4.1 JPA를 이용한 리포지터리 구현
- ModelRepositoryImpl은 인터페이스와 구현체를 분리하기 위한 타협안 같은 것이지 좋은 설계 원칙을 따르는 것은 아니다.
- 리포지터리가 제공하는 기본 기능
- ID로 애그리거트 조회
- null을 사용하고 싶지 않다면 Optional 사용
- 애그리거트 저장
- 삭제 기능
- deletedAt 같은 플래그값을 사용하는 방식 고려
- ID로 애그리거트 조회
4.2 스프링 데이터 JPA를 이용한 리포지터리 구현
- 규칙에 맞게 인터페이스를 정의하면 리포지터리를 구현한 객체를 알아서 만들어 스프링 빈으로 등록
- @SpringBootApplication으로
컴포넌트 스캔및 리포지터리 인식 - JpaRepositoryFactory 리포지터리 프록시 구현 생성
- SimpleJpaRepository 기반 실제 구현체 생성
- @SpringBootApplication으로
- 엔티티 저장
- save(Entity entity)
- 엔티티 조회
- findById()
- List findByOrderer(Orderer orderer)
- 엔티티 삭제
- delete(Order order)
- deleteById(OrderNo id)
4.3 매핑 구현
-
애그리거트와 JPA 매핑을 위한 기본 규칙
- 애그리거트 루트는 엔티티 → @Entity로 매핑
- 한 테이블에 엔티티와 밸류가 같이 있다면
- 밸류는 @Embeddable로 매핑
- 밸류 타입 프로퍼티는 @Embedded로 매핑
- @AttributeOverride
-
내장 객체의 필드 중 하나의 컬럼 매핑을 재정의
- 하나의 내장 객체를 다른 이름의 컬럼으로 여러 번 재사용할 때
- 공통 속성(주소, 기간, 이름 등)을 재사용 가능한 객체로 분리하고 싶을 때@Entity public class Member { @Embedded private Address homeAddress; @Embedded @AttributeOverrides({ @AttributeOverride(name = "city", column = @Column(name = "work_city")), @AttributeOverride(name = "street", column = @Column(name = "work_street")), @AttributeOverride(name = "zipcode", column = @Column(name = "work_zipcode")) }) private Address workAddress; }
-
-
엔티티와 밸류에는 기본 생성자가 필요없다.
- 생성 시점에 필요한 값을 모두 전달받기 때문이다.
- 그러나
JPA에서 @Entity와 @Embeddable로 클래스를 매핑하려면 기본 생성자를 제공해야한다. - 다른 코드에서 기본 생성자를 사용하지 못하도록 protected로 선언한다.
-
엔티티가 객체로서 제 역할을 하려면 외부에
set 메서드 대신 의도가 잘 드러나는 기능을 제공해야한다. -
객체가 제공할 기능 중심으로 엔티티를 구현하게끔 유도하려면 JPA 매핑 처리를
프로퍼티 방식이 아닌 필드 방식으로 선택해서 불필요한 get/set을 구현하지 말아야 한다.- 필드 방식
-
리플랙션을 이용해 JPA가 직접 필드에 접근해서 값을 조작@Entity public class Member { @Id // ← 필드에 위치 → JPA는 "필드 접근 방식" 사용 private Long id; private String name; public Long getId() { return id; } public void setId(Long id) { this.id = id; } } -
장점
- setter 없어도 가능
- 단순하고 명확
-
단점
- 리플랙션으로 private 필드를 직접 조작해서 캡슐화 침해
-
- 프로퍼티 접근
-
getter/setter를 통해 JPA가 값에 접근@Entity public class Member { private Long id; @Id // ← getter 메서드에 위치 → JPA는 "프로퍼티 접근 방식" 사용 public Long getId() { return id; } public void setId(Long id) { this.id = id; } private String name; } -
장점
- 캡슐화 보장
- setter 안에서 유효성 검증 가능
-
단점
- setter 반드시 필요해서 불변 객체 설계가 어려움
- 동작 예측 어려움
-
- 캡슐화를 중요시하여 setter를 사용할지, 객체의 기능 중심으로 엔티티를 구현할지 고민해서 결정해야한다.
- 필드 방식
-
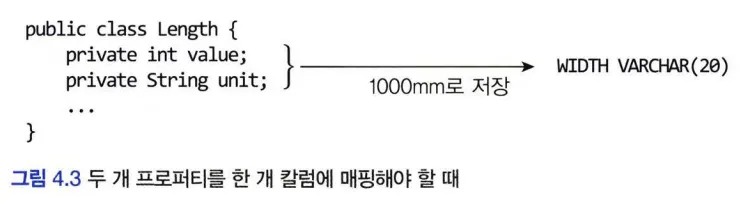
밸류 타입의 프로퍼티를 한 개 칼럼에 매핑해야할 때
-
AttributeConverter로 구현
@Converter(autoApply = true) public class MoneyConverter implements AttributeConverter<Money, Integeo { @0verride public Integer convertToDatabaseColumn(Money money) { return money = = null ? null : money.getValue(); } @0verride public Money convertToEntityAttribute(Integer value) { return value = = null ? null : new Money(value); } } -
@Converter 어노테이션으로 Money 타입 적용
-
-
밸류 컬렉션 : 별도 테이블 매핑
- @ElementCollection과 @CollectionTable 사용
- list 타입은 인덱스를 가지고 있기 때문에 별도의 인덱스 컬럼을 저장하지 않는다.
- @ElementCollection과 @CollectionTable 사용
-
밸류 컬렉션 : 한 개 컬럼 매핑
- Attributeconverter를 사용하려면 밸류 컬렉션을 표현하는
새로운 밸류 타입을 추가해야 한다.
- Attributeconverter를 사용하려면 밸류 컬렉션을 표현하는
-
밸류를 이용한 ID 매핑
- @EmbeddedId 어노테이션 사용
- 장점
- 식별자에 기능을 추가할 수 있다.
-
1세대 시스템의 주문번호와 2세대 시스템의 주문번호를 구분할 때
@Embeddable public class OrderNo implements Serializable { @Column(name = "order_number") private String number; public boolean is2ndGeneration() { return number.startsWith("N"); } ... -
is2ndGeneration() 으로 세대 구분
-
- 식별자에 기능을 추가할 수 있다.
-
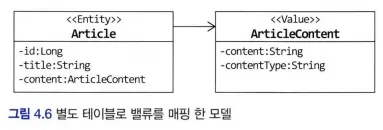
별도 테이블에 저장하는 밸류 매핑
-
애그리거트에서 루트 엔티티를 뺀 나머지 구성요소는 대부분 밸류
-
단지 별도 테이블에 데이터를 저장한다고 해서 엔티티인 것은 아니다. 주문 애그리거트도 OrderLine을 별도 테이블에 저장하지만 OrderLine 자체는 엔티티가 아니라 밸류이다.
-
자신만의 독자적인 라이프 사이클을 갖는다면 구분되는 애그리거트일 가능성이 높다.
-
애그리거트에 속한 객체가 밸류인지 엔티티인지 구분하는 방법은
고유 식별자를 갖는지를 확인하는 것
- 식별자를 찾을 때 매핑되는 테이블의 식별자를 애그리거트 구성요소의 식별자와 동일한 것으로 착각하면 안 된다.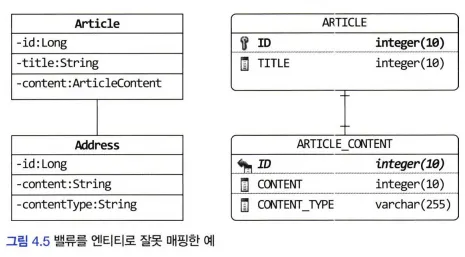
-
ARTICLE 테이블의 데이터와 연결하기 위함이지 ARTICLE_CONTENT를 위한 별도 식별자가 필요하기 때문은 아니다.
-
밸류를 매핑 한 테이블을 지정하기 위해
@SecondaryTable과@AttributeOverride사용- @SecondaryTable
-
name 속성은 밸류를 저장할 테이블을 지정
// @SecondaryTable로 매핑된 article_content 테이블을 조인 Article article = entityManager.find(Article.class, IL); -
article_content가 불필요할 때는 대비하여 ArticleContent를
지연 로딩방식 적용
-
- @AttributeOverride
- 해당 밸류 데이터가 저장된 테이블 이름을 지정한다.
- @SecondaryTable
-
-
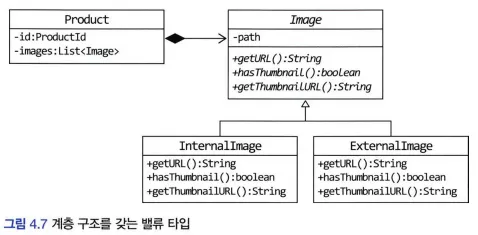
밸류 컬렉션을 @Entity로 매핑하기
-
구현 기술의 한계나 팀 표준 때문에 @Entity를 사용해야하는 경우
-
예시 > 제품 이미지 업로드 방식에 따라 이미지 경로와 썸네일 이미지 제공 여부가 달라지는 경우
-
상속 구조를 갖는 밸류 타입을 사용하려면 @Entity 사용이 필요하다.
-
@Inheritance 애너테이션 적용
-
strategy 값으로 SINGLE_TABLE 사용
-
@DiscriminatorColumn 애너테이션을 이용하여 타입 구분용으로 사용할 칼럼 지정
@Entity @Inheritance(strategy = InheritanceType.SINGLE_TABLE) @DiscriminatorColumn(name = "image_type") @Table(name = "image") public abstract class Image { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "image_id") private Long id; @Column(name = "imagej)ath") private String path;@Entity @DiscriminatorValue("II") public class Internallmage extends Image { } @Entity @DiscriminatorValue("EI") public class Externalimage extends Image { } -
Image가 @Entity 이므로 Product는 @OneToMany로 매핑
- 이미지 삭제하는 경우
- 하이버네이트의 경우
@Entity를 위한 컬렉션 객체의 clear() 메서드를 호출하면 select 쿼리로 대상 엔티티를 로딩하고,각 개별 엔티티에 대해 delete 쿼리를 실행한다.- 이미지 4개 삭제 시 delete 쿼리 4개 필요
@Embeddable타입에 대한 컬렉션의 clear()를 메서드를 호출하면한 번의 delete쿼리로 삭제 처리 수행- 이미지 4개 삭제 시 delete 쿼리 1개 필요
변경 빈도에 따라 어떻게 설계할지 고려 필요
- 하이버네이트의 경우
- 이미지 삭제하는 경우
-
-
-
-
ID 참조와 조인 테이블을 이용한 단방향 M-N 매핑
-
요구사항을 구현하는 데 집합 연관을 사용하는 것이 유리하다면 id 참조를 이용한 단방향 집합 연관을 적용해 볼 수 있다.
@ElementCollection @CollectionTable(name = "product_category", joinColumns = @JoinColumn(name = "product_id")) private Set<**CategoryId**> categorylds;
-
4.4 애그리거트 로딩 전략
- 애그리거트 루트를 로딩하면 루트에 속한 모든 객체가 완전한 상태여야 한다.
- 즉시 로딩 적용
- 단점
- outer join으로 인해 중복 결과 발생
메모리 상에서 중복 제거→ 데이터가 많아질 때 불필요한 데이터 발생
- 단점
- 완전해야하는 이유
- 상태를 변경하는 기능을 실행할 때 애그리거트 상태가 완전해야하기 때문
- 표현 영역에서 애그리거트의 상태 정보를 보여줄 때 필요
- 조회 전용 기능과 모델을 구현하는 방식이 더 유리
- 지연 로딩을 이용해 실제로 상태를 변경하는 시점에 필요한 구성 요소를 로딩해도 무방
- 즉시 로딩 적용
4.5 애그리거트의 영속성 전파
- 애그리거트 루트를 저장, 삭제할 때도 하나로 처리해야 한다.
@Embeddable매핑 타입은 함께 저장되고 삭제되므로 cascade 속성을 추가로 설정하지 않아도 된다.- 애그리거트에 속한 @Entity 타입에 대한 매핑은 cascade 속성을 사용해서 저장과 식제 시에 함께 처리되도록 설정
4.6 식별자 생성 기능
- 생성 방법 3가지
- 사용자가 직접 생성
- 도메인 로직으로 생성
- 식별자 생성 규칙이 있다면 엔티티를 생성할 때 식별자를 엔티티가 별도 서비스로 식별자 생성 기능을 분리해야 한다.
- 도메인 영역에 위치
- 식별자 생성 규칙이 있다면 엔티티를 생성할 때 식별자를 엔티티가 별도 서비스로 식별자 생성 기능을 분리해야 한다.
- DB를 이용한 일련번호 사용
- @GeneratedValue
- 리포티토리 영역
- @GeneratedValue
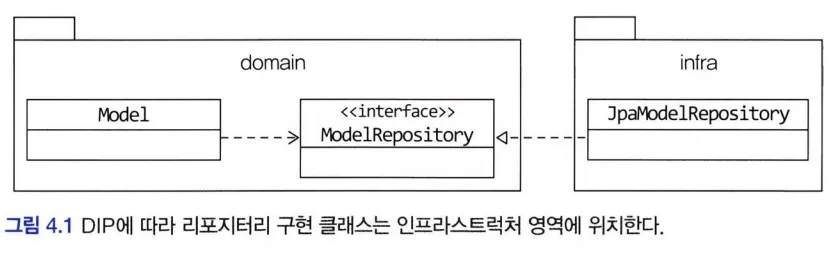
4.7 도메인 구현과 DIP
@Entity
@Table(name = "article")
@SecondaryTable(
name = "article_content",
pkJoinColumns = @PrimaryKeyJoinColumn(name = "id")
)
public class Article {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
...-
DIP에 따르면 @Entity, @Table은 구현 기술에 속하므로 Article과 같은 도메인 모델은 구현 기술인
JPA에 의존하지 말아야 하는데이 코드는 도메인 모델인 Article이 영속성 구현 기술인 JPA에 의존하고 있다.- 도메인이 인프라에 의존
-
구현 기술에 대한 의존 없이 도메인을 순수하게 유지하려면?
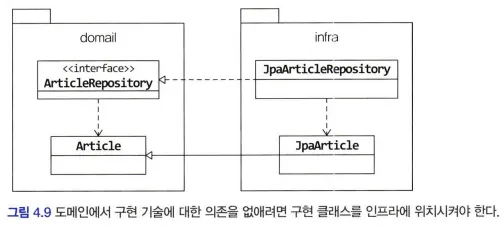
- DIP를 적용하는 주된 이유는 저수준 구현이 변경되더라도 고수준이 영향을 받지 않도록 하기 위함
- 그러나 리포지터리와 도메인 모델의 구현 기술은 거의 바뀌지 않는다.
- 이렇게 변경이 거의 없는 상황에서 변경을 미리 대비하는 것은 과하다고 생각한다.
- JPA 전용 어노테이션을 사용했지만 도메인 모델을 단위 테스트하는 데 문제는 없다.
- DIP를 완벽하게 지키는 것과 개별 편의성, 실용성을 가져가면서 구조적인 유연함을 지키는 것 중 선택하면 된다.
- DIP를 적용하는 주된 이유는 저수준 구현이 변경되더라도 고수준이 영향을 받지 않도록 하기 위함
