업데이트
- 2021.05.20 세미나 내용 업데이트
세미나를 하기 전
이 글은 랩메이트 석준의 GPU Utilization 세미나 소개글입니다. 또한 세미나 후 관련 내용을 정리해서 업데이트할 예정입니다.
Deep Learning 시대에 진입한지 5~6년이 흐르고 Keras, Pytorch-Lightning, 각 task 별로 유명한 프레임워크(BasicSR, Detectron2)를 통해 최적화를 많이 신경쓸 필요 없이 연구를 진행가능하게 되었습니다.
하지만 언제나 자원은 부족하고 연구 진행 속도는 빠를수록 좋습니다. GPU Utilization 세미나에서는 Training Pipeline을 이해하고 GPU를 포함한 서버 자원을 더 효율적으로 사용하는 법을 간단히 소개하고자 합니다. 매일매일 GPU를 혹사시키며 쌓아온 석준의 노하우를 들을 절호의 기회!
좀더 실용적으로는 아래와 같은 예쁜 그래프를 만들 수 있는 기회가 되겠습니다.
- 날짜: 4.15(목) 3시
- 장소: D701
 |
|---|
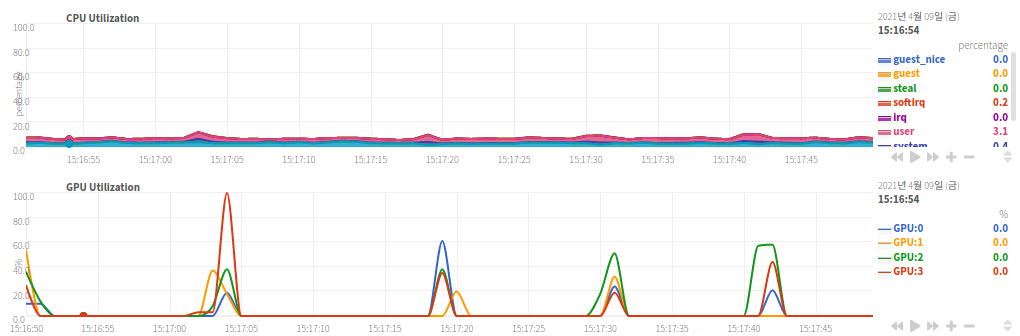
| GPU 사용의 적당한 예시 |
 |
|---|
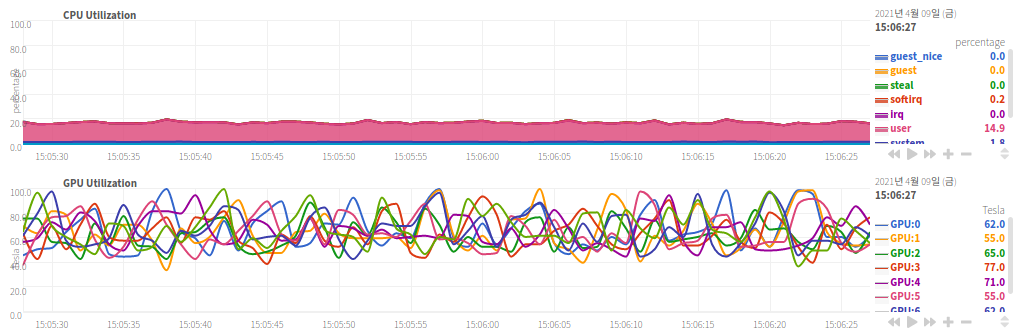
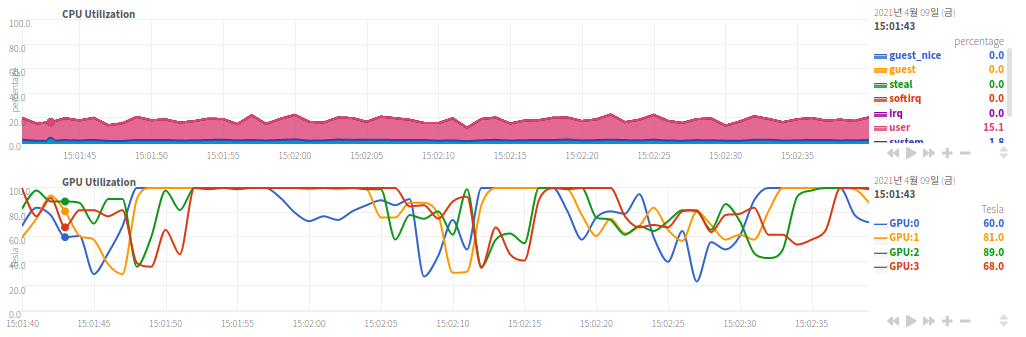
| GPU 사용의 극한 예시(GPU 타는 소리가 들린다) |
 |
|---|
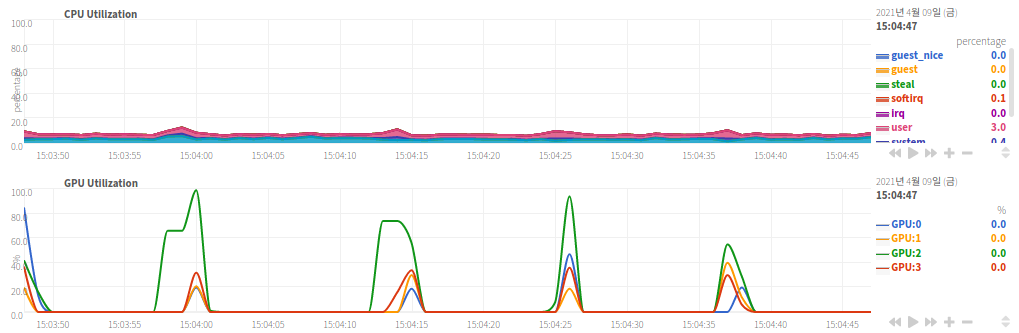
| GPU 사용의 안 좋은 예시 |
세미나 내용 정리
기본 원칙
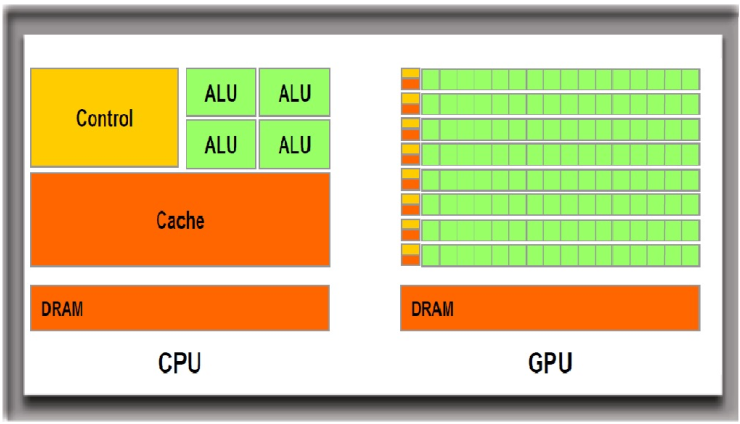
GPU 사용의 기본 원칙을 이해하려면 우선 구조 상의 차이점을 알아야한다. CPU의 경우에는 Turing Machine에 한없이 가까운, 다시 말해 우리가 생각하는 대부분의 컴퓨터 연산이 구현가능한 시스템 반도체다. GPU와 대비해 비유하자면 머리가 대단히 좋은 학생이 소수(1명 ~ 32명)이 있는 구조다.
반면 GPU는 대단히 간단한 계산(더하기, 곱하기 등)만을 수행할 수 있지만 이를 대규모로 병렬로 처리할 수 있는 시스템 반도체다. CPU와 대비해 비유하자면 머리가 안 좋은 학생이 다수(5000~10000명)이 있는 구조라고 할 수 있겠다.
이와 같은 상황에서 GPU를 잘 사용한다는 것은 Space Complexity를 희생해 메모리를 많이 사용하더라도 GPU Core를 놀리지 않도록 프로그래밍할 때 신경쓰는 것을 의미한다.
Practical Tip 1: Data가 Bus를 덜 타도록 하자
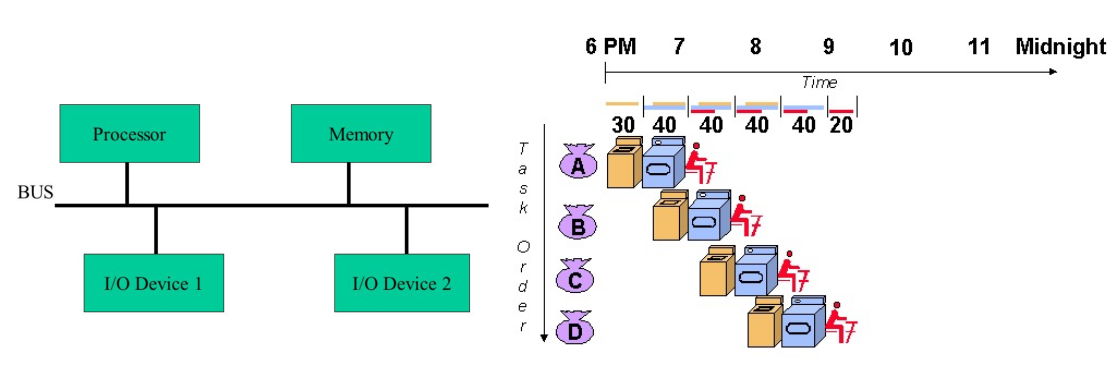
운영체제를 배웠다면 알겠지만 폰 노이만 구조에서 필수적인 부분은 Processor와 Memory이며 그 외에는 모두 I/O Device로 Request, Interrupt를 이용해서 사용하게 된다.
예를 들면 키보드 같은 경우에는 입력이 들어오면 매번 OS에게 Interrupt로 입력을 알려 주는 식이고, 모니터 같은 경우에는 OS에게서 Request를 받는 식이다. GPU도 마찬가지로 GPU Job을 Request받고 그 결과를 CPU에 Interrupt로 알려준다. 그런데 이 과정에서 Data가 Bus를 타고 오가게 되는데 GPU 연산의 특성상 그 양이 대단히 많다. 따라서 아래와 같은 Cpu job, Gpu job의 순서를 가지면 중간에 있는 Cpu job 앞뒤로 대단한 병목 현상이 일어나게 된다.
좀더 Practical하게는 Pytorch의 Data Loader에서 CPU에서 할일을 빠르게 끝내고 GPU에서 일을 시킨 동안은 모두 GPU에서 처리한 뒤에 다시 CPU로 가져와야한다. 이 관점에서는 For Loop을 사용하는 것도 문제가 될 수 있는데 for loop에 사용되는 index variable이 CPU에서 연산되기 때문에 병목이 될 수 있기 때문이다.
Practical Tip 2: Indexing을 잘 활용하기
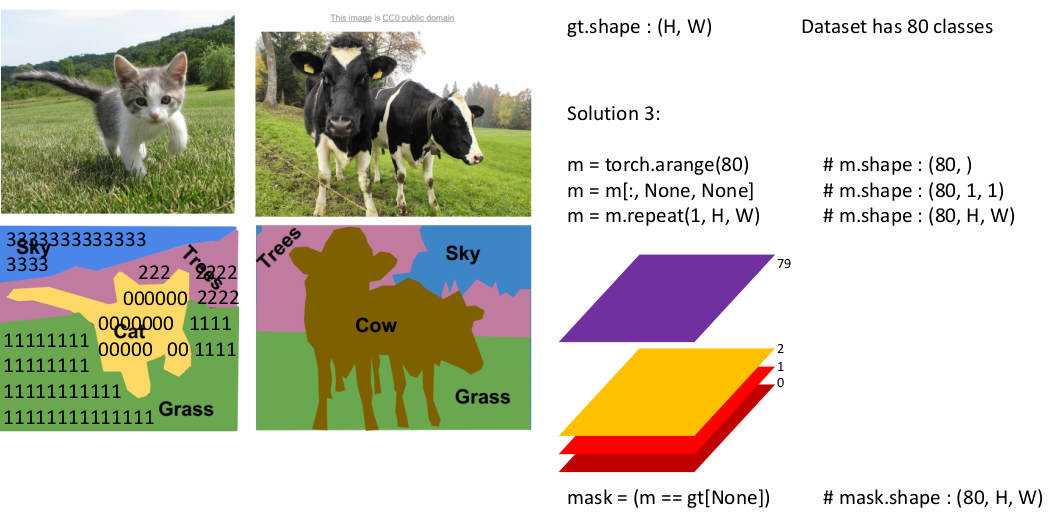
아래와 같이 80개의 클래스가 있는 segmentation map이 있는데 각 클래스 별 bit mask(80, H, W)를 만들고 싶다고 하자. 이 경우 아래와 같이 For loop을 사용하지 않고 해결할 수 있다.
Practical Tip 3: 메모리를 뿌셔서 속도를 올리기
이미지 사이즈가 달라서 고민되는 경우 아래와 같이 그냥 zero padding을 해서 size를 맞추고 연산을 한 뒤에 Loss를 실제 이미지 영역에만 적용하는 게 더 좋다. GPU에서는 코어와 메모리가 충분하기 때문에 이렇게 하는 게 좋다. 실제로 Convolution 연산을 할 때도 im2col과 같은 연산들은 이런 패러다임으로 디자인 되어있다.

사소한 팁들
- Pytorch에서는 Contiguous를 주의해야한다. View만 바꾸는 것인지 실제로 Memory상에서 Replace를 하는 것인지. 예를 들면
flatten과permute가 있다 - For loops을 가능한 없애고 vectorization, generator 등을 사용한다
- 좋은 코드를 많이 보자. Detectron2, ClassyVision, VSL 등 훌륭한 기관에서 관리하는 Open Source들을 많이 보면 좋다
참고자료
