Redis란?
- Key, Value 구조의 비정형 데이터를 저장하고 관리하기 위한 오픈 소스 기반의 비관계형 데이터 베이스 관리 시스템 (DBMS)
- 데이터베이스, 캐시, MQ로 사용된다.
리뷰에서 캐시를 사용하는 상황
- 쓰기보다 조회가 많이 일어난다.
- 평균 평점, 총 리뷰 수에 캐시를 사용하기 때문에
쓰기 연산보다 읽기 연산이 많이 발생한다. - 특정 기간 안에 리뷰를 작성하면 상품을 주는 이벤트를 하더라도 한번에 처리하는 리뷰 수는 많지 않다.
- 따라서 읽기 전략은
Look Aside, 쓰기 전략은Write Through를 적용한다.
캐시 서버 패턴
Look aside cache(Cache Aside)
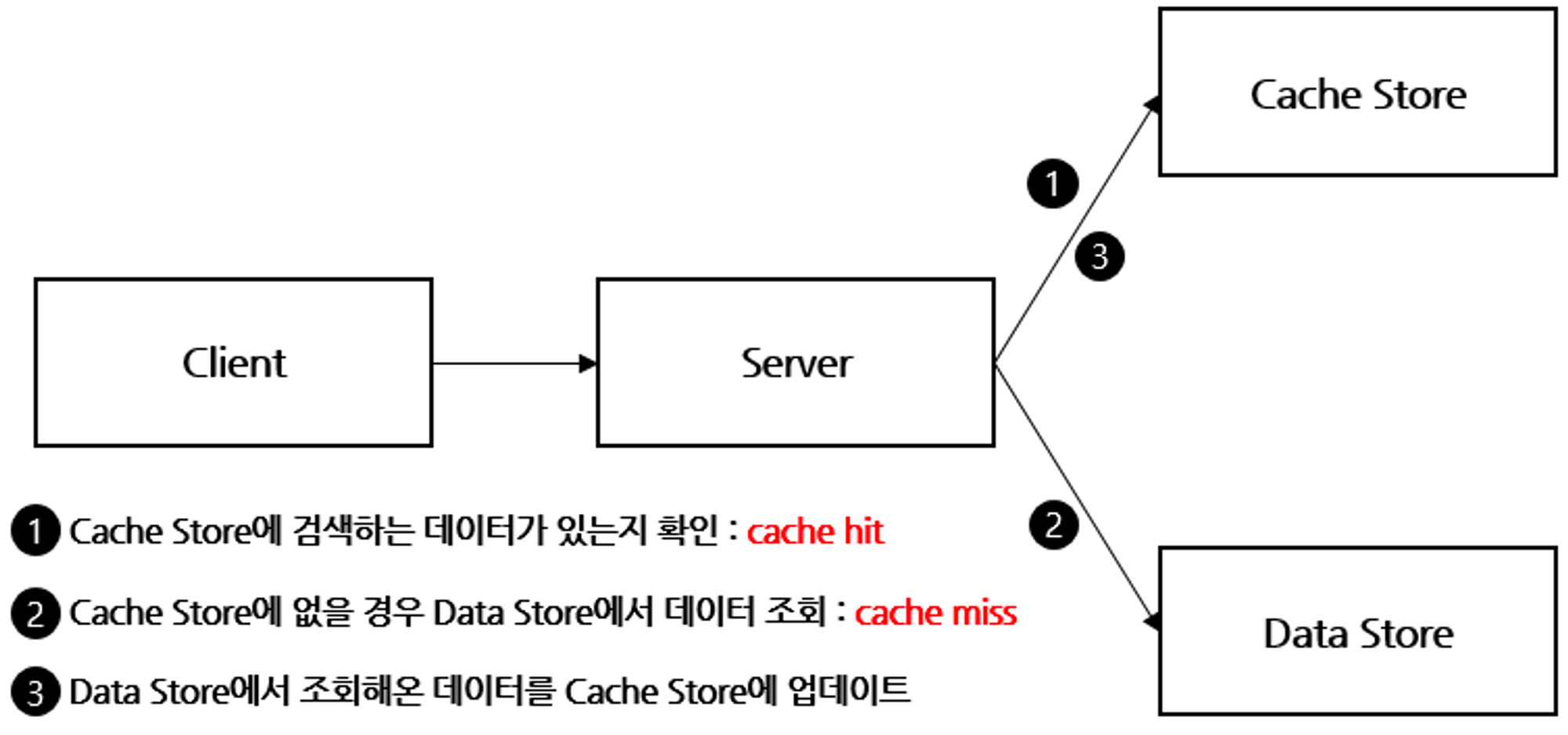
초기에 데이터를 DB에만 저장했다면 처음엔 cache miss가 많기 때문에 성능 저하의 가능성이 있다.
그래서 DB에서 캐시로 data를 미리 넣어주는 Cache Warming 작업을 한다.
<장점>
- 캐시와 DB가 분리되어 가용되기 때문에 원하는 데이터만 별도로 구성하여 캐시에 저장
<단점>
- 캐시에 붙어있던 connection이 많았다면, redis가 다운된 순간 순간적으로 DB로 몰려서 부하 발생.
Write Through
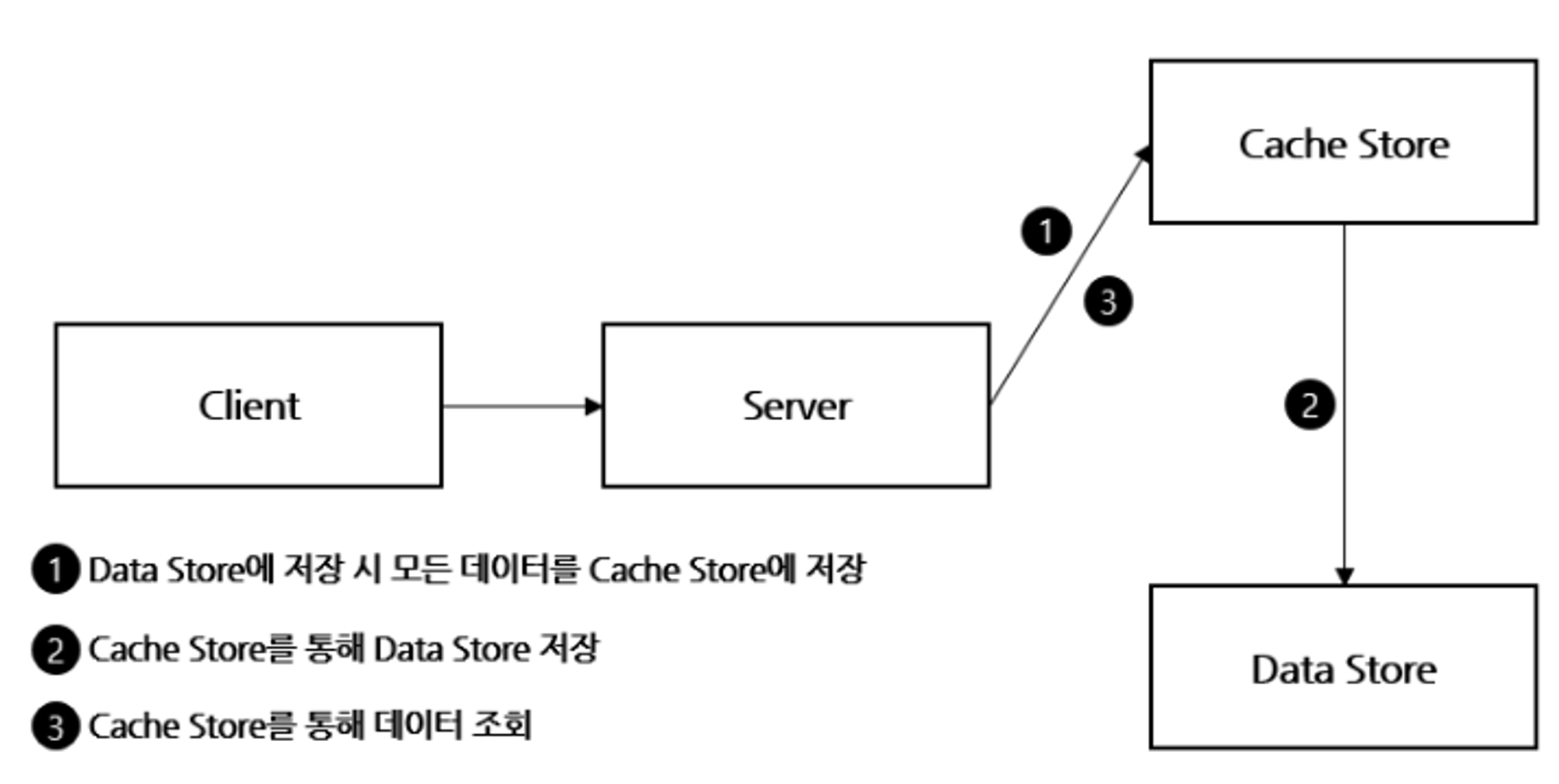
<장점>
- 캐시와 백업 저장소에 업데이트를 같이 하여 데이터 일관성을 유지할 수 있어서 안정적
<단점>
- 쓰기 작업이 많은 시스템이라면 눈에 띄는 딜레이를 유발할 수 있음
Redis Client는 어떤 것을 사용할까?
Redis Client에는 Jedis, Lettuce가 있다.
둘 모두 몇 천개의 Star를 가질만큼 유명한 오픈소스 이다.
어떤걸 선택할지 고민해보자.
Jedis
- 파이프라인을 제외하고 모두 동기식으로 되어있다.
- 여러 쓰레드에서 단일 jedis 인스턴스를 공유하려 할 때 쓰레드에 안전하지 않다. pooling(Thread-pool)과 같은 jedis-pool을 사용하여 안전하게 쓰는 법이 있지만 connection할 인스턴스를 미리 만들어놓고 대기하는 연결비용의 증가가 따른다.
Lettuce
- 동기, 비동기를 모두 지원한다.
- netty(비동기 이벤트 기반 고성능 네트워크 프레임워크) 라이브러리 위에서 구축되었고, connection 인스턴스(StatefulRedisConnection)를 여러 쓰레드에서 공유가 가능하기 때문에 Thread-safe하다.
<속도 차이>
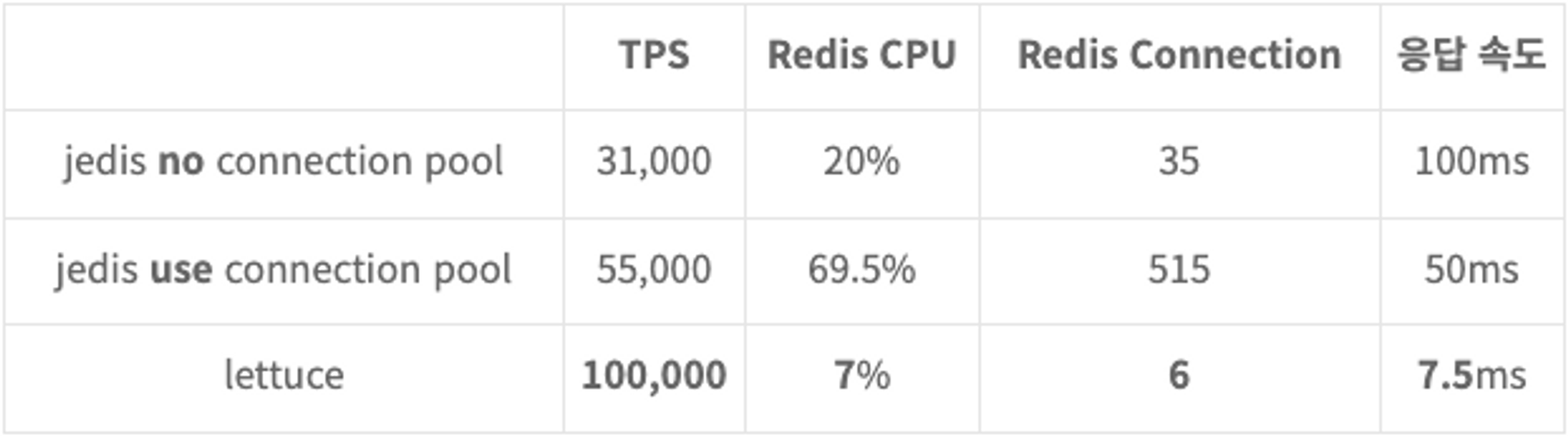
Lettuce가 훨씬 빠르다.
빠른 속도, 비동기 지원으로 인해 Lettuce를 사용할 예정이다.
Redis 테스트 환경 구축 방법
쓰기, 읽기 연산 구현 방법
읽기 연산
- 레디스에서 확인
- 없으면 DB에서 조회 후 레디스에 업데이트
- 초기에 DB와 레디스 데이터 맞추기
데이터 정합성을 위해 일정 주기마다 레디스 데이터 업데이트
쓰기 연산
DB에 저장 후 캐시에 저장
실제 적용한 코드
RedisCacheService.java
@Service
@RequiredArgsConstructor
public class RedisCacheService {
private final ReviewRepository reviewRepository;
private final RedisTemplate<String, Long> redisTemplate;
public Long getTotalReviewsByItemId(Long itemId, String cacheKey) {
Long cachedCount = redisTemplate.opsForValue().get(cacheKey);
if (cachedCount != null) {
return cachedCount;
}
long dbCount = reviewRepository.countByItem_ItemId(itemId);
redisTemplate.opsForValue().set(cacheKey, dbCount);
return dbCount;
}
}ReviewService.java
@Transactional(readOnly = true)
public Long findTotalReviewsByItem(
final Long itemId
) {
Item foundItem = findItemByItemId(itemId);
String cacheKey = "item:" + foundItem.getItemId();
return redisCacheService.getTotalReviewsByItemId(foundItem.getItemId(), cacheKey);
}Redis 사용 이후 읽기 연산 속도 차이
데이터가 100만개 있는 상황에서 Jmeter를 이용해 테스트를 했다. itemId를 찾는 쿼리 + 해당 itemId에 따른 리뷰를 count하는 쿼리가 발생했다.

1, 3번은 데이터베이스를 거치지 않고 Redis에서 바로 데이터를 가져왔다.
2, 4번은 Redis에 데이터가 없기 때문에 데이터베이스에서 데이터를 가져왔다.
| Redis에서 가져온 데이터 | DB에서 가져온 데이터 |
|---|---|
| 12ms | 160ms |
| 10ms | 158ms |
결과적으로 속도가 10배 이상 개선되었다.
적용한 프로젝트
https://github.com/prgrms-be-devcourse/BE-04-NaBMart
참고
https://inpa.tistory.com/entry/REDIS-📚-캐시Cache-설계-전략-지침-총정리
https://inpa.tistory.com/entry/REDIS-📚-데이터-타입Collection-종류-정리#redis_-_strings
https://www.baeldung.com/spring-boot-redis-cache
https://blog.naver.com/qjawnswkd/222403436289
https://m.blog.naver.com/qjawnswkd/222404574159
https://happy-jjang-a.tistory.com/178
Redis 테스트 환경
https://devoong2.tistory.com/entry/Springboot-Redis-테스트-환경-구축하기-Embedded-Redis-TestContainer
https://loosie.tistory.com/813#3.임베디드_Redis라이브러리_사용하기
Jedis, Lettuce
https://junghyungil.tistory.com/166
https://jojoldu.tistory.com/418
Jmeter
