Assigning numbers to non-number values using Label Encoder
import pandas as pd
df = pd.DataFrame({'A': ['a', 'b', 'c', 'a','b'],
'B': [1, 2, 3, 1, 0]})
df['le_A'] = le.fit_transform(df['A'])
df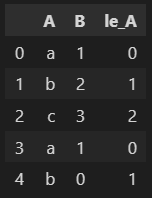
We can go from string to int:
le.inverse_transform(df['le_A'])Feature Scaling
- Feature scaling enables gradient descent to run faster
Min-max Scaling
df = pd.DataFrame({
'A': [10, 20, -10, 0, 25],
'B': [1, 2, 3, 1, 0]
})
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
mms.fit(df)
df_mms = mms.transform(df)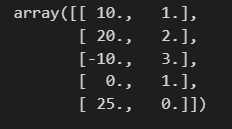
Standard Scaler (Z-score)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(df)
df_ss = ss.transform(df)
Robust Scaler
from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler
mm = MinMaxScaler()
ss = StandardScaler()
rs = RobustScaler()
df_scaler = df.copy()
df_scaler['MinMax'] = mm.fit_transform(df)
df_scaler['Standard'] = ss.fit_transform(df)
df_scaler['Robust'] = rs.fit_transform(df)
df_scaler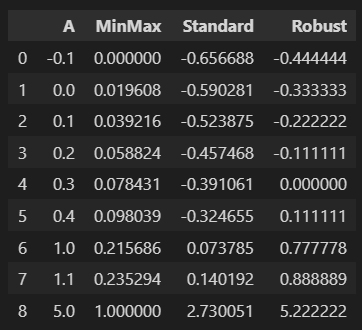
In general there is very little difference in performance between the MinMaxScaler and the StandardScaler. The Robust scaler may be more 'robust' against outliers as the median will be 0. If I am using ReLU as the activation function, for instance, I would lean towards the Min-Max Scaler as this will yield target values between [0, 1].
Creating a Pipeline
import pandas as pd
red_url = "https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv"
white_url = "https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv"
red_wine = pd.read_csv(red_url, sep=";")
white_wine = pd.read_csv(white_url, sep=";")
red_wine['color'] = 1
white_wine['color'] = 0
wine = pd.concat([red_wine, white_wine])
X = wine.drop(['color'], axis = 1)
y = wine['color']
wine.head()
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [
('scaler', StandardScaler()),
('clf', DecisionTreeClassifier())
]
pipe = Pipeline(estimators)
pipe.steps[('scaler', StandardScaler()), ('clf', DecisionTreeClassifier())]
pipe.set_params(clf_max_depth=2)
pipe.set_params(clf__random_stae=13)

An Aspiring Back-end Developer