🖥️ PintOS
📌 권영진 교수님 PintOS 특강
보통 학습은 bottom-up이지만 OS는 design reauirements를 top-down으로 이해하면 좋다.
PintOS 왜 함? : 언젠가 low-level로 코드 짜게 될 거임. 그리고 컴퓨터가 기본적으로 어떻게 돌아가는지 이해해야 성능 좋은거 짤 수 있음.
똑같은 memset 했는데 왜 걸린 시간이 다름?? : 1. 캐싱, 2. 첫 번째로 allocate할 땐 page fault 발생해서 느림(디맨드 페이징).
최신 CPU도 64MB밖에 캐시가 안된다. 1GB allocate하려고 하면 캐시 안됨.
소프트웨어 개발은 문제가 기하급수적으로 증가.
문제를 Divide & Conquer 해야 한다. (문제를 각각 Abstraction해서 쌓아나간다.)
중요한 개념 2가지 : Decomposition, Abstraction
그런 의미에서 OS는 그 두 가지를 배우기 좋은 best practice
OS에서 배우는거
1. 하드웨어를 사용하기 위한 추상화
2. OS 기능 : Protection, Isolation, Sharing resources
easy to program, management unit of execution, protection unit of execution을 추상화해서 각각의 프로그램이 하나의 machine에서 돌아가는 것처럼 환상을 제공하는게 process
CPU, Memory, Storage를 추상화해서 Machine을 사용할 수 있게 하는게 system call
각각의 process는 machine의 abstaction이라할 수 있다.
Own address space, virtual CPU, files
kernel이 virtual address space 각각의 공간에 적재해줌
int a는 stack에, int a = 33의 33은 data에 넣음
각각의 프로세스는 물리 공간 직접 못 보고 가상 주소만 본다.
가상 주소 공간을 4096=4KB라는 chunk로 쪼개서 mapping한다. 그게 page.
Level of indirection : information이 가상 주소 공간에서 물리 주소 공간으로 translation 된다. 행렬 곱하기, 가상주소를 물리주소로 변환하는 함수, 그 중에 하나가 page table
가상주소를 물리주소로 어떻게 mapping? (책을 찾아보시라)
- Segmentation
- Paging (Single-level, multi-level)
- Segmented paging
하드웨어 거쳐서 가는 과정
MMU가 해석해서 이상한 주소면 page fault (exception의 하나, signal : SIGSEGV) libc에 적혀있는대로 segmentation fault
하드웨어가 이벤트를 일으켜서 제어권이 커널로 가고 이벤트에 맞는 행동 함.
exception : overflow, divide by zero. 커널에 알려주면 이벤트 핸들러.
Address translation: paging : MMU에서 일어나는 구체적인 과정은 찾아봐라
페이징을 TLB에 채우는 건 OS가, 물리 주소를 넣어주는 건 HW가
접근할 때마다 page fault남. 그 때 HW가 물리 주소 넣어줌. (demand paging)
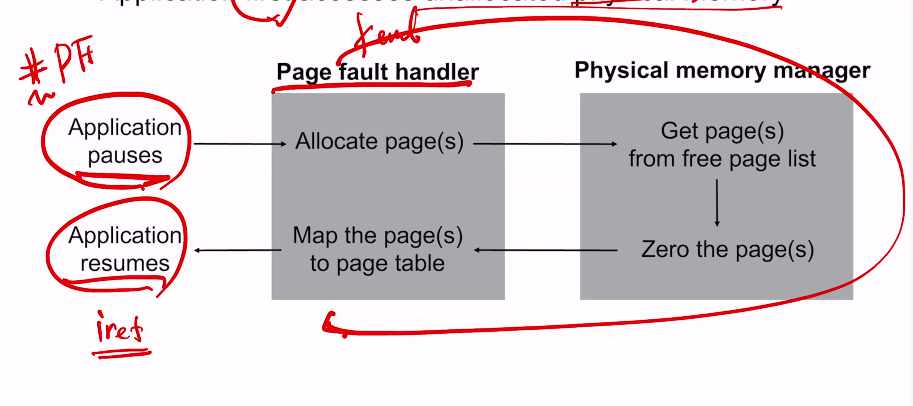
넉넉하게 잡아놓아봤자 다 안 쓸거잖아? application이 요구할 때 물리 주소 할당한다. Demand paging.
application 성능에 critical한 코드들.
Zero the page가 압도적으로 느리다.
근데 이거 안 지우고 주면 안됨. Protection에 정면으로 위배.
어 근데 malloc은 쓰레기값 있지 않음? 그건 같은 프로세스의 쓰레드들끼리니까.
쓰레드 사이의 Protection은 필요 없다. 프로세스 사이의 Protection은 반드시 지켜야 한다.
code, data : file-backed memory, 디스크에서 가져온다, mmap fd 유무
heap, stack : Anonymous memory, 메모리에서 가져온다, mmap MAP_ANONUMOUS 플래그
Direct Memory Access (DMA) : I/O controller에서 CPU를 bypass해서 memory로 direct 접근, 다 끝나면 interrupt
대충 file : 가상 주소, disk에 있는거 : 물리 주소
Location of data is identified by offset(파일의 위치)
주소는 VA -> PA
파일은 (file, offset) -> 디스크 주소(block address)
이걸 file system이라 한다
<filename, data, metatdata> -> <a set of blocks>
파일을 chunk로 쪼갠다 (block)
파일에서 매핑하는 건 indexing
Storage는 느리니까 mmu같은거 없이 sw로 indexing해도 된다
metadata는 storage에 있음
파일은 '저장'시에 physical block에 allocate됨. (fsync라는 시스템 콜 호출)
file system만의 고유 : performance optimization for slow storage device (dram에 올려놓음. page cache -> 최초에는 L2였는데 file단위로 관리하기 위해 L4(VFS - POSIX)로 올림)
Storage stack layer
Generic Block Layer가 HDD, SSD 동일하게 읽을 수 있게 (추상화) 해줌. file system(5xt4, NTFS, XFS...) 읽고 쓰기도 동일하게 해줌.
VFS, POSIX API(open, read, write...) : 유저레벨 소프트웨어가 서로 다른 파일 시스템들을 동일하게 사용할 수 있음.
IO queue는 모든 Storage을 이용해야 하니 L2
🔷 Priority donation
1. priority-donate-multiple 통과시키기
void debug_lock_list(struct thread *t)
{
ASSERT(t != NULL);
struct list *lock_list = &t->lock_list;
struct list_elem *e;
int i = 0;
printf("Debugging lock_list for thread %s (tid: %d)\n", t->name, t->tid);
for (e = list_begin(lock_list); e != list_end(lock_list); e = list_next(e))
{
struct lock *l = list_entry(e, struct lock, elem);
i++;
printf("Lock %d: \n", i);
printf(" Holder: %s (tid: %d)\n", l->holder ? l->holder->name : "None", l->holder ? l->holder->tid : -1);
printf(" Semaphore value: %d\n", l->semaphore.value);
}
if (i == 0)
{
printf("No locks held by thread %s (tid: %d)\n", t->name, t->tid);
}
}gpt한테 디버그 코드 짜달라고 했더니 함수를 만들어줬다.
확실히 이렇게 하면 다 쓰고 나서 지워줄 필요도 없고 좋을듯.
근데 자꾸 무한루프 돌길래 폐기함. 결국 내가 짰음.
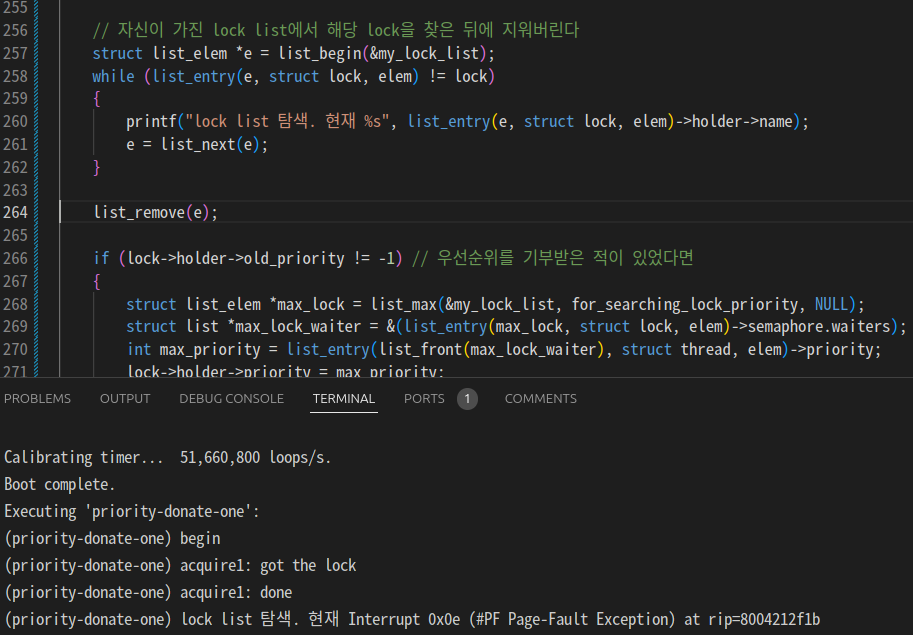
list_remove()에서 문제가 생기는 걸 해결하기 위해 디버깅 문구 삽입.
웬 Interrupt 친구가 lock_list에 있음.
list_remove 도입
list_remove(&lock->elem);
// while (e != list_end(&my_lock_list))
// {
// struct lock *current_lock = list_entry(e, struct lock, elem);
// if (current_lock == lock)
// {
// list_remove(e);
// // printf("Removed lock: %p from lock_list\n", lock);
// break; // 리스트에서 요소를 제거한 후에는 루프를 종료해야 함
// }
// e = list_next(e);
// }디버깅 문구 오만곳에 썼다가 지우는 걸 반복해보다가 gpt한테 물어봤는데 도움 안됨.
동기한테 물어봤더니 list_remove()로 하면 순회 돌 필요 없다고 함.
오류가 왜 생겼던 건진 모르겠지만 일단 이걸로 코드도 간단해지고 문제도 해결 완료.
if (list_begin(my_lock_list)->next == list_end(my_lock_list)->next) // 남은 락이 1개 뿐이라면
{
struct list_elem *remain_lock = list_front(my_lock_list); // 남은 lock을 가져와서
struct list *lock_waiter = &(list_entry(remain_lock, struct lock, elem)->semaphore.waiters); // 남은 lock의 waiter까지 접근한 뒤에
int max_priority = list_entry(list_front(lock_waiter), struct thread, elem)->priority; // 최대 priority로
lock->holder->priority = max_priority; // priority를 교체해준다
}
else
{
struct list_elem *max_lock = list_max(my_lock_list, for_searching_lock_priority, NULL); // 최대 priority를 가진 lock을 찾고
struct list *max_lock_waiter = &(list_entry(max_lock, struct lock, elem)->semaphore.waiters); // 그 lock의 waiter까지 접근한 뒤에
int max_priority = list_entry(list_front(max_lock_waiter), struct thread, elem)->priority; // 최대 priority로
lock->holder->priority = max_priority; // priority를 교체해준다
}
lock->holder = NULL;
sema_up(&lock->semaphore);
}
}
// [락을 대기하고 있는 쓰레드들 중의 최대 priority] 중에 최대값을 탐색하기 위한 함수
bool for_searching_lock_priority(const struct list_elem *a, const struct list_elem *b, void *aux)
{
struct list *al = &(list_entry(a, struct lock, elem)->semaphore.waiters);
struct list *bl = &(list_entry(b, struct lock, elem)->semaphore.waiters);
// 리스트가 비어 있으면 0
int ap = list_empty(al) ? 0 : list_entry(list_front(al), struct thread, elem)->priority;
int bp = list_empty(bl) ? 0 : list_entry(list_front(bl), struct thread, elem)->priority;
return ap > bp;
}지우기 전 백업
(살짝 갈아엎고 만들기)
lock list 순회 터지는거 해결
// 아니 그럼 이새끼도 터짐?
size_t list_size(my_lock_list);
// 내려놓은 lock의 우선순위를 갱신해준다
if (lock->holder->old_priority != -1) // 우선순위를 기부받은 적이 있었다면
{
// 자신이 가진 락들을 다시 순회하여 최대 priority 얻기
int max_priority = lock->holder->old_priority;
struct list_elem *e;
for (e = list_begin(my_lock_list); e != list_end(my_lock_list); e = list_next(e))
{
// int elem_priority = list_entry(e, struct lock, elem)->priority_to_donate;
// printf("elem_prirotiy : %d\n", elem_priority);
// max_priority = (elem_priority > max_priority) ? elem_priority : max_priority;
}
lock->holder->priority = max_priority;
// 만약 남은 락이 없었다면 기부 받을게 없으므로 old_priority를 -1로 바꿔주기
if (list_empty(my_lock_list))
lock->holder->old_priority = -1;
}size_t list_size(my_lock_list); 여기 순회 로직이
size_t
list_size(struct list *list)
{
struct list_elem *e;
size_t cnt = 0;
for (e = list_begin(list); e != list_end(list); e = list_next(e))
cnt++;
return cnt;
}내 순회 로직이랑 똑같은데도 list_size는 통과하고 내 순회는 오류 일으키길래 뭐지? 했는데
size_t list_size(my_lock_list); 이렇게 해놔서 틀렸던 거
원래는 변수로 선언해서 받으려고 했는데 까먹고 자료형까지만 써뒀음
list_size(my_lock_list); 이렇게 했더니 여기서 멈춤.
일단 순회할 때 뭔가 문제가 생긴다는 건 알겠음.
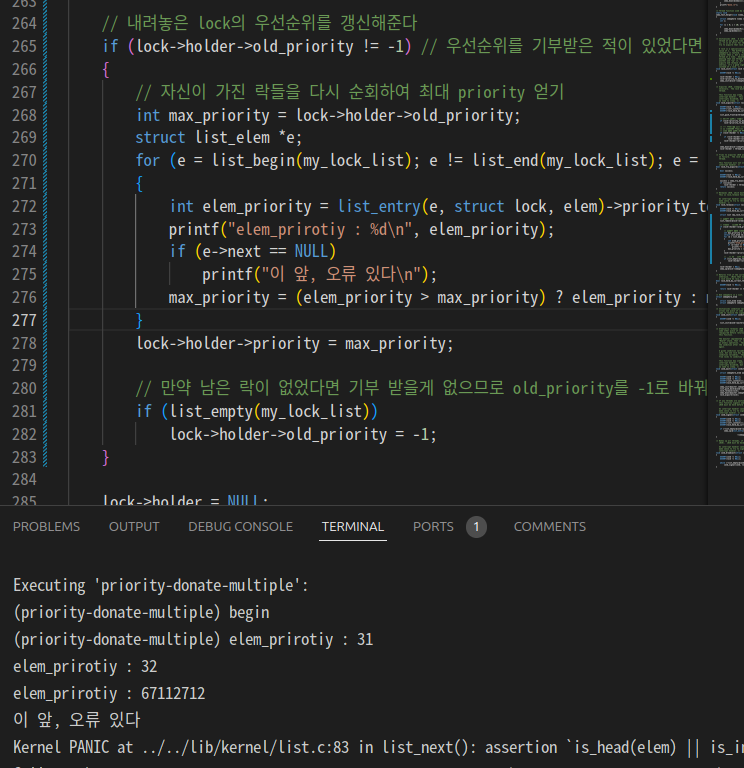
제대로 된 오류 상황을 드디어 처음 확인함.
1. lock에 이상한게 들어가있음.
2. list_end 조건에 안 걸리고 마저 순회를 돌다가 터져버림.
첫 번째 문제를 해결하기 위해 lock_acquire을 확인해야 함.
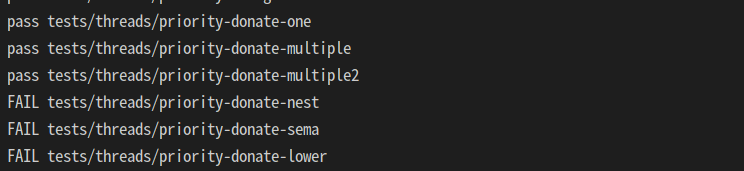
아니 한 줄 위치 바꿨더니 모든 오류가 사라지면서 통과함;
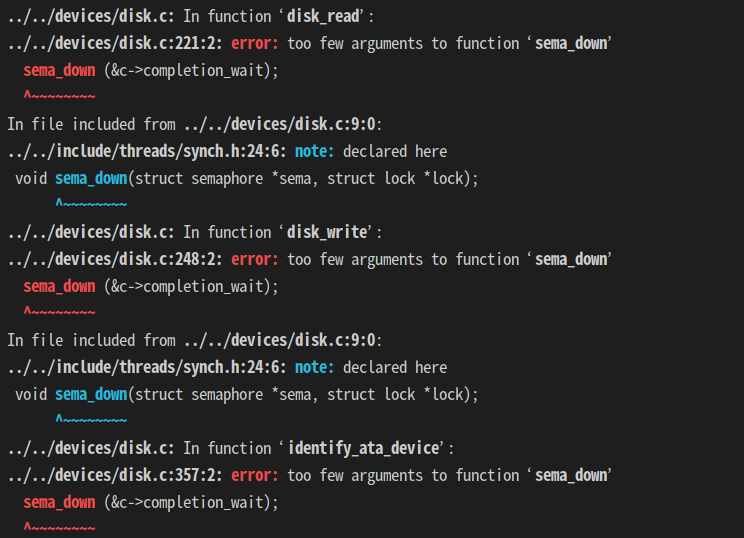
sema_down 인자는 절대 추가하면 안된다. 너무 고칠게 많아짐. 안 고치는게 맞는 것 같음.
정리
void lock_acquire(struct lock *lock)
{
ASSERT(lock != NULL);
ASSERT(!intr_context());
ASSERT(!lock_held_by_current_thread(lock)); // current_thread는 해당 락 아직 안 갖고 있음
// 새로운 쓰레드 추가로 인해 락이 donation할 우선순위 갱신
if (lock->priority_to_donate < thread_current()->priority)
lock->priority_to_donate = thread_current()->priority;
/* !!! 이새끼가 문제 !!! */
/* 락 리스트에 이상한게 들어가서 터지는 것? */
// 락을 가진 쓰레드의 우선순위가 락 대기열의 최고 우선순위보다 낮다면 우선순위 기부
if (lock->holder != NULL && lock->holder->priority < lock->priority_to_donate)
{
if (lock->holder->old_priority == -1) // 기부를 처음 받는다면 old_priority에 저장
lock->holder->old_priority = lock->holder->priority;
lock->holder->priority = lock->priority_to_donate;
}
sema_down(&lock->semaphore);
list_push_front(&(thread_current()->lock_list), &lock->elem); // 해당 쓰레드의 락 리스트에 락을 넣어준다.
lock->holder = thread_current();
}list_push_front(&(thread_current()->lock_list), &lock->elem); 이 친구 위치를 sema_down 아래로 넣어줬을 뿐인데 갑자기 donate-multiple을 통과했다.
쓰레드에 락이 추가되면 추가된 락을 갖고 있는 holder의 우선순위를 기부한다.
그 후 semaphore를 하나 내려주고,
쓰레드의 lock_list에 lock을 넣어준다.
lock의 elem은 유일하기 때문에 lock을 얻기 전에 넣어버리면 lock이 이 쓰레드 저 쓰레드에 소속되어버려서 순회하면 펑. 그래서 그랬던 거였음.
void lock_release(struct lock *lock)
{
ASSERT(lock != NULL);
ASSERT(lock_held_by_current_thread(lock));
struct list *my_lock_list = &(lock->holder->lock_list); // 자신이 가진 lock들의 list
// 자신이 가진 lock들의 list에서 해당 lock을 지워버린다
list_remove(&lock->elem);
// 내려놓은 lock의 우선순위를 갱신해준다
if (lock->holder->old_priority != -1) // 우선순위를 기부받은 적이 있었다면
{
// 자신이 가진 락들을 다시 순회하여 최대 priority 얻기
int max_priority = lock->holder->old_priority;
struct list_elem *e;
for (e = list_begin(my_lock_list); e != list_end(my_lock_list); e = list_next(e))
{
int elem_priority = list_entry(e, struct lock, elem)->priority_to_donate;
// printf("elem_prirotiy : %d\n", elem_priority);
// if (e->next == NULL)
// printf("이 앞, 오류 있다\n");
max_priority = (elem_priority > max_priority) ? elem_priority : max_priority;
}
lock->holder->priority = max_priority;
// 만약 남은 락이 없었다면 기부 받을게 없으므로 old_priority를 -1로 바꿔주기
if (list_empty(my_lock_list))
lock->holder->old_priority = -1;
}
lock->holder = NULL;
sema_up(&lock->semaphore);
}lock을 내려놓기 전에
자신이 가진 lock들의 list에서 해당 lock을 지우고
해당 lock의 우선순위를 갱신해준다.
2. priority-donate-sema 통과시키기
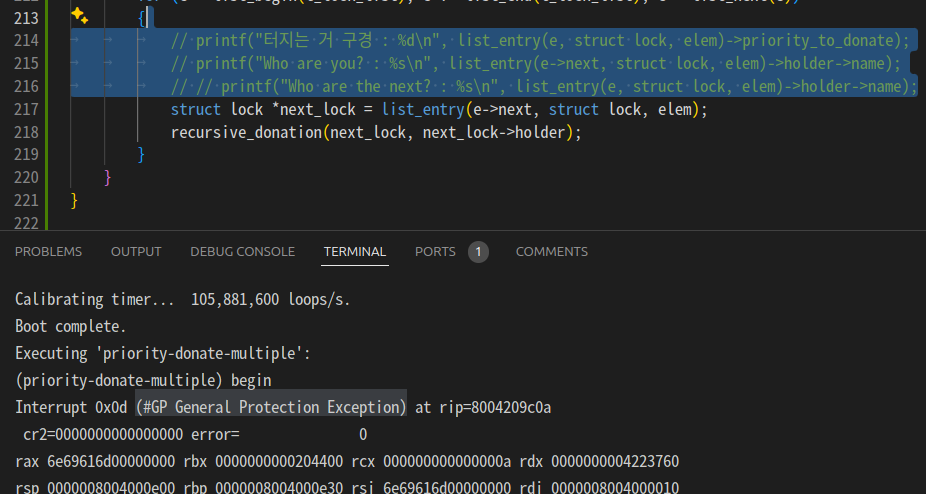
디버깅 문구를 찍어봤더니 그 친구 이름이 Interrupt였던게 아니라,
그냥 출력하려고 해당 값에 접근하면 오류 인터럽트가 나는 거였음.
아무튼 (#GP General Protection Exception) 라는 걸 검색해봤더니

https://wasdpluskr.tistory.com/6

gpt한테 마저 설명해달라고 했는데
대충 재귀로 만들어서 그런게 아닐까 싶음.
void recursive_donation(struct lock *lock, struct thread *t)
{
// lock에 대해 thread t의 우선순위 정보가 추가(혹은 갱신)된 것을 반영하는 재귀 함수
if (lock->priority_to_donate < t->priority)
{
lock->priority_to_donate = t->priority;
// 락을 가진 쓰레드의 우선순위가 락 대기열의 최고 우선순위보다 낮다면 우선순위 기부
if (lock->holder != NULL && lock->holder->priority < lock->priority_to_donate)
{
if (lock->holder->old_priority == -1) // 기부를 처음 받는다면 old_priority에 저장
lock->holder->old_priority = lock->holder->priority;
lock->holder->priority = lock->priority_to_donate;
// 이제 내가 우선순위를 갱신한 holder 친구가 가진 lock들의 우선순위도 갱신해줘야 함
struct list *holders_lock_list = &lock->holder->lock_list;
struct list_elem *e;
for (e = list_begin(holders_lock_list); e != list_end(holders_lock_list); e = list_next(e))
{
struct lock *next_lock = list_entry(e, struct lock, elem);
recursive_donation(next_lock, lock->holder);
}
}
}
}
void lock_acquire(struct lock *lock)
{
ASSERT(lock != NULL);
ASSERT(!intr_context());
ASSERT(!lock_held_by_current_thread(lock)); // current_thread는 해당 락 아직 안 갖고 있음
recursive_donation(lock, thread_current());
sema_down(&lock->semaphore);
list_push_front(&(thread_current()->lock_list), &lock->elem); // 해당 쓰레드의 락 리스트에 락을 넣어준다.
lock->holder = thread_current();
}
void lock_release(struct lock *lock)
{
ASSERT(lock != NULL);
ASSERT(lock_held_by_current_thread(lock));
struct list *my_lock_list = &(lock->holder->lock_list); // 자신이 가진 lock들의 list
// 자신이 가진 lock들의 list에서 해당 lock을 지워버린다
list_remove(&lock->elem);
// 내려놓은 lock의 우선순위를 갱신해준다
if (lock->holder->old_priority != -1) // 우선순위를 기부받은 적이 있었다면
{
// 자신이 가진 락들을 다시 순회하여 최대 priority 얻기
int max_priority = lock->holder->old_priority;
struct list_elem *e;
for (e = list_begin(my_lock_list); e != list_end(my_lock_list); e = list_next(e))
{
int elem_priority = list_entry(e, struct lock, elem)->priority_to_donate;
max_priority = (elem_priority > max_priority) ? elem_priority : max_priority;
printf("내가가진락은:%s\n", list_entry(e, struct lock, elem)->holder->name);
}
lock->holder->priority = max_priority;
// 만약 남은 락이 없었다면 기부 받을게 없으므로 old_priority를 -1로 바꿔주기
if (list_empty(my_lock_list))
lock->holder->old_priority = -1;
}
lock->holder = NULL;
sema_up(&lock->semaphore);
}안됨. 코드도 더러워짐. 내일 다시 싹 갈아엎고 만들어야할 것 같음.
이거 보니까 디버깅 하는 것보다 안되겠다 싶을 때마다 다시 갈아엎는게 맞는 것 같음.
안되는 거 붙잡고 있으니까 진전이 없음.
