들어가며
aws 클라우드의 모니터링은 자사의 cloudwatch 말고도 아래 등등의 모니터링 플랫폼을 사용할 수도 있다. 가장 큰 차이점은 비용일텐데, 가령 cloudwatch는 사용량에 따른 요금을 부과하지만 datadog과 new relic 등은 구독형 지불 방식(플랜은 다양해 보였다.)을 채택하는 것 같아 보였다. 아무튼, 나는 현재 cloudwatch는 free tier를 사용할 수 있기 때문에, billing에서 아래와 같이 항목을 확인할 수 있었다.
가장 큰 차이점은 비용일텐데, 가령 cloudwatch는 사용량에 따른 요금을 부과하지만 datadog과 new relic 등은 구독형 지불 방식(플랜은 다양해 보였다.)을 채택하는 것 같아 보였다. 아무튼, 나는 현재 cloudwatch는 free tier를 사용할 수 있기 때문에, billing에서 아래와 같이 항목을 확인할 수 있었다. 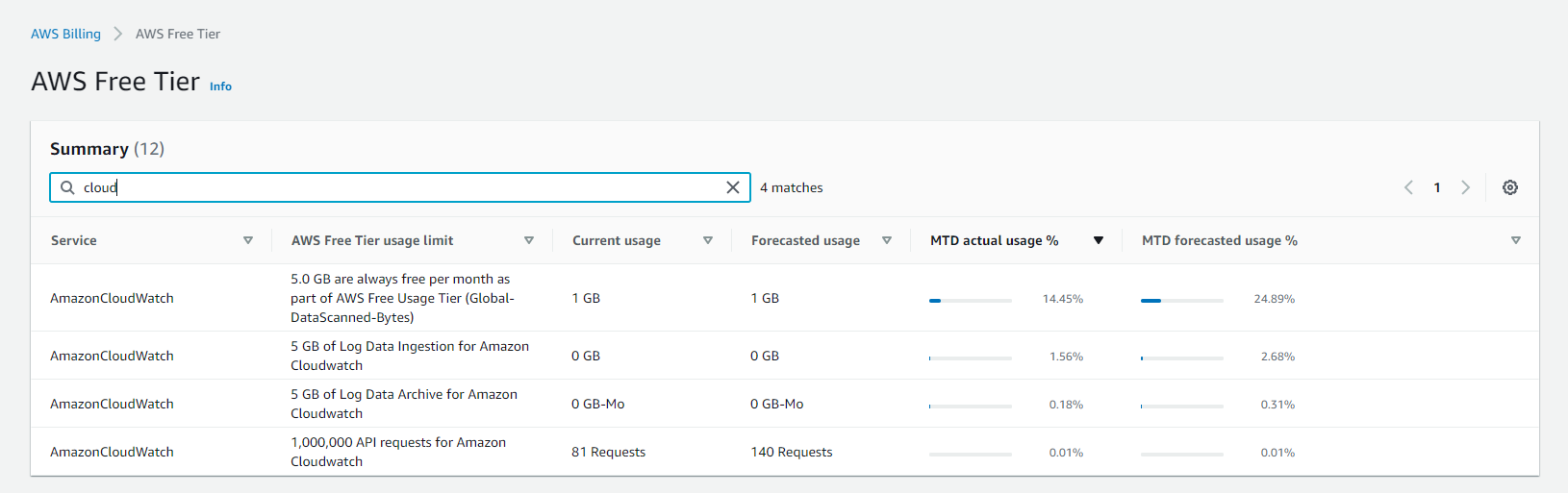
 아직 배포 전인데도 불구하고 최적화가 되어 있지 않기 때문에 모든 log를 출력하고 저장한다. 그로 인해 예기치도 못한 0.7GB가 사용된 것을 볼 수 있었다.
아직 배포 전인데도 불구하고 최적화가 되어 있지 않기 때문에 모든 log를 출력하고 저장한다. 그로 인해 예기치도 못한 0.7GB가 사용된 것을 볼 수 있었다.
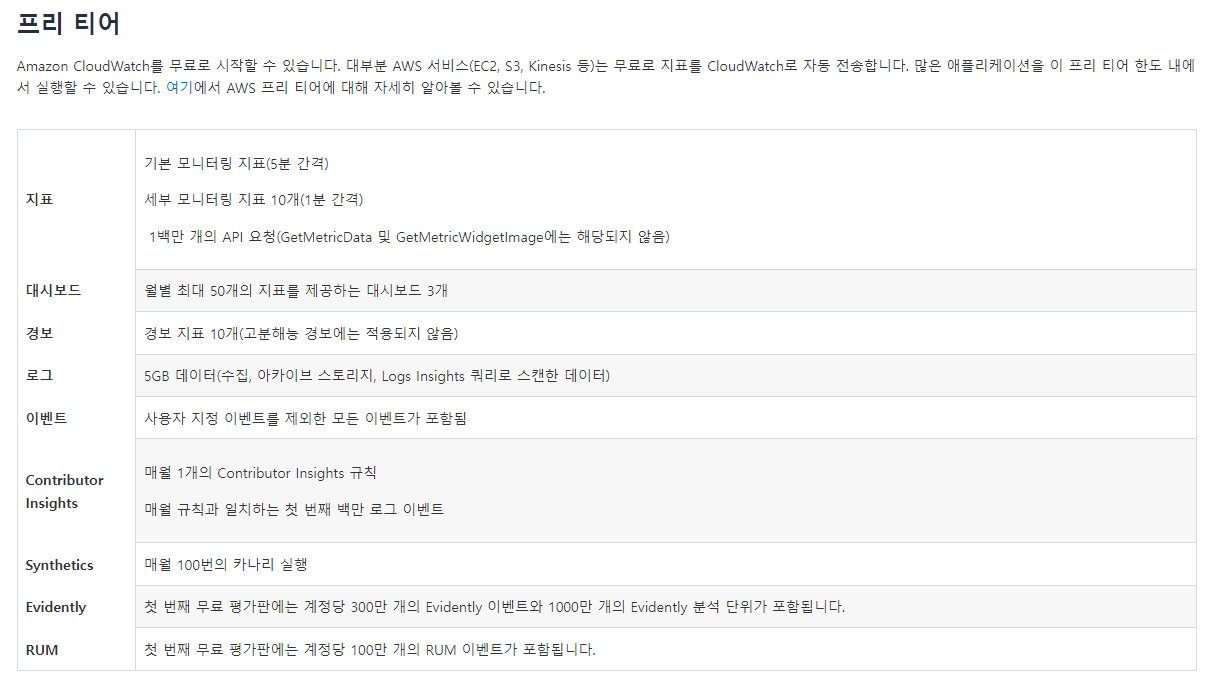 참고로 프리 티어의 요금제한은 위와 같다. 로그의 경우 서비스에 대한 로드맵을 덜 그린 현 시점에서는 최소화 하여 구성하기로 하고, 설정을 시작하도록 한다.
참고로 프리 티어의 요금제한은 위와 같다. 로그의 경우 서비스에 대한 로드맵을 덜 그린 현 시점에서는 최소화 하여 구성하기로 하고, 설정을 시작하도록 한다.
설계 및 조사
어떤 로그가 필요할까
무작정 로그를 남길 수 없을 것이다. 현재 팀에 기획자분이 계시지만, 다른 업무를 진행하고 계시기에 우선 내가 생각하는 최소 수집 기준을 상정할 것이다. 이를 cloudwatch 상에서 가시화를 해둔다면, 추후 요청하시는 수집 기준을 빠르게 마련할 수 있을 것이다.
아무튼 내가 생각하는 현재 catchcatch 프로젝트의 중요한 수치들은 다음과 같다.
- 접속자 수, 생성된 문제집 수, 로그인 횟수, 풀이자 수
- rds 커넥션 수, rds 사용률
- lambda 동시성 수, 성공 응답 수, 실패 응답 수, 평균/최대/최소 응답 시간
- 네트워크 패킷 수
어떻게 사용할 수 있을까
cloudwatch 사용법
브랜디에서 cloudwatch를 구성하는 방법을 포스팅해주어서, 그걸 참고하여 구성하고자 한다. 참고로 AWS::Serverless 의 cloudformation으로 cloudwatch를 관리하는 탭은 없는듯 하였다. 아래는 브랜디에서 설명해주는 cloudwatch의 기능들이다.
- event를 사용해 등록된 특정 패턴이 일치할 때나 주기적으로 규칙을 실행할 수 있다.
- logs는 운영중인 리소스를 기록하고 관련 로그 데이터를 패턴에 맞게 검색할 수 있다. 중요한 것은 보관일자를 지정하여 삭제할 수 있다 는 것이다.
- metric은 모니터링하고자 하는 통계치를 직접 커스텀하여 관리할 수 있도록 해준다.
- logs에서 지원하는 패턴에 맞는 로그 검색을 필터로 하여 지표로 확인할 수 있게끔 도와준다.
- alarm으로는 지표를 감시하여 측정치에 맞는 경보를 설정하여 이메일 등으로 알려줄 수 있다고 한다.
- dashboard는 metric filter를 이용하여 리소스를 가시화하여 볼 수 있도록 해준다.
cloudwatch 최적화
cloudwatch로 요금 폭탄을 맞을 수 있다는 글을 어디선가 본 적이 있다. 그래서 적절한 optimization 글을 찾아보았다. 다른 글들은 모두 상황에 대한 가정이었는데, 실제로 요금이 많이 나와 이를 최적화 하는 것을 보여주는 글이 있었다.
글에서는 특정 이벤트가 예상치 못하게 큰 지분을 차지하여 지출이 나온 상황이지만 이를 찾기 위해 log group들의 IncomingBytes 를 지표로 사용하여 보는 구간이 매우 흥미로웠다.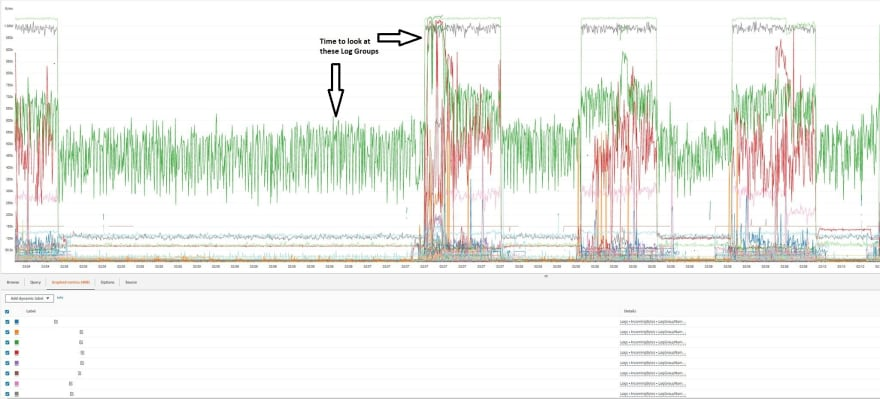
운용 방향
우선 위 서비스 중 event를 제외하고 모두 사용한다고 했을 때, 프리티어를 기준으로 다음과 같이 운용할 수 있을 듯 하다.
- metric
- 세부 모니터링 지표 (1분 간격, 10 개) : 접속자 수, 생성된 문제집 수, 로그인 횟수, 풀이자 수, 네트워크 패킷 수, rds 커넥션 수, lambda 동시성 수, 성공 응답 수, 실패 응답 수
- 일반 모니터링 지표 (5분 간격) : rds 사용률, 평균/최대/최소 응답시간,
- logs
- 접속자 수 : 로그인 함수 모든 로직 완료 시 info
- 생성된 문제집 수 : 문제 저장 함수 모든 로직 완료 시 info
- 로그인 횟수 : 유저 생성 후, 혹은 기존 유저 로그인 함수 로직 완료 시 info
- 풀이자 수 : 풀이자 정보 저장 함수 모든 로직 완료 시 info
- 네트워크 패킷 수 : NAT Instance EC2의 인아웃 패킷 수
- 평균/최대/최소 응답시간: Default Lambda Log 사용
- 성공/실패 응답 수: Default Lambda Log 사용
- lambda 동시성 수: Default Lambda Log 사용
- rds 커넥션/사용률 : Default RDS Log 사용
- alarms
- 아직 미정
순서
공식 블로그 글에서도 외부 로깅 프레임워크를 사용하길 권장하는 듯 하다. (물론 필요 없다면 그냥 해도 좋다고 한다.) 나는 추후에 배포 환경에 따라 로깅을 달리 적용할 예정이기에 winston을 사용한다. winston 구현은 이 글을 참고하였다. 아래의 글은 검색하다 발견한 글인데, 중간에 가격측면에서 극단적인 무책임한 로그의 예시를 들어줘서 인상적이었다. 필자가 바이트 단위의 금액을 계속 예시로 들어주며 이유를 설명하는 것 또한 믿음직스러웠다.
구현하는 순서는 다음과 같다.
- 서비스 로직 lambda 코드 내에서 운용 방향에 맞게 표출될 값을 로그로 남긴다.
- rds, lambda 등의 log 기록 방식을 확인한 후, 각 리소스들의 지표를 기록할 수 있도록 구성한다.
- cloudwatch에서 log group을 관리해준다. (만료 일자, 삭제된 리소스 확인 등)
- metric으로 대시보드에 나타낼 값들을 작성해준다.
- 대시보드로 metric들을 나타내 주고, 이를 공유가능하도록 열어둔다.
구현
lambda 내 로그 로직 추가
코드를 작성하다가 중간에 큰 문제가 발생했다. 최초 event를 parsing 하는 모듈이 정상적으로 동작하지 않는 것을 보았다. 이는 배포 전에 한번 더 상기하고자 TODO를 달아두었다.
winston 오류 발생까지의 개발
winston의 createLogger로 logger를 초기화 해준 다음, controller level에서 모듈을 di로 주입받아 사용하기로 했다.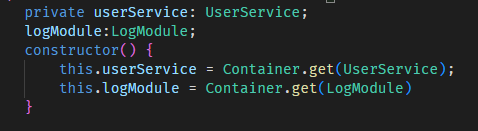
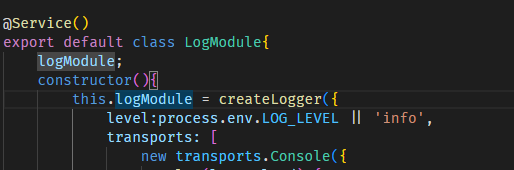 방법은 조금 야매(?)스럽지만, di를 시키기 위해 class를 하나 만들어서 @Service()로 컨테이너에 등록시켜줬다.
방법은 조금 야매(?)스럽지만, di를 시키기 위해 class를 하나 만들어서 @Service()로 컨테이너에 등록시켜줬다.
해당 로그 모듈은 logModule.info / error / debug 등을 실행하는 동명의 함수들을 property로 갖고 있다. 이는 ctrl 단에서 실행되며, 그 내용은 다음과 같다.
 로컬에서 잘 수행되는 것을 확인했으니, 구현한 내용을 배포하고 다음 작업을 진행하도록 한다.
로컬에서 잘 수행되는 것을 확인했으니, 구현한 내용을 배포하고 다음 작업을 진행하도록 한다.
winston console 갱신
잘 된다고 생각했지만, warm start 상황에서 logger가 동작을 안하는 것으로 확인되었다. 상당히 막막한 문제여서 쉽게 해결을 하지 못하고 있다가, winston의 동작 방식을 찬찬히 생각해내어 Console을 새로 만드는 로직을 포함하고 있다는 것을 깨달았다. 그리고는 console을 만드는 함수를 export 하고, 핸들러를 감싸는 wrapper에 logger의 console을 갱신시켜주었다.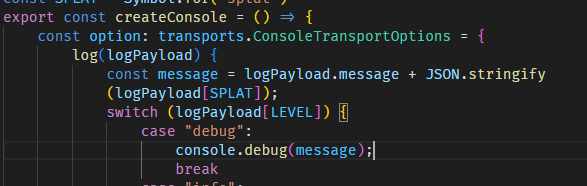
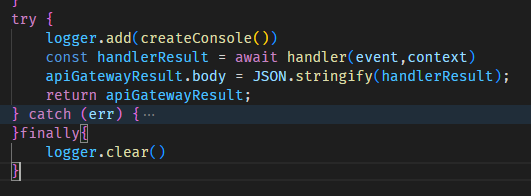
logger.add로 핸들러 호출 시의 새 콘솔을 지정하여 부착하고 핸들러가 끝날 시점에 그를 clear 해주는 방식으로 만들었다. 다행히도, 이번엔 정말 잘 동작한다.
다행히도, 이번엔 정말 잘 동작한다.
하지만, 응답 시간이 조금 늘어난 기분탓이 든다. 내일 lambda를 최적화 하며 최대한 이를 줄여보도록 한다.
각 리소스들의 지표 남기기
RDS와 Lambda 모두 기본적으로 동작에 대한 로그와 지표를 자동으로 수집한다고 한다. 각 서비스의 monitor 탭을 확인해보면 알 수 있다.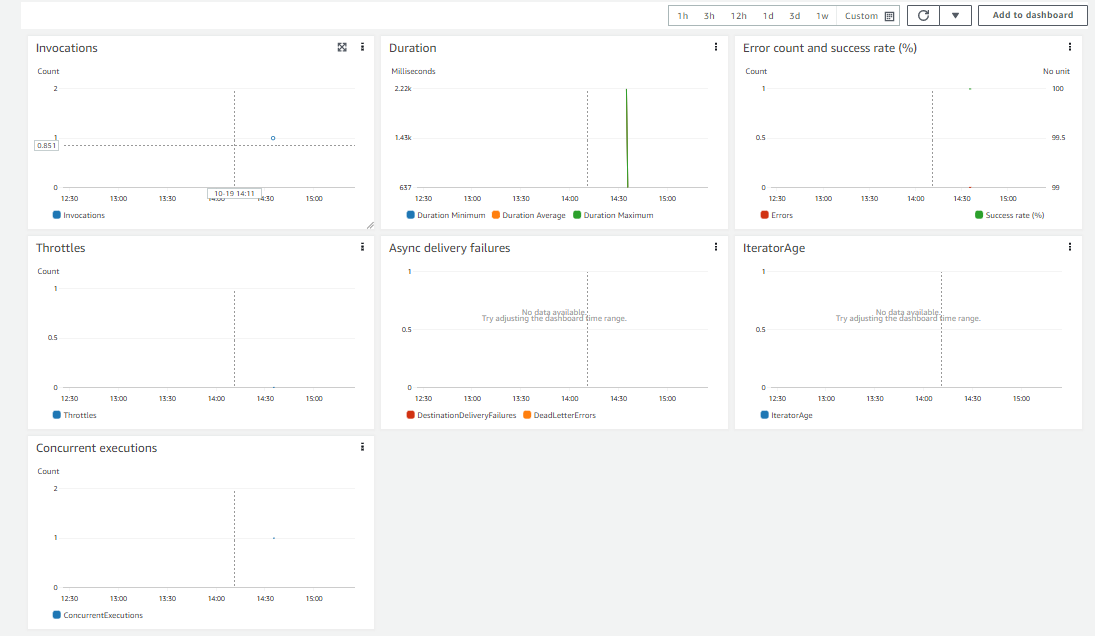

log group metric 생성 & 관리
앞서 로그로 남겼던 모든 lambda의 log groups에서 metric을 생성해준다. log group을 가보면, 나는 여태까지 sam으로 cloudformation을 많이 생성하고 삭제해왔기 때문에 여러 함수 이름으로 group들이 생성되어 있는 것을 볼 수 있다. 한번 생성된 스택에 대해서는 static하다고 한다. 모쪼록 이런 정리는 안하도록 구성해야겠다.
한번 생성된 스택에 대해서는 static하다고 한다. 모쪼록 이런 정리는 안하도록 구성해야겠다.
현재 로그가 작성되고 있는 그룹을 제외한 모든 그룹을 삭제하고, retention 주기를 설정해주었다. 그리고 사용하는 그룹 중 lambda에서 info 로깅을 남기는 그룹만 metric filter를 생성해주었다. 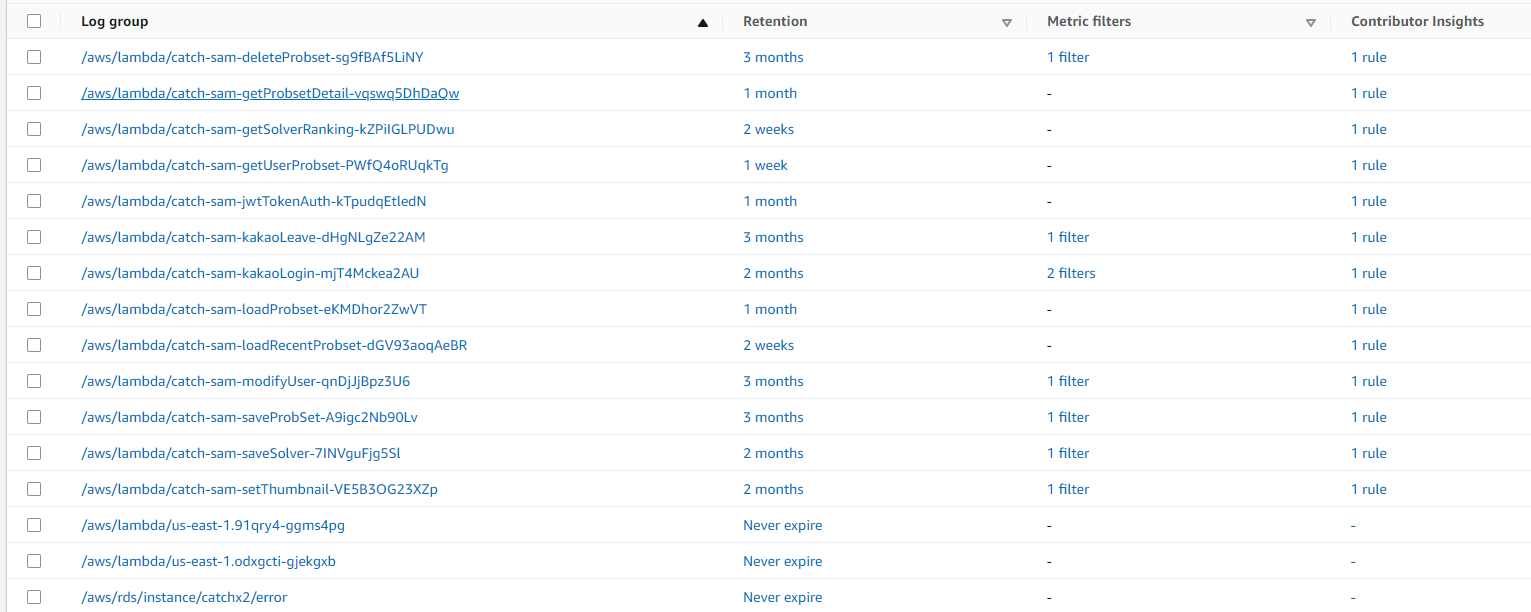 완성하고 나니 이런 형태를 얻을 수 있었다. 맨 마지막 contributor insights는 범용적인 에러로그를 위한 세팅이지만... 추후에 진짜 metric으로 동작하는지 확인이 필요할 것이다.
완성하고 나니 이런 형태를 얻을 수 있었다. 맨 마지막 contributor insights는 범용적인 에러로그를 위한 세팅이지만... 추후에 진짜 metric으로 동작하는지 확인이 필요할 것이다.
log group의 metric filter를 작성하는 것은 정말 간단하다. 아래와 같이 Filter pattern에 정규식을 포함하는 패턴을 입력하면, 해당 로그 그룹에서 매칭되는 결과를 긁어서 지표로 나타내 주는 역할을 하게 된다.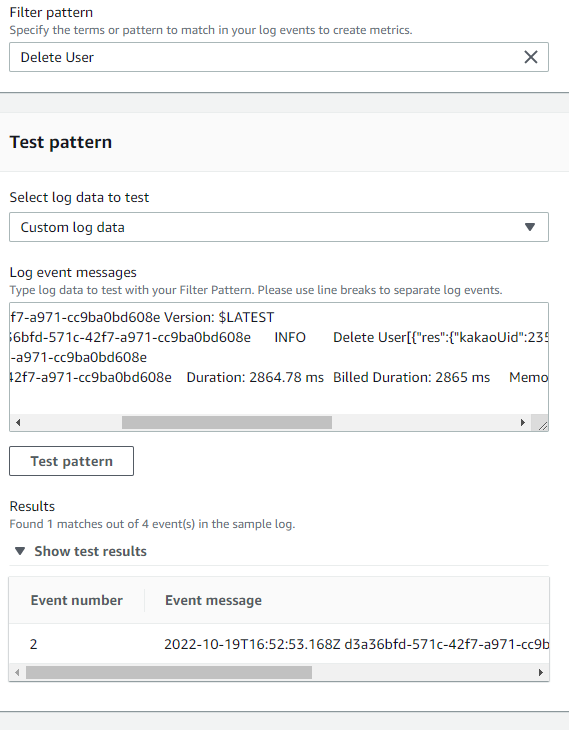
대시보드 꾸미기
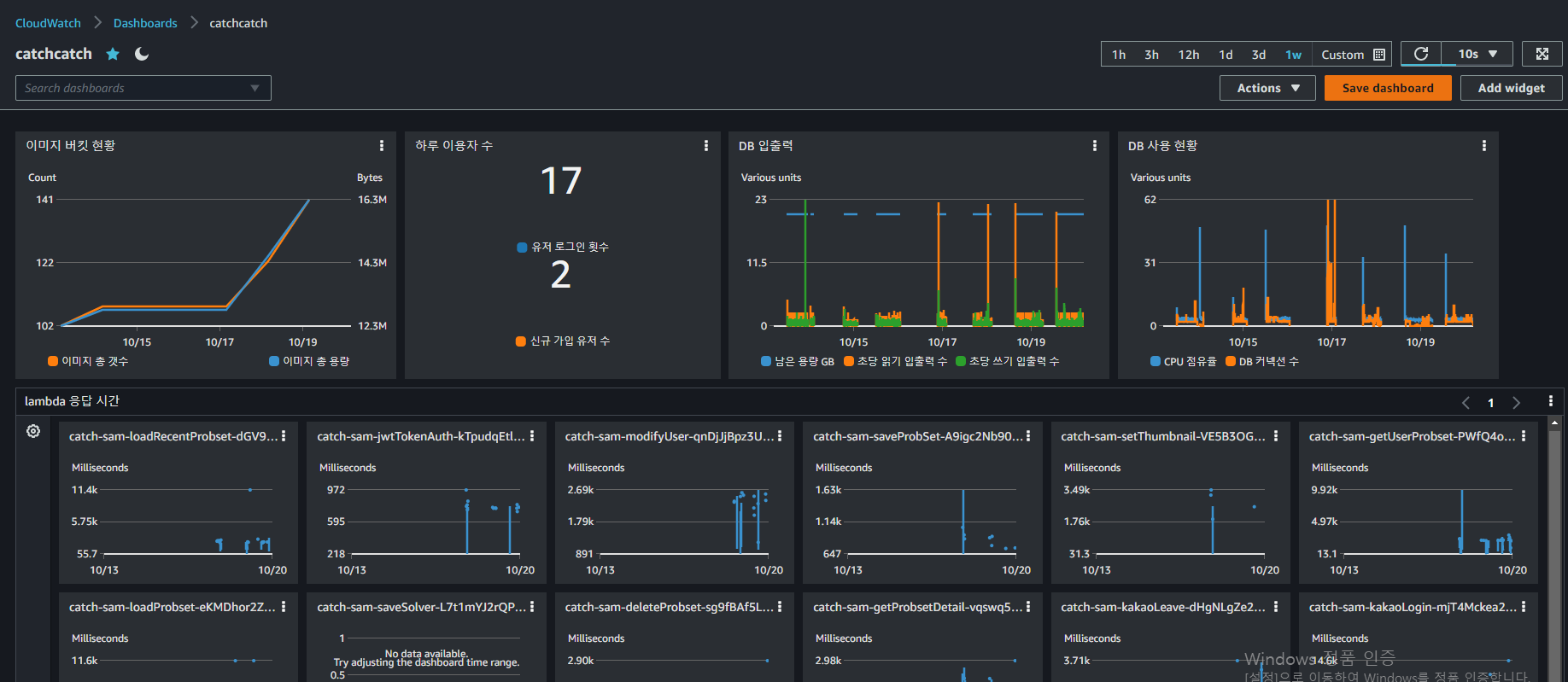
위에서 구성한 log group의 metric과 default resource metric을 함께하여 대시보드를 꾸밀 수 있다. add widget을 누르고 이것 저것 추가하다보면 아래와 같이 그나마 보기 편하게 구성된다.