Strings and runes
-
go 언어의 String은 기본적으로 byte slice이다.
-
각각의 byte들은 UTF-8 인코딩의 유니코드 문자 코드값들을 담고 있다.
-
rune은 UTF-8인코딩의 유니코드 코드 포인트를 표시하는 정수이다.
-
즉, 각각의 유니코드 문자들은 rune으로 표현될 수 있다.
-
예제로 더 알아보자
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
const s = "안녕하세요"
fmt.Println("Len:", len(s))
for i := 0; i < len(s); i++ {
fmt.Printf("%x ", s[i])
}
fmt.Println()
fmt.Println("Rune count:", utf8.RuneCountInString(s))

- 위에 서술했듯 go에서 문자열은 기본적으로
[ ] byte형태이다. 문자들은 각각 UTF-8로 인코딩된 형태이며, 한글은 유니코드 문자 하나당 3byte를 차지하기 때문에 15를 반환하는 것을 볼 수 있다. - RuneCountInString 함수를 이용하면 유니코드 문자 갯수를 반환 받을 수 있다.
...
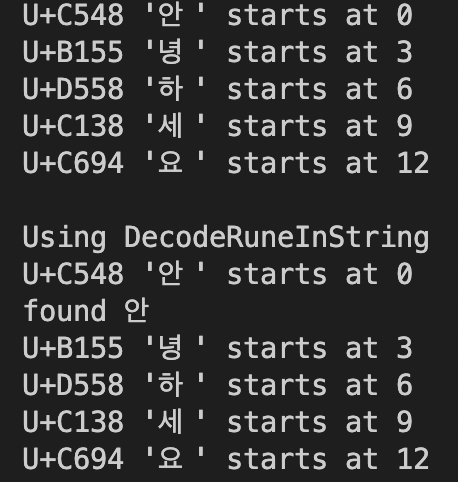
s := "안녕하세요"
for idx, runeValue := range s {
fmt.Printf("%#U starts at %d\n", runeValue, idx)
}
fmt.Println("\nUsing DecodeRuneInString")
for i, w := 0, 0; i < len(s); i += w {
runeValue, width := utf8.DecodeRuneInString(s[i:])
fmt.Printf("%#U starts at %d\n", runeValue, i)
w = width
examineRune(runeValue)
}
}
func examineRune(r rune) {
if r == 't' {
fmt.Println("found t")
} else if r == '안' {
fmt.Println("found 안")
}
}
-
for 과 range를 이용해 룬 값과 문자열의 몇번째 바이트에서 시작하는지 오프셋을 얻을 수 있다.
-
utf8.DecodeRuneInString 함수도 같은 값을 반환하지만 반환해주는 순서가 반대이다.

https://github.com/poi1649/learning