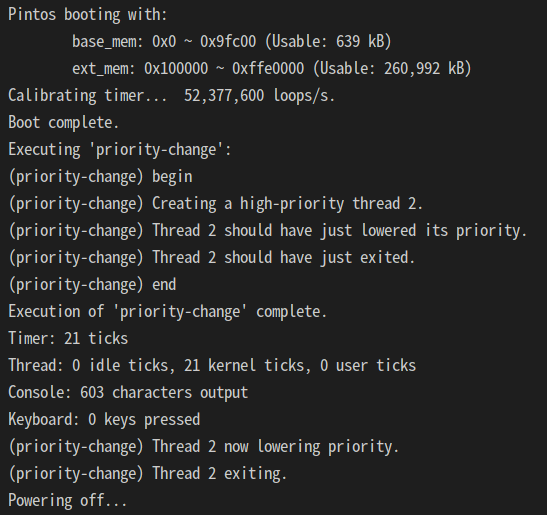
이것까진 된듯.
노화 현상도 구현해보려고 했는데 딱히 구현이 어려운 것도 아니고,
언제 나이를 먹을 건지에 대한 임의의 숫자를 구하는게 어려운 거고,
그것도 테스트에 따라서 억지로 맞춰야 하는건데 그게 의미가 있는건 아닌듯?
라운드 로빈으로 넘어가자.
라고 생각했는데
test.c에 있는 것들 필요 없는거 주석 처리하면 원하는 것만 테스트 빠르게 한꺼번에 가능
이라는 정보를 얻고 다시 돌려보니
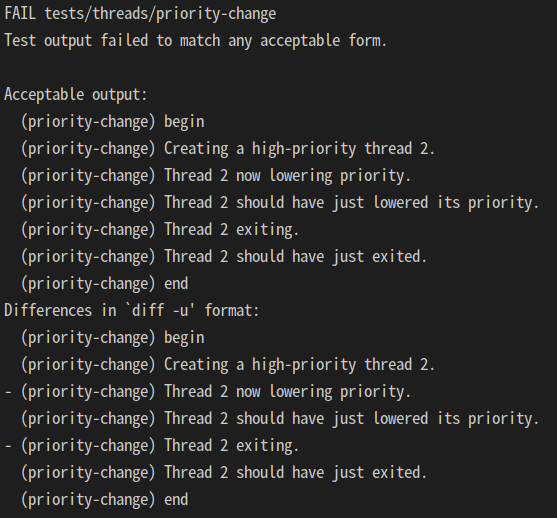
안되는 거였다.
타이머 인터럽트 핸들러에서 한 번 tick 돌아갈때마다 검사하는게 아니라
우선순위를 바꾸면 현재 선점 중인 것도 바로 바뀌어야 하는 건가??
void reschedule_by_priority(void)
{
// 기다리고 있는 친구들 중에 우선순위 높은 친구 있으면 그 친구 먼저 실행
struct list_elem *listP = list_begin(&ready_list);
while (listP != list_end(&ready_list))
{
struct thread *ready_thread = list_entry(listP, struct thread, elem);
if (ready_thread->priority > thread_current()->priority) // 현재 실행중인 쓰레드의 우선순위가 자신보다 낮다면
{
listP = list_remove(listP); // 대기 리스트에서 현재 요소를 제거하고 다음 요소로 이동
list_push_front(&ready_list, &ready_thread->elem); // 대기 리스트 맨 앞에 우선순위가 높은 쓰레드를 놓고
thread_yield(); // 현재 쓰레드를 대기 리스트 맨 뒤로 보낸다
}
else
{
listP = list_next(listP); // 다음 요소로 이동
}
}
}이거 timer.c가 아니라 thread.c에 선언한 뒤에
thread_create()에서 unblock() 뒤랑
/* Sets the current thread's priority to NEW_PRIORITY. */
void thread_set_priority(int new_priority)
{
thread_current()->priority = new_priority;
reschedule_by_priority();
}thread_set_priority()에 이런 식으로 넣었더니

이거 하나는 통과함. 대충 된듯?
근데 이대로면 컨텍스트 스위칭 비용 때문에 비효율적일듯.
그리고 priority-preempt 통과시켜보려고 했는데
내 구현 방식에 치명적 문제 있음.
무작정 큰 거 발견할때마다 yield해버리면
정렬도 안되고 효율도 안 좋음.
이것 때문에 통과 못 한듯.
정렬시키면서 이상한거 발견하면 나중에 최대 priority 가진거 올려보내야 할듯.
어차피 이거 안 고치면 다음 것도 다 망가지는거라
이것부터 해결해야될듯
도대체 less는 뭐고 aux는 뭔가?
왜 list_sort (struct list list, list_less_func less, void *aux)에 있는
list_less_func는 header에만 정의가 되어 있는거고,
코드 한 줄도 없이 정의만 돼있는 주제에 설명은 왜 비교하는거라고 쓰여있는거고,
aux는 도대체? 뭔지?
왜 find all references로 코드를 뒤져봐도 용례가 단 하나도 안 나오는건지?
도저히 모르겠어서 gpt 도움.
list_less_func?
list_less_func은 "비교 함수"가 어떤 모양(형태)을 가져야 하는지를 정의하는 약속입니다. 이 약속은 C 언어에서 함수 포인터라고 불립니다.
list_less_func: 두 개의 리스트 요소를 비교하는 함수가 어떤 모양이어야 하는지 약속하는 정의입니다.
함수 포인터: 특정 조건에 따라 다른 비교 함수를 사용할 수 있게 해줍니다.
왜 필요한가요?: 리스트에서 요소들을 특정 기준으로 정렬하거나 비교할 때, 다양한 방법으로 비교할 수 있게 해줍니다.
포인터가 안 붙었는데 이게 함수 포인터라고?
typedef bool list_less_func (...)는 함수 자체의 타입을 정의한 것입니다.
실제로 함수 포인터를 사용할 때는 list_less_func *와 같이 사용합니다.
이렇게 함으로써 여러 곳에서 동일한 함수 타입을 일관되게 사용할 수 있고, 코드의 가독성과 유지보수성이 향상됩니다.
aux?
aux는 auxiliary의 줄임말로, 보조 데이터 또는 추가적인 정보를 의미합니다. Pintos의 리스트 관련 함수에서 aux는 비교 함수가 실행될 때 추가적인 맥락이나 데이터를 전달하기 위해 사용됩니다.
예를 들어, 리스트 요소들이 단순한 정수 값을 가지고 있고, 이 값을 기준으로 비교하는 함수가 있다고 가정해 봅시다. 그런데, 비교할 때 단순히 값을 비교하는 것이 아니라, 어떤 기준 값을 기준으로 비교해야 한다고 합시다. 이 기준 값은 aux를 통해 전달할 수 있습니다.
물어보기 잘함. 이게 함수 포인터인 줄 내가 어떻게 알았겠음???
https://www.youtube.com/watch?v=1S4gGCx0syc
그래서 함수 포인터에 대해 알아봤는데 대가리 빠개질 것 같음.
어떤 함수에 상황마다 다른 함수가 필요하면
인수에 함수 포인터 넣어서
상황마다 다른 함수 쓸 수 있게 하는거인듯.
void reschedule_by_priority(void)
{
// ready_list에서 기다리고 있는 친구들을 정렬한다
// 만약 ready_list 중에 최고 priority가 현재 thread의 priority보다 높다면 thread_yield를 한다.
// thread_yield에서 그냥 push_back하는게 아니라 list_insert_ordered를 한다
// 최적화하려면 직접 정렬도 구현하고 정렬 와중에 최댓값을 저장해놓으면 될듯
list_sort(&ready_list, &for_descending_priority, NULL); // 정렬
// // 정렬 후 리스트의 우선순위를 출력하여 확인
// printf("Ready list after sorting by descending priority:\n");
// struct list_elem *e;
// for (e = list_begin(&ready_list); e != list_end(&ready_list); e = list_next(e))
// {
// struct thread *t = list_entry(e, struct thread, elem);
// printf("Thread name: %s, Priority: %d\n\n", t->name, t->priority);
// }
// printf("current_thread name: %d, Priority: %d\n\n", thread_current()->name, thread_current()->priority);
struct list_elem *maxE = list_max(&ready_list, &for_descending_priority, NULL); // 최대 priority 가진 대기 리스트 원소
struct thread *maxE_thread = list_entry(maxE, struct thread, elem); // 최대 priority 가진 쓰레드
int maxE_priority = maxE_thread->priority; // 대기 리스트에서 최대 priority
// printf("maxE_priority : %d\n\n", maxE_priority);
if (thread_current()->priority < maxE_priority) // 대기 최대 priority가 현재 priority보다 크다면
{
list_remove(maxE); // 대기 리스트에서 제거하고
thread_yield(); // 현재 쓰레드 꺼버리기 (thread_yield도 수정함)
}
}여기까지 해보고 도저히 모르겠어서 gpt한테 물어봄

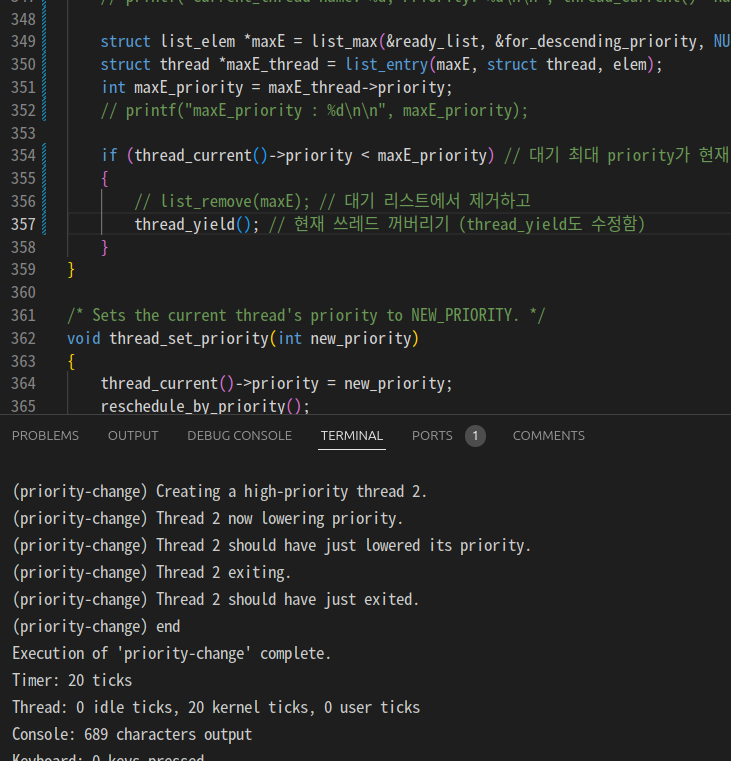
하라는 대로 list_remove() 지워봤더니 됐음.
ready_list에서 지울 필요 없이 알아서 끝나면 지워지니까 그런듯?
ready_list는 순서만 잘 정렬해주고 현재 프로세스 yield 때려버리면
알아서 ready_list에서 꺼내 쓴다. 오히려 지워버리면 못 찾음.
(yield 바꾸라는 것과 maxE_priority는 개소리)
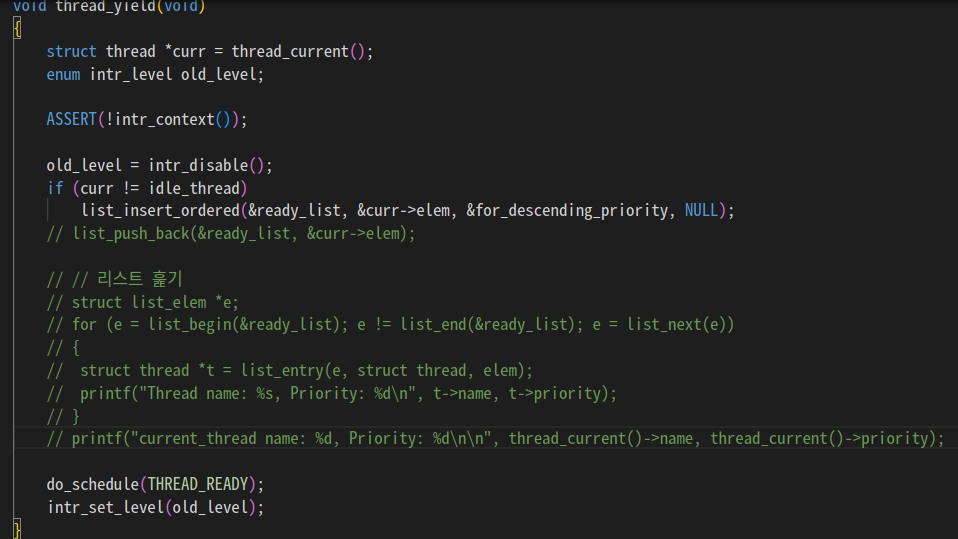
근데 아무리 생각해도 priority-preempt도 통과를 해야 되는거 같은데
통과를 안 하길래 yield 수정하려고 봤더니
list_insert_ordered를 효율화가 아니라 무조건 넣어야 되는거였음.
원래 넣으려고 했는데 못 넣었던 건 priority-change도 통과를 못해서였는데
뭔가 이상해서 printf로 디버깅 찍어봤더니
내가 의도한것과 다르게 작동함 (우선순위에 대해 오름차순으로 정렬돼있었음)
// 우선순위 내림차순으로 정렬하기 위한 함수
bool for_descending_priority(const struct list_elem *a, const struct list_elem *b, void *aux)
{
int ap = list_entry(a, struct thread, elem)->priority;
int bp = list_entry(b, struct thread, elem)->priority;
return ap > bp;
}그래서 이 함수(각종 리스트 정렬에 쓰인다) return 부등호 방향 바꿨더니
주석 처리 안 한 테스트들 전부 통과함
나이스나이스
(+저번엔 통과 안됐던 alarm-priority도 통과되는것도 확인함)
라운드 로빈은 일단 나중에 하고,
donation을 먼저 해보자.
정리
0. for_descending_priority 구현
// 우선순위 내림차순으로 정렬하기 위한 함수
bool for_descending_priority(const struct list_elem *a, const struct list_elem *b, void *aux)
{
int ap = list_entry(a, struct thread, elem)->priority;
int bp = list_entry(b, struct thread, elem)->priority;
return ap > bp;
}리스트 정렬 및 탐색에 쓰이는 함수.
list.c의 함수 중 함수 포인터가 필요한 자리에 넣으면 된다.
1. reschedule_by_priority() 구현
void reschedule_by_priority(void)
{
// ready_list에서 기다리고 있는 친구들을 정렬한다
// 만약 ready_list 중에 최고 priority가 현재 thread의 priority보다 높다면 thread_yield를 한다.
// thread_yield에서 그냥 push_back하는게 아니라 list_insert_ordered를 한다
// 최적화하려면 직접 정렬도 구현하고 정렬 와중에 최댓값을 저장해놓으면 될듯
list_sort(&ready_list, &for_descending_priority, NULL); // 정렬
struct list_elem *maxE = list_max(&ready_list, &for_descending_priority, NULL); // 최대 priority 가진 대기 리스트 원소
struct thread *maxE_thread = list_entry(maxE, struct thread, elem); // 최대 priority 가진 쓰레드
int maxE_priority = maxE_thread->priority; // 대기 리스트에서 최대 priority
if (thread_current()->priority < maxE_priority) // 대기 최대 priority가 현재 priority보다 크다면
{
thread_yield(); // 현재 쓰레드 꺼버리기 (thread_yield도 수정함)
}
}정렬 후 대기 리스트 중 최고 priority를
현재 쓰레드의 priority와 비교하여
priority가 높은 쪽을 (마저) 실행
2. thread_set_priority()와 thread_create()에 reschedule_by_priority() 삽입
/* Sets the current thread's priority to NEW_PRIORITY. */
void thread_set_priority(int new_priority)
{
thread_current()->priority = new_priority;
reschedule_by_priority();
}여기랑
tid_t thread_create(const char *name, int priority,
thread_func *function, void *aux)
{
struct thread *t;
tid_t tid;
ASSERT(function != NULL);
/* Allocate thread. */
t = palloc_get_page(PAL_ZERO);
if (t == NULL)
return TID_ERROR;
/* Initialize thread. */
init_thread(t, name, priority);
tid = t->tid = allocate_tid();
/* Call the kernel_thread if it scheduled.
* Note) rdi is 1st argument, and rsi is 2nd argument. */
t->tf.rip = (uintptr_t)kernel_thread;
t->tf.R.rdi = (uint64_t)function;
t->tf.R.rsi = (uint64_t)aux;
t->tf.ds = SEL_KDSEG;
t->tf.es = SEL_KDSEG;
t->tf.ss = SEL_KDSEG;
t->tf.cs = SEL_KCSEG;
t->tf.eflags = FLAG_IF;
/* Add to run queue. */
thread_unblock(t);
reschedule_by_priority();
return tid;
}여기에 넣었다.
테스트 파일 보고 흐름 따라가면서 필요해보이는 곳에 끼워넣었음.
3. thread_yield() 수정
/* Yields the CPU. The current thread is not put to sleep and
may be scheduled again immediately at the scheduler's whim. */
void thread_yield(void)
{
struct thread *curr = thread_current();
enum intr_level old_level;
ASSERT(!intr_context());
old_level = intr_disable();
if (curr != idle_thread)
list_insert_ordered(&ready_list, &curr->elem, &for_descending_priority, NULL);
do_schedule(THREAD_READY);
intr_set_level(old_level);
}기존처럼 push_back으로 하면 매번 정렬해서 다시 갖고 와야 하니
효율도 안 좋을 거고
priority가 큰 놈이라 다시 앞으로 돌아와서 바로 실행돼야할 때
reschedule_by_priority()가 커버를 못 해주는 부분이 생겼었음.
push_back()을 list_insert_ordered()로 대체하여 해결.
2. 우선순위 기부 구현
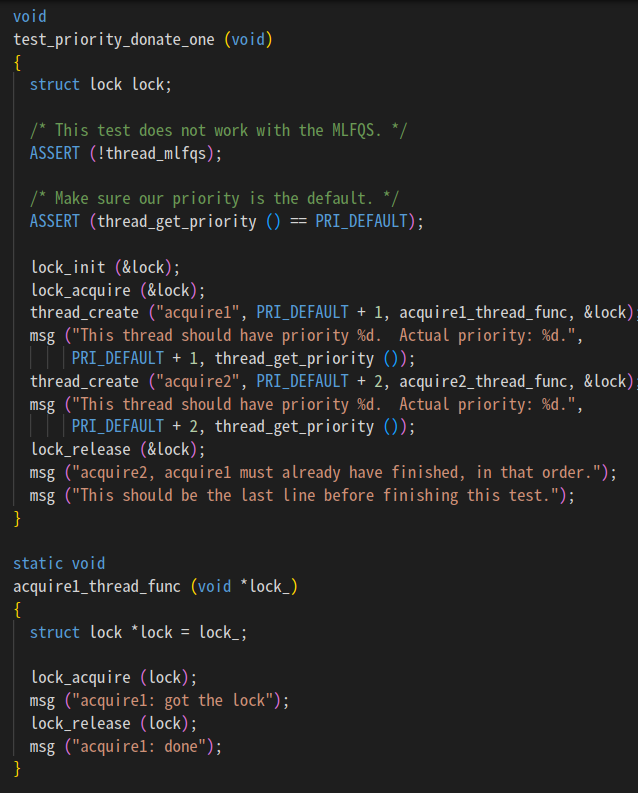
문답무용 테스트 파일 확인해봄
/* Lock. */
struct lock {
struct thread *holder; /* Thread holding lock (for debugging). */
struct semaphore semaphore; /* Binary semaphore controlling access. */
};락에는 락 갖고 있는 놈이랑 세마포어 저장
/* A counting semaphore. */
struct semaphore {
unsigned value; /* Current value. */
struct list waiters; /* List of waiting threads. */
};세마포어에는 값이랑 대기 중인 쓰레드 저장
msg ("acquire2, acquire1 must already have finished, in that order.");이 부분이 제일 중요한듯.
근데 뭔 소린질 모르겠어서
https://www.youtube.com/watch?v=gTkvX2Awj6g
이거 봄
정리
race condition(경쟁 조건)
: 여러 프로세스/스레드가 동시에 같은 데이터를 조작할 때 타이밍이나 접근 순서에 따라 결과가 달라질 수 있는 상황
동기화(synchronization)
: 여러 프로세스/스레드를 동시에 실행해도 공유 데이터의 일관성을 유지하는 것
critical section(임계 영역)
: 공유 데이터의 일관성을 보장하기 위해 하나의 프로세스/스레드만 진입해서 실행(mutual exclusion) 가능한 영역
TestAndSet은 CPU atomic 명령어
- 실행 중간에 간섭받거나 중단되지 않는다
- 같은 메모리 영역에 대해 동시에 실행되지 않는다
스핀락(spinlock)
: 락을 가질 수 있을 때까지 반복해서 시도. 기다리는 동안 CPU를 낭비한다.
뮤텍스(mutex)
: 락을 가질 수 있을 때까지 휴식
뮤텍스는 스핀락보다 항상 좋은가?
: 멀티 코어 환경이고, critical section에서의 작업이 컨텍스트 스위칭보다 더 빨리 끝난다면 스핀락이 뮤텍스보다 더 이점이 있다.
semaphore(세마포)
: signal mechanism을 가진, 하나 이상의 프로세스/스레드가 critical section에 접근 가능하도록 하는 장치. 쓰레드들의 실행 순서를 정해줄 때 사용할 수 있다.
binary semaphore, 이진 세마포 : value가 1
counting semaphore : value가 1보다 큼
뮤텍스와 이진(binary) 세마포의 차이점
- 뮤텍스는 락을 가진 자만 락을 해제할 수 있지만 세마포는 그렇지 않다
- 뮤텍스는 priority inheritance 속성을 갖지만 세마포는 갖고 있지 않다
상호 배제만 필요하면 뮤텍스를, 작업 간의 실행 순서 동기화가 필요하다면 세마포 사용
📖 OSTEP
제6장 제한적 직접 실행 원리 (Limited Direct Execution)
직접 실행 시키면 얘가 이상한거 못하게 못하고 다른 프로세스로 전환도 못 시킴
이상한거 못하게 하기
사용자 모드, 커널 모드로 나누고 프로세스한테 시스템 콜로 커널 모드 기능 접근
시스템 콜 실행하기 위해 trap 특수 명령어 실행
이 명령어는 커널 안으로 분기하는 동시에 권한 수준을 커널 모드로 상향 조정.
커널 모드로 진입하면 운영체제는 모든 명령어를 실행 가능.
완료되면 운영체제는 reutrn-from-trap 특수 명령어를 호출.
커널은 부팅 시에 트랩 테이블(trap table)을 만들고 이를 이용하여 시스템을 통제.
운영체제는 특정 명령어를 사용하여 하드웨어에게 트랩 핸들러(trap handler)의 위치를 알려줌.
시스템 콜 어디 있는지 안 숨기면 보안 위협
프로세스 간 전환
프로세스가 실행 중이라는 것은 운영체제는 실행 중이지 않다는 것을 의미.
운영체제는 어떻게 CPU를 다시 획득하여 프로세스를 획득할 수 있는가?
1. 협조 방식 : 시스템 콜 호출시 까지 대기
프로세스들이 각자 시간 지나면 yield이라는 시스템 콜로 운영체제한테 제어 넘겨줌
프로그램이 불법적 연산 하면 운영체제한테 제어 넘어감(트랩 일어남)
프로세스가 시스템 콜 호출 안하면 재부팅이 유일한 답.
2. 비협조 방식 : 운영체제가 제어권 확보
타이머 인터럽트(timer interrupt)를 사용한다.
타이머는 수 밀리 초마다 인터럽트라 불리는 하드웨어 신호를 발생시키도록 프로그램 가능하다.
인터럽트가 발생하면 운영체제는 수행 중인 프로세스를 중단시키고 해당 인터럽트에 대한 인터럽트 핸들러(interrupt handler)를 실행한다.
문맥의 저장과 복원
시스템 콜로 협조적으로 하건, 타이머 인터럽트로 강제적으로 하건,
운영체제가 제어권을 다시 획득하면
현재 실행 중인 프로세스를 계속 실행할 것인지
아니면 다른 프로세스로 전환할 것인지 결정해야 함.
이 결정은 운영체제의 스케줄러(scheduler)에 의해 내려짐.
현재 프로세스 중단하고 다른 프로세스 실행하기로 결정하면 운영체제는 문맥 교환(context switch)이라 불리는 코드를 실행함.
현재 실행 중인 프로세스의 레지스터 값들을 커널 스택 같은 곳에 저장하고 새로이 실행될 프로세스의 커널 스택으로부터 레지스터 값을 복원함.
시스템 콜 처리할 때 타이머 인터럽트가 발생하면 어케 됨?
인터럽트 처리할 때 다른 인터럽트가 발생하면 어케 됨?
-> 인터럽트 끄거나 락(lock) 기법 사용
28장 락
락은 일종의 변수다.
락 변수는 (또는 짧게, 락은) 락의 상태를 나타낸다.
락은 사용 가능(available) 상태 (unlocked 또는 free) 또는
사용 중(acquired) 상태 둘 중 하나의 상태를 갖는다.
사용 가능 상태는 어떤 쓰레드도 락을 소유하고 있지 않은 거고
사용 중 상태는 임계 영역에서 정확히 하나의 쓰레드가 락을 획득한 상태이다.
lock() 호출하면 unlock() 호출할 때까지 리턴안 함.
상호 배제 지원할 때 인터럽트 끄는 식으로 해결하면
- 쓰레드가 인터럽트 활성/비활성화하는 특권 연산을 실행할 수 있도록 허가해야 함
- 멀티프로세서에서는 적용할 수 없음
- 장시간 인터럽트 끄면 중요한 인터럽트를 놓칠 수 있음
