📝 배운 것들
🏷️ TA님 QnA
- 단순히 락만 걸려고 한다면 락 변수를 선언할 필요 없이 인터럽트만 꺼도 되는건가요? (싱글코어일 경우)
- 뮤텍스나 세마포어에서 말하는 자원이라는 게 CPU 연산이나 어떤 변수에 대한 접근을 의미하는게 맞나요?
- 만약 preemption이 일어나지 않으면 동기화 기법은 필요 없는게 맞나요?
-
일반적으로 그렇지 않습니다. Interrupt를 끄면 타이머 동작이 무시되어 다른 쓰레드로 스케쥴링되는 것을 막을수는 있지만, exception이라는 메커니즘이 일어날 경우에 문제가 일어납니다. Exception의 대표적 예시로 잘못된 메모리에 접근할때 발생하는 page fault가 있는데, 현재 쓰레드가 특정 자원을 lock한 상태로 page fault가 일어날 경우 현재 쓰레드는 일시정지되고 자동적으로 커널 코드가 실행됩니다. 이 경우 커널 코드가 lock된 자원을 접근하려고 할지도 모르는데, lock변수가 선언되지 않은 경우 lock되어있는지 판단할 방법이 없습니다.
-
말씀하신걸 포함하여 좀 더 광범위한 자원을 생각하시면 됩니다. 가령 filesystem을 구현할 때 disk라는 리소스를 lock으로 접근 제한하는 경우가 있습니다.
-
Preemption이 일어나지 않는 동시성/병렬성이 모두 없는 상황에선 동기화 기법이 필요 없습니다. 동기화 기법은 여러 쓰레드가 동시에 접근할 가능성이 생길때 필요한 메커니즘이기 때문입니다 .하지만 현실적으로 이런 상황은 거의 없는 것 같습니다.
🏷️ pintos에서 얻어갈 것들
시분할 시스템이 어떻게 동작하는지?
스케줄링은 무엇인지?
스케줄링의 대상은 무엇인지?
쓰레드는 무엇을 가상화 하고 있는지?
스케줄링시 쓰레드의 상태가 어떻게 변화되는지?
동기화란 무엇이고, 왜 필요한지? 해결 방식은 어떤 것이 있는지?
(추가적인 내용은 공부키워드를 참고해보세요…)위의 내용을 책이나 구글링을 통해서 습득한 경우보다는
코드 분석과 디버깅을 통해서 어렵게 경험하면, 더 깊이 있게 이해할수 있습니다.
(테스트케이스와 키워드를 연결해서 생각하시기 바랍니다)
일단 gpt로 개념 skimming.
구현할 때 이런 것들을 느껴야 한다고 한다.
- 시분할 시스템이 어떻게 동작하는지?
시분할 시스템(Time-Sharing System)은 여러 사용자 또는 작업이 CPU 자원을 공유할 수 있도록 설계된 시스템입니다. 이러한 시스템에서는 CPU가 각 작업에 일정한 시간 단위(타임 슬라이스 또는 퀀텀)를 할당하며, 이 시간을 초과하면 다른 작업으로 CPU가 전환됩니다. 이 과정은 매우 빠르게 이루어지며, 사용자들은 자신이 시스템을 독점적으로 사용하는 것처럼 느낄 수 있습니다.
동작 방식:
- 타임 슬라이스 할당: 각 작업 또는 프로세스에 대해 CPU가 일정한 시간(타임 슬라이스)을 할당합니다.
스케줄러: CPU가 현재 실행 중인 작업의 타임 슬라이스가 끝나면, 스케줄러가 개입하여 다음 작업으로 전환합니다. - 작업 전환(Context Switch): CPU가 다른 작업으로 전환되기 전에 현재 작업의 상태(레지스터 값, 프로그램 카운터 등)를 저장하고, 새로운 작업의 상태를 복원합니다.
- 빠른 전환: 이 전환이 매우 빠르게 이루어지기 때문에 사용자나 작업은 마치 시스템을 독점적으로 사용하고 있는 것처럼 느낄 수 있습니다.
- 스케줄링은 무엇인지?
스케줄링(Scheduling)은 운영체제가 여러 작업이나 스레드 중 어떤 작업을 언제 실행할지 결정하는 과정입니다. 스케줄러는 시스템의 자원을 효율적으로 사용하고, 작업의 응답성을 높이며, 공정하게 자원을 분배하기 위해 다양한 스케줄링 알고리즘을 사용합니다.
주요 스케줄링 알고리즘:
- FCFS(First-Come, First-Served): 먼저 도착한 작업을 먼저 처리합니다.
- SJF(Shortest Job First): 가장 짧은 작업을 먼저 처리합니다.
- Round Robin: 각 작업에 일정한 타임 슬라이스를 순차적으로 할당합니다.
- Priority Scheduling: 우선순위가 높은 작업을 먼저 처리합니다.
- 스케줄링의 대상은 무엇인지?
스케줄링의 대상은 프로세스와 스레드입니다.
프로세스는 실행 중인 프로그램의 인스턴스입니다. 각 프로세스는 고유의 메모리 공간을 가지며, 독립적으로 실행됩니다.
스레드는 프로세스 내에서 실행되는 작업의 단위입니다. 여러 스레드가 하나의 프로세스 내에서 메모리 공간을 공유하며, 독립적으로 실행될 수 있습니다.
- 쓰레드는 무엇을 가상화 하고 있는지?
쓰레드(Thread)는 CPU의 실행 단위를 가상화합니다. 여러 스레드가 마치 각자 독립적으로 CPU를 사용하는 것처럼 보이지만, 실제로는 CPU 시간을 나누어 사용합니다. 스레드는 다음과 같은 요소를 가상화합니다:
- CPU의 실행 흐름: 각 스레드는 독립된 실행 흐름을 가지며, 마치 여러 CPU를 사용하는 것처럼 보일 수 있습니다.
- 스택 메모리: 각 스레드는 독립된 스택을 가지며, 로컬 변수나 함수 호출 정보를 유지합니다.
스레드는 프로세스 내에서 가상화된 실행 단위이기 때문에, 다중 스레드 환경에서는 하나의 프로세스 내에서 여러 스레드가 동시에 실행되는 것처럼 보이게 됩니다.
- 스케줄링 시 쓰레드의 상태가 어떻게 변화되는지?
스레드의 상태는 스케줄러에 의해 제어되며, 다음과 같은 주요 상태 변화가 발생합니다:
- New (생성): 스레드가 생성되었지만 아직 실행되지 않은 상태.
- Ready (준비): 스레드가 실행을 기다리는 상태. CPU가 사용 가능해지면 실행될 준비가 되어 있습니다.
- Running (실행 중): 스레드가 CPU를 할당받아 실제로 실행 중인 상태.
- Blocked (블록): 스레드가 I/O 작업 완료, 리소스 잠금 해제 등 외부 이벤트를 기다리는 상태. 이 상태에서는 CPU를 사용하지 않습니다.
- Terminated (종료): 스레드가 실행을 완료하고 종료된 상태.
스케줄러는 스레드가 Ready 상태에서 Running 상태로 전환되도록 하고, 실행이 끝나거나 블록되는 경우 스레드를 Blocked 상태로 전환하거나 Terminated 상태로 전환합니다.
- 동기화란 무엇이고, 왜 필요한지? 해결 방식은 어떤 것이 있는지?
동기화(Synchronization)는 여러 스레드나 프로세스가 공유 자원에 동시에 접근할 때 발생할 수 있는 충돌을 방지하기 위한 기법입니다. 동기화가 필요한 이유는 경쟁 조건(race condition)을 방지하고, 데이터 일관성을 유지하기 위함입니다.
왜 동기화가 필요한가?
- 경쟁 조건: 두 개 이상의 스레드가 동시에 공유 자원에 접근하여 그 자원을 수정하려고 할 때 발생할 수 있습니다. 이로 인해 데이터가 손상되거나 예상치 못한 결과가 발생할 수 있습니다.
- 데이터 일관성: 여러 스레드가 동시에 데이터를 읽거나 쓸 때, 데이터가 일관된 상태로 유지되도록 해야 합니다.
동기화 해결 방식:
- 뮤텍스(Mutex): 한 번에 하나의 스레드만 공유 자원에 접근할 수 있도록 하는 동기화 도구입니다. 스레드가 자원에 접근하려면 뮤텍스를 획득하고, 작업이 끝나면 뮤텍스를 해제해야 합니다.
- 세마포어(Semaphore): 여러 개의 스레드가 동시에 접근할 수 있도록 허용하되, 특정 개수만큼만 접근을 허용합니다. 예를 들어, 세마포어 카운터가 3이라면 최대 3개의 스레드가 동시에 자원에 접근할 수 있습니다.
- 모니터(Monitor): 뮤텍스와 조건 변수를 결합한 동기화 기법입니다. 모니터는 자원에 대한 접근을 뮤텍스를 통해 제어하고, 조건 변수를 통해 스레드 간의 시그널링을 처리합니다.
- 조건 변수(Condition Variable): 특정 조건이 만족될 때까지 스레드를 대기시키고, 조건이 만족되면 대기 중인 스레드를 깨우는 데 사용됩니다.
🖥️ PintOS
🔷 Priority Scheduler
1. 기초 공부
쉬운코드 : https://youtu.be/gTkvX2Awj6g?si=TILhtd3j2dQEWQ31
우테코 : https://youtu.be/NL9JQh5bbZ8?si=c0kgQeFpm9gGW1H7
락이 경쟁 조건을 방지하는 방법
락 자체가 경쟁 조건의 가능성이 있는데 어떻게 경쟁 조건을 방지함?
락이 경쟁 조건을 방지할 수 있는 이유는 락의 구현 자체가 경쟁 조건이 발생하지 않도록 설계되었기 때문입니다. 이를 위해 하드웨어 지원과 저수준 원자적 연산이 사용됩니다.
원자적 연산 (Atomic Operations)
락을 구현하는 데 사용되는 기본적인 연산은 원자적입니다. 원자적 연산이란 말 그대로 "원자(atom)"처럼 더 이상 쪼갤 수 없는 연산을 의미하며, 이 연산은 다른 연산에 의해 중단되지 않고, 한 번에 실행됩니다.
예를 들어, test-and-set이나 compare-and-swap 같은 하드웨어 명령어가 있습니다. 이들은 CPU가 명령어를 수행하는 동안 어떤 다른 작업도 끼어들 수 없도록 보장합니다.

맞는 말 한듯?
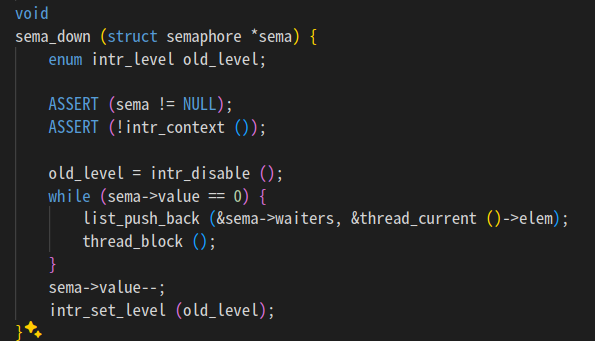
핀토스에는 하드웨어 수준 함수가 없는데 어떻게 한 거지? 하고 봤더니
이 친구는 인터럽트를 끈다. test-and-set 같은 걸 직접 만드는 느낌인듯.
핀토스는 프로세스 하나만 돌아가는 싱글코어니까 인터럽트만 끄면 원자적 연산 가능할듯?

그리고 핀토스는 락을 세마포 함수들을 통해 구현한다.
인터럽트 끄는 법
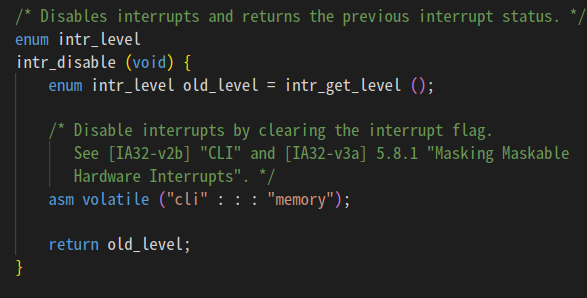
인터럽트 끄는게 어떻게 되는건지 궁금해서 찾아봤더니
대충 플래그 조작하는듯. 주석이 궁금해서 물어봄.
/* Disable interrupts by clearing the interrupt flag.
See [IA32-v2b] "CLI" and [IA32-v3a] 5.8.1 "Masking Maskable
Hardware Interrupts".[IA32-v2b]
이게 뭘 보라는거임
[IA32-v2b]와 같은 참조는 Intel® 64 and IA-32 Architectures Software Developer’s Manual이라는 문서의 특정 부분을 가리키는 표기 방식입니다. 이 문서는 Intel 프로세서의 아키텍처와 관련된 상세한 기술 정보를 제공하며, 컴퓨터 시스템의 하드웨어 및 소프트웨어 인터페이스에 대해 설명합니다.
문서의 구조
Intel의 IA-32 및 Intel 64 아키텍처 매뉴얼은 여러 권으로 구성되어 있으며, 각 권이 특정 주제를 다루고 있습니다.
IA32-v2b: 여기서 v2b는 매뉴얼의 특정 볼륨(Volume 2B)을 의미합니다.
Volume 2는 일반적으로 명령어 세트에 대한 설명을 다루며, 2B는 두 번째 부분을 의미합니다.
CLI: 이는 "Clear Interrupt Flag" 명령어를 가리킵니다. 이 명령어는 인터럽트 플래그(IF)를 0으로 설정하여, 프로세서가 마스크 가능(maskable) 하드웨어 인터럽트를 무시하도록 만듭니다.
5.8.1: 이는 특정 절(section)을 가리킵니다. 여기서는 마스크 가능 하드웨어 인터럽트를 비활성화하는 방법에 대한 설명을 참조하라는 의미입니다.
매뉴얼을 찾는 방법
이러한 참조를 찾기 위해서는 해당 매뉴얼의 올바른 부분을 열어보는 것이 필요합니다. 매뉴얼은 다음과 같이 구성됩니다:
Volume 1: Basic Architecture - 아키텍처 개요와 기본적인 CPU 동작에 대한 설명.
Volume 2A/B: Instruction Set Reference - CPU 명령어에 대한 상세 설명.
2A와 2B는 명령어 집합의 첫 번째 및 두 번째 부분입니다.
Volume 3A/B: System Programming Guide - 시스템 레벨 프로그래밍에 대한 상세 설명.
3A와 3B는 시스템 프로그래밍 가이드의 첫 번째 및 두 번째 부분입니다.
https://www.intel.com/content/www/us/en/developer/articles/technical/intel-sdm.html
진짜 뭐가 있는듯
세마포어는 왜 여러 개를?
여러 개를 동시에 임계 구역에 들이면 안되는 거 아님?
라고 생각했는데
동기분이 설명해주시기론 그땐 따로 경쟁 조건 안 일어나게 사용자가 조율해야 한다고 함

깃북에 의하면, 1 초과 값을 가지는 세마포어는 잘 안 쓴다고 함.
thread_create에 lock 들어가는 이유
thread_create ("acquire1", PRI_DEFAULT + 1, acquire1_thread_func, &lock);&lock이 뭐임?? 갑자기 aux 인자에 왜 주는거?
-> 대충 따라가보니까 어셈블리 코드랑 이어짐.
lock 구현을 하기 위해 넣어주는 것 같음.
트랩과 인터럽트의 차이
/* Creates an gate that invokes FUNCTION.
The gate has descriptor privilege level DPL, meaning that it
can be invoked intentionally when the processor is in the DPL
or lower-numbered ring. In practice, DPL==3 allows user mode
to call into the gate and DPL==0 prevents such calls. Faults
and exceptions that occur in user mode still cause gates with
DPL==0 to be invoked.
TYPE must be either 14 (for an interrupt gate) or 15 (for a
trap gate). The difference is that entering an interrupt gate
disables interrupts, but entering a trap gate does not. See
[IA32-v3a] section 5.12.1.2 "Flag Usage By Exception- or
Interrupt-Handler Procedure" for discussion. */interrupt.c에서 gate 구조체 선언 위에 이런 주석이 달려 있었음.
게이트는 CPU가 발생하는 인터럽트나 예외를 처리하기 위해 특정 코드를 실행해야 할 때, 그 코드를 어떻게 호출할지 지정하는 방식입니다. 이는 x86 아키텍처에서 주로 사용되는 개념으로, 인터럽트 핸들러나 예외 처리 루틴이 실행될 때 사용됩니다.
트랩은 인터럽트의 일종임?
트랩과 인터럽트는 서로 관련이 있지만, 엄밀히 말하면 다른 개념입니다. 둘 다 CPU가 정상적인 프로그램 흐름을 중단하고 특정한 코드를 실행하게 만드는 이벤트이지만, 발생 방식과 처리 방법에 차이가 있습니다.
-
인터럽트(Interrupt)
정의: 인터럽트는 외부 하드웨어 이벤트 또는 시스템 내부에서 발생하는 비동기 이벤트에 의해 발생합니다. 예를 들어, 키보드 입력, 타이머, 네트워크 패킷 수신 등이 인터럽트를 발생시킬 수 있습니다.
발생 시점: 비동기적으로 발생합니다. 즉, 프로그램의 실행 흐름과 무관하게 언제든지 발생할 수 있습니다.
처리 방식: CPU는 현재 실행 중인 작업을 중단하고, 해당 인터럽트를 처리하는 인터럽트 핸들러로 점프합니다. 인터럽트 처리 후, CPU는 중단된 작업을 재개합니다.
예시: 타이머 인터럽트, 키보드 인터럽트, 디스크 I/O 인터럽트 등. -
트랩(Trap)
정의: 트랩은 프로그램 내부의 특정 조건에 의해 발생하는 동기적 이벤트입니다. 트랩은 일반적으로 프로그램이 의도적으로 시스템 콜(예: 파일 열기, 메모리 할당)을 요청하거나, 예외 상황(예: 나누기 오류, 페이지 폴트)이 발생했을 때 발생합니다.
발생 시점: 동기적으로 발생합니다. 즉, 프로그램 코드의 실행 흐름에 따라 예측 가능한 시점에 발생합니다.
처리 방식: CPU는 트랩이 발생한 명령어를 실행한 다음, 즉시 트랩 핸들러로 제어를 넘깁니다. 트랩 핸들러는 특정 작업을 수행한 후, 프로그램 실행을 계속할 수 있도록 CPU를 다시 원래 상태로 복귀시킵니다.
예시: 시스템 콜, 예외(디바이드 바이 제로, 불법 명령어 등).
트랩도 넓은 의미에서 인터럽트의 일종으로 볼 수 있지만, 보통은 프로그램 내부의 예외나 시스템 콜 처리를 위해 발생하는 동기적 이벤트를 의미합니다.
인터럽트 게이트와 트랩 게이트는 각각 인터럽트와 트랩을 처리하기 위한 메커니즘을 제공합니다. 두 게이트의 주요 차이점은, 트랩 게이트는 트랩이 발생해도 인터럽트를 비활성화하지 않는다는 점입니다.
2. priority-sema 통과시키기
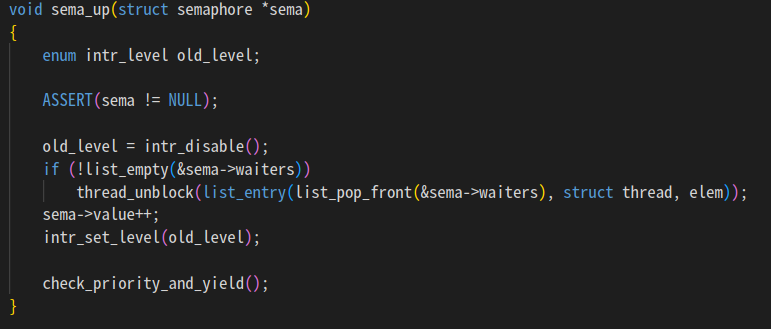
void sema_up(struct semaphore *sema)
{
enum intr_level old_level;
ASSERT(sema != NULL);
old_level = intr_disable();
if (!list_empty(&sema->waiters))
thread_unblock(list_entry(list_pop_front(&sema->waiters), struct thread, elem));
sema->value++;
intr_set_level(old_level);
if (!list_empty(&ready_list))
{
struct thread *FT = list_entry(list_front(&ready_list), struct thread, elem);
if (thread_current()->priority < FT->priority) // 대기 최대 priority가 현재 priority보다 크다면
{
thread_yield(); // 현재 쓰레드 꺼버리기
}
}
}
몇 시간 내내 이것저것 뜯어 고치다가
sema_up에 우선순위 높은 놈이 preemption 하는거 넣어주니까 통과함.
엉뚱한 unblock 가서 오류만 일으키다 제대로 읽어보니까
sema_up에 순회 한 번 넣어주면 끝나는 거였음.
그래도 gpt 도움 안 받고
실행 흐름 읽어보면서 이상한 점 알아내는 과정 겪어봐서 좋았다.
이렇게 ad-hoc 식으로 하는거 말고 schedule 함수에 넣으면 앞으로도 편할 것 같긴 한데...
거기에 넣어서 해보려고 할 때마다 자꾸 코드가 터져서 못했었음.
일단 통과했으니 됐다.
3. priority-donate-one 통과시키기
- 상황 1: 현재 스레드가 기부받지 않은 상태 : 현재 스레드는 아직 다른 스레드로부터 우선순위를 기부받은 적이 없는 상태입니다. 이 경우, 새로운 우선순위를 설정하기 전에 기존의 우선순위를 저장해 두어야 합니다.
old_priority: 스레드의 원래 우선순위를 기록하는 변수입니다. 우선순위를 변경하기 전에 현재 우선순위를 old_priority에 저장합니다.
priority: 스레드의 실제 우선순위를 나타내는 변수입니다. 새로운 우선순위를 설정할 때 이 값을 변경합니다.
- 상황 2: 현재 스레드가 이미 기부받은 상태에서 새로운 우선순위 설정 : 현재 스레드는 이미 다른 스레드로부터 우선순위를 기부받아 우선순위가 상승한 상태입니다. 이 상태에서 새로운 우선순위를 설정해야 하는데, 이 새로운 우선순위가 기부받은 우선순위보다 낮을 때입니다.
우선순위 유지: 현재 스레드의 기부받은 우선순위가 더 높으므로, 우선순위를 낮추지 않고 old_priority만 업데이트합니다. 즉, 스레드의 실제 우선순위(priority)는 변경하지 않습니다.
- 상황 3: 현재 스레드가 기부받은 상태에서 다시 기부받을 때 : 현재 스레드는 이미 다른 스레드로부터 우선순위를 기부받은 상태에서, 다시 또 다른 스레드로부터 우선순위를 기부받는 상황입니다.
old_priority 유지: 현재 스레드의 원래 우선순위(old_priority)는 이미 기록되어 있으므로, 새로운 기부를 받을 때 old_priority를 다시 설정할 필요가 없습니다. 즉, old_priority는 변경되지 않고, 스레드의 priority만 업데이트됩니다.
저번에 긁어왔던 거.

이건 뭔 소린지 모르겠다. 일단 되는대로 해보자.
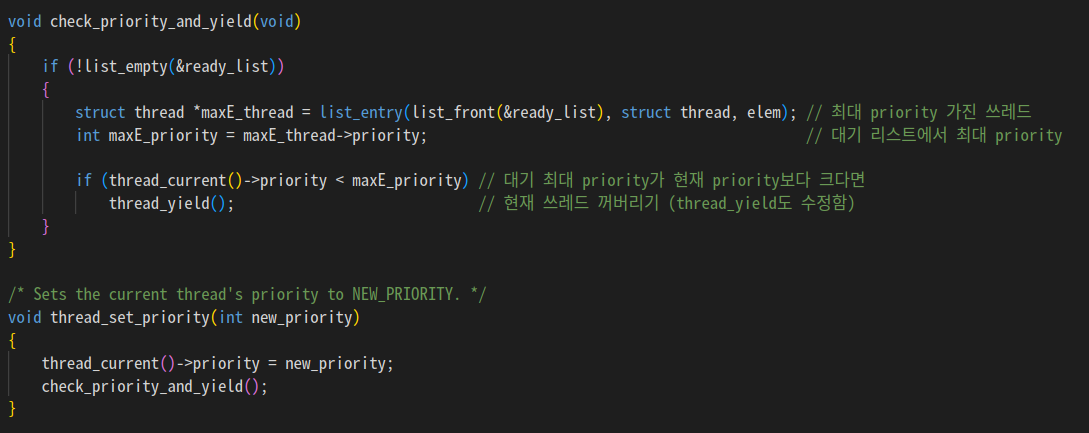
donation 때문에 한참 헤매다가
내 코드가 너무 어지럽다는 사실을 깨달음.
일단 리팩토링 진행해서 코드 깔끔하게 만듦.
어차피 새 쓰레드가 만들어질 때마다 insert_order 함수로 우선순위에 따라 삽입되고,
우선순위 바꾸는 건 현재 쓰레드에서만 이루어지기 때문에 굳이 정렬을 다시 해 줄 필요 없음.
(만약 현재 쓰레드가 아니라 대기 리스트에 있는 쓰레드의 우선순위를 바꿀 수 있는 거였다고 해도 if문 만들고 현재 쓰레드가 아니면 insert_order로 다시 추가해주면 됐을듯)
우선순위 기부는 새로운 우선순위 (아예 새로운 프로세스건, 새로운 우선순위를 부여받았건) 가 등장했을 때 해야지 락을 걸었을 때 현재 리스트 중에서 해버리면 나중에 도착한 놈이 우선순위 크면 우선순위 기부를 못 해버림.
check_priority_and_yield(前 reschedule_by_priority)를 수정해서 우선순위 기부를 구현하면 될듯.
한참을 lock을 어떻게 가져와야할지 생각하다가
gpt한테 자존심 굽히고 물어봤는데 도움도 안됨
팀원분한테 물어봤더니 lock_acquire에서 lock에 대한 정보를 catch했다고 함.
어떻게까지는 더 안 물어봤는데
- 쓰레드에 락 정보를 저장한다
- 락 리스트를 만들어서 관리한다
정도가 있을듯. 지금 내가 해야 되는게
어떤 새로운 우선순위가 등장했을 때
➀ 지가 필요한 락에 우선순위를 기부하고
만약 락 걸려 있는 놈도 다른 락이 필요하면
➁ 걔도 또 기부받은 우선순위를 기부하는게 필요한 건데
그냥 공간 조금 낭비되더라도 쓰레드에 락 저장하는게 마음 편할듯.
는 개소리고 그냥 lock_acquire에서 바로 우선순위 기부해버림.
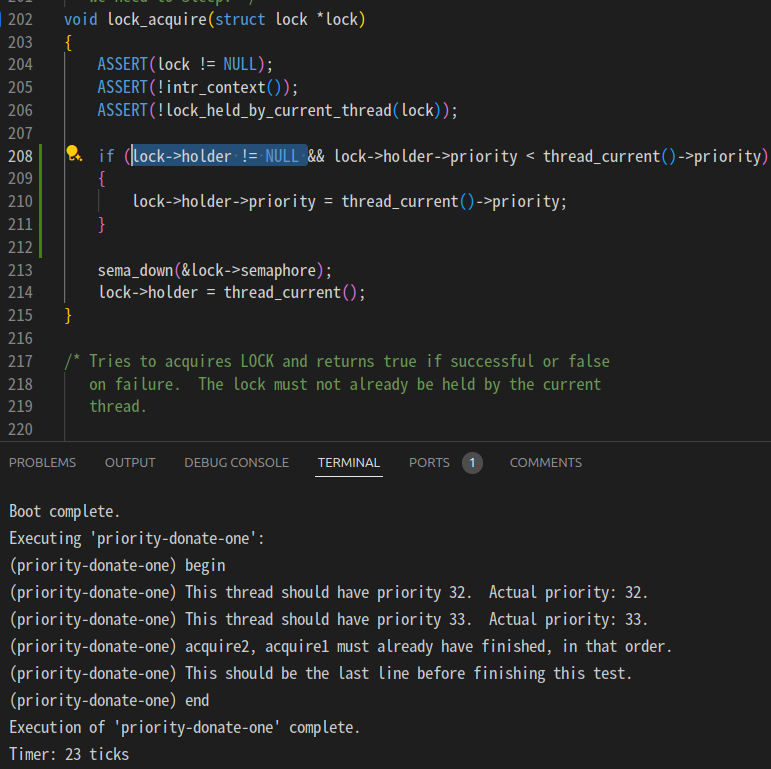
if (lock->holder->priority < thread_current()->priority)
{
lock->holder->priority = thread_current()->priority;
}많은 삽질을 거쳐 이거를 lock_acquire에 추가하기까진 했는데
자꾸만 바로 꺼져버리길래 또 자존심 굽히고 gpt한테 물어봤더니
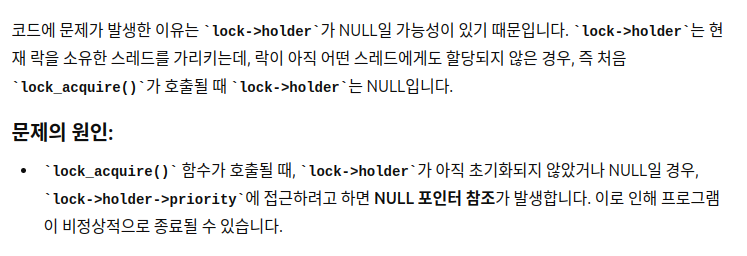
lock->holder != NULL 이거를 조건문에 추가하라고 함.
말도 안되는 소리 하네 ㅋㅋ 하면서 넣었더니 바로 실행됨.
다시 생각해보니 맞는 말이었음.
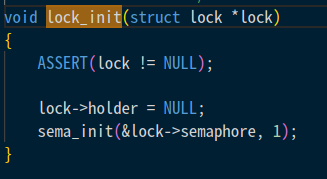
lock_init은 holder를 NULL로 초기화해줌.
그래서 NULL한테 우선순위를 줘버리고, 바로 꺼져버렸던 거임.
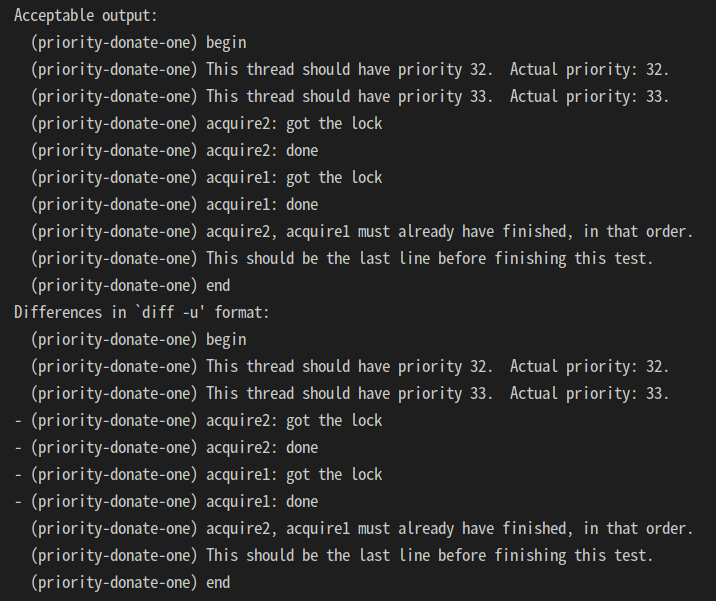
근데 테스트를 통과하진 못함. 이번엔 got the lock이 사라져버림.

쓰레드가 원래 priority로 안 돌아오면
그냥 나머지 lock 얻고 lock release 하는 친구들은 무시해버리고
나 우선순위 높으니까 마저 실행할게~ 하면서 끝까지 실행한 다음
끝나버리는 거였음
그래서 맨 처음에 old_priority가 있어야 된다고 했던 거구나.
쓰레드에 old_priority 정보 저장하면 끝일듯? 나머지는 쉽고.
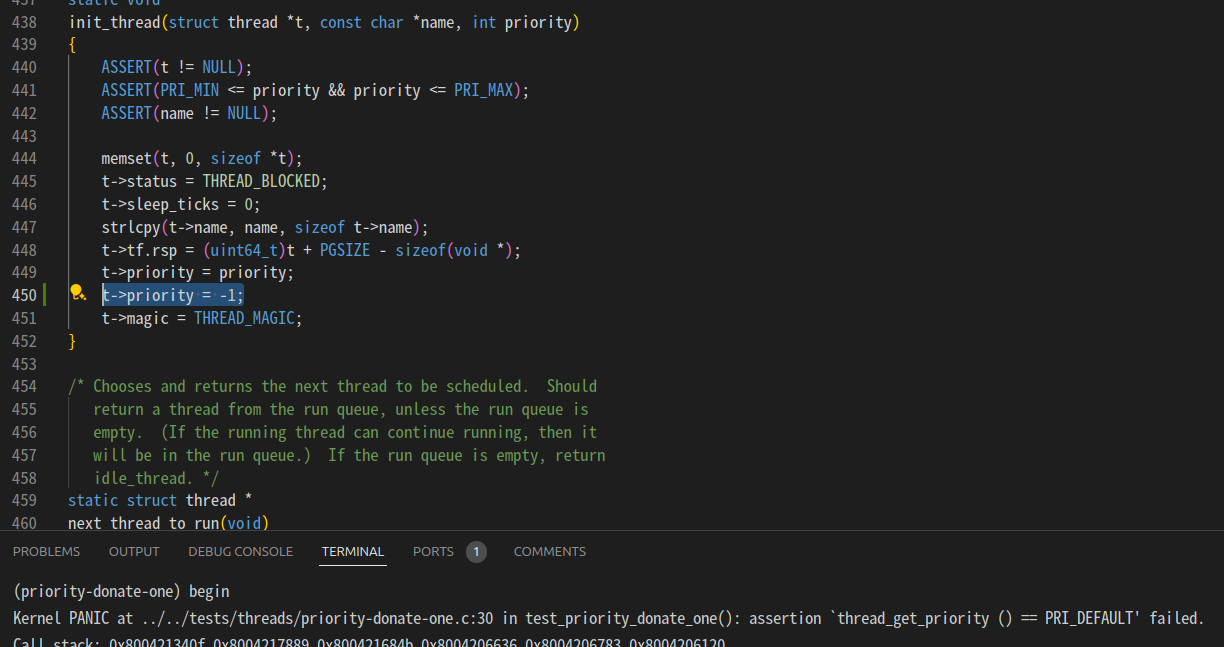
old_priority를 -1로 해야 되는데 priority로 적어놓고 아 왜 안되지 이러고 있었다.
고치니까 통과.
근데 priority-donation-one 말고는 아무것도 통과 못함.
정리
void lock_acquire(struct lock *lock)
{
ASSERT(lock != NULL);
ASSERT(!intr_context());
ASSERT(!lock_held_by_current_thread(lock));
if (lock->holder != NULL && lock->holder->priority < thread_current()->priority)
{
if (lock->holder->old_priority == -1) // lock holder가 기부를 처음 받는 거라면
lock->holder->old_priority = lock->holder->priority; // 기부 받기 전 priority 저장
lock->holder->priority = thread_current()->priority;
}
sema_down(&lock->semaphore);
lock->holder = thread_current();
}lock_acquire할 때 lock holder의 우선순위가 자기보다 작으면 우선순위 기부.
원래 우선순위는 저장. (thread에 old_priority 추가. -1로 초기화함.)
void lock_release(struct lock *lock)
{
ASSERT(lock != NULL);
ASSERT(lock_held_by_current_thread(lock));
if (lock->holder->old_priority != -1) // 기부 받은 적이 있다면 기부 받기 전으로 우선순위 원상복구
lock->holder->priority = lock->holder->old_priority;
lock->holder = NULL;
sema_up(&lock->semaphore);
}lock_release할 때 lock holder가 기부받은 적 있었으면 원래 우선순위로 되돌려놓음.
4. priority-donation-multiple 통과시키기
Acceptable output:
(priority-donate-multiple) begin
(priority-donate-multiple) Main thread should have priority 32. Actual priority: 32.
(priority-donate-multiple) Main thread should have priority 33. Actual priority: 33.
(priority-donate-multiple) Thread b acquired lock b.
(priority-donate-multiple) Thread b finished.
(priority-donate-multiple) Thread b should have just finished.
(priority-donate-multiple) Main thread should have priority 32. Actual priority: 32.
(priority-donate-multiple) Thread a acquired lock a.
(priority-donate-multiple) Thread a finished.
(priority-donate-multiple) Thread a should have just finished.
(priority-donate-multiple) Main thread should have priority 31. Actual priority: 31.
(priority-donate-multiple) end
Differences in `diff -u' format:
(priority-donate-multiple) begin
(priority-donate-multiple) Main thread should have priority 32. Actual priority: 32.
(priority-donate-multiple) Main thread should have priority 33. Actual priority: 33.
(priority-donate-multiple) Thread b acquired lock b.
(priority-donate-multiple) Thread b finished.
(priority-donate-multiple) Thread b should have just finished.
- (priority-donate-multiple) Main thread should have priority 32. Actual priority: 32.
+ (priority-donate-multiple) Main thread should have priority 32. Actual priority: 31.
(priority-donate-multiple) Thread a acquired lock a.
(priority-donate-multiple) Thread a finished.
(priority-donate-multiple) Thread a should have just finished.
(priority-donate-multiple) Main thread should have priority 31. Actual priority: 31.
(priority-donate-multiple) end1% 부족한 느낌?
와 이해하고 나니까 소름돋네;
b만 락 풀면 a로 받는 우선순위 기부는 풀리면 안됐던 거였음;
그럼 쓰레드가 아니라 락에다가 old_priority를 저장하면 될듯?
라는 걸로 간단하게 해결되는 문제가 아니었다.

lock이 a, b 순서대로 잠긴다고 해보자.
a가 준 priority가 32면 old_priority는 31,
b가 준 priority가 33이면 old_priority는 32가 된다.
이때 a의 lock이 풀리면 old_priority로 되돌아가야 하니까 31이 된다.
하지만 사실 31로 돌아가면 안된다. 33을 유지해야 한다.
(그려놓고 다시 생각해보니까 32에 밑줄치면서 32가 돼야돼! 라고 했던 건 개소리였다.)
그니까 다른 락 덕분에 기부를 또 받았다면 old_priority로 되돌아가면 안된다는 얘기.
락을 얼마나 갖고 있는지 쓰레드에 저장을 해야되는건가? 그것도 너무 이상함.
필요한 정보 : 락 a가 기여한 priority, 락 b가 기여한 priority, 쓰레드가 가진 락들에 대한 정보
해야 하는 연산 : 락 a가 release되면 락 b, 혹은 c,d,e... 가 기여한 priority 중 가장 큰 것을 골라 (갱신될 수도 있으니 그때 다시 순회를 돌려야 함. 잠깐 그러면 우선순위가 갱신될 때마다 락이 기여하는 우선순위도 갱신돼야 한다는 건가?) 현재의 우선순위로 만들어야 함. 그리고 old_priority는 31(맨 처음 우선순위)로 고정돼야 함. 즉, 이것만큼은 쓰레드에 종속된 값이라는 뜻.
싹 다 개소리. 그림마저 개소리.
사실 전부 개소리는 아니고, 다시 정리하자면
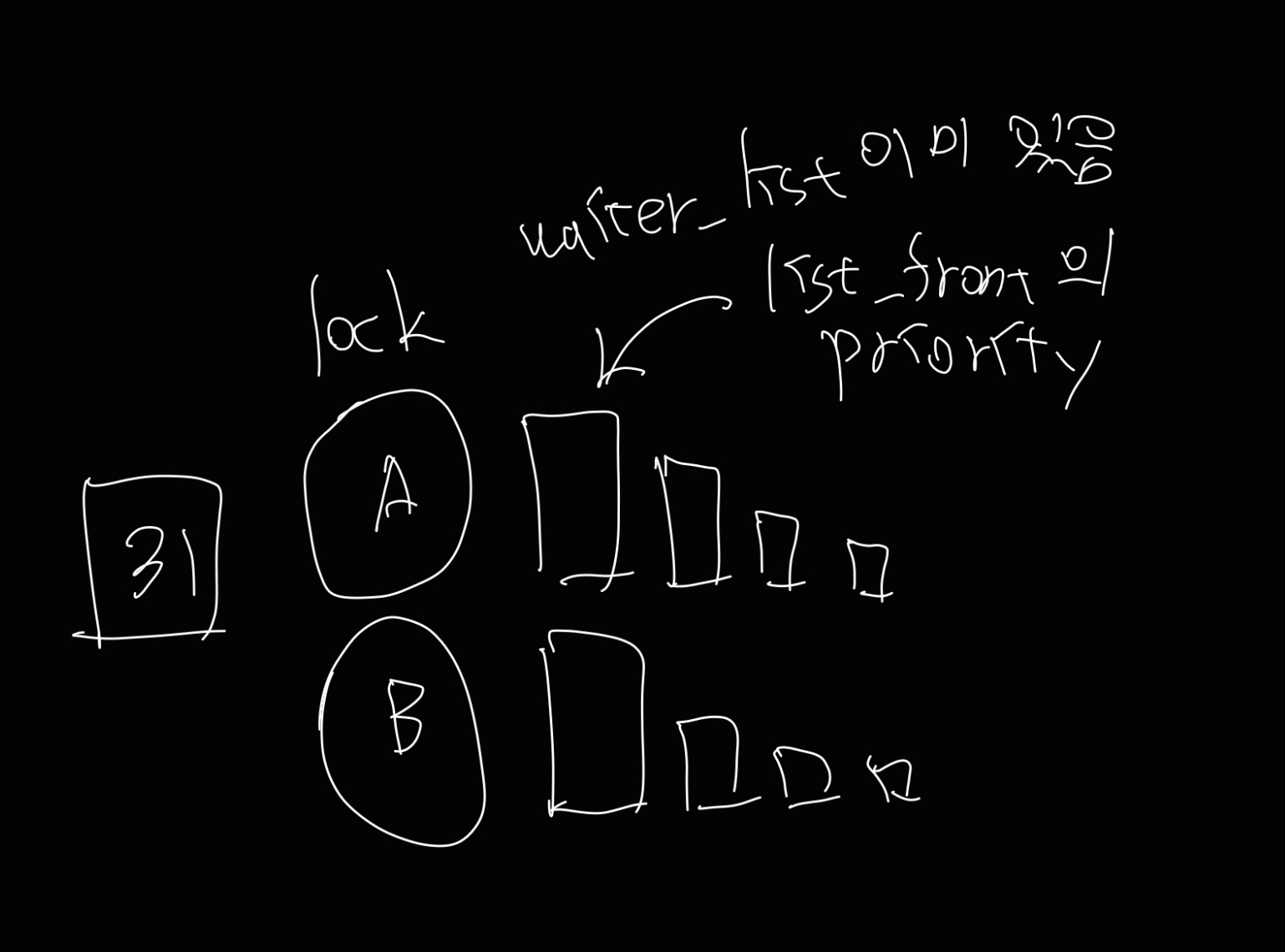
사실 락은 자기가 기여한(할) priority에 대한 정보를 이미 갖고 있음.
pintos에 정의된 락에는 semaphore가 있고, semaphore에는 waiter list가 있기 때문.
waiter list는 내가 우선순위 순서대로 넣어지도록 만들었었음.
따라서 waiter list의 맨 앞에 있는 걸 가져오면 최대 priority, 그러니까 해당 락이 기여하는 우선순위 기부를 얻을 수 있음.
만약 락이 사라지면 해당 쓰레드에 있는 락들을 순회하면서 최대 priority들의 최대값을 구하고 priority를 갱신함.
이때 해당 쓰레드가 갖고 있는 락의 리스트가 empty고 기부받은 적이 있었다면 old_priority로 되돌아감. old_priority는 쓰레드에 종속되는 값임. (락들을 우선순위 순서대로 나열시키면 O(1)이겠지만 락이 어마어마하게 많이 있는것도 아니고 그냥 로직만 구현하는건데 굳이...)
락이 추가되거나 쓰레드가 추가되면 자신의 최대 priority(혹은 priority)와 비교하여 낮을 시 자신의 우선순위로 변경함.
void lock_acquire(struct lock *lock)
{
ASSERT(lock != NULL);
ASSERT(!intr_context());
ASSERT(!lock_held_by_current_thread(lock));
list_push_front(&(thread_current()->lock_list), &(lock->elem)); // 해당 쓰레드의 락 리스트에 락을 넣어준다.
if (lock->holder != NULL && lock->holder->priority < thread_current()->priority) // 락을 가진 쓰레드의 우선순위가 자신보다 낮다면 우선순위 기부
{
if (lock->holder->old_priority == -1) // lock holder가 기부를 처음 받는 거라면
lock->holder->old_priority = lock->holder->priority; // 기부 받기 전 priority 저장
lock->holder->priority = thread_current()->priority;
}
sema_down(&lock->semaphore);
lock->holder = thread_current();
}
void lock_release(struct lock *lock)
{
ASSERT(lock != NULL);
ASSERT(lock_held_by_current_thread(lock));
// 자신이 가진 lock list에서 해당 lock을 찾은 뒤에 지워버린다
struct list_elem *e = list_begin(&(lock->holder->lock_list));
while (list_entry(e, struct lock, elem) != lock)
e = list_next(e);
list_remove(e);
if (list_empty(&(lock->holder->lock_list)) && (lock->holder->old_priority != -1)) // 이제 더 이상 lock이 없고 기부받은 적이 있었다면
{
lock->holder->priority = lock->holder->old_priority; // 원래 priority로 원상복귀한다.
lock->holder->old_priority = -1; // old_priority도 -1로 초기화해준다.
}
else if (lock->holder->old_priority != -1) // 자신이 가진 lock이 아직 남아있다면
{
struct list_elem *max_lock = list_max(&(lock->holder->lock_list), for_searching_lock_priority, NULL); // 최대 priority를 가진 lock을 찾고
struct list *max_lock_waiter = &(list_entry(max_lock, struct lock, elem)->semaphore.waiters); // 그 lock의 waiter까지 접근한 뒤에
int max_priority = list_entry(list_front(max_lock_waiter), struct thread, elem)->priority; // 최대 priority로
lock->holder->priority = max_priority; // priority를 교체해준다
}
lock->holder = NULL;
sema_up(&lock->semaphore);
}
// [락을 대기하고 있는 쓰레드들 중의 최대 priority] 중에 최대값을 탐색하기 위한 함수
bool for_searching_lock_priority(const struct list_elem *a, const struct list_elem *b, void *aux)
{
struct list *al = &(list_entry(a, struct lock, elem)->semaphore.waiters);
struct list *bl = &(list_entry(b, struct lock, elem)->semaphore.waiters);
int ap = list_entry(list_front(al), struct thread, elem)->priority;
int bp = list_entry(list_front(bl), struct thread, elem)->priority;
return ap > bp;
}여기까진 했는데 오류남. 이제 자야됨. 내일 마저 하기로.
while (list_entry(e, struct lock, elem) != lock)
e = list_next(e);
list_remove(e);
if (list_empty(&(lock->holder->lock_list)) && (lock->holder->old_priority != -1)) // 이제 더 이상 lock이 없고 기부받은 적이 있었다면
{
lock->holder->priority = lock->holder->old_priority; // 원래 priority로 원상복귀한다.
lock->holder->old_priority = -1; // old_priority도 -1로 초기화해준다.
}
else if (lock->holder->old_priority != -1) // 자신이 가진 lock이 아직 남아있다면
{
struct list_elem *max_lock = list_max(&(lock->holder->lock_list), for_searching_lock_priority, NULL); // 최대 priority를 가진 lock을 찾고
struct list *max_lock_waiter = &(list_entry(max_lock, struct lock, elem)->semaphore.waiters); // 그 lock의 waiter까지 접근한 뒤에
int max_priority = list_entry(list_front(max_lock_waiter), struct thread, elem)->priority; // 최대 priority로
lock->holder->priority = max_priority; // priority를 교체해준다
}이 부분 고치면 됨
⚔️ 백준
📌 1488 연산자 끼워넣기
def backtrack(num, idx, p, m, mt, dv):
global min_val, max_val
idx += 1
if idx == N:
min_val = min(min_val, num)
max_val = max(max_val, num)
return
next_num = arr[idx]
if p != 0:
backtrack(num+next_num, idx, p-1, m, mt, dv)
if m != 0:
backtrack(num-next_num, idx, p, m-1, mt, dv)
if mt != 0:
backtrack(num*next_num, idx, p, m, mt-1, dv)
if dv != 0:
if num < 0:
backtrack(-(abs(num)//next_num), idx, p, m, mt, dv-1)
else:
backtrack(num//next_num, idx, p, m, mt, dv-1)
N = int(input())
arr = list(map(int, input().split()))
ope = list(map(int, input().split()))
idx = 0
num = arr[idx]
min_val, max_val = float('inf'), -float('inf')
backtrack(num, idx, ope[0], ope[1], ope[2], ope[3])
print(max_val)
print(min_val)이게 이번에 푼 거고
N = int(input())
L = list(map(int, input().split()))
ope_list = list(map(int, input().split()))
res_list = set()
def brute(res,remain,a,b,c,d):
if remain != 0:
if a > 0:
brute(res+L[-remain],remain-1,a-1,b,c,d)
if b > 0:
brute(res-L[-remain],remain-1,a,b-1,c,d)
if c > 0:
brute(res*L[-remain],remain-1,a,b,c-1,d)
if d > 0:
brute(int(res/L[-remain]),remain-1,a,b,c,d-1)
else:
res_list.add(res)
return
a = ope_list[0]
b = ope_list[1]
c = ope_list[2]
d = ope_list[3]
brute(L[0],N-1,a,b,c,d)
maxR = max(res_list)
minR = min(res_list)
print(maxR)
print(minR)이게 저번에 푼 건데,
이번에는 모바일 ide로 풀어서 그런가
시간도 오래 걸렸고, 로직도 뭔가 아래가 조금 더 알아먹기 쉬운 것 같다.
모를 땐 몰라서 내가 최대한 알아먹게 짰는데
조금 성장했다고 싸가지 없이 코드를 짜버리는 것 같기도.
